





Sharing data in a secure way
One of the most common processes in software development is using a copy of production data to help develop new features or troubleshoot an issue. This typically involves creating a database backup by copying backup files to a local development server or the developer’s computer.
In this process there are several risks involving the data. How was the backup generated, for example? Is the copy being done over a clear or encrypted connection? Is the developer’s computer fully patched and secured with antivirus, anti-malware, or disk encryption?
These are important questions to ask because there are now sophisticated hackers stealing information all around the world, and the ways we share data have become a primary target. Whether that happens by eavesdropping through unprotected connections or with malware, the reality is that we need to protect our customer data at all cost. We must always be one step ahead of hackers and because data still needs to be shared and moved around, it is imperative we consistently provide the proper tools to protect information while also implementing a secure practice for sharing such data.
The first and most obvious solution to prevent anyone from stealing data while it’s being shared is not to share it – but then we would not have data to work on. Once the need to share data is recognized, what can we do to maximize its protection, so it won’t be stolen?
Some solutions have surfaced to address this problem. One is to allow developers to connect directly to the production database, but this is by far the most dangerous option. Anything can happen in this scenario and most likely the entire infrastructure and operations teams would refuse to allow it.
Another solution is encryption. In general, you should aim to have all (or at least the most sensitive) information encrypted. This can be done in several ways and secure certificates have been a popular choice in recent years. With an encrypted database, a backup will have the data encrypted so even if it’s stolen the data will be inaccessible.
There is a second level of encryption during its copy stage. The connection over the internet or through a regular network must also be encrypted to protect data while in transit.
The third and final level of encryption is when it reaches the developer’s computer (or local development server). At this point, disks should be encrypted with technologies such as BitLocker or similar.
Now, let’s pause a moment and study why are we doing this. We are talking about customer data that needs to be shared. If you take, for example, a database from an online retailer, it will probably contain sensitive information gathered during the purchase process. Most likely there will also be customer addresses, birth dates, and so forth. This information constitutes personally identifiable information that can be (mis)used in many ways to access financial details and steal money, contact and/or locate a person, etc.
As you can see, while encryption is a solid solution, it requires many elements at different levels and may not only be costly but also impractical or overkill to implement.
What should we do then? A solution that works very well is data masking. With data masking, developers are provided with a copy of production data, but the sensitive information has already been masked. Once personally identifiable information has been masked and cannot be traced back to people, it is safe to share with the development team.
Masking must also, however, abide by certain data rules, such as when data is shared, and masked data must propagate across different tables. For example, the task of masking a complete set of information related to an individual could potentially spread across multiple tables and sometimes that information needs to flow through multiple databases. In the end, any sensitive data must be masked but also be consistent.
Data masking is a tedious, difficult process but there are tools that can help, such as Redgate’s Data Masker. In the image below, you can see how it works, based on a set of rules that are applied to tables.
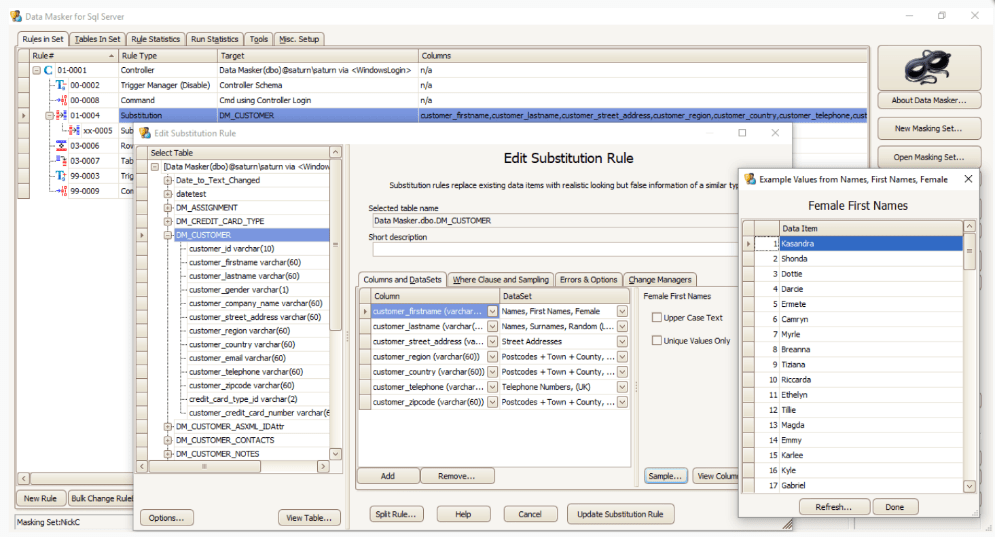
As can be seen, a substitution rule works on the customer table by changing the values in some of the columns. This includes a set of dictionaries with readily available fake information that will anonymize real data.
After applying the rules to the database tables, the new, fake data is ready to be shared with developers. It cannot be traced back to real people but can now be used to troubleshoot problems or develop new features:
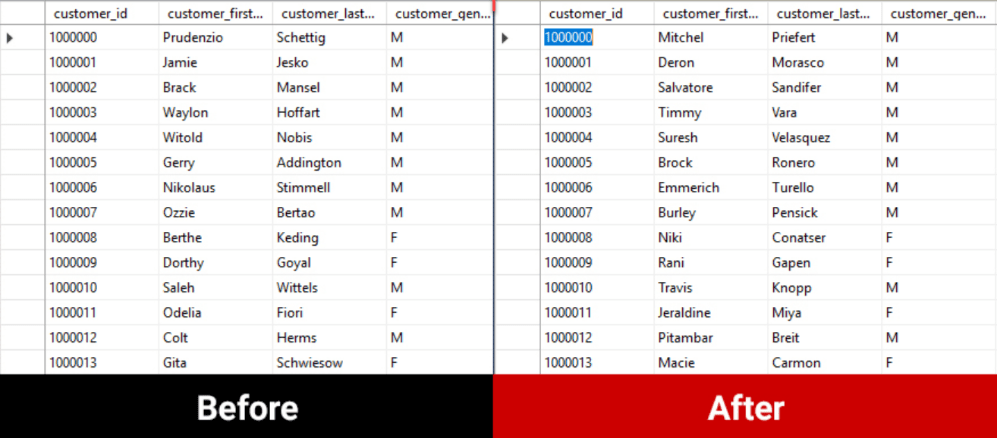
Data masking is a great solution to protect sensitive data. With the use of the right tools it can be implemented to meet all levels of compliance, run repeatedly, consistently and fast. Planning for data masking should be considered when sharing data, from provisioning a copy of a database to masking the data to share the masked database, all to protect our customers and their data.
![]() Jose Guay is Director of Software Development at CSW Solutions, a Chicago-based custom software consulting and development firm, which provides web/mobile, database and cloud services. More information about the Microsoft-certified partner can be found online at cswsolutions.com.
Jose Guay is Director of Software Development at CSW Solutions, a Chicago-based custom software consulting and development firm, which provides web/mobile, database and cloud services. More information about the Microsoft-certified partner can be found online at cswsolutions.com.
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
You may also like

Blog
In 2026, engineering teams are quietly accepting more risk. Here’s why

Blog
Without Governance, AI Is Just Faster Failure

Blog
Loading comments...