How to Manage Static Data in Existing Flyway Projects
How do we capture static data in our Flyway projects, and then track and deploy any changes to it, while also ensuring that our automated deployment process doesn't try to deploy static data to databases where it already exists, such as the production database? For new Flyway projects, it's quite straightforward, but for existing projects there may be complications, depending on your database development and deployment strategy.
Managing static data in a Flyway development
Most databases will contain a certain amount of relatively unchanging reference or static data, required for applications to function correctly. There are a couple of ways to manage this static data during Flyway development. For example, you could store it in a read-only view (a view based on a derived table). This technique means static data is treated as part of the DDL. It’s kept in version control so we can track changes to it, and it’s deployed using versioned migrations, so any changes will change the Flyway version, which, unlike for data generally, is what we want for ‘static’ data.
However, we don’t use read-only views in our databases, and since we use Flyway Desktop in development work, we can get the same advantages simply by informing Flyway which tables contain static data and then letting it manage the rest (as was possible with SQL Source Control). In Flyway Desktop (v6.x and later) we do this using the Static data & comparisons button on the Schema model tab:
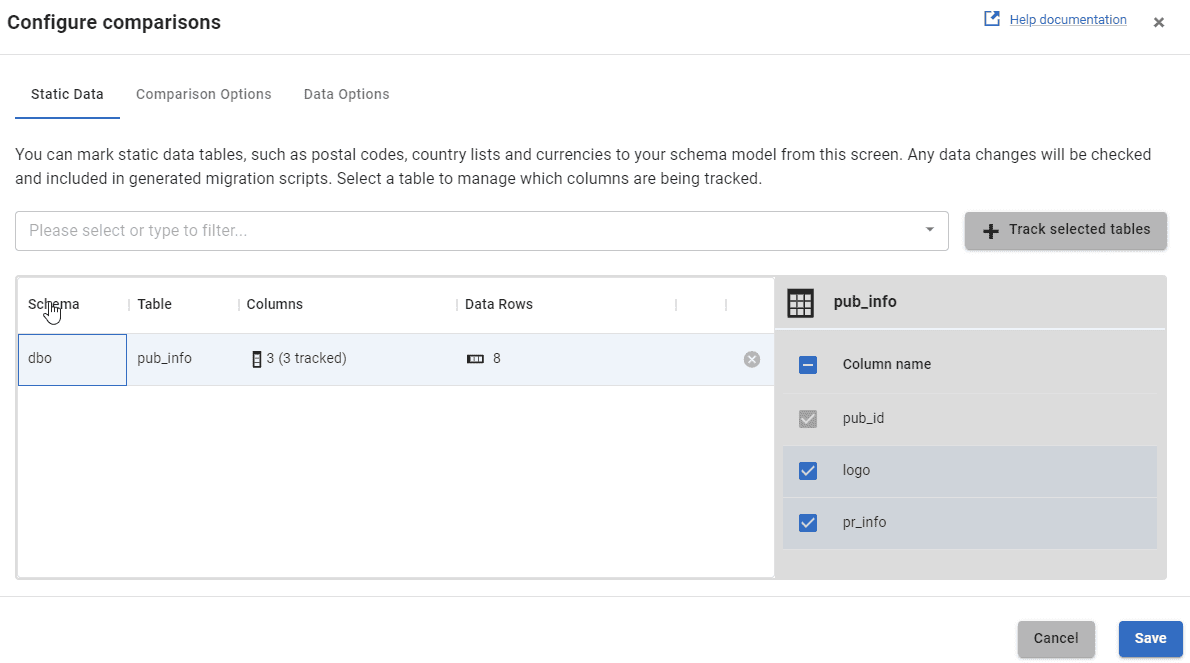
Track the static data tables and save them to the schema model, then switch to the Generate migrations tab. Select the static data objects and hit Generate scripts. Flyway Desktop will generate and verify, using the shadow database, a new versioned migration script for the static data, and the accompanying undo script if you’ve configured the project to capture these. This static data script will contain a series of INSERT INTO statements for each of the static data tables, which is fine for small data volumes.
Deploying static data
How do we avoid having Flyway run these static data migrations when an existing database already has this data? If this is a new Flyway project, then once you’ve saved the initial static data scripts to the project, you capture a baseline migration, as usual, and it will include the static data.
However, if this is an existing project, there are a couple of ways to handle this. We’ll start with the documented approach (“skip migration”), and then I’ll describe an alternative, in case the conditions associated with use of this method won’t work for you.
Initial Static data migration – skip migration approach
For existing projects, the solution suggested in the Flyway Desktop documentation is to follow the steps described above to save all the static data that already exists in production, and any other ‘downstream’ databases, to the schema model. From there, we can capture it in a versioned migration script and save it to the project.
You then need to switch to the migrations tab, connect to the production environment, and then each of your other downstream environments that already contain the initial static data (Testing, QA, Staging…), and execute the flyway migrate command using the -cherryPick and -skipExecutingMigrations parameters:
flyway migrate -cherryPick=<yourStaticDataVersionNumber> -skipExecutingMigrations=true”
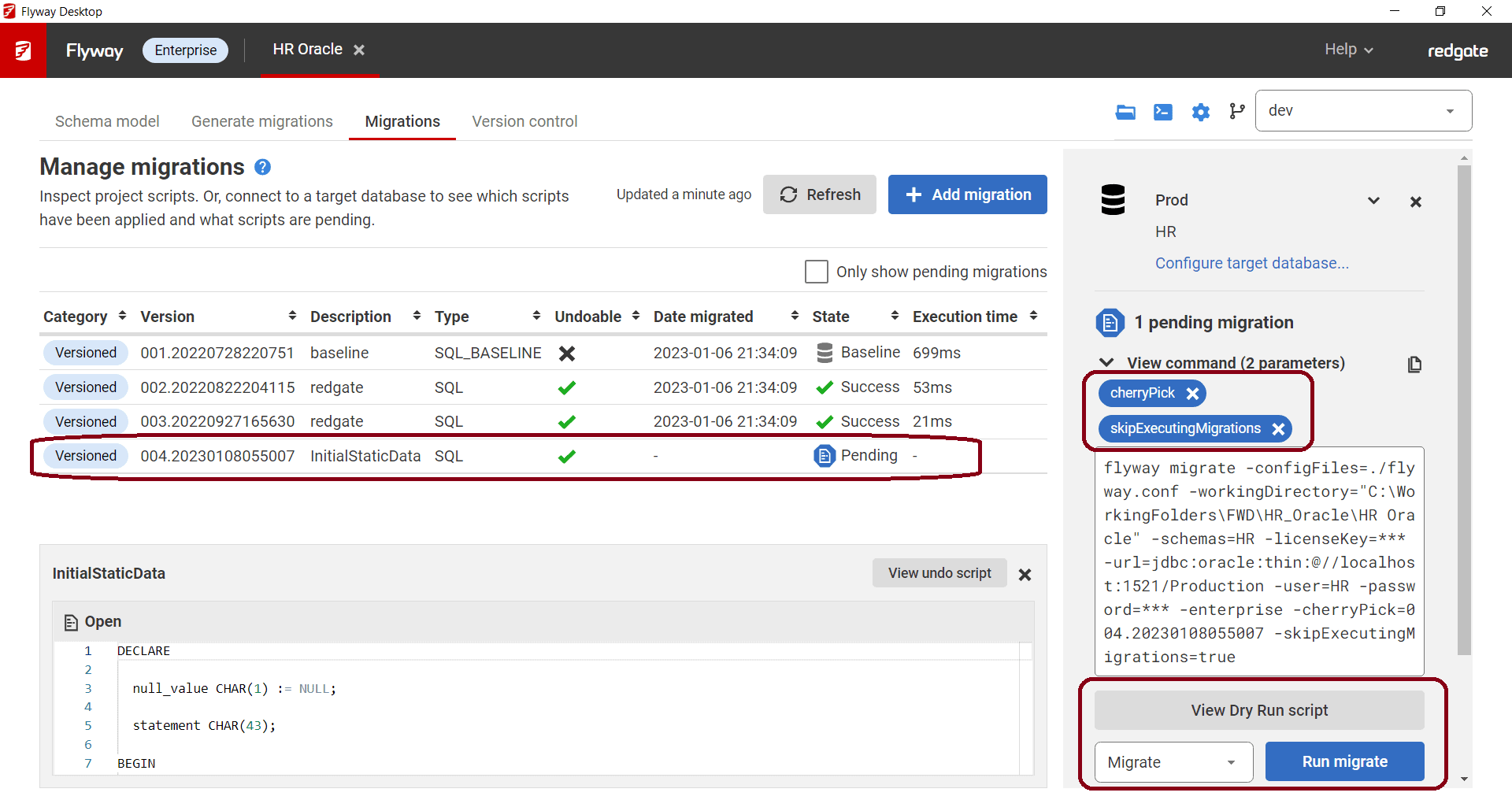 This command registers the static data migration file in the schema history table of each the downstream databases, without Flyway executing the script (because these databases already contain this initial static data). It also prevents Flyway from trying to re-run the initial static data file on all subsequent migrations.
This command registers the static data migration file in the schema history table of each the downstream databases, without Flyway executing the script (because these databases already contain this initial static data). It also prevents Flyway from trying to re-run the initial static data file on all subsequent migrations.
This approach works, but it makes a couple of assumptions that may not be valid for your development or deployment strategy. Firstly, it assumes that you can connect from Flyway Desktop and execute this command on all your upstream databases, including production. In many organizations, this won’t be allowed.
Secondly, in our case, the development databases, and those in all downstream environments, are clones, created from an image of the current version of the production system. So, for example, a developer or tester can spin up a clone from the latest image, run some destructive tests, then instantly reset it, by deploying a fresh clone from the current image.
So, for this approach to work, we’d need to request our operations team to run the “skip migration” command on production, then capture a new image, and then we’d need to use that new image to redeploy all development and downstream databases. Alternatively, the team would have to remember to apply the command every time they created a new environment, or reset an existing environment, which is a recipe for mistakes. We needed an alternative approach.
Initial Static data migration – “only on Shadow database” approach
If the documented approach isn’t viable, for the reasons discussed, then there is an alternative way to add the initial static data migration to an existing Flyway Desktop project, while ensuring it’s not executed on any existing environments.
The first steps are, again, as described above. Having ‘marked’ your static data tables in Flyway Desktop, save the data to the schema model and generate a migration script. It’s worth remembering that Flyway Desktop will, at this point, build in the Shadow database the current version of the schema, as represented by the migrations folder. It will then compare the shadow database to the schema model folder and generate a script that captures the initial static data. It can validate this script by running it on the shadow database, and finally we can save it to the migrations folder in the project.
The next step is different and includes a small hack that instructs Flyway to run these initial static data scripts only on the shadow database. We alter both the migration and undo scripts by adding IF … BEGIN…END constructs to each one (3b in the diagram above):
IF DB_NAME() LIKE '%_Shadow' BEGIN <… migration content …> END
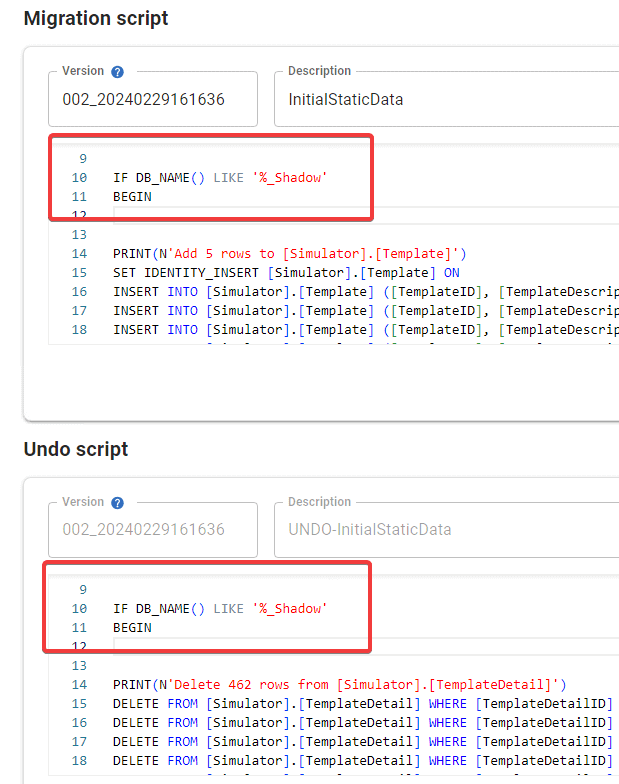
This little addition will make sure that:
- These static data migrations always run against your shadow database, so Flyway Desktop will capture any subsequent changes to the static data and generate migrations for those changes.
- The initial static data script never runs on production, nor on any of the other downstream databases where the data already exists.
There is a downside: if a developer ever just wants to build a new version of the database from scratch, by running the scripts in the Flyway migrations folder, rather than doing a restore or deploying a clone, then it won’t include the initial static data. You’d have to run that script manually.
Conclusion
Managing static data with Flyway Desktop is a very welcome feature and it even works in brownfield projects, where most of the static data is already in upstream databases. However, the solution offered in the official documentation doesn’t work for everyone. The alternative “shadow database only” approach that I’ve proposed, combined with the good written documentation, will hopefully allow more team to version and track their static data, in a Flyway project.
Tools in this post
Redgate Flyway Desktop
Redgate Flyway Desktop helps you easily and safely version control your database schema and prepare validated deployments
You may also like
-

Article
Creating Flyway Migration Files using Redgate Schema Comparison Tools
How to use Redgate's schema comparison engines to generate object-level scripts for every database version that Flyway creates, and then use them to create ad-hoc, Flyway-compatible migration files.
-
Article
How to Automate Cross-Platform Database Development
In order to focus on their primary task of developing databases, the development team need to automate as many as possible of the routine tasks that are essential for database delivery, such as testing, scripting, version control, documentation, code review, reporting and so on. This article gives some advice on how to do it, faced with the added challenge of needing to use several different relational databases.
-

Live training session
Advanced Features of Flyway: Discover the capabilities of Redgate Flyway Enterprise
Discover the potential of Redgate Flyway Enterprise Join Redgate Advocate, Steve Jones and Solution Engineer Andrew Guard for an in-depth training session for those looking to discover how to utilize the full capabilities of Redgate Flyway Enterprise. What You’ll Learn: Backups as Baselines: How to create reliable database backups as baselines for versioning and future
-
Article
Flyway for SQL Server Data Tools Users
If you are using SSDT for authoring, building, debugging, and publishing a database project, how do you change to, or preferably migrate towards, a Flyway-based database development? Flyway doesn't need to replace any code part of SSDT, but if allowed to manage every release candidate, it does allow for much cleaner branching, merging, and deployments.
-

Webinar
5 advantages of Flyway Enterprise to accelerate and de-risk database delivery
Database DevOps has come of age. Now seen as a key technical practice, which can contribute to the successful implementation of DevOps, it stops the database being a bottleneck and makes releases faster and easier. This on-demand session with industry expert, Ryan Booz, and Flyway product manager, Stephanie Herr, aims to tackle the pressing challenges
-

Webinar
From Bottleneck to Breakthrough: Gain Control and Confidence in Your Monolithic Database Changes
Monolithic systems sit at the core of many mission‑critical platforms, especially in industries such as finance, but they often become a bottleneck when change feels risky. In practice, most organizations don’t fix monolithic databases or break them apart all at once. Instead, they work with them: stabilizing the core, managing dependencies, and making controlled, incremental





