





Traditional database security doesn’t protect data
It seems every week there’s a new data breach to read (or tweet) about. I recently discovered this lovely visualization of the growing amount of private data about people like you and me that is being exposed. You can filter and/or sort the data by industry sector, method of leak and data sensitivity. It makes for a beautifully depressing coffee break.
After reading that, you might like to check to see if your details have been included in any of the data breaches listed on haveibeenpwned.com. Thanks to this site, and an alert I received from it following the 2016 LinkedIn breach, I now use a password manager – and I recommend you do the same.
If you're responsible for a database, and would like to avoid your company being the topic of a highly critical – and funny – TV sketch like Stephen Colbert's Equifax rant on The Late Show, you need to think very seriously about how you are going to protect your data, particularly with the growing emergence of data privacy regulations such as the GDPR.
As a Database Lifecycle Management (DLM) and Database DevOps consultant, I get to see a lot of dev, test and production environments. I am surprised how often I see sensitive production data in development databases that is available to the entire development team. I sometimes need to ask customers to revoke my access to those dev systems because, as a consultant, I don’t want to expose myself to the risk that I might accidentally click a phishing link and let the bad folks in, facilitating a data breach.
(If you think you are above making a silly mistake like clicking a phishing link – get serious. It can happen to the best of us. It’s wise to be prudent and protect yourself, regardless of how confident you are that you’ll never make a mistake.)
The point is that hackers aren’t targeting production systems any more. Database Administrators (DBAs) are quite rightly making ever more strident efforts to lock those systems down so it’s more difficult to get in. It’s much easier for hackers to scan the network for a dev database or a forgotten backup file. Ask yourself, how would you (or your boss) feel if someone uploaded your dev database to the internet?
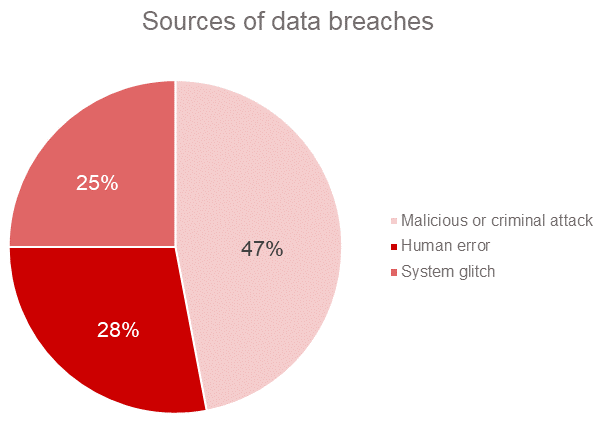
And it’s not just hackers you need to worry about. According to IBM’s 2017 Cost of Data Breach Study, malicious attacks are the root cause of slightly less than half of data breaches. System glitches and human error are responsible for roughly a quarter each.
No doubt, had the data in the dev databases and backups been treated with as much diligence, a good portion of these data breaches could have been avoided.
Perhaps the 2016 Uber hackers wouldn’t have been able to find the credentials saved in a developer’s GitHub repo that granted them access to an archive of rider and driver information. And perhaps that faulty backup with 1.37 billion email addresses wouldn’t have been mistakenly uploaded to a public storage account by spam company River City Media.
Unfortunately, traditional database security has failed us.
Developers need access to the dev database to do their work. They need to be able to use appropriate test data to test their code. Traditional security features (logins, roles and users – even encryption technologies, dynamic data masking and row level security, etc) can be used to manage who has access to the data in production systems, but if a dev or test database already has the sensitive data these fundamental security features are worthless with regard to data protection. Even encrypted data only remains secure if the keys remain safe.
Sure, traditional security features protect the data in the production system – but not if it has already been copied to a less secure environment. And most people don’t track that with anywhere near as much rigor as they should.
To protect data effectively, we need to think much more consciously, not just about the production database, but also about all the other databases and backups that make up our database lifecycles, including dev and test systems and dev workstations. We need to know exactly where our security perimeter lies. Any copy of sensitive production data needs to live within the security perimeter and not outside it.
I propose that dev and test systems lie outside the security perimeter and that they should not contain sensitive data. The evidence tells us that people are much more likely to suffer a data breach if the data starts propagating to many environments, with lower priority security policies, and where many more people have access. We should assume that our dev and test systems could be leaked to the internet at any time, and we should design our dev and test data with that in mind.
Also, if your data is regulated by regulations like the GDPR, you will probably either need to justify processing it for dev/test purposes by gaining ‘explicit consent’ from 100% of data subjects (which is probably near impossible) or arguing ‘legitimate interests’ (which, for most, would probably be a pretty bold and difficult case to make).
In contrast, by ensuring sensitive data does not leave the production domain, your processes are in line with regulatory expectations like the six principles of data processing, described in article 5 of the GDPR and covering areas such as data minimization, purpose limitations, storage limitations and integrity/confidentiality.
So how can we protect ourselves from sensitive production data leaking into the dev domain?
Since traditional database security doesn’t help us very much, I suggest the following five-step process. This aligns with various standards like ISO 27001 and the official advice from the UK Information Commissioners Office (ICO).
Frankly, it’s just common-sense.
Step 1: Conduct an inventory and create a data catalogue
Data protection is all about risk management. Some data is more sensitive and/or risky than others and deserves extra care. Regulations like the GDPR recognize this explicitly:
“Guidance on the implementation of appropriate measures and on the demonstration of compliance by the controller or the processor, especially as regards the identification of the risk related to the processing, their assessment in terms of origin, nature, likelihood and severity, and the identification of best practices to mitigate the risk, could be provided in particular by means of approved codes of conduct, approved certifications, guidelines provided by the Board or indications provided by a data protection officer.”
Taking a risk-based approach to data protection requires that an organization understands the risks associated with data it holds and where that data is located. Therefore, the first task for anyone responsible for managing data security should be to perform an audit/inventory of all the data they hold (in every environment), and document it with respect to data sensitivity.
Gartner recently declared that Data Catalogs Are the New Black in Data Management and Analytics. Understanding data sensitivity is a fundamental requirement of any risk-based approach to data security, and a data catalogue allows users to easily understand what data exists in the database and how sensitive it is.
Step 2: Write a data protection policy … in code
Based on the outcome of step 1, it may be appropriate to apply different security measures to different sorts of data. For example, if you store foreign currency exchange rates in one column and bank balances in another, you might wish to apply different security processes to each.
You may, for example, choose to copy the real exchange rates into dev (because these are public knowledge anyway), but mask the bank balances in some fashion (because this is clearly private information).
Our security processes should be defined by a policy that determines, based on a data sensitivity classification, things like who should have access to the data, how that access is enforced, data minimization and masking techniques, and how backups should be managed.
These policies are very useful as they normally allow an organization to remain compliant with multiple regulations at the same time through a single process. As long as your data protection policy applies a common-sense, risk-based approach to the ethical and security issues associated with data processing/controlling (and you can provide evidence that your policy is adhered to), you will probably find that you have relatively little additional work to do when the next data privacy regulation comes along.
However, in my experience these data protection policies are normally stale Word documents that are forgotten in dusty filing cabinets in dark corners of offices. They rarely get reviewed, they only get dug out at audit time, and they are often out of date. If I ask the average developer whether their organization has a data protection policy, their answer will probably be: “I’m guessing so – but I’ve never read it”.
My suggestion is that we need to digitize our data protection policies.
I can imagine a future where our data protection policies are actively protecting our estate. They would become a tool managed by a DBA or a Data Protection Officer (DPO). There would be data privacy monitoring dashboards displayed on monitors next to the DBA team. Changes to the policy could be audited, and even source controlled.
When the auditor comes to assess compliance with respect to the data protection and privacy, it will be trivial to explain how the security of your estate is managed and you will have the evidence to back it up.
Step 3: Automate the provisioning of dev/test data
If you work with sensitive data, this is an essential part of your security policy.
We use traditional security features to lock down production, but we use automated provisioning processes to protect the sensitive data from leaking into our non-production environments. And since the non-production environments are often an easier target, it’s arguable that the automated provisioning processes are more (or at least equally) important.
DevOps has taught us the importance of shifting as much testing as possible as far left as possible. Gone are the days of those integration testing and release testing phases during month 10 and 11 of a 12-month project (which always seemed to run late and over-budget). These are activities that are largely automated nowadays, and which are running constantly as part of your development processes.
By shifting testing activities to the left, we can write better quality code and ship fewer bugs and regressions. That alone has value with regards to risk-based approach to data protection. Bugs are risky.
Arguably, the best data for testing is production data. Unfortunately, based on what I’ve said so far, that’s not an option if you have sensitive data. The best we can realistically provide is an anonymized or masked copy of the production data, where all the sensitive and/or identifying information has been removed. I propose that the measure of whether your database is suitably anonymized is as follows:
“Imagine someone copied your unencrypted development database to the public internet, and then posted a link to it on a popular hacker website. Did your heart just skip a beat?”
If the answer is yes, then that data should not be in the development domain. Based on the research by IBM I mentioned earlier, you cannot trust your developers with this data. That’s nothing personal – I don’t trust myself with it. It’s the same reason I wear a seatbelt and it’s the same reason you take backups. It’s just not worth exposing your organization to the risk.
DevOps has also taught us that self-service is important. Logging a ticket for a DBA to manually come and provision a database and manually run the masking rules for each developer and each new feature branch (for example) is enormously inefficient.
We need to provide a practical and repeatable process for developers to be able to provision themselves with a development database containing suitable test data. And this should be the only way they are able to provision themselves with test data.
Step 4: Lock down production
That’s right. This is step 4. Not step 1.
If I was primarily thinking about the security of my production system, maybe I would have ordered these steps differently. But right now, I’m talking about security in the context of data protection, and what is the point in locking down the production database if all the sensitive data is accessible in the dev and test systems anyway? I promise you, the hackers and any malicious (or careless) employees will be leaking the data from your dev servers before they target your production servers anyway. It’s just easier to do.
Of course, we certainly do need to lock down the production system, but my case is simply that if you have skipped any of the first three steps, this may be a pointless exercise. You are polishing the brass on the Titanic. The water is washing all around your feet, but you are going to get that porthole latch spotless if it’s the last thing you do.
That said, while it may only step 4 in the list, it’s still important. Of course it is! Without locking down production, you are obviously leaving the door wide open. We do need all the traditional security tools and features which I alluded to above to help us do that. I don’t want you to read this blog post and interpret that I don’t think they are important. They are.
Our access controls will be driven by the sensitivity labels in our catalogue and our policies about who should have access and who shouldn’t. And we will certainly want to report on how compliant our access controls are with our policy and monitor for policy breaches. If someone creates a new user against the production system, that should also be logged and an alert may need to be raised.
Step 5: Monitor for breaches of your data policy
By this point you have a data catalogue, a digitized policy engine, a policy-based automated process for provisioning masked non-production environments, and a policy-based and data sensitivity-based set of access controls against your production system.
However, data protection isn’t a one-time task, it’s an ongoing process. Once we’ve got our ship in order we want it to keep it tidy. For example:
- As our data, our context and our regulations evolve we will want to continually review our policies
- New columns will be added over time and they will need to be classified with respect to privacy and we may need to create masking rules for them
Some of this stuff will need to be monitored by manually reviewing our processes. For example, software isn’t very good at picking up on changing social contexts that may cause us to re-evaluate our data sensitivity classifications.
On the other hand, some of this can (and should) be monitored automatically. For example, it’s conceivable that my monitoring software could raise an alert if it spots data in the dev domain that looks suspiciously like sensitive production data. I might also appreciate an alert if any user who is not a member of the DBA admin group gains access to a production system.
I’m aware that’s quite a big job …
I’m sorry that this may feel like quite a lot of work. I’m also aware that a lot of the software I’ve described has not yet been written and is not available of the shelf.
However, at a time when the vast majority of us have already been affected by multiple data breaches, and when we are witnessing data breaches with greater scale, frequency and increasingly dangerous consequences, it is clear that the way we have been managing data security to date has not worked.
And this is why I propose that the features we think of as traditional database security are not sufficient to protect your data. There is a lot more we need to do to meet the increasingly strict data privacy and protection demands placed upon us. As an industry, we need to change the way we think about data security.
The good news is that I expect to see plenty of innovation and new tooling coming out over the next few years to fill some of the gaps. And I expect my friends at Redgate to be at the forefront of that movement. Just take a look at their SQL Data Privacy Suite.
And if you would like any help from me, please do get in touch with me at www.dlmconsultants.com.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
You may also like

Blog
In 2026, engineering teams are quietly accepting more risk. Here’s why

Blog
Without Governance, AI Is Just Faster Failure

Blog
Loading comments...