





Getting your SQL Server Development Data in Three Easy Steps
If you just need to copy the data from one small SQL Server database into another, it is a relatively simple task, assuming the table structures are nearly the same in both, of course. If you are copying from a database with production data, then you'll also need to replace all the sensitive data with fake, spoofed values, before copying in the data. When you need to test for performance, you will need to expand the amount of data in some tables, by generating additional fake rows.
This article will demonstrate these three different tasks: straight copying, copy and masking, and finally increasing the table size using purely generated data. The advantage of copying data by having every table initially take its data from an existing, reference database is that, once you've saved it as a project, you can then use a copy of this project for the 'anonymized' version and then another for the third, generated version. After all, several tables in the typical database are just reference data and the data may not need to be changed. It also allows you a more gradual approach to entirely generated data, doing it a table, or a group of tables at a time.
I'll show how to do all this using SQL Data Generator (SDG). We'll set up an SDG project for copying the data from one database to another, and then use that as a basis for a second project that replaces all the personal and sensitive columns with generated data, every time you copy the data. Finally, we'll amend this SDG project to expand the amount of data in any table, using its various generators to provide all the extra rows of data.
By its very nature, SDG removes the data that is already there in the target database, so it is ideal for repetitive tests that require the database's data to be set up and torn down. Once you have a system working, you will then want to automate the whole process, so you can get on with something else while it copies data to as many databases as you need. I won't cover the automation part here, but you can refer to: Automatically build-and-fill multiple development databases using PowerShell and SQL Data Generator.
Generating realistic development data for the Pubs database
We'll use the old Pubs database to demonstrate all this because it is so small that you can follow along if you want. First, we use this script to create our reference database, called Pubs, and then create all the tables (it's the same as the original Pubs except I had to widen a few columns to accommodate more realistic test data). We'll pretend that this is our reference database, representing the production release. We can then use this script to insert the data from the original Pubs database. Now, we need to create a database with a different name, such as PubsTest, on the same, or another, server, using the same build script. We don't need the data for this one so, we can just use the build script that we used to create Pubs.
Copying the data from one database to another
We'll start by using SQL Data Generator to copy a database's data. To do this, we set it to use our new PubsTest database. We see that it lists the tables. We need to select them all.
On the right-hand pane, we see the Authors table ready, with a form asking us how we want to do the data generation. We select 'Use existing data source'. This means that an existing, populated table, in a database somewhere, should be used as the source.
The defaults for using the data source are all fine so we click the Browse button and enter the credentials for the server where the source of our data is located, Pubs in our case. If you are using SQL Server Security, be sure to click on 'Remember Credentials' otherwise all goes sour later.
The following screen allows you to specify the table from which to grab the data, but generally the application finds it for you. Finally, you'll see a preview of the Authors table in PubsTest, populated with data from Pubs.
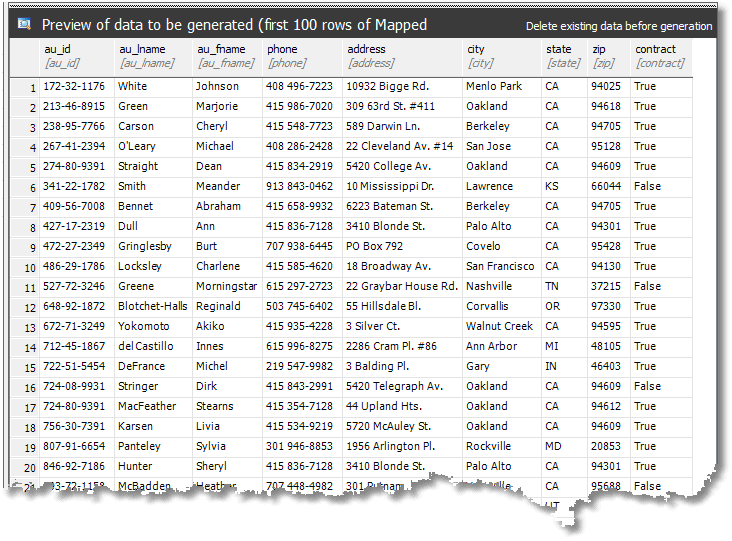
Under each column name is the name of the generator used for that column. If the source of the data for a column is simply a column in another database, as is the case here, then they appear in square brackets.
Now we just repeat this for all the tables…I know, there should be a button that does the mapping for us, but there isn't, because we're doing things that were never really intended by the designers of SQL Generator. The default column matches are almost always right so it is a matter of repetitive clicking while listening to a good music track and remembering that this is a once-off chore.
OK: here's one I prepared earlier…
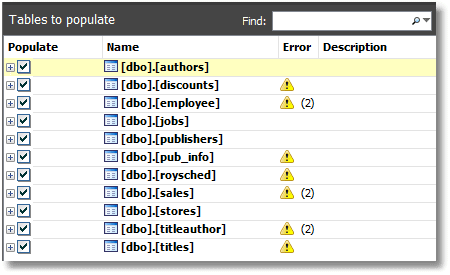
There are several warnings, you'll notice. This is OK, because they concern fields that contain FOREIGN KEY constraints, and reference other tables. SQL Data Generator will cope with this because the references are all intact: after all, we've imported all tables as-is. At this stage, we're going to avoid specifying any other generations.
If we now opt to generate the data (Ctrl+G), it all works fine, and we can then check that the data is identical, using SQL Data Compare (as we're using the original version, discounts and roysched couldn't be compared as they don't have PRIMARY KEYs).
Hang on, we've got another couple of databases that need doing. No problem. We click on the menu File - Edit Project - database and use the database tab to change the database. Basically, you can copy the data from a reference database to any number of target databases. Beware that this is much slower than doing a native BCP copy, but it is often a lot more convenient.
You can run an existing project, like the one I've just created, in the command-line using either a batch process or using PowerShell. I've described, in Automatically filling your SQL Server test databases with data and in Automatically build-and-fill multiple development databases using PowerShell and SQL Data Generator, how to use PowerShell scripting to do this for you. The only difference is that this time we are just copying the original data rather than exquisitely faked, spoofed data.
At this point, you can save the project as something like PubsTest_CopyOfPubs. In general, I'd really recommend that you save the project frequently as you work along. It is quite easy to make a mistake that requires you to retreat to the previous backup.
Replacing personal and sensitive data
It is at this point, as we reflect smugly on a job well done, with our database builds being filled with data, automatically, that someone reminds us that we can't use production data for our development work without anonymizing it. The publishers won't like it and the employees would sue if there was a breach. We need to disguise the data sufficiently that it passes muster as anonymous data. I explain all the issues in 'Masking Data in Practice'.
OK. The first thing to do is create a copy of the previous project (call it something like PubsTest_AnonymizedPubs). The first thing to go must be the titles and especially the notes about them, because the publishers would be recognized. Because the table is still assigned to the corresponding table in the Pubs reference database, SDG will choose the corresponding columns, by default, but you can override individual columns with one of the other generators. We will anonymize the publisher and notes columns using generated lists of fake titles and fake notes as the source, because that takes the least effort. We'll generate these lists in PowerShell, though it is also possible to do it in SQL.
To follow along, you'll need the PowerShell script, Get-RandomSentence.ps1, which contains the functions that generates random strings from a list of strings, and a helper function that converts a string to a title while applying title casing. You also need the JSON-based phrase-bank, HumanitiesPublications.json, from which the random titles and notes are generated. If you store this JSON file in the same directory, you can then generate the two lists very quickly by using this, saving the resulting lists in text files (BookTitles and NoteAboutBooks) in your home documents directory.
Here's a sample of the generated titles:
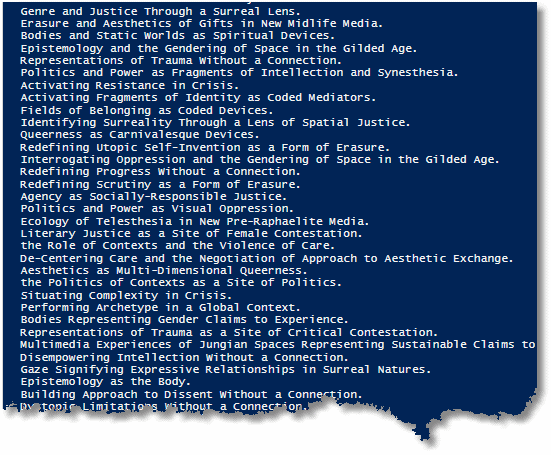
We simply generate as many titles as we want and save them to a text file, one to a line. A lot of the time, it is sufficient merely to use a file-based list but where you have to mash up phrases to give a certain verisimilitude to text-based data, then a phrase-bank is better. However, there are many ways to do all this, and SQL Data Generator gives you plenty of alternatives. The important point here that leads us to use a JSON-based phrase-bank is that we want each title to have a unique name, so we need a generator with a pretty wild variability, if we want thousands of titles.
And to provide notes for the titles we use the same phrase-bank, but with a different entry-point

Anonymizing book titles, types, and notes
Now, we feed these fake titles into our titles table, in PubsTest, using SQL Data Generator. We click on the title column, switch its generator to a File List and browse to wherever we saved the BookTitles.txt file. Then we do the same for the Notes column, taking the input from the file-based list in notesAboutBooks.txt. The other columns should, at this point, be unchanged.
Then we need to change the type of book. We don't need anything quite so elaborate so we can simply choose SDG's Regex Generator (in the Generic section) and do it with this simple reverse-regex expression (see this article, for a basic explanation of how reverse regexes work, if you're new to them, and struggling):
Architecture|Arts|Art and Design|Biomedical Sciences|Biography|Business|Business, Economics and Law|Cognitive Sciences|Computer Science|Crime and Thrillers|Cultural Studies|Design|Digital Humanities & New Media|Economics|Education|Engineering|Environment|Fiction|Food and Drink|Game Studies|Graphic Novels|Health and Wellbeing|History|Humanities|Information Science|Linguistics & Language|Mathematics & Statistics|Medical and Nursing|Neuroscience|Philosophy|Science, Technology & Society|Social Sciences|Technology and Transport|Travel|Urbanism
We now get this preview, and you'll see that for generated columns, SDG no longer encloses the names of the source in square brackets:
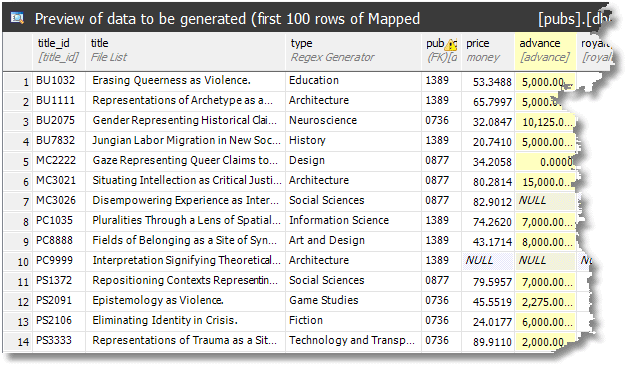
Anonymizing keys
Now, we're going to have to scrabble the primary key of the titles table, titleid. It is a six-character unique string. The reason that we must change it is that it has the first two characters of the publisher in the key which could leak some data.
We set the generator for this field to be the regex generator, and it figures out without our help that we need the whole field to be filled with ASCII characters or digits. The expression is:
[A-Z0-9]*
And we need it to be unique with no nulls. This is important for all PRIMARY KEYs for which you specify a generator.
We've set the FOREIGN KEY fields to take their contents from the actual data, so we need to change each foreign key field that references this title_id to use the 'Foreign Key (automatic)' SQL Type generator. In fact, we're going to change every foreign key field to use this generator, except job_id which needs to continue to refer to Pubs (see the next section).
SQL Data Generator flags each of these fields with a warning triangle, as we saw earlier, so they are easier to spot.
Anonymizing employee names
We can now anonymize the employee table. The table is still assigned to the corresponding table in the Pubs reference database, but simply click on the name of the column and you can pick from SDG's list of alternative generators, for each column. The ones in the Personal section are good for this table. If you get stuck, it might help to create a separate SDG project, pointing at an empty copy of Pubs, and just let it generate all columns. This way you can see what generator it chooses, and use the same, if it's appropriate.
It will need a few tweaks. It thinks, for example, that fname means 'full name' rather than 'first name'. I changed the hire dates to something more convincing by using the 'DateTime' SQL Type Generator. Note that job_id and job_lvl should be left to refer to their respective columns in the Pubs database, due to the presence of the employee_insupd trigger that makes sure that the job level values are appropriate to the job.
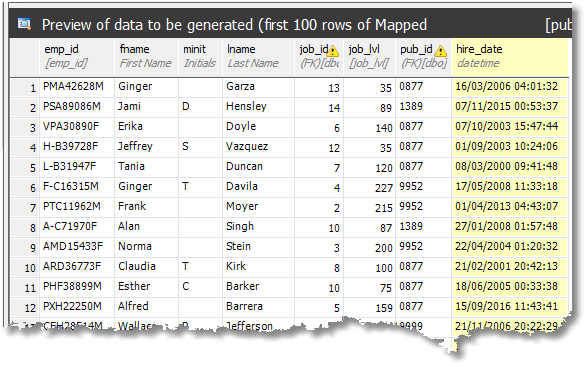
Anonymizing author names and addresses
For the authors table, the built-in generators in the Personal and Geographical sections will let you anonymize the name and address columns. I've also explained how to generate some realistic addresses here: Generating test data with localized addresses using SQL Data Generator.
Anonymizing publisher names
The names of the publishers need to be changed too. There seems to be no pattern in the way they are named so we can quickly use a reverse-regex like this:
(Libris|Pustaka|Leabbar|Biblio|Adlis|Kitabu|Signi|Kirja|Livre|Boku|Libro) (Academic|Clinical|Medical|Technical){0,1} (Publications|Books|Guides|Services|support|Communications|Press|Editions|Promotions|dielectics|book services|publishers) (International|Products|Corporation|||){0,1}
This gives us the following, for pub_name:
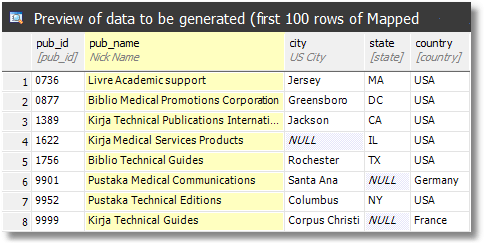
Anonymizing images and text in Pub_info
We carry on with this process with the database until we can be certain that nobody can identify an individual via an inference attack. We'll just have to remember not to make any further changes in the way that the data in any PRIMARY KEY fields is generated without changing the FOREIGN KEY fields that reference it to the 'Foreign Key (automatic)' SQL Type generator.
The Pub_info table provides a wonderful illustration of what can go wrong with an anonymization, and why it can never be entirely automated. I could have gone through the database with all sorts of search tools and never discovered that all the original names could be pulled out from image data. In this case, in this fictitious example, it is only the names of the publishers, but avatars stored in a database can provide a rich source for inference attacks. I've seen XML fields in supposedly-anonymised databases with enough personal data in plain sight that many individuals could have been identified.
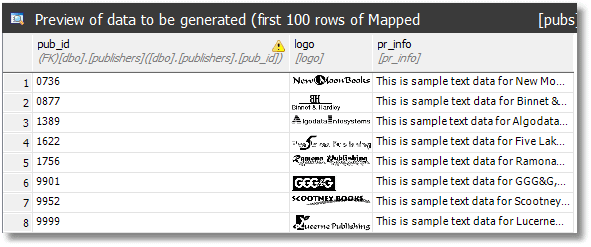
We put this right. Here, I've used SQL Data Generator's image SQL type generator for the image.
For the publisher information (pr_info), I've used a Reverse Regex. A JSON-based phrase bank would have given a better result for the latter because you can see that there is still a peculiar feeling of falsehood in the publisher blurb, which I realise is somewhat authentic but nevertheless overdone.

The reverse regex expression was …
(For many years, we have gained a reputation as a publisher that |We have rapidly established ourselves as a|It is due to our deep knowledge of the subject matter that we've grown into a|We have become known as a publisher that|Without doubt, we are a|A leading publisher of international academic research in science, the Arts, humanities and social sciences, We are a|publishes in both print and electronic formats for the trade, professional, college, scientific, and technical marketplaces worldwide, we are a|In a highly-competitive market, we are a|We engage with the public and policy makers to increase awareness of scientific issues in society as a|We are a|We are a) (New|fast-growing|independent|major|global|world-leading) (publishing house|Publisher|publishing company|publisher|provider of professional information solutions) (producing|publishing|that publishes the best in) (books, |print, |online journal collections, |magazines, |academic journals, |monographs, |reference works, |Scientific communications, |specialist academic texts, |monographs, |textbooks, |academic books for the general public, |textbooks, |English-language teaching, ){3,5}fiction, and non-fiction. This includes (politics, |popular science, |psychology, |philosophy, |history| world religions) and general science.
We (deliver superior information services that foster communication, build insights, and enable individual and collective advancement our topics|exclusively commission leading specialists and award-winning writers|Have an unrivalled combination of professional know how and the personal touch, |work with our authors and deal with customers, |help authors develop and publish high-quality, saleable books, |provide a Professional in-house design and printing service, ){1,2}and generally work closely with our society partners, authors, and subscribers. We also offer (exceptional editing, design, printing, publishing, distribution and book marketing services|a detailed and expert assessment of your manuscript|a commitment to our authors who require a holistic approach|provide research to understand what sort of approach works best|bring together people and organisations to develop ideas|measuring the outcomes of our products)
We (engage with policymakers and the general public to develop awareness and understanding of the value of the subject|are a small family business|deliver to the widest possible audience|constantly go from strength to strength with the help of the wonderful people we work with|have an unrivalled combination of professional know how, the personal touch|are a world-class professional organisations with offices in many countries)
We've now reached a point where we could, if the original data were real, do development work without any security issues.
Increasing the size of the data
Up to now, we've been teaching SQL Data Generator to do new tricks, but this next task is nearer to its comfort zone. We want to go a bit further with our changes and allow some of the data to be entirely generated, so we can have more of it for testing. We don't need to do it for every table, since some of them are more like reference data.
Before we can get to the point that we can calmly and simply specify the number of rows we want in each table, we first need to remove any dependency between that table for the corresponding table in the reference version of the database, Pubs in our case. Before you start, save a fresh copy of the project, and call is something like PubsTest_CopyAndGenerate.
1000 titles
We start with the titles table and we'll generate a thousand publications. To do this, click on the titles table and, leaving the source as the existing data source (i.e. Pubs), change the table generation settings so that Specify number of rows by is set to Numeric value and choose 1000 rows.
Next, we need to break the link between the tables and the database that is supplying the data. We've already done a lot of the hard work for this table, when we anonymized the title, notes, type, and title_id columns, earlier. For the rest, we just click on each column that is still referencing Pubs (as indicated by the square brackets around the source) and choose a suitable generator. We need to choose 'Foreign Key (automatic)' SQL Type generator for pub_id. The rest of the columns are quite easy because the fields are either money or integers and we can work out the ranges and so on from the original data.
A few minutes later, we have a table with a thousand titles. We have a few duplicates, and "Erasing Identity as a Form of Erasure" is for some reason, surprisingly popular. It is a matter of fine-tuning, but if you are developing and/or maintaining fewer than a handful of databases it is a job worth refining as you will only ever need one title generator.
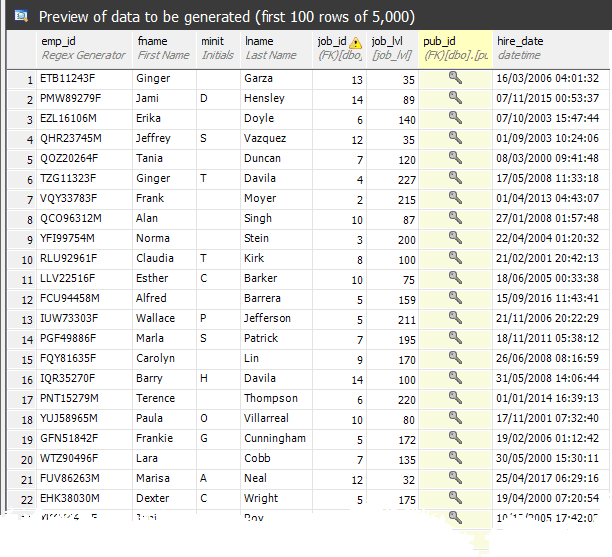
5000 employees
We turn to the employee table. Again, we dealt with the name columns earlier, so now we just need to change the source of emp_id to be a Regex Generator (as for title_id, earlier). The job_id should continue to reference the source database, and pub_id can use 'Foreign Key (automatic)'. Now just choose to generate 5000 employees, which seems about right. Here is the preview pane ready to let us increase the number of rows:
More authors
We need plenty of authors, around the same number as books, I reckon. The au_id has a CHECK constraint that requires you to use three numbers followed by a dash, followed by two numbers, then a dash, ending with four numbers. When you switch to a Regex Generator, for this column, SDG automatically suggests a reverse regex of:
[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9]
However, we could equally use the slightly tidier:
[0-9]{3}-[0-9]{2}-[0-9]{4}
The number in curly brackets is the number of times it must generate the digit.
Finally, we also fix the titleAuthor table by assigning both foreign key references to the 'Foreign Key (automatic)' SQL Type generator.
Testing it all out
Save the project a final time, hit Ctrl+G and we can test it out.
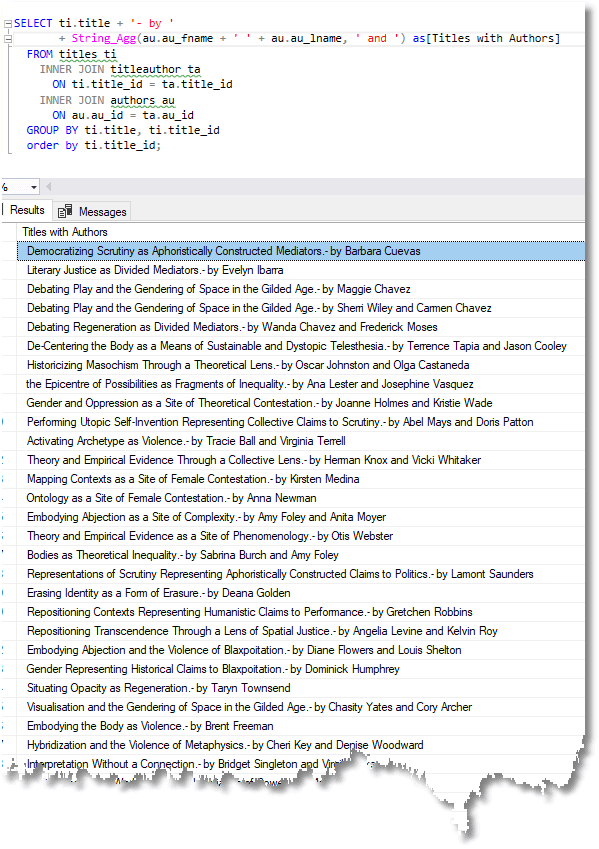
Yes, a thousand titles along with their authors. This is a continuum: we can add more publishers and so on, as needed.
Summary
Sometimes, the task of generating an entire database is just too daunting. It is much less stressful to start by just copying the existing data first by assigning every table to get its data from the same table in your reference copy of the database. Then, if it is data from and existing production version of the data, you immediately anonymize any personal or sensitive data. Finally, when it becomes necessary, you choose the data to generate entirely to expand the number of rows. You do it bit by bit, as the need arises.
This doesn't remove entirely the need to build your databases from source and populate them via native BCP, but it kicks the inevitable down the road, and you end up with a generated dataset which is great for different types of testing. It isn't fast, but if you save the data to file until you make table-level changes and postpone your data-generation until then, you get the best of both.
Tools in this post
You may also like

Article
Realistic, simulated data for testing, development and prototypes
Generating realistic test data is a challenging task, made even more complex if you need to generate that data in different formats, for the different database technologies in use within your organization. Dave Poole proposes a solution that uses SQL Data Generator as a ‘data generation and translation’ tool.
Article
How to Automatically Fill your SQL Server Test Databases with Dummy Data
A PowerShell script to automatically populate a SQL Server database with dummy data, for database development and testing work.

Article
Customer tips for improving productivity with Redgate products
We recently invited our customers to share their top tips for improving productivity in the first Redgate Tool Tips Swap. This post outlines their hints for using Redgate products to boost productivity and includes relevant training resources to further your learning. SQL Prompt Share formatting settings across your team to consistently format code before checking it into source control. Justin Bird, Principal Consultant, Metricy UK. “We keep ours alongside the code in source control so everyone can keep up to date. Adhering to code formats ensures ‘developer preference’ doesn’t result in false changes in the code base where a developer
Article
Pseudonymizing your data with SQL Data Generator
Starting from a database view, as the basis for a typical sales reports, Phil factor shows how to generate a data-masked version of this report, which the Tax Men can safely pore over.
Article
Generating test data in JSON files using SQL Data Generator
Phil Factor shows how to use SQL Data Generator to produce as much pseudonymized data as you are likely to need for your testing, and then convert it to JSON so that you can also use it to test your MongoDB and Azure Cosmos databases, or to test out a new web service.
Article
Pseudonymizing a Database with Realistic Data for Development Work
How to use SQL Data Generator, and PowerShell to obfuscate personal data (names), while retaining the same distribution of data, so that the test database behaves like the original.
Loading comments...