




Creating Multiple Masked Databases with SQL Provision
Sometimes developer teams need access to a copy of the database containing live data. However, if that database contains sensitive or personal data, then it cannot be used for testing and development work, unless all appropriate security measures are in place. The data protection regulations make no distinction between development and production databases, in the event of a data breach.
SQL Provision offers a lightweight, low-impact way to create 'clones' of SQL Server databases, for use in pre-production development and testing workflows. Each clone can be created in seconds, requires very little disk space, and can be consumed like any regular copy of the database. SQL Provision allows users to create custom-defined masking rulesets that will ensure that the data is protected, before it is delivered to the pre-production servers.
Previous articles have discussed how you can use SQL Provision to create and manage non-production database copies, and have demonstrated how to start automating the process of creating a database image, with the required masking rules applied during image creation, and then distributing 'compliant clones'. In this article, I'll extend those concepts to demonstrate how you can use SQL Provision to create masked copies of multiple databases, delivered as a group, for example when you are working with a Data Warehouse that contains several cross-database relationships.
The Problem
As a simple example of the problem, let's say we have two databases, DMDatabase2018 and DMDatabaseDW2018. They share the same structure, and store the same information, except that the former stores only the current year's data, and the latter also stores all previous years.
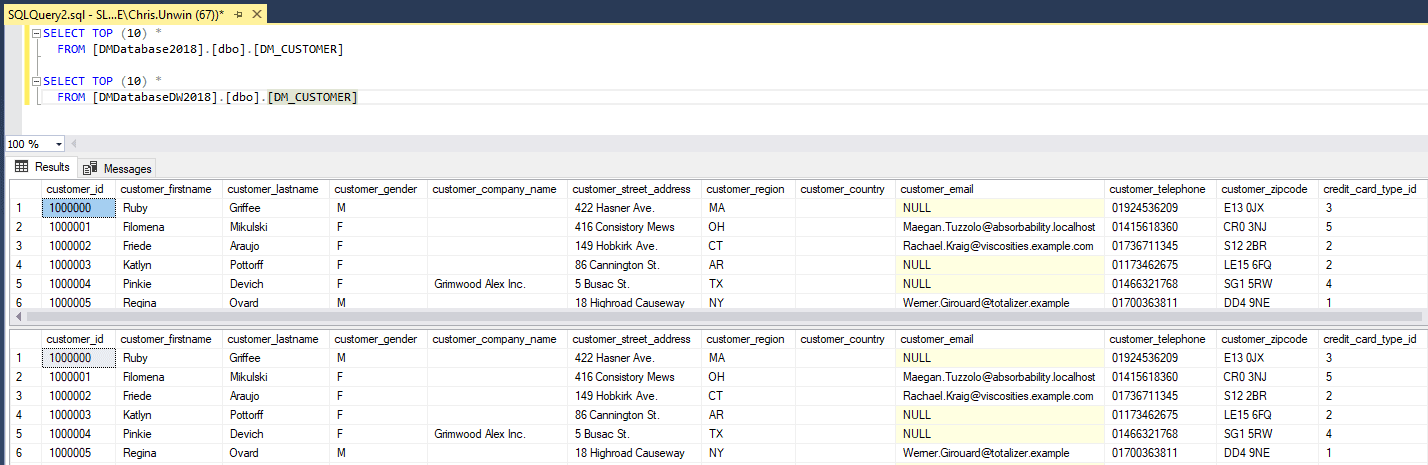
Figure 1: Customer Table in DMDatabaseDW2018 and DMDatabase2018
We need to deliver these databases to pre-production, as a group, with the data appropriately and consistently masked in each. How do we achieve this, given that SQL Provision can only capture an image of one database, at a time, with separate masking scripts applied to each?
The Approach
To solve this problem, we'll first have to restore temporary, full copies of each one to a secondary instance of SQL Server, so that we can connect to them in a physical location and mask each one consistently. This secondary instance will need to be secure. For example, we'd remove all non-essential permissions to this instance, before performing the restore, so that we limit any access to PII, in any state.
The subsequent data masking approach relies on data masker's support for cross-database, table-to-table synchronization rules. These allow us to copy the contents of a table in one database, masked according to the rules defined by the Rule Controller, and update the corresponding rows in a table in another database, so that the data is the same in each. Finally, we use SQL Clone to create the images of each of the masked databases and deliver clones of each one to our pre-production server.
The approach uses PowerShell to chain together each of the required steps in an end-to-end automated process.
Step 1. Restore the Databases
The first task is to restore temporary copies of the DMDatabase2018 and DMDatabaseDW2018 databases, from their latest nightly backups. We can do this manually, but I prefer to automate the process using PowerShell:
|
1
2
|
Restore-SqlDatabase -ServerInstance "[My Machine]\[My Instance]" -Database "DMDatabase2018" -BackupFile "C:\Program Files\Microsoft SQL Server\MSSQL14.SQLEXPRESS01\MSSQL\Backup\DMDatabase.bak" | Out-Null
Restore-SqlDatabase -ServerInstance "[My Machine]\[My Instance]" -Database "DMDatabaseDW2018" -BackupFile "C:\Program Files\Microsoft SQL Server\MSSQL14.SQLEXPRESS01\MSSQL\Backup\DMDatabaseDW2018.bak"|Out-Null
|
Listing 1
At this point, we can run the SQL Scripts to carry out immediately any additional processing of the databases, to prepare them for moving into a Dev/Test workflow. For example, we might remove Production level user logins and replace or remap them to the necessary Development permissions and logins.
Step 2. Run the Data Masking process
Now, we need to define a single masking set that masks the data in both the DMDatabase2018 and DMDatabaseDW2018 database, in the same way. We'll add a rule controller for DMDatabase2018, define the required masking rules, add an additional rule controller for each target database, DMDatabaseDW2018 in this case, and use a Table-To-Table rule to synchronize the masked data from the former to the latter database.
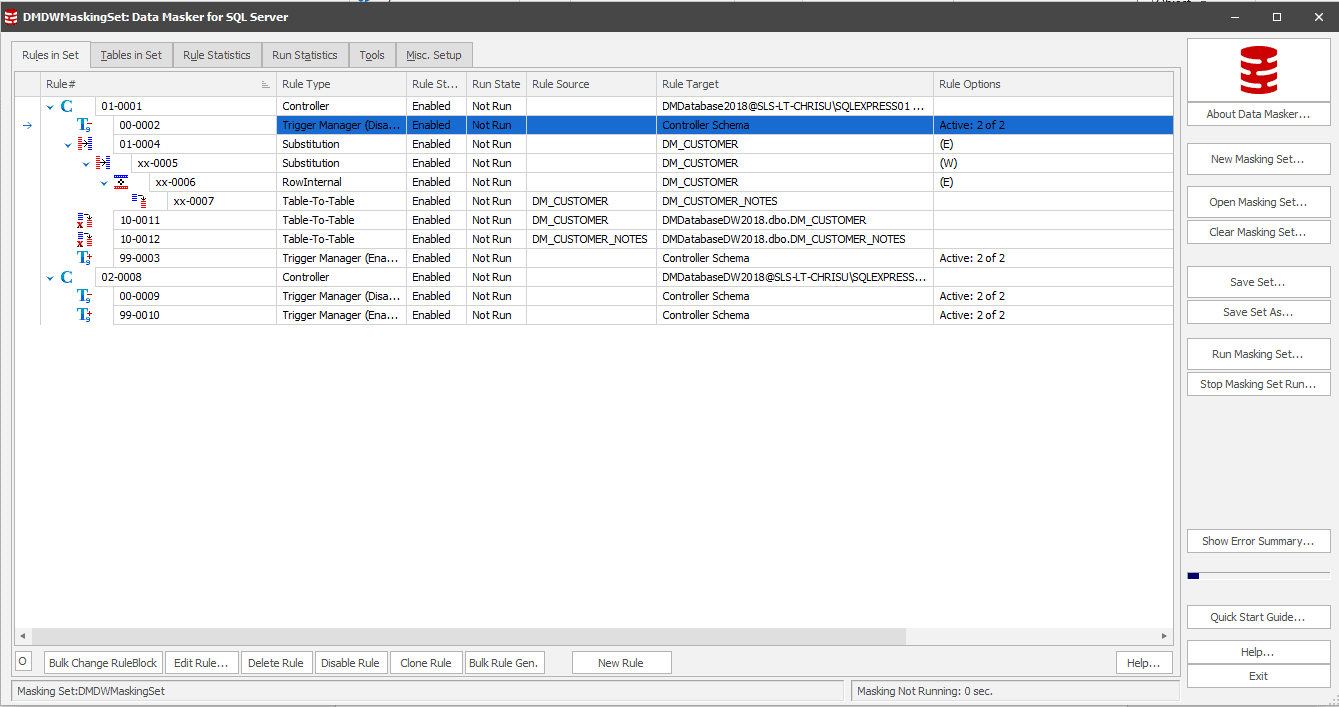
Figure 2: Using table-to-table synchronization rules in data masking
In Figure 2, we're using the table-table rules in Rule Block 10 to take the masking rules and synchronize them over to DMDatabaseDW2018. Note the additional Rule Controller for the latter database, in Rule# 02-0008. More information on setting up your masking set to connect to multiple schemas can be found here.
We can now use PowerShell to call Data Masker via the command line, using the "&" operator, and apply the masking set automatically, as soon as the previous restore stage completes. In Listing 1, I piped the output to null, which means that Listing 2 will only kick off once the database restores have completed.
|
1
|
& "C:\Program Files\Red Gate\Data Masker for SQL Server 6\DataMasker.exe" "C:\Users\chris.unwin\Documents\Data Masker(SqlServer)\Masking Sets\DMDWMaskingSet.DMSMaskSet" -R -X | Out-Null
|
Listing 2
Step 3. Create the Images and Clones
Having masked the restored databases, we can create the necessary images of each. We can, of course, do this manually through the SQL Clone dashboard, but again, I prefer to automate the process using the SQL Clone PowerShell cmdlets. Note in Listing 3 below I show only the 'bare bones' of the code, but you can easily build in your own error handling and so on.
|
1
2
3
4
5
6
7
8
|
Connect-SqlClone -ServerUrl 'http://[My Machine]:14145/'
$SqlServerInstance = Get-SqlCloneSqlServerInstance -MachineName [My Machine] -InstanceName [My Instance]
$ImageDestination = Get-SqlCloneImageLocation -Path '//[My Image Path]'
$ImageOperation = New-SqlCloneImage -Name "DMDatabase2018"
-SqlServerInstance $SqlServerInstance
-DatabaseName 'DMDatabase2018'
-Destination $ImageDestination
Wait-SqlCloneOperation -Operation $ImageOperation
|
Listing 3
Figure 3 shows the SQL Clone dashboard, with the newly-created images of our obfuscated databases.
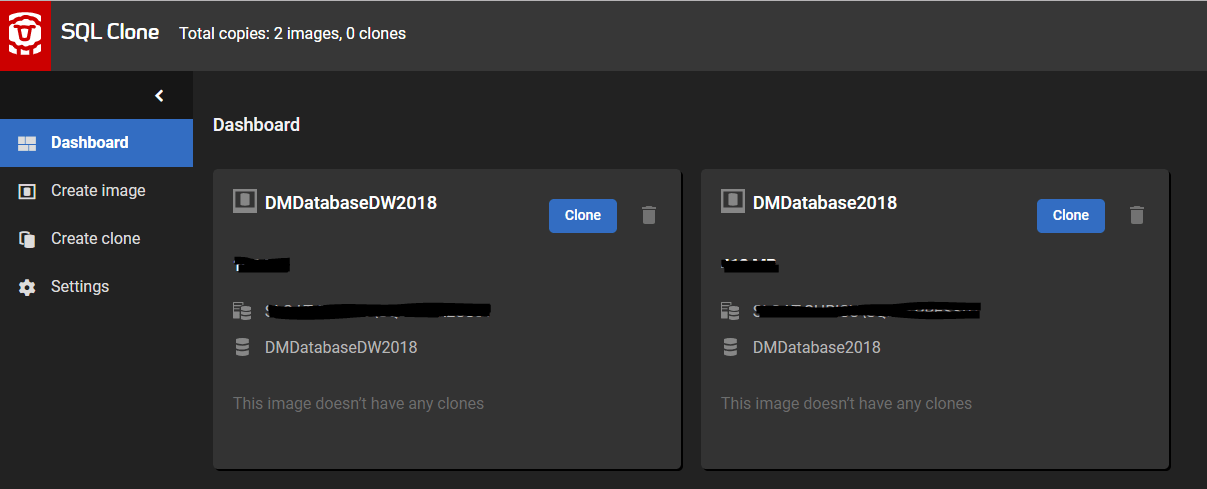
Figure 3: The SQL Clone dashboard displaying the consistently-masked images
Finally, we drop the temporary database copies, using the sqlps module, then create clones of each image on the required development and test workstations.
|
1
2
3
4
5
6
7
8
|
$server = New-Object Microsoft.SqlServer.Management.Smo.Server("[My Machine]\[My Instance]")
$server.databases["DMDatabaseDW2018"].Drop() | Out-Null
$server.databases["DMDatabase2018"].Drop() | Out-Null
$Image1 = Get-SqlCloneImage -Name 'DMDatabase2018'
$Image2 = Get-SqlCloneImage -Name 'DMDatabaseDW2018'
$SqlServerInstance = Get-SqlCloneSqlServerInstance -MachineName [My Machine] -InstanceName [My Instance]
New-SqlClone -Name 'DMDatabase2018_Dev_Chris' -Location $SqlServerInstance -Image $Image1 | Wait-SqlCloneOperation
New-SqlClone -Name 'DMDatabaseDW2018_Dev_Chris' -Location $SqlServerInstance -Image $Image2 | Wait-SqlCloneOperation
|
Listing 4
Conclusion
The approach I describe in the article can ensure consistent masking across a group of databases that we need to deliver into Development and Testing. When we need to query data from multiple sources, we're able to do so in a way that is repeatable, automated and never compromises on the security of our Personally Identifiable Information.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
You may also like

Article
SQL Provision offers users an easier way to manage, organize and make available masked copies of databases
Rebecca Edwards premieres the new SQL Clone 3.0 dashboard, and explains new features to make it easier to manage clones, view recent activity on them, and reset clones with the push of a button.
Article
New permissions features brings access control to SQL Clone
SQL Clone permissions give you simple control over who can access SQL Clone, and what they can do with it.

Article
How SQL Clone and SQL Change Automation enable seamless Database Branch Switching
Learn how SQL Clone and SQL Change Automation, used together, now allow you to branch your database in Git as quickly and simply as your code.
Article
How to create and refresh development and test databases automatically using SQL Clone and SQL Toolbelt
A PowerShell automation script to build a SQL Server database from source control, seed it with dummy data, document it, and then deploy copies to any number of test and development servers.

Article
Bloor 2019 Market Update for Test Data Management lists Redgate as an innovator
Bloor has published its 2019 Market Update for Test Data Management, listing Redgate as an innovator, and scoring SQL Provision 4.5 stars out of 5 for test data provisioning. If you’re not familiar with Bloor, it’s an independent research and analyst house founded to help organizations choose optimal technology solutions. As database teams grapple with shortening release cycles and tightening data protection laws, the need to deliver realistic and compliant test data to development quickly and safely is greater than ever. Choosing the wrong approach can hamper development, drive down quality, risk non-compliance, and lead to escalating infrastructure costs. In this
Article
Running SQL Clone on an Azure VM with Azure File Storage
How to use SQL Clone in the Azure Cloud, installing it on an Azure Virtual Machine, storing a copy of your SQL Server database as an 'image' on an Azure File Share, and then deploying multiple clones to another Azure VM or to a remote machine.
Loading comments...