Security and compliance
Ensure data security and compliance with data masking, monitoring, and change traceability
Ensure data security and compliance with data masking, monitoring, and change traceability
Monitor and understand your databases with full visibility into performance and change
Build, test, and deploy database changes with confidence
Simplify and speed up database development workflows
Prepare reliable data foundations for AI initiatives
Simplify and secure database modernization across platforms
Control costs and boost efficiency in database operations
Simplify and speed up cloud database transformation
By Steve Jones
"The database is down!"
This is arguably the most dreaded call a database administrator can receive. Your heart races, your stomach clenches, and your first instinct is to connect to your system immediately. After all, if the database is down or unresponsive, then it's likely your application has stopped working as well. Whether by mobile device or remote laptop, it's imperative that you determine the issue as quickly as possible and correct the problem.
I've received more than a few of these "database down" calls, the cause of which ranges from hardware failures to network problems to users being unable to complete any data modification transactions in the database.
In one case, I had users report to me that their changes wouldn't complete; they were unsure of the exact problem, only that something was "wrong" with the database. My response in this situation is to log into the system and try to create a small table, perhaps adding a few rows, using code like that shown in Listing 1. The error message immediately confirmed for me that the file location for this database was, indeed, out of space.
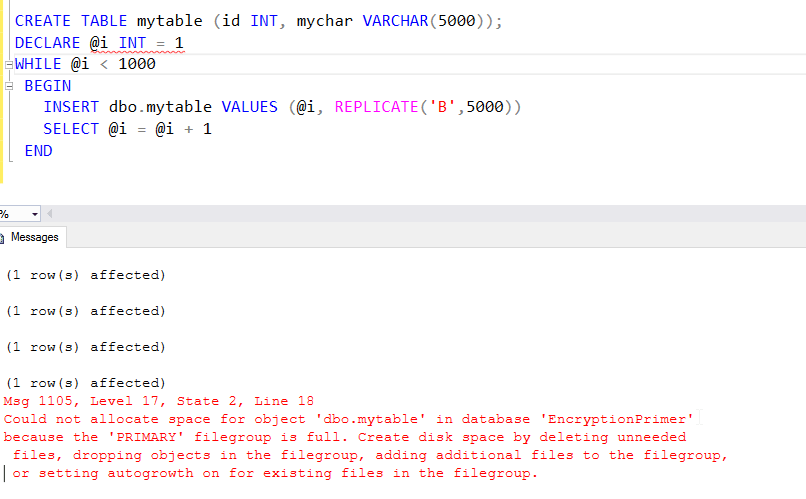
Figure 1 – a short script to CREATE a table, with an error message about disk space
Fortunately, since I had good error handling in place the users hadn't been exposed to this error and so were unaware of the actual problem with SQL Server.
Of course, it's a fairly simple process to open Windows Explorer on the affected server and confirm how much disk space is available on a drive. Hopefully, your disk won't ever look as shown in Figure 2.
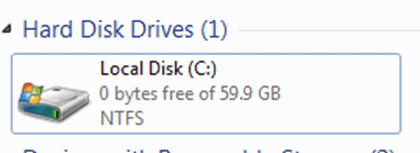
Figure 2 – Local Disk with 0 bytes free
Running out of disk space is not only extremely embarrassing, it's professionally unacceptable. It's also a sign to upper management of an administrator who isn't paying attention to their environment. You may get away with it once or twice, if you're able to respond and fix the issue very quickly, but if it happens repeatedly, you'll lose the trust of managers, and possibly your job. In this case, I'd received a disk space alert, but the log and data files for this particular database had grown rapidly and filled the disk before I'd had time to free space and avert the problem. I was able to fix things very quickly, but it was a harsh lesson that I needed to improve our disk space monitoring and alerting.
Having confirmed a disk space-space problem, the first item to check is the autogrowth settings for both the data and log files of the affected database. If autogrowth is disabled, it could be that either, or both, of these files have grown to their maximum size. If this is the case, then you may be able to resolve the issue by manually growing your database or log files, depending on which is out of space.
However, if the problem is that files are full and the underlying disk is full, then you cannot grow the files further. That's a scary moment, and I hope you have placeholder files that you can delete to quickly fix things. However, if you don't, then likely you'll need to look for some type of file(s) you can delete. Often, you can free up space by removing old backup files, import/export files, or application log files (such as error logs, event logs and so on). If your data and log files are located on a SAN, perhaps your SAN administrators can grow the underlying disk presented to the server, and give you more space.
If none of these fixes are possible, or don't work, perhaps you can find a way to add an additional data or log file. You'll need to attach to the Windows host a disk with free space on it, and then use the ALTER DATABASE command to add and configure additional data files (and/or filegroups), as required in order to provide adequate storage for continuing database operations.
Adding files or filegroups on another drive complicates your system for administrators, and can cause confusion during disaster recovery situations, so be sure you document your changes. You may also want to make an appointment in your calendar to attempt to undo your changes, when more space is available.
It is important that a system administrator knows about an impending disk space problem, well before a lack of space becomes a real problem, noticed by users. The way to prevent your systems from running out of disk space is to track this metric over time, on each of your systems, with an alert set up to warn of issues as soon as possible.
Despite a DBA's best efforts to measure and accommodate the predicted rate of data growth in their databases, there will always be periods of unexpected growth caused by rogue data loads, disabled log backups, runaway transactions, and more. While we can't prevent these issue entirely, we can ensure that we regularly monitor disk space and receive alerts of issues as soon as possible. Early warning of impending issues is important, as for most organizations adding disk space usually requires some lead time.
The following sections describe a few ways to track disk space, some of which are easier than others.
You could certainly check Explorer every day, like this:
Figure 3 – manually checking disk space in Explorer
And then track this data in an application, such as Excel.
Figure 4 – tracking SQL Server disk drive space in Excel
You could even expand your tracking to include the size of the disk, space consumption change as new rows are added, or really any mathematical calculation that Excel would support.
There are companies that track space manually, like this, but it's an expensive and error-prone way to use your system administrator and isn't what most administrators would prefer. Tracking disk space manually across many machines, and many months, quickly becomes a tedious chore. Humans aren't good at the sort of mundane, monotonous tasks of which this is a perfect example, at least not over a sustained period.
It is also prone to failure at multiple points. Will someone remember to perform this task every day? Will someone enter a typo for the space value? Are the alerts properly set across all instances and disks?
This is a task crying out for automation.
A quick Internet search will reveal all manner of scripts that you can use to automate disk space checks. Many of these use a scripting language, such as PowerShell or VBScript, to connect to various Windows hosts, measure the disk space, and then compile and email a report, highlighting any disks with space below a specified threshold level. Sean Duffy's article, Disk Space Monitoring and Early Warning with PowerShell, offers a typical example of what's possible.
This is a good system to put in place and indeed, you might combine this with Method 3; many administrators implement both a primary and secondary means of tracking and alerting on disk space, in order to have a safeguard in case one fails.
Of course, developing any scripted solution requires programming skills, as does maintaining it over time, for example to add tracking of additional disks. You may also want to store historical monitoring data for trending, which entails logic to archive and trim older data. Someone will want a report at some point, so you'll be developing those, perhaps endlessly as someone always wants to tweak report design. Downloading a script or writing a short program doesn't cost any money, but maintaining and adapting your system over time, testing changes, and more can add up to significant costs for an organization.
For many organizations, a more cost effective way of tracking disk space is with a monitoring tool, such as Redgate Monitor, which allows the administrator not only to set a wide range of alerts at configurable threshold levels, including disk space alerts. We can also view easily trends that might inform the administrator well in advance of the lack of disk space becoming a problem.
When you install Redgate Monitor, a number of alerts are enabled by default. One of these is the disk space alert, which tracks space on each disk mounted on one of your monitored servers. You can see your current space for your databases in the Analysis tab, with metrics tracked for each individual disk. In this case, I've drilled down to a single database, shown in Figure 5.
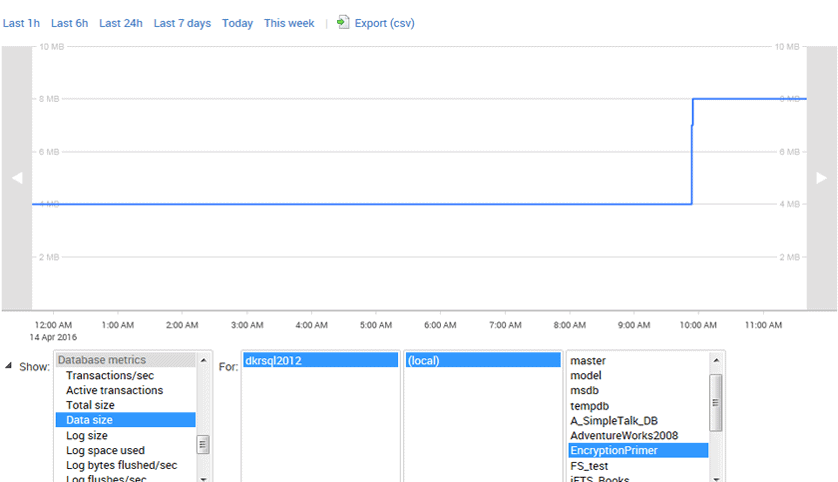
Figure 5 – data size graph for a single database in Redgate Monitor
We can see a spike in the size of the data file for the EncryptionPrimer database, which was caused by a large data load. A user decided to import a file that turned out to be much larger than expected. The data file would have grown more, but the disk filled before the load completed. This is a common situation that has happened in many organizations.
The power of monitoring space really comes from the ability to configure an effective "early warning" system, using alerts. By default, Redgate Monitor will raise a medium level Disk space alert when disk space falls below 1GB on any monitored server, as shown in Figure 6.
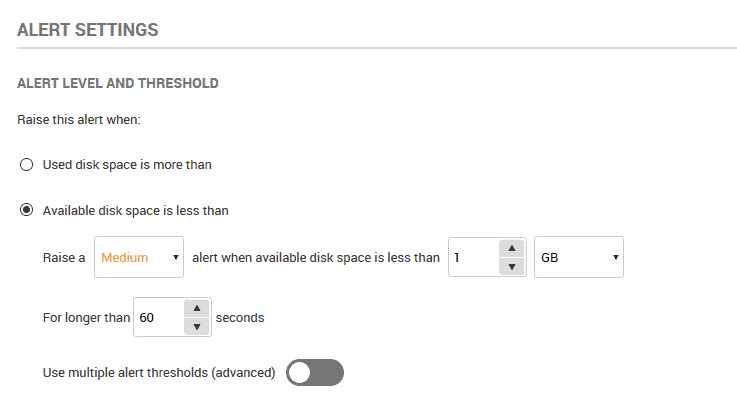
Figure 6 – setting the disk space alert threshold in Redgate Monitor
While this might work for some systems, I think I'd like to be aware well before disk space drops below 1GB. In a situation like this one, where an unexpected load takes place, I may not be able to respond quickly enough if I only know of the problem when so little space disk capacity remains. Ideally I'd like to be alerted when there is more time to add disk space and prevent emergency situations.
Fortunately, Redgate Monitor gives me flexibility. By activating the slider at the bottom of Figure 6, I can set multiple alert thresholds to let me know well in advance of any impending issues.
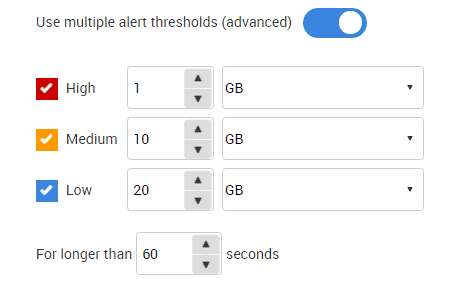
Figure 7 – setting multiple thresholds for the disk space alert
With these alerts set, I can begin planning how to make space, or expand current disk capacity, or order more disks, as soon as a Low level alert is raised. I'll also be sure that I have alerts on disk space emailed to the operations group. Running out of disk space is important enough to notify DBAs, especially for mission critical systems.
When one or more of these thresholds are breached, as happened when the user loaded a large file, I'll receive alerts, showing the object that caused the alert, the C: drive in this case.
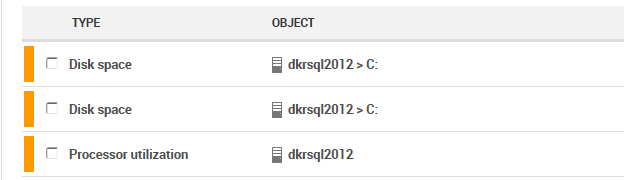
Figure 8 – disk space alerts for the C:\ drive
By clicking on the alert, I can see a detailed view of space used and available, as well as the space used by my local SQL instance. Most of the disk is user by other files, but the growth of this one database was enough to fill the disk.
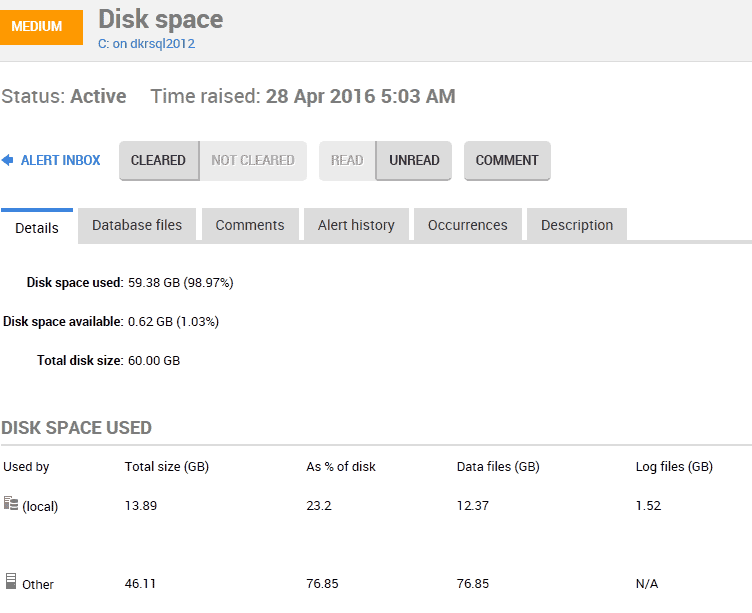
Figure 9 – drilling into a disk space alert to check the space being used
If I wasn't aware of the issue, Redgate Monitor does give me a way to investigate other metrics and processes, to determine what activity was occurring at the time of the issue.
Fortunately for me, I had taken the precaution of having some placeholder files on the drive, as discussed earlier, so I could remove the immediate problem by simply deleting them to allow further growth in the data and log files.
After that, I would speak with the user who loaded the files and reassess the amount of space this database needs in the future. I prefer to ensure all of my databases have enough space to handle the next 90-120 days of data growth, growing them every month or two in order to handle future needs.
I might also consider setting up more granular alerting of data or disk space for this database, for example by incorporating into my Redgate Monitor system one of the custom metrics available at SQLMonitorMetrics.red-gate.com
Running out of space on your laptop isn't a big deal. While it's annoying, most of us can find some extra files to delete. However, on a server, this can cause work to grind to a halt, and be extremely embarrassing for the system administrator. The goal is to avoid this type of issue altogether, via proactive monitoring, rather than reactively trying to delete files and free up space.
Generally, databases tend to grow at a known rate, so monitor the data and log space growth and watch out for abnormal trends and unexpected growths. I try to manually grow all files, choosing an increment that will allow the database to function for the next 3-4 months. When I grow files, I'll check the underlying disk space, but certainly having alerts is valuable in the event of unexpected growths.
I would also recommend that you 'reserve' a few 1GB files on each disk using placeholder files, which you can delete if space gets tight. The contig.exe utility from Microsoft makes creating these easy, and I'd encourage you to use it on all your disks.
Whether you want more details about Redgate Monitor, a demo or information on best practices – get in touch with us.

Redgate has specialized in database software for over 25 years. Our products are used by 92% of the Fortune 100. 200,000 customers rely on Redgate worldwide.

Redgate offers comprehensive documentation and a friendly, helpful support team. An average 87% of customers rate our support 'Excellent'.




