Generating realistic dates using SQL Data Generator and Python
How to generate more realistic dates, in your SQL Server test data.
When you’re generating test data, you have to fill in quite a few date fields. By default, SQL Data Generator (SDG) will generate random values for these date columns using a datetime generator, and allow you to specify the date range within upper and lower limits.
This is fine, generally, but occasionally you need something more. What if the date in a column has to be greater than a date in another one, by some varying interval? What if a date must be the same as a previous date, if the date in a third column is NOT NULL? There are plenty of examples where what SDG provides just isn’t quite enough.
This article will show how to exert more control over the test date in your date columns, using SDG’s Python Generator, where a Python expression or Python program provides the value to use to generate the SQL value.
If you’re unfamiliar with SDG, I recommend you read the following pieces as well:
- How to start producing realistic test data with SQL Data Generator – gives a basic tour of the tool, introduces the
Customersdatabase that we use here, and shows what data SDG generates for each of the columns, by default - Generating test data with localized addresses using SQL Data Generator – tackles the problem of producing realistic, localized addresses using regular expressions
SDG date generation out-of-the-box
Firstly, download and run the script to create the Customer database. If you’ve already created a previous version of the database, while working through any of the above articles, it’s probably easiest to drop it and recreate it using the referenced script, point SDG at it and generate fresh data.
If you have a previously saved SDG project, it will still work, assuming the new database has the same name and connection details. If not, you can right-click the project file, open it in EditPad (or similar) and edit the XML to point at your new database.
Figure 1 shows the auto-generated data for the NotePerson table, a simple table that connects a customer with a note. Customers can have many notes, and notes can apply to many customers.
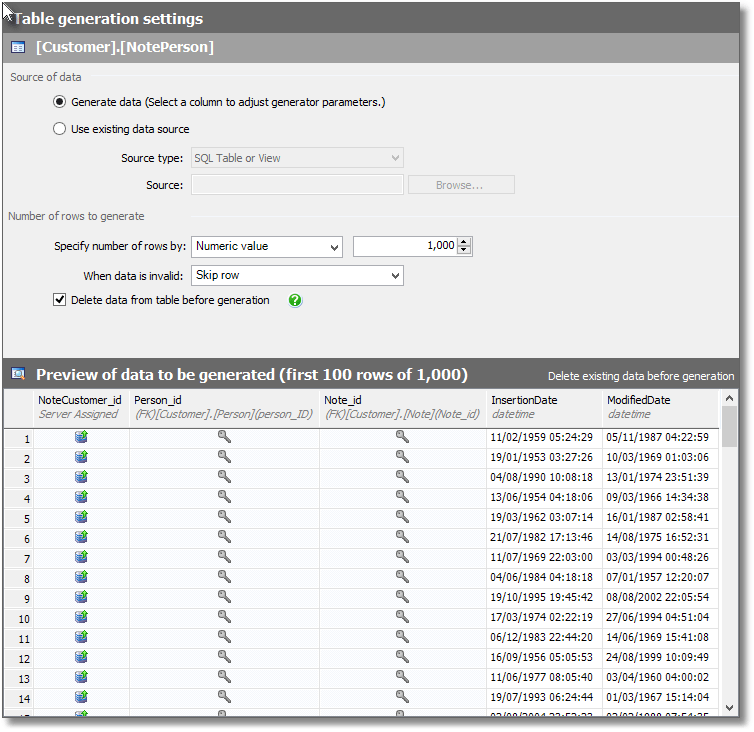
Figure 1
The problem is in the default values for the date columns. The InsertionDate needs to start within the last five years, but that is very easy to fix using the supplied Min and Max date ranges.
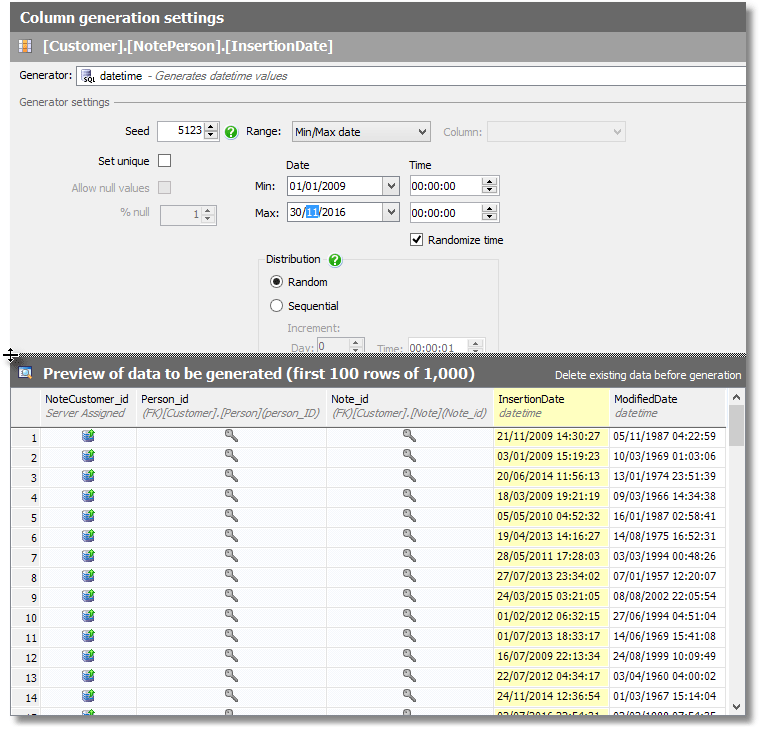
Figure 2
That’s better, but now the ModifiedDate column is wrong; each of the date values in this column need to be some random interval after their respective insertion date.
One option is to use choose Offset from column from the Range: dropdown, then specify an offset from the InsertionDate column, of between, say, 1 and 1,000 days. That would work well enough in this simple case, but you’ll see that while the allocation of dates after the start date is random, its distribution is uniform – there is an equal chance of any particular value being returned.
This isn’t often realistic; you’re more likely to see a normal (‘bell shaped’) distribution in real production data. Let’s see what is possible using custom python scripts, as this allows us to create more realistic distributions of data that conform more closely with the way production data behaves.
Working with the SDG Python generator
I’m not really a Python programmer, and I don’t know many DBAs who use Python either, but I had little trouble getting all this to work because there are loads of Python examples on the Internet that can be adapted for use.
SDG was designed for a previous version of Python (2.7), but my Python install is up-to-date (v3.5.2 at time of writing). This means that some of the examples provided for SDG won’t work unless you have installed only the older Python libraries (2.7), because Python made breaking changes between the two versions.
As such, in the following scripts I stuck to what’s possible with Python when using only the .NET python libraries. This is necessary anyway when manipulating SQL Data.
Installing or Upgrading Python
If you don’t have Python, or need to upgrade to the latest version, I recommend use of Chocolatey. You can install it from PowerShell (running as an administrator). After that, using Chocolatey to install Python (or anything else) is as simple as issuing commands such as ‘choco install python’, or ‘choco upgrade python’.
You may see a few ‘python script timed out for row’ error warnings in the SDG UI, on the columns that used these Python 3.5.2 scripts (I did). They tend to pop up on reopening a SDG project, when SDG regenerates the preview data. Generally, just clicking on or in the offending columns removes the error warning after a few seconds.
Using the Python generator for dates
To fix the ModifiedDate column in the NotePerson table, I go to my collection of Python templates and choose one that seems most similar to what I want. Here, I wanted the modification date to be at a date that is normally distributed at an average of 720 days after the entry was made but with a standard distribution of 200 days. Real data is often normally distributed.
I’ve chosen a simple way of doing this but there are plenty of faster and better ones around such as the Box-Muller transform. I’ve added the twist that if the result is in the future, or before the record was created, I use a NULL instead.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from System import Random random = Random() def main(config): StandardDeviation=200 #days Mean=720 #days DaysAfterwards= random.Next(- StandardDeviation,StandardDeviation)+random.Next(- StandardDeviation,StandardDeviation)+random.Next(- StandardDeviation,StandardDeviation)+Mean EndDate= InsertionDate.AddDays(DaysAfterwards) if DateTime.Now<EndDate or EndDate<InsertionDate: EndDate= null return EndDate |
Listing 1: Python Script for ModifiedDate column in NotePerson table
I paste it in and away we go; we now have dates for modification of the record that are after the date of insertion, and look realistic, as shown in Figure 3. The important point here is that I’m able to reference the values in other columns in Python expressions.
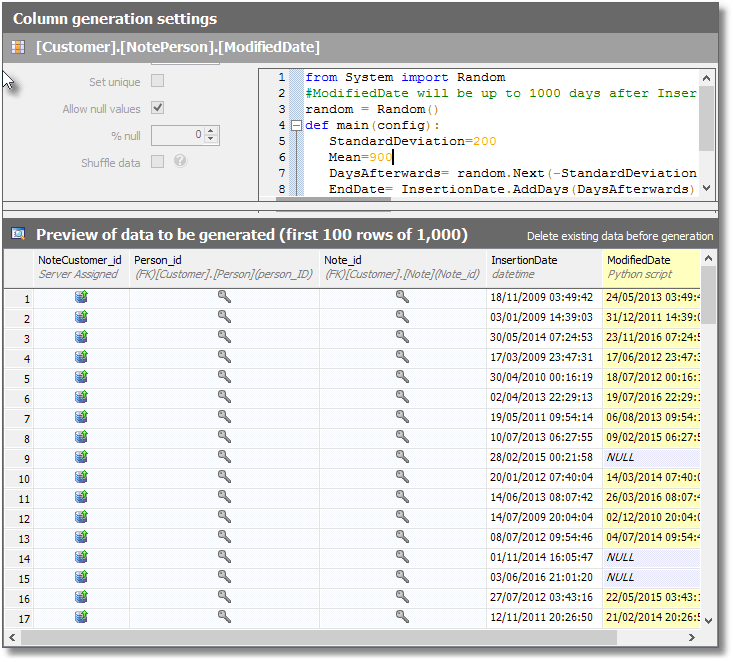
Figure 3
Next, we need to fix the date columns in the Phone table, which is similar but provides the link between customers and phone numbers.
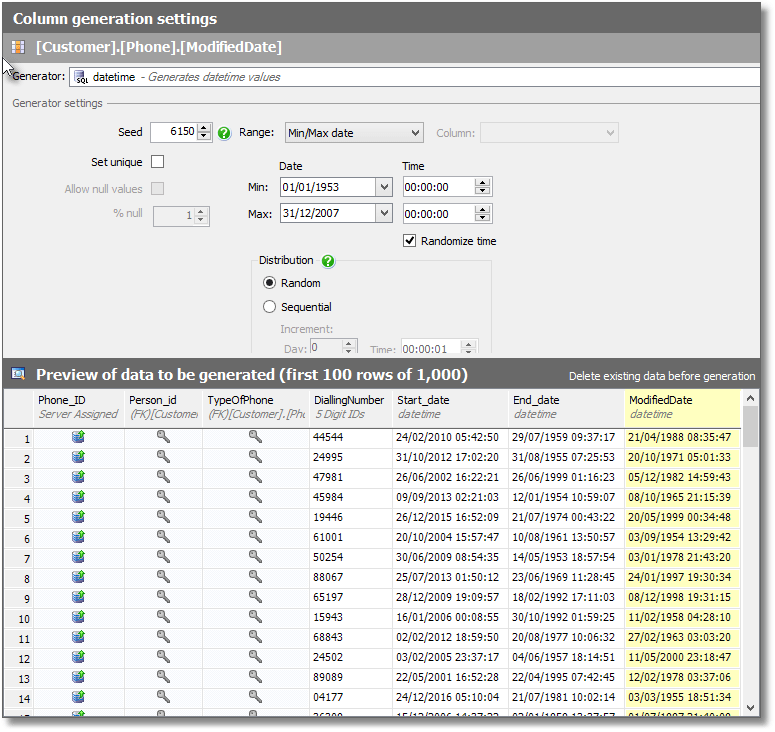
Figure 4
We have a Start_date column and an End_date column. We can adjust the range for Start_date, as before. The End_date values must be after the Start_date values, of course, unless the phone number is still current, in which case the entry must be NULL.
Again, we could probably handle this case by defining the End_date column values as an offset from the Start_date column values, and also by increasing the proportion of Null values in the generated data for End_date.
However, let’s use a python solution instead, as shown in Listing 2.
|
1 2 3 4 5 6 7 |
from System import Random # End date is either NULL or after the start random = Random() def main(config): EndDate= Start_date.AddDays(random.Next(1000)) if random.Next(10)>5: EndDate= null return EndDate |
Listing 2: Python Script for End_date column in Phone table
Here we have a script that imports the Random class from .NET, creates a random number generator and then creates an end date that is between 0 and 99 days after the start date. Half of the resulting rows use a NULL instead.
Paste that into SDG as the script for the python generator to use, and the results should look similar to those shown in Figure 5.
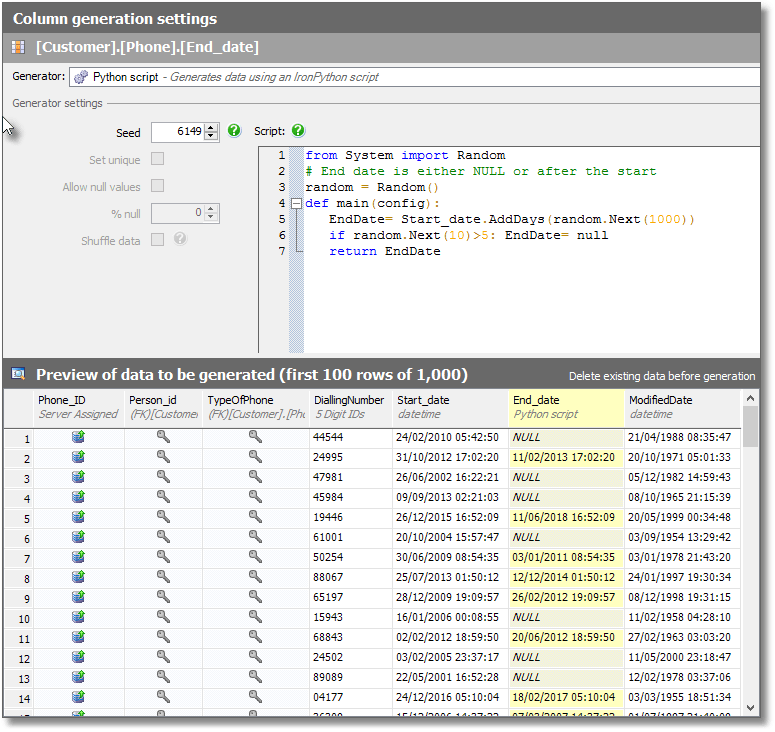
Figure 5
Next, we need to deal with the ModifiedDate column. We need something different, and slightly more complicated, here.
If there is an End_date value, then the corresponding ModifiedDate value will probably be the same as that for the End_Date. After all, the final thing you do with a record is to end it. However, if the phone is still current, then ModifiedDate must be some random time after the Start_date.
This time, the value for ModifiedDate is conditional on values in two other columns, and we really do need a Python script.
|
1 2 3 4 5 6 7 8 9 10 11 |
from System import Random #If end date is not null then make it the same as enddate #otherwise a random time after the start random = Random() def main(config): if End_date.ToString() is not None: ModifiedDate=End_date else : ModifiedDate=Start_date.AddDays(random.Next(100)) return ModifiedDate |
Listing 3: Python Script for ModifiedDate column in Phone table
Once again, paste it in, and the result should look similar to Figure 6.
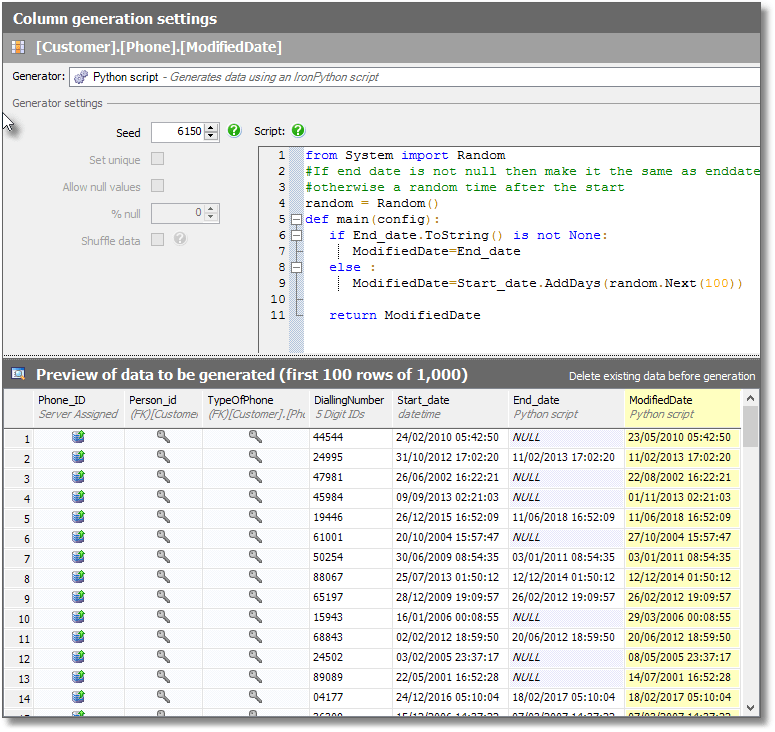
Figure 6
Summary
We have used several simple python scripts to generate realistic date values for various columns, notably created date values in one column that were conditional on the values in two other columns. This covers a lot of practical cases.
Python is a good choice for this sort of use; not only because it is very fast as a scripting language, but because its library of random numbers allows us a great deal of versatility in mimicking real data distributions. More to come!
Tools in this post
You may also like
-

Article
How to Monitor IDENTITY columns to prevent unplanned downtime
If a table runs out of IDENTITY values then it, and any dependent services and applications, will be "read-only" until the problem is fixed. Steve Jones explains how to set up a custom monitor to detect and prevent such problems.
-

Article
Basic data masking for development work using SQL Clone and SQL Data Generator
Richard Macaskill describes a lightweight copy-and-generate approach for making a sanitized database build available to development teams, using SQL Clone, SQL Change Automation and SQL Data Generator.
-

Article
SQL Change Automation Scripting: Getting Data into a Target Database
Your strategy for loading a freshly built database with data will depend on how much you need. If just a few rows, then single-row INSERT statements will be fine, but for more than that you'll need to build insert the rows using native-format BCP. Fortunately, SQL Change Automation (SCA) can be used with either strategy, as Phil Factor demonstrates.
-

Article
A whole new way to see differences in SQL Compare
SQL Compare 12.4 adds the Summary view, a tab that sits alongside SQL view and provides a more concise breakdown of the differences between two objects.
-

Article
How to Automatically Fill your SQL Server Test Databases with Dummy Data
A PowerShell script to automatically populate a SQL Server database with dummy data, for database development and testing work.





