





A Real-world Implementation of Database DevOps: People, Processes, Tools
Many organizations understand the benefits of introducing DevOps practices into their database development cycle and deployment pipeline but struggle with the implementation. Flyway Enterprise is one set of tools that is designed to help with this. It will allow you to you "automate database deployments across teams and technologies". OK, but how? You've opened the new bundle of tools, sifted through documentation, reviewed many of the hundreds of articles and videos. How do you distil all this information into a plan for your own implementation?
That is a good question, and I can't offer you a 'golden path', but I do have first-hand experience to share, earned from recent efforts to transform an existing database development and release process, with lots of repetitive manual steps and processing, into an automated implementation of Flyway Enterprise.
In this first article, I'll summarize where we started, what we will try to accomplish, and the people, processes and tools involved in making it all work. After all, according to Microsoft's definition:"DevOps is the union of people, process, and products to enable continuous delivery of value to our end customer."
The People
DevOps is about more than automation. It's about helping your technology teams work more collaboratively towards a single, shared goal, which is delivering value to the customer.
For DevOps to happen, people need to learn, collaborate and share responsibility. By bridging the cultural and technical gaps between teams, practices such as Continuous Integration (CI) and Continuous Delivery (CD), which require a high level of cooperation, become possible.
Within any organization, or even in a single team, there is often a lack of shared understanding of why a process is necessary, who needs to do what, who benefits from it or worse who suffers from not doing it. DevOps is about breaking away these walls of confusion.
It starts by pulling people together from different teams or departments. In our case the sales engineer, the database engineer, the software developer, the tester and even the people responsible for the deployment to production teamed up. The idea is to encourage collaboration, and the participation of the right expertise, at the right time. It is this 'secret ingredient', perhaps more than anything else, that DevOps helps to deliver.
The Processes
The processes within the development, test, release and deployment pipeline should be clear to each individual team member. Each process should be controlled and standardized, as far as possible (for example, the way we update a database to a new version should be consistent in every part of the process), and then automated.
By using automation to improve the processes of build, integration, release, test, and deployment, which would otherwise be manual, repetitive and error-prone, we both reduce the workload, and make each process more reliable and repeatable. The more we automate, the more we can focus on delivering value to the customer.
To improve quality, we must ensure that each part our automated processes benefits from the expertise of people who understand the organization's requirements, and its data. We need these processes to be 'visible' across teams, to make cooperation easier, and avoid any nasty surprises. By doing all this, we get more frequent, higher quality and more reliable delivery of changes.
The DevOps tools and services
You can't buy DevOps "in a box". There are, however, products, tools, and services that help to enable the DevOps practices. Usually, these tools work in a simple 'linked chain' with each link being executed consecutively and the output from one tool forming all or part of the input for the next one.
It is rare that all the required tools will come from a single vendor. Instead, we pick the best tool for our requirements, and then rely on all the tools working together, such as via simple in a command-line Interfaces.
In our case, our DevOps pipeline consists of several Redgate tools, such as SQL Clone to provision development databases, Flyway Desktop to generate database change scripts, and the Flyway migration engine to deploy them. These tools must, of course, work seamlessly with our version control system (Git), integration pipeline (Azure DevOps), and other workflow tools such as bug trackers and so on.
Transforming to an automated Database DevOps process
For this implementation we will look at a team of professionals developing bespoke .NET solutions for their customers. Broadly, their 'old', manual database development, test and release processes looked like this.
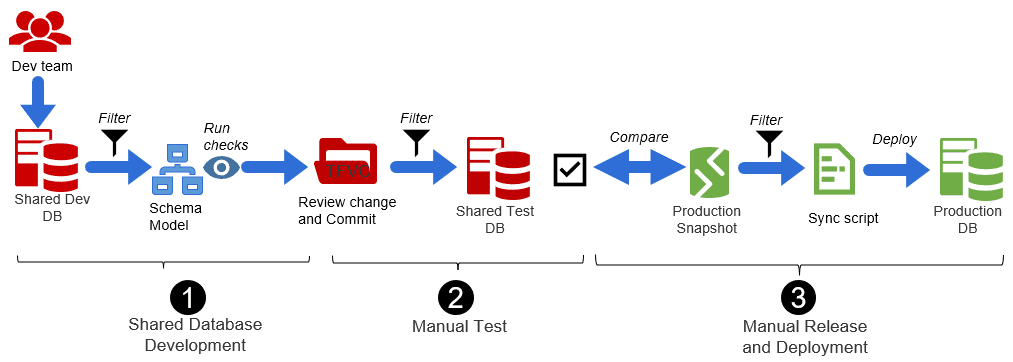
It used a shared development and test databases, a couple of 'standalone' Redgate tools, SQL Source Control and SQL Compare, and a lot of manual processing. Once a change is ready, in the shared development database, it is reviewed and committed, and the commit then applied to the shared test database, where manual tests and checks are carried out. Eventually this change is generated as a deployment script, against a snapshot of production. The deployment to production is carried out manually, by the customer.
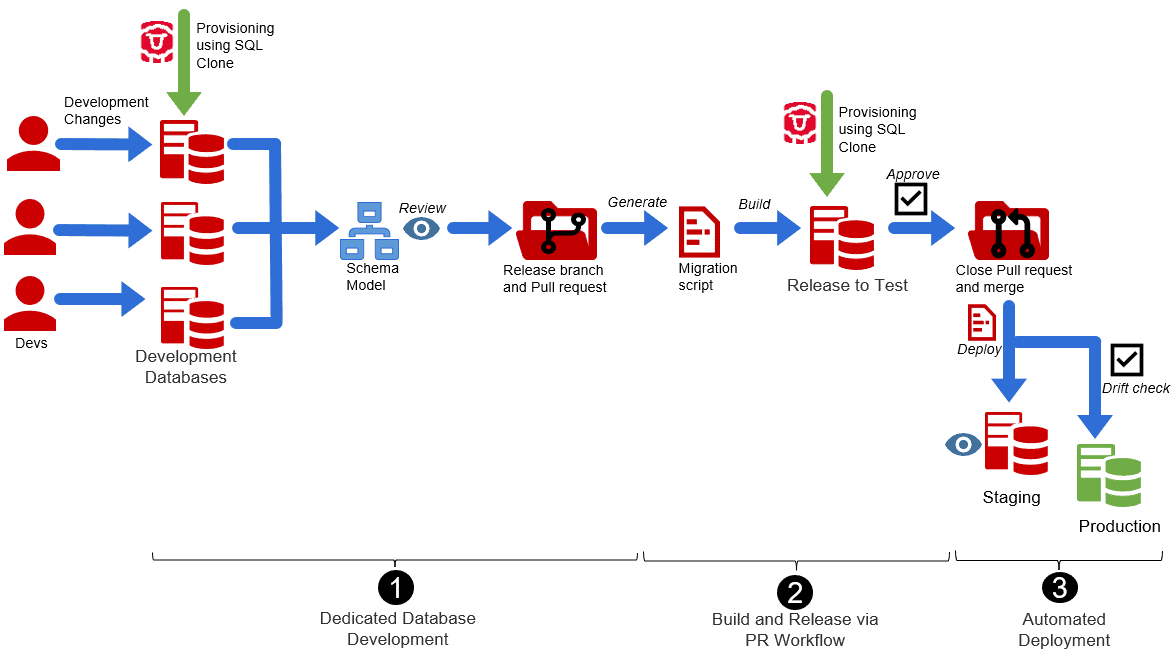
Their new Database DevOps implementation, by contrast, allows developers to spin up dedicated, personal databases for development and test, on demand, using SQL Clone. It uses an interconnected set of tools in the Flyway Enterprise bundle for SQL Server (Flyway Desktop, Flyway commandline engine, SQL Compare, SQL Clone) for generating and deploying migration scripts, and the set of automation services present in Azure DevOps, such Azure Repos (Git) and Azure DevOps Pipelines.
The new processes look more like this, with each of the steps involved being automated and repeatable:
The current, manual workflow
One issue that should leap out immediately is that this workflow involves filtering out the same change, repeatedly and the risk of bumping into another unrelated change in the shared database is very high. Unfortunately, there is no other way, due to the use of the shared databases. Also, there was no way to do a realistic deployment rehearsal, prior to sending the deployment script to the customer.
1. Shared database development

A SQL developer creates a change in the shared SQL Server database and then notifies the reviewer (another developer who must review the change and, if approved save it to the version control system):
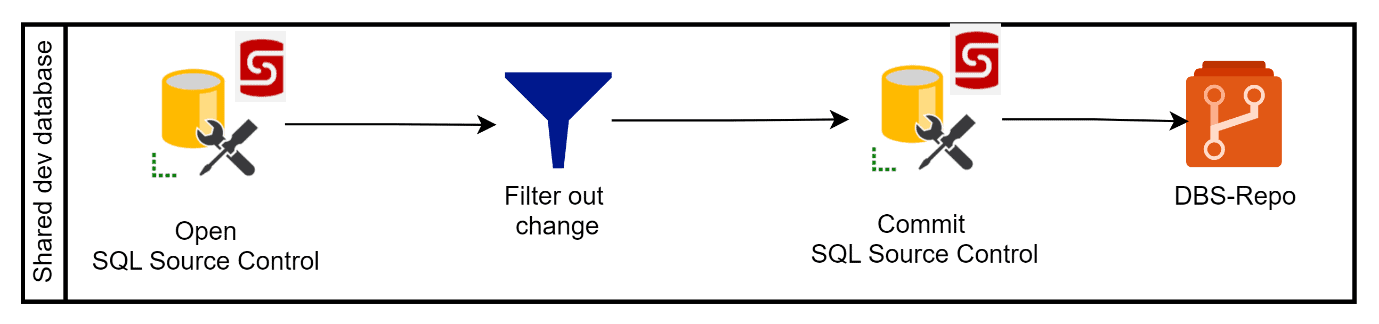
The reviewer, working on the same shared SQL Server database, must isolate the 'pending' change by filtering it out using SQL Source control. Having approved the change, the schema model updates are commited to a TFVC repository.
2. Manual tests and checks
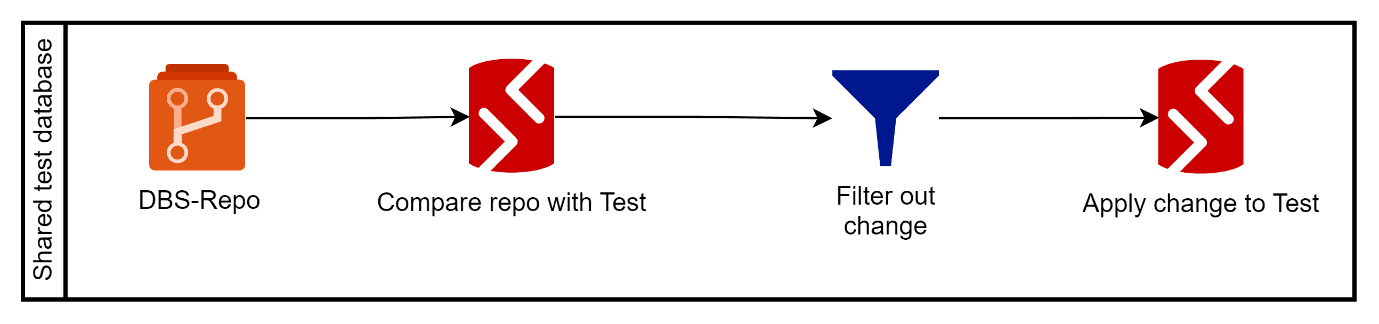
To deploy the committed change to the shared test database, the tester compares the SQL Source Control repo to the shared SQL Server test database using SQL Compare and, again, applies a filter. Having located the change, it is deployed to the shared SQL Server test database.
If the change passes all the tests, the Tester notifies the SQL Developer that it is "all clear" to be released.
3. Manual release and deployment
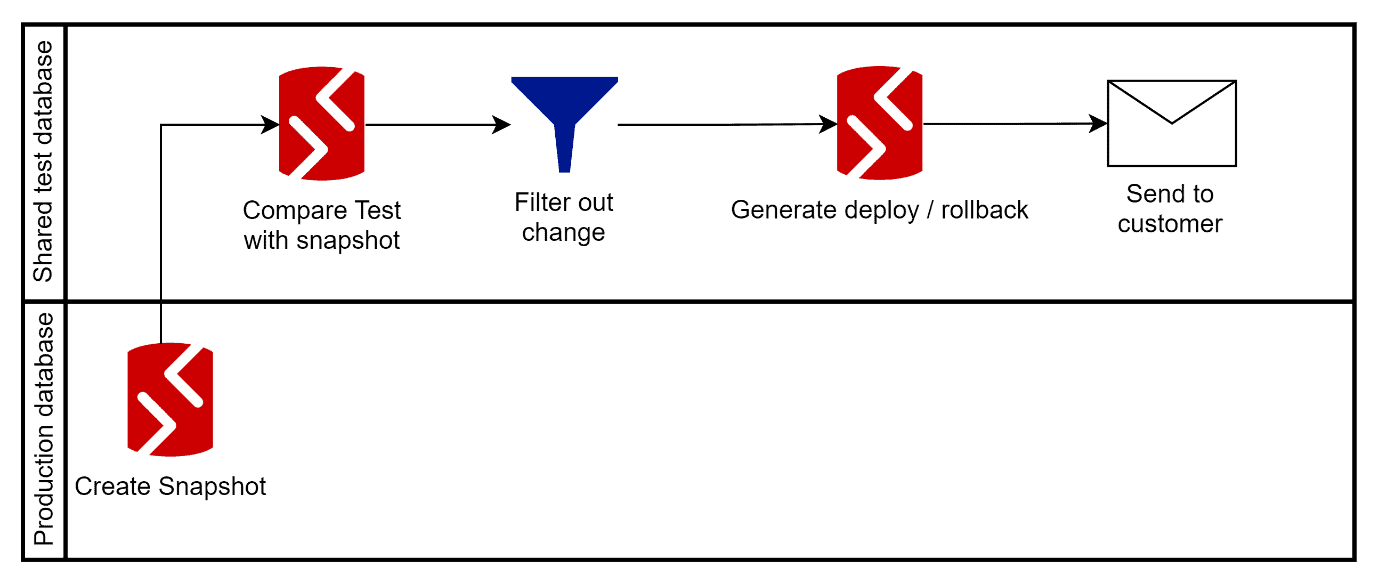
The SQL Developer now needs to generate the deployment script. Again, this is done by schema comparison, with the Test database as the source, and a snapshot of the current production database as the target, with the same filter applied.
The test database is used as source to be sure nothing from repo will leak through unintendedly; there are always more changes to filter out in the repo than in the just tested shared database. The unrehearsed generated deployment script can then be sent to the customer.

The customer will deploy the change to production outside office hours with SQL Server management studio and notifies the development team.
The new, automated DevOps workflow
In the new workflow, each of these manual and perceptive processes is transformed. Each developer works on a personal cloned database, a copy of the latest production version. This gives them far more creative freedom for development and testing. The commit and share changes by updating the schema model. After a code review, we generate a migration script, which in turn will trigger a test release as part of a pull request workflow. If the test is approved, the same migration can then be released to a cloned pre-prod database and eventually to production. All this happens as part of an automated pipeline, so without any need for filtering, or running scripts manually.
1. Dedicated Database Development

Each SQL developer works in their 'sandbox' clone database. A developer creates, tests it, then uses Flyway Desktop to update the schema model.
To administer the change, the developer creates a branch and pull request and commit and pushes this to the Git repository. The reviewer immediately reviews the pull request and approves it. After this the changes are captured in a new versioned migration script, generated using Flyway Desktop. This is the script that will be used to deploy the change to any 'downstream' database that is currently at an earlier version.
2. Automated Build and Release via a PR workflow
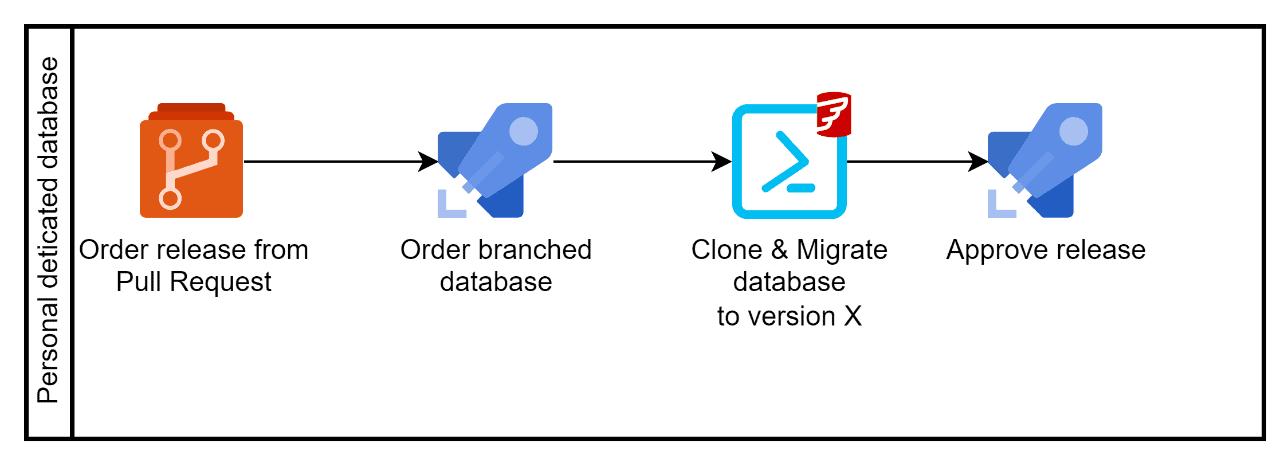
The tester orders a database release via the pull request. The PR workflow in Azure DevOps creates a special build, called the pre-merge build. It contains the latest version of the main branch plus the changes from the branch that needs testing. This build is then used in the release pipeline.
This release will prepare a personal SQL Server database for testing, by deploying a clone of the latest release and then migrating it to the version available in the pre-merge build, using the Flyway engine.
3. Automated Deployment
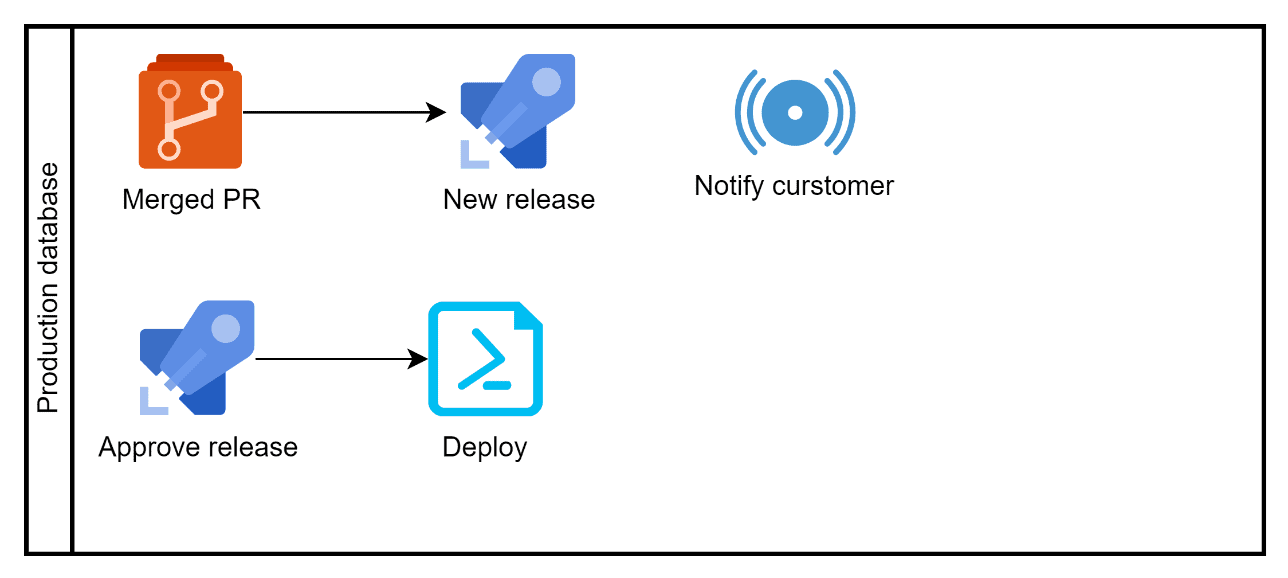
When the tester approves a release, it triggers the pull request to complete, and the result is a new database release available for production. After a pre-production release, and checks, the customer is automatically notified that a new release is available.
The only thing left to do for the customer is finding a correct window for deployment. First a database drift check is carried out and, assuming no drift is detected, the migration is applied to the production database. The database is now at the new version, without the customer manually running scripts.
Summary and outlook
In this first article we looked at the people, the processes and the tools they use to do their work. Not only the products of Redgate the team uses change, but also the work process of the people in the team is changing. It requires a lot of careful management and, as always, the 'devil is in the detail', which we'll start to explore in subsequent articles, as I walk through demos of how each part of the process works, in practice.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Passing Parameters and Settings to Flyway Scripts
This article explains the various ways of using placeholders to pass information and settings to any Flyway script, to gain bit of extra flexibility in a migration run., providing examples of conditional execution, running SQL expressions using environment variables and even one of using placeholders in a callback to send a warning notification to your phone, after a migration completes.

Article
A Flyway Teams Callback Script for Auditing SQL Migrations
Demonstrates a cross-database PowerShell callback script for reporting on and auditing Flyway migrations, telling you which scripts were used to create each version, when they were run, who ran them and more.
Article
Redgate Flyway’s Product Updates – February 2026
This month’s highlights include smarter dependency handling in Flyway Desktop, and a look at how we’re starting the year strong for Oracle users. Plus: last call to share your feedback in our Flyway user survey (the prize draw closes soon!). Even more control for your dependencies in Flyway Desktop One of Flyway’s strengths is tracking your schema as individual SQL DDL scripts on disk, giving you version control, a complete audit trail, and the ability to automate deployments with confidence. This update gives you more control over dependent objects as you capture changes and prep releases. Read the post: Control
Article
Using SSDT and DACPACs with Flyway: a Demonstration
The aim of this article is simply to demonstrate that you can use two DACPAC files, representing the source and target versions of a SQL Server database, to create a migration file that can then be used in Flyway.

Live training session
Redgate Flyway AutoPilot with PostgreSQL: Get Flying in Under 30 Minutes
Chris Hawkins and Huxley Kendell, Solution Engineers at Redgate, are back to lead you through a hands-on session with Flyway AutoPilot, this time featuring PostgreSQL. This interactive, ready-made sample project will allow you to experience using Redgate Flyway Enterprise in under 30 minutes.

Article
SQL Server deployments: Which Redgate tools should you use?
Since 1999, we’ve been developing tools at Redgate to support database deployments for SQL Server. In the past couple of years, we’ve increased our effort in this space by further developing our proprietary technologies based on SQL Compare, and acquiring others like Flyway, the most popular database migration engine. As a result, we now offer tools which provide more options for SQL Server and also support deployments for 20 different database systems. This can, however, be slightly confusing for customers who are already familiar with our SQL Server tools and want to know how the new additions work alongside them.
Loading comments...