





Forks in Flyway Database Development Work
Flyway was designed from the ground-up to fit in with a range of team-based database development methods. This article will spell out some of the ways Flyway supports database forking, allowing teams to experiment, test, and develop new features or patches on separate forks of the database. Once changes are fully vetted, they can be merged back and deployed to production with minimal disruption. It also explains how it can help teams manage forks for variants of a released production database.
Why forking?
Once a database is in production, the art of database development is about making incremental improvements to the database without any disruption in the service. Instead of rebuilding the whole database, small, controlled changes need to be applied while the database is still in use. These changes are typically made through migration scripts that must update the database structure (like adding columns or modifying tables) without losing existing data.
To do this smoothly, the key is to deploy small, well tested updates. "Well tested" means both ensuring the database continues working as expected and that the migration script updates the database reliably without causing errors. The task is made more challenging when the development team is required to support multiple editions, variants or versions of the same database, such as for SaaS applications with client-specific schema requirements.
All these requirements are much more easily met with an automated system of database development that supports forking.
Forks, branches and their uses
A 'fork' is a divergence or split in the codebase of a development project. Each fork creates a new development task that can run simultaneously with, and independently of, the original parent development. This allows the developers to work independently and in parallel, when necessary, so work can be task-based, prioritized and delivered in a series of controlled incremental changes
A fork in development is usually a short-lived branch, created to support parallel development tasks, such as adding new features, developing a patch, or performing A/B testing. The work will soon be merged back into the main development. However, a fork can also be a long-term diversion from the parent development, such when a business needs to support multiple variations of a database schema for different clients or environments.
Sometimes forks can lead to the creation of entirely new database systems or projects, where different groups continue development separately. Alternatively, they may eventually merge back into the original project if the differences are reconciled or if one fork becomes dominant. A fork may be needed to maintain a legacy version of a database system that is no longer being actively developed by the original creators. Occasionally, I come across the practice of a 'fork' being used to try to remedy a flawed deployment.
Creating a fork is easy, sometimes too easy. Merging can be more challenging. The merge process for a long-term fork can be an 'interesting and absorbing' activity that is best done methodically.
Branches in database development
When you create a branch, you're creating a separate line of development that allows the team to work on different changes, such as for a hotfix or a new feature, or just to run experiments, without affecting the main codebase. These changes will, in all or in part, be merged into the parent branch and from there to eventual release.
Maintaining production databases
Often, the DBA or Ops team need to apply urgent 'tweaks' to a production database system after a release, often termed a 'roll forward'. This is done to fix urgent bugs or correct performance issues. This 'hotfix' migration is applied directly to production, post-deployment, and then promptly added back into the main branch as an idempotent 'patch' migration, reconciling the divergence, and ensuring consistency across environments. Similarly, I've known cases where the deployment team work entirely independently and maintain their own set of patch migrations. Once applied to production, and after a period of stabilization, they are passed to the development team to devise a satisfactory merge. This is a type of 'controlled version drift'.
There are legitimate reasons for making changes without a full release, but these strategies aren't risk free. A hotfix that is done quickly to maintain the service can have subtle repercussions on other parts of the system. Sometimes, mopping-up after a failed hotfix is messy and distracting.
Any complicated changes should, ideally, be developed and tested in a fork off the current release, as a hotfix branch. These fixes can be thoroughly tested in staging, deployed as a full release and only then merged with the develop and main branches, by adding the hotfix migration file to them.
Forks for maintaining variants in released production databases
Things become more complex with multiple production systems, especially when each requires different changes. Here, the use of forking becomes a necessity. The classic example is the use of forks to maintain database 'variants', where the database is a software product such as a banking system, a payroll system or which must function correctly and independently under different financial or cultural requirements.
Similarly, in a multi-tenant SaaS application, you may have clients with specific customization requirements that diverge from the standard database schema. You may also need to fork a production database to do A/B testing.
Forking development in Flyway projects
Flyway works most easily and safely if it does simple migration runs. However, if you do 'trunk-based development', avoiding use of forks and branches, you will inevitably arrive at a point where your migration runs become more complicated. You'll need to induce Flyway to skip migrations (such as when a hotfix has already been applied to Staging and Production), execute migrations out of order, or execute migrations conditionally.
Flyway will do this if you specify certain values to command line parameters or, more permanently, as flyway.conf items. If you add in devices such as 'repeatable' migrations or conditional migrations, or even changing the list of directories of migration files, there are plenty of ways of accommodating divergences between databases that would otherwise require a database fork. After all, Flyway thrives by accommodating to the way that you, or your team, works.
However, the simple use of such configuration items can become a complex and error-prone way of doing team-based database development. I also believe that some users aren't aware, because it isn't spelled out, that Flyway has other ways of accommodating divergence and facilitating teamwork, by using forks. We'll discuss three ways it can do this, using the locations configuration, using baseline migrations, and by mapping Flyway projects to schemas.
Using Flyway locations for each fork
The obvious way of forking a Flyway database is to use the Flyway locations configuration item. Flyway works on a list of 'locations', a location being a path to a directory in which you store your migration files. At the start of a project, you'd probably only need one location for the main or trunk development (A, in the diagram below) It is then easy to fork a database by adding a directory location for each branch of the fork (B & C). Each branch is then developed independently by adding further migrations to the appropriate extra location (B or C). The team can even add migrations that are appropriate to both forks, such as bugfixes to existing code, to the original directory if they can avoid clashes, and out-of-sequence migrations.
Forking at Every Release
The following diagram shows how you can deploy the latest release with any production changes by using the locations config parameter to fork the development branch. For example, for the release branch, the locations list will include two relative or absolute references, each with the filesystem: prefix, one referencing the local branch migration files, and the other one the parent branch's (i.e. main) migrations. Similarly, for the development branch we use the locations list to ensure that all the files in the trunk and all the development work after the release are visible to Flyway, at the point of migration.
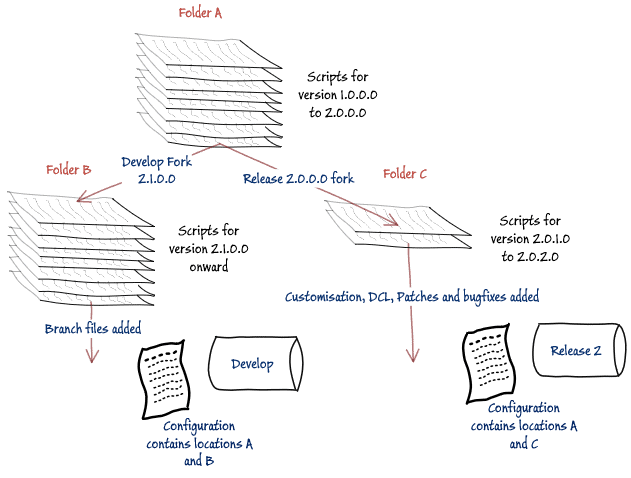
I demonstrate this technique in Maintaining Variants of a Database using Flyway Locations. It would still work even if the files were mistakenly given the same name, but different content, in the two branch directories, though the Version Control System would rightly protest. I refer to this technique as ‘interpolation’ because the extra scripts are interpolated into the sequence. Bugfixes would be merged into the development branch
At the point of merge, from branch to parent, you will need to prepare a single 'merge migration file' containing the cumulative changes made in the branch and add it to the parent with the correct version number. I use a comparison tool to do this, as I've described in Database Branching and Merging without the Tears.
The main difficulty with this locations approach is that if you are forking at the point of every release, this would require a new directory for each release and for the development branch, so you can quickly get a whole lot of directories and a long list of locations that must be accurate but are difficult to maintain.
One trunk directory, one release fork
We can reduce complexity by having just one trunk directory, and one branch directory for managing releases. To ensure that the trunk and release branches don't use conflicting version numbers (e.g., both trying to use V2.0.0), the main trunk would need to avoid using patch numbers when deciding on the version increment.
If an older version of the system in production (i.e., a system running a previous release) needs a patch, but you don't want to upgrade it to the latest version, you can use Flyway's -target parameter. This allows you to apply the patch to a specific version without migrating beyond it. For example, you can configure the -target version in the flyway.conf file in the release directory, along with the appropriate locations.
Mapping Flyway projects to schemas
Sometimes, complications arise from the need to add features that are only used for production and therefore only apply to a release. The most common example of this requirement is a script that provides access permissions defined in DCL, but it would also apply to special code for monitoring, alerting and production support.
This production-specific code should be stored in a separate location for the release, using a patch number to ensure it is versioned correctly. The simplest way to handle this is to put this code in a separate schema and manage it from a separate production Flyway project. I demonstrate this technique in Maintaining a Utilities Schema in a Flyway Project. It uses 'physical' branching of the Flyway project, but the technique can also be made to work with GitHub branching:

Each schema in a database system such as PostgreSQL or SQL Server can have its own project, though I've only experienced a single 'maintenance' schema controlled that way. The only problem I've come across is with the clean command, which will delete every object in the schemas listed in the project configuration. However, this is no problem if you have separate schemas for separate projects. A Flyway project can place objects in schemas other than those listed in the flyway.schemas configuration, but this is not advisable as it will lead to inconsistencies.
Simplifying forking using baseline migrations
Earlier, we looked at managing forks in Flyway using the -locations and -target and configuration items. By using Baseline migrations, we can simplify things further by removing the need to access the trunk directory at the point of forking. If we create a baseline migration file at the version of the previous release and use it to create a new develop branch, then Flyway will ignore all prior migrations and so won't try to validate them. The locations won't even need to include references to them once the development databases have all been cleaned for the new development cycle.
This implies that there should be just two permanent branches, main and develop, and that all feature branches are forked off and then merged into the develop branch. The main branch should keep all the migration files within reason. It will only ever, on a release, use the files from the current development cycle.
The Develop Branch should, in this method of using Flyway, merely consist of a series of baseline files for historical releases, sufficient for the developers to recreate a previous release when necessary for debugging.
Only the current development cycle needs to be represented by the original migration files, and these are copied to the main branch for release. On a successful release, a baseline file can replace the need for the individual migrations, once the development database is cleaned and rebuilt. This baseline file is created from the successful release candidate before the production features such as permissions, access controls, and maintenance/monitoring features are attached.
This technique is shown in the following illustration. One might blink at the daunting number of old migration files, and the consequential slow build time, but how often do you build a production system from scratch?
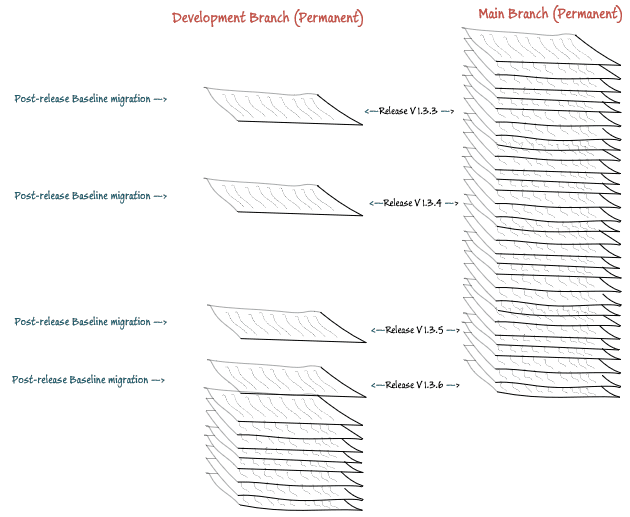
Baseline migrations are now supported in all editions, though only enterprise edition will generate them automatically. However, you can still create a build script to the point of the last release, and name it as a version file to the release (V1.3.6 in the drawing). The disadvantage is that you cannot keep previous build scripts in the same set of locations, and you would need to clean and migrate each of your development databases to bring them all up to the correct level.
The feature branch database
This baseline migration principle can be applied to feature branches. If you create a new copy of a database at the point of the fork, and we acknowledge the seniority of one part of the fork as trunk and the temporary nature of the other as branch, then the branch isn't obliged to be able to directly access the previous migrations to do the development work. Instead, it can use a baseline migration to build the version at the point of split, after which, previous migrations would be ignored anyway. Because the previous migrations aren't there anyway, there is no downside to building a clean database. This can be done from the initial migration that can be an ordinary migration file rather than a Baseline migration.
Retaining archaic migrations
If you are using baseline migrations for branches to avoid having to process all the old migrations, why keep them for main? The most important reason is that Flyway checks all the files that were used to build the database before it executes a migration command and throws an error if a file has changed, if a file has vanished or been added. The migration run is the 'audit trail' of this version, and proof that it is the version that it says it is.
As well as the highly unlikely requirement of providing the means to allow the production database to be recreated, but without the production data, the migration files contain block comments and end-of-line comments that explain the code and the reasons why it was done a particular way. Also, the chain of files is sometimes necessary for tracking down a subtle bug to re-create old versions for testing.
If you are happy with the idea of losing the immediate convenience that comes from retaining the entire migration sequence, there are other ways to get the benefits. If you are working with a database system that allows you to attach comments and documentation directly to the objects and will generate the comments with the objects in a build script, the documentation problem can be circumvented by extracting the documentation from the source files and adding it directly to the objects so that they appear in build scripts.
The second problem, recreating the same version, goes away if you generate a build script at the end of a migration run, using whatever means are provided by the database system you use. Because you are saving the migration files into source control anyway, both problems go away.
You can, of course, after doing a backup, remove the paths to all your migrations files from the 'locations' value in the Flyway configuration with the location containing a single 'static' script that has the same name of the last successful version, and then run the 'Repair' command.
Conclusions
Flyway easily accommodates the requirements of team-based databases developments by allowing several independent strands of development to be worked on independently on different databases and tested independently too. I've already written in other articles about the occasional complications of the merge process, which are only daunting if other teamwork processes are insufficient to prevent clashes. There are tools and techniques to assist even complex merges.
One might wonder why Flyway provides the means to allow database developers to circumvent the strict enforcement of versioning. Why, for example, allow 'repeatable' migrations, script-based migrations, configuration settings that allow skipping migrations or running them out of order, the repair command, and so on, to subvert the process? The answer, I believe is that Flyway facilitates versioning rather than enforces it. It aims to support development teams with the techniques they choose to use, rather than require them to use a particular methodology. One man's meat, as they say, is another man's poison.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Loading comments...