





Managing Database Code Quality in a Flyway Development
It would be hard to argue that the quality of database code doesn't matter, but it can be frustratingly difficult to get an objective measure of it. Database code is so different from procedural code that few of the general techniques for assessing code quality transfer to database code.
What is code quality for databases?
'Code Quality' isn't about bugs: it isn't even about performance. It certainly isn't the same as code prettiness. Code quality is about getting the meaning right. It's about code that is easily understood, simple in form, and easy to maintain.
Code quality for a declarative language like SQL requires more upfront design. With procedural code, if you make initial compromises on quality to accelerate progress, it's relatively easy to make retrospective adjustments, but it requires a lot more effort to improve a database design retrospectively, and the priorities are different.
Let's take, for example, object naming. The names you choose for tables, columns and constraints all need to be easily understood. For a team trying to manage code quality in a database development, the priority is to capture accurately, in the names of tables, views and columns, the terms used by the organization for the various processes they support. These should be in the business analysis if it has been done properly.
Whatever the purpose of the database, it should use terms familiar to the people charged with using and maintaining the system. If you get this wrong, generations of application developers, report creators, ops people and support people will curse your memory. Even you, after a few months, will be forced to wrestle with database objects whose purpose once seemed blindingly obvious to you, but now have names that are opaque.
It's not just object-naming that has to be got right early in database development: A database must also be, from the very start, designed to avoid bad data getting into it. It must be designed up-front to be secure, allowing the various user roles access only to the data they require. It must have a design that fits the relational model – it should be properly normalized.
Unfortunately, you cannot postpone these aspects of 'quality', and evolve a database as one might evolve an impressionist painting. Even where it is possible, it is very painful in terms of time and tedium to have to re-engineer a working database to rename all the objects, meet security requirements or to enforce data integrity. A lot of work with nothing visible to show for it.
Issues in database code quality
Let's list some of the important aspects of a Flyway development that need attention. They aren't listed in terms of priority. They're all essential.
Keys and constraints
Keys and constraints are used to ensure that all the rules for your data are enforced. The UNIQUE constraint, for example, forbid duplicates in a column that needs to have unique values. The CHECK constraint ensures that the values in a column, or combinations of column values, conform to the rules that govern that data type. Foreign key constraints ensure that the values referred to in the key exist. The NOT NULL constraint will ensure that an essential required value is always there in a column, and DEFAULT values allow sensible values for a column if none are specified.
Keys and constraints make it possible to enforce data integrity within the database in just one place and are far more efficient than doing these checks in code, even where it might be possible. In many cases, they also enhance the performance of queries. There is no question that the more keys and constraints that a table has, the better.
Comments and documentation
Whenever I point out the value of comments, developers often recoil in horror. However, they are vital for providing an up-to-date description of your base tables and code modules, explaining their purpose to your later self, your team and to the wider business (operations, business analysts, technical architects and so on).
Comments and documentation are applied in two different ways:
- 'Decorating' the source with comments, which are ignored by the compiler
- Add the documentation for each object directly to the database, as attributes of the table, column or other database component, so that it is part of the data dictionary
Any migration-based database development system differs slightly from a system based on individual database objects. Conventionally, the build script for each object, or maybe schema, is seen and altered over time and so all those beautiful, articulate 'decoration' comments are preserved intact for posterity. I've spent years decorating build scripts with comments and documentation, which are then preserved as part of the source code and clearly visible to anyone altering the code.
In a migration-based system, objects are likely to be altered progressively over many versions and migrations scripts. Therefore, if you document the objects using the first approach, then the comments will be fragmented across a chain of versioned migrations files, and probably archived when the database was 'baselined'. If you lose this documentation, it makes team-based database development slower and more tedious, unless of course you skimp and hope that nothing goes wrong. To realize the full extent of this loss, you need to have worked in a team where documentation was done properly.
Migration scripts should still contain the explanations of the migration process, as 'decorative' comments, but the documentation of database objects such as tables, views and columns should be of the second variety, attached to the database object.
Every object (table, view, function, procedure etc.) and attribute (column, constraint etc.) needs an 'attached' attribute comment. Fortunately, they are supported by all good relational database systems. In PostgreSQL (V10 onwards), you can attach one comment on any type of object or attribute. MySQL 4.1 onwards allows comments to be attached to the metadata of tables and columns. SQL Server requires you to use Extended properties, but although they have an awkward syntax, they are very versatile. Oracle allows you to add a comment to a table, view, materialized view, or column.
We then need a way to extract the database object documentation into a single, maintainable source. This should be separate from the DDL code that builds the database because a change in documentation shouldn't mean a change in version. I find that a markup document, either XML or JSON, works best for this. This 'living documentation' can be maintained during development, held in source control, and used to publish as database documentation so that other roles, such as Ops, can see instantly what is in any version of a database, and how it works.
Object naming conventions
It's been my experience that the naming of tables, columns, foreign keys and so on in databases is always crystal-clear to whoever designs the table and inevitably opaque to all subsequent developers. Developers also try to truncate names into strange codes by removing vowels or otherwise disguising their meaning.
Full, meaningful names cost no more than the short incomprehensible ones. They don't slow the database down. The only people fooled by this are the occasional managers who believe that if code looks short on the page at a cursory glance, it is somehow more efficient, and nothing slims down code like incomprehensible names. I've found that the best approach is to make explicit in a document what the naming conventions should be at the start of work, and so everyone can, in a code review, point to the team conventions.
Semantic data model
The quality of a Semantic data model is probably the most difficult aspect of quality to judge or to assess. The semantic model represents the understanding of the kinds of entities that exist in the application environment that is being represented in normal form by the database, and the way that they relate.
By far the best test of a model, in my experience, is one called the 'Pub test'. Find someone who has no IT background, take them to a pub, buy them a pint of Stout (a good Porter will do) and explain your database model to them. The client, or ultimate user of the database, is an ideal subject. If they can understand it after half an hour to the point that they can suggest how it can be extended easily, you've got a good model. If you can't, then more work is required.
Database models are merely a formalization of the human understanding of data. A data model, like code, wants to be simple. Normalization is the way that humanity deals with complexity. However, there are signs of poor-fit such as EAV tables, polymorphic association, 'God objects' and 'data packing'. I describe these and other SQL Database design 'smells' in my article and book SQL Code Smells.
SQL code problems
As well as the database objects that can be created and altered using SQL DDL code, there will be many routines such as procedures, rules, functions, agent jobs and triggers that contain code. These must be checked for quality. It is difficult to summarize the things to look for in a few short paragraphs so I'll instead refer you to the article SQL Code Smells and to the many articles I've written to explain the reasons behind Redgate's Code Analysis system, seen in SCA, SQL Prompt and Redgate Monitor.
How to start improving database code quality during Flyway developments
If your database code quality is currently poor, or you simply don't know what state it's in, then you could consider taking the following sequence of actions. They will allow you to introduce ways to report on and improve each of the aspects of database code quality we've discussed above.
The way I've demo'd the sort of things that are required is to run scripted Flyway post-migration tasks, as part of a Flyway Teamwork PowerShell framework, which is designed for use with Flyway Teams command line.
If you're using Redgate Deploy, many of desired artifacts (change report, code analysis report, object-level source and build scripts) are built-in and so don't require writing and maintaining a separate script library.
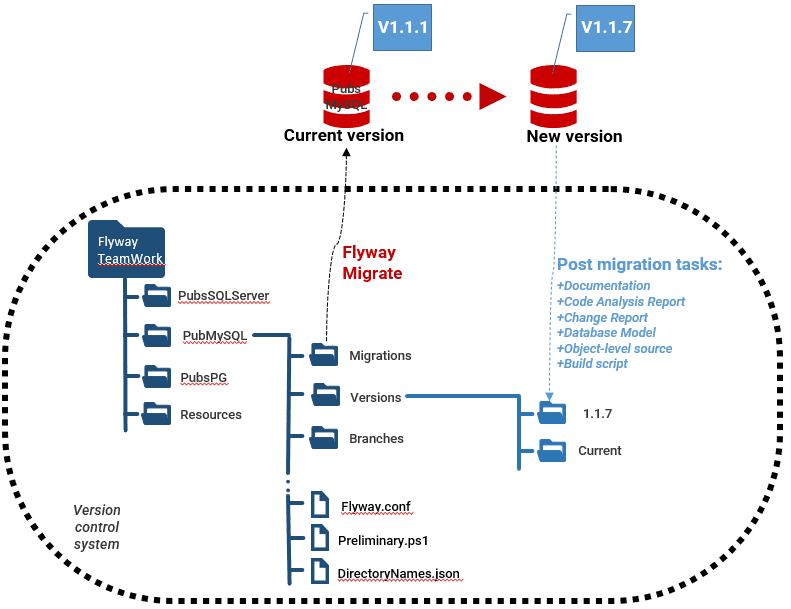
Many of the tasks that I reference below can be found in the DatabaseBuildAndMigrationTasks.ps1 file of my GitHub project.
Level 1: Keys and constraints
Are all the necessary keys and constraints implemented, to protect the consistency and reliability of the data? There are two ways to checks this: by reviewing build scripts, or by investigating the existing table properties using metadata (information_schema) queries.
With a conventional build script for a database, or of a set of related tables, you can read a CREATE TABLE statement like a list, and it becomes second nature to scan an eye over it to make sure that all the required constraints are there. With a Flyway development you don't necessarily have that, so it pays to have a generated build script for each version. For Oracle and SQL Server databases you can use Redgate's schema comparison tools, but otherwise most RDBMs supply native tools to generate these scripts, such as pgdump and mysqldump.
My Flyway Teamwork framework provides PowerShell tasks that will generate a database build script ($CreateBuildScriptIfNecessary) and object-level build scripts ($CreateScriptFoldersIfNecessary) for every new version created by Flyway, for all the common relational databases.
The alternative approach is to write metadata queries. For each RDBMS, the $SaveDatabaseModelIfNecessary task, in my framework, will run the required information_schema query and then save the results into a JSON-based 'model' of the database. By reporting off the JSON database model, generated for each new version, you can then highlight tables that are suspiciously light on Keys and constraints
These two sources of information provide what you would otherwise lose from moving to a migration-first approach.
Level 2: Documentation
All tables, columns and views should contain comments that are in the metadata. Procedures, functions and parameters should have comments if the RDBMS supports this.
To review the current database object documentation, you can use a tool like SQL Doc (SQL Server only), or you'll need to use metadata queries to extract it from the comments (or in SQL Server case, extended properties) associated with each object.
My Flyway Teamwork framework includes a PowerShell scriptblock task called $ExecuteTableDocumentationReport (SQL Server, MySQL, MariaDB, PosgreSQL) that does this job for you for the basic requirement of tables, views and columns. It extracts the documentation into a JSON file, which we can maintain during development by adding lots of useful comments to any objects we add or alter.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{
"TableObjectName":"dbo.prices",
"Type":"user table",
"Description":"these are the current prices of every edition of every publication",
"TheColumns":{
"Price_id":"The surrogate key to the Prices Table",
"Edition_id":"The edition that this price applies to",
"price":"the price in dollars",
"advance":"the advance to the authors",
"royalty":"the royalty",
"ytd_sales":"the current sales this year",
"PriceStartDate":"the start date for which this price applies",
"PriceEndDate":"null if the price is current, otherwise the date at which it was superceded"
}
}
|
There is also a sample Flyway 'afterMigrate' script (afterMigrate__ApplyTableDescriptions.sql) that takes the JSON document and applies it to the database by checking whether each table exists and, if so, whether it has the documentation. It then does the same for all the columns if the table exists.
Level 3: Object naming
Having generated the documentation, you'll probably start to notice inconsistencies in the naming of various database objects. The team must adopt a standard for object-naming conventions (e.g., ISO/IEC 11179-5), and then start implementing it for all new objects.
I've demonstrated how you can check for violations of that standard elsewhere, although it is a little harder to get an overall measure of the quality of naming. I've seen attempts to do this purely by measuring the length of all the database names, but Devs soon defeat this. It is sometimes possible, if word boundaries are delimited with the underscore to get a rough indication by checking all database names against a bank of the 40,000 commonest English words. This can give a rough indication of the spread of words and the percentage of names that use them. There is enough to show where to investigate
Level 4: Database model design
Start to investigate deficiencies in the overall design of your database model. For example, are tables normalized consistently? Are all foreign table references covered by a constraint that is supported by an index? Do all tables have a primary key? Is every table referenced?
If the answer to a lot of these questions in "no", it's a sure sign of a model being seriously adrift. A table that isn't referenced and has no primary key may be a cunning an efficient logging system, in which case there should be an explanation of this attached via a comment. More likely, it is the detritus of an abandoned part of the database model.
Again, you can spot many of these design flaws using metadata calls. I've created a sample system as a Flyway Teamwork task to list anything that might need further investigation. It is called $ExecuteTableSmellReport (currently SQL Server only).
At this point, you should also review the access control system. It must identify where sensitive data is held and ensure that direct access is allowed only for appropriate roles, and that inference attacks are not possible. Although Operations will assign different users to the roles, they are unlikely to be involved in defining the roles
Level 5: Code smells
All code should be reviewed and checked against a style guide, either manually during code review, or automatically using a static code analyzer. Redgate supplies code analysis engines for Oracle and SQL Server.
I have created a task in the Flyway Teamwork that runs this on a SQL Server database and migration code (see Running SQL Code Analysis during Flyway Migrations) .I find this feature very useful and, although it is configurable there are very few checks that I'd ever think of switching off. If it highlights any uses of deprecated features of the SQL dialect, these should be purged from the code, at this stage.
Conclusions
I must admit that I came to database development from procedural coding. It was a shock to discover a technology that, from sheer necessity, had very different priorities and characteristics. A database system on which an organization can rely cannot 'evolve' with the understanding of the system. The creation of a robust and extendable database model and design is unforgiving of errors or impatience. A corporate database is more like a building; you need to know precisely what you are building before you start. Any assessment or measurement of database quality must reflect this.
The most obvious challenge facing Flyway users, striving to maintain code quality for a database development, is the difficulty in piecing together the accurate story of individual database objects, such as a table or set of tables, from a directory full of migrations. For database documentation, for example, the migration approach requires that the developers must still take care to provide all the comments and documentation they need, and which usually decorate the object-source scripts that are the 'deliverable' of the more traditional database development process. This can be extended further: relationship maps, entity-relationship diagrams, searchable documentation.
Flyway itself is sternly command-line, but it is best served with the means of providing all the necessary visual representations, help and information about the database. Not only is it then quicker to develop an error-free database, but also easier to maintain, and easier to train people how to use it.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Database Branching and Merging without the Tears
Armed with a schema comparison engine and an object-level directory of the source for every recent version of the database, you'll be able to remove a lot of the uncertainty around merging database changes back into development.
Article
Flyway Teams and the Problem of Database Variants
The 'ShouldExecute' script configuration option in Flyway Teams simplifies 'conditional execution' of SQL migration files. This makes it easier to support multiple application versions from the same Flyway project, to deal with different cultural or legislative requirements. It also helps developers handle environmental differences between development, test and staging, such as the need to support multiple versions or releases of the RDBMS.
Article
Complex Production Database Deployments and Flyway
This article explains how, by use of schemas and stub interfaces, we can use Flyway to manage the main development work smoothly alongside any changes or additions required to maintain production-only code. It also demonstrates how this mechanism enables Flyway to manage a 'mock' or 'dummy' variant of a production schema, in development, so that the team can still develop and test code that, when deployed, will access production-only features.

Article
Using SSDT and DACPACs with Flyway: a Demonstration
The aim of this article is simply to demonstrate that you can use two DACPAC files, representing the source and target versions of a SQL Server database, to create a migration file that can then be used in Flyway.
Article
Re-baselining a Database using Flyway Desktop
Over time, Flyway projects can accumulate a lot of migration scripts, with many database objects being created, altered, and dropped across many files. Tonie Huizer explains why you might want to create a new baseline migration file to create the latest version of a Flyway-managed database in a single leap, and how to persuade Flyway Desktop to do it.
Article
Bulk Loading Data via a PowerShell Script in Flyway
The test data management strategy for any RDBMS needs to include a fast, automated way of allowing developers to "build-and-fill" multiple copies of any version of the database, for ad-hoc or automated testing. The technique presented in this article uses a baseline migration script to create the empty database at the required version, which then triggers a PowerShell callback script that bulk loads in the right version of the data.
Loading comments...