Database Branching and Merging without the Tears
Armed with a schema comparison engine and an object-level directory of the source for every recent version of the database, you'll be able to remove a lot of the uncertainty around merging database changes back into development.
Branching and merging in database development is similar to branching and merging in software development, but it is a mistake to expect them to be the same. In particular, the extent of the interdependencies can come as a shock.
In a well-disciplined team, merging database changes from a branch back into development will generally proceed with peace, love and understanding. However, you will sometimes find that a table or view on which your code depends has been altered by someone else in a way that breaks your code. Conversely, you might discover that since you created branch, another developer has merged in a change that creates a new dependency on a table that you’ve now altered.
Almost every engineering process that involves parallel tasks has the same potential problem when it comes to the point of assembly. For a database, the objective of each merge is to safely update a database that contains data, without breaking any of the complex interdependencies between its components.
In this article, I’ll offer some advice on how to achieve this.
How to do database branching and merging
There are several points in a database development where any shortcomings in the methodology in use will become painful. The first of these is when changes to the database have to be merged into the development branch. The second is when new features are scheduled for release.
My general advice for merging database changes as painlessly as possible is as follows:
- Apply strict database versioning – a great deal of confusion in branching, merging and testing is avoided if it is always clear what version a database is at, the version that any migration script runs from, and the version it migrates to.
- Design in resilience to change – the team must discuss all planned changes to the database and get an understanding of the potential problems of breaking dependencies. The database should be designed to allow features to be less vulnerable to changes by using views and table functions to provide interfaces between features.
- Use feature branches – each feature should be developed within a separate branch and merged back into the development branch. This is usually done once it is completed, and scheduled for release and deployment, rather than when it is merely finished, so that testing, training and sign-off can be coordinated and planned.
- Deploy single purpose patches – branches that are make changes that are, essentially, patches rather than new features should be small: don’t try to bundle several fixes and tweaks into a single branch. A single-purpose branch is easier to handle, particularly at merge.
- Archive the object level source for all recent database versions – version control systems, such as Git, can help to track changes to your database schema and allow you to merge changes more easily. The best artefact for this purpose is an object-level script because it identifies immediately which objects in the database have changed, and in what way they’ve changed.
- Test before merging – thoroughly test the branch changes with integration tests to ensure they don’t break anything, before merging them back into the development, and then into the main branch. The failure of a release from the main branch tends to be rather public and messy and you want to avoid it!
- Use tools to automate the process – when merging back into Main, you should set up, where possible, an automated workflow for parallel integration and performance testing. For a release candidate, this workflow will include the various aspects of deployment. Merges into Development require similar testing but will require UI-based tools as well, because it can never be entirely automated. RDBMSs provide system views and other tools to help with this process. You will need them.
Branching and merging challenges
In a traditional database development environment, developers made use of the intrinsic multi-user, multithreaded capabilities of the RDBMS to avoid conflicts in a system that, by its very nature had many interdependencies. They shared a single development database and coordinated their work by checking on what changes were being made to the database, and by whom. Most RDBMSs provide this information; for example, SQL Server uses the default trace and nowadays Extended Events.
Potential conflicts were negotiated then and there by normal development team processes. Any foolishness would be shown up at the regular integration tests, usually conducted overnight. To avoid embarrassment, developers often developed the habit of ‘tear-down’ scripts that could undo experimental or temporary work.
In a database development system that allows branching, developers will normally prefer to work on an isolated version of the database so that any changes are theirs alone, and these changes constitute the work of the branch. The difficulties arise, of course, when it’s time to merge in those changes back into the development branch. You need to understand which objects are affected by your new branch version and to check for any conflicting changes or broken dependencies that may be caused by your changes, or by changes that others have committed the development branch, in the meantime.
Most development teams will try to reduce the scale of the work at a merge by trying to avoid having different branches working on the same objects and negotiating on changes to any objects that other active branches reference. However, it will never eliminate the problem completely; if you rely on the version control system to auto-merge the changes, you’ll be in for a hard time.
Most RDBMS will provide system views that allow you to detect changes to objects on which your code depends and detect dependencies on objects that you wish to alter. However, this is more awkward to do when development work is done in an isolated branch, and so this check is usually delayed until the merge.
Fortunately, Redgate’s Schema Comparison tools have evolved over decades and can assist with merging changes into a database.
Using schema comparison to compare different versions of a database
At the simplest level, a schema comparison tool compares two versions of a database, in just the same way as any tool that checks differences in source code, except it doesn’t compare the text of the code but the result of the code. It does this by creating a hierarchical ‘model’ of both the source and target database and comparing them. It doesn’t just compare live databases: it can parse various other types of sources into a ‘model’ of the database, such as an object-level scripts folder containing a set of DLL scripts, or a build script. It also makes it easier to specifically include or ignore objects, or whole classes of objects from the comparison.
Having done the comparison, it can then go on to produce a ‘synchronization’ script that, for the objects and object types you’ve selected, would make the target the same as the source, if the target was a live database. If you include just a couple of tables, for example, the script will make the changes to these tables on the target database to so that they become the same as the source.
If the target is a live database and there is already data in the tables, it will do its best to make sure that the data is preserved in the altered tables. If there is any doubt, you are advised to review the synchronization code.
How schema comparison tools help with database merging
At the point of merge, we can use the schema comparison tool to review what work has been done on the feature branch, and also check for any potentially conflicting work that has been committed to the parent branch (Development) in the interim.
The first step of this process is to compare the current branch database with the database as it existed at the version at which the branch was created. This is why it is so useful to keep an object-level directory of the source for every recent version of the database. This will give us a ‘first-cut’ migration script for just the branch changes. So far, so good, but this alone doesn’t guarantee a successful merge.
The second step is to compare the current branch database to the current version of the development branch, because this will also include the changes made as a result of every successful merge into the development branch, since the branch was created:
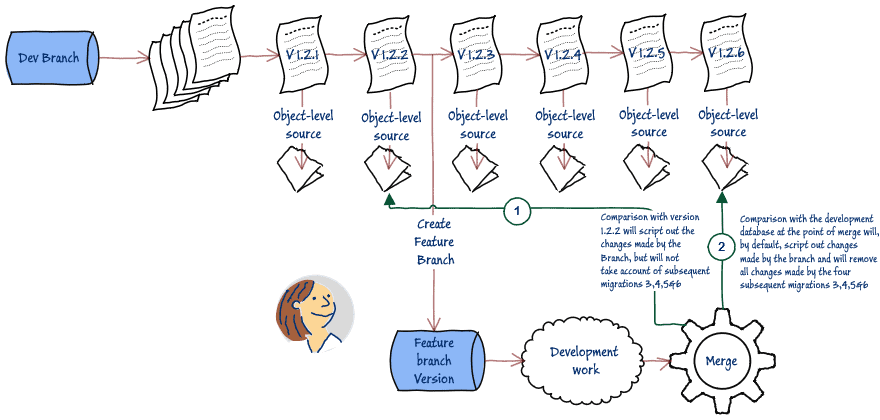
For step 2, it’s important to remember that this is a database-level comparison, the net result of which is a merge migration script that will make all the changes necessary to make the target database (development branch database) the same as the source (your branch database).
This means that not only will any new branch objects be added, but any objects others added to the development branch, in the meantime, will be removed, and any alterations will be undone! In other words, the synchronization script will carefully remove all the changes made to the development branch since the moment you made a copy at the point of branching. This is not the royal road to team cohesion.
To get around this possibility, I have seen it suggested that you should pull all the changes made on the parent branch on to your branch. This negates much of the purpose of branching, and it also means you can no longer do a comparison with the version you started from so as to tell you the totality of changes made in the branch.
It is much easier, I think, to use filters to restrict the comparison to just the objects that you know, from your ‘first-cut’ script, are involved in the branch development. What if the tool you are using to compare the versions of the database doesn’t allow you to specify the list of objects you want included? In that case, you need to edit the synchronization script to take out all this extra code that is attempting to reverse committed changes made by other merges.
Checking for conflicting changes and broken dependencies
Having restricted the comparison, between the current branch and the latest version of development, to only those changes made by the branch, the team can review a list the objects that will be added, deleted or altered and decide what, exactly is merged. Generally, it will be all the branch changes, but it is quite possible that other objects have changed in the interim, causing dependency issues such as:
- Conflicting changes to the same objects
- Intervening merges that affect changes to database objects on which the modified branch objects depend
- Branch object changes that affect code changes made by intervening merges (for example a parent branch merge that created a new dependency on an object has now been altered in the branch)
These issues are usually the result of a name change in a parameter or column, or an incompatible change in a data type, but can involve other more subtle ‘build-breakers’. These changes may require discussion and negotiation where a compromise is necessary.
As well as poring over the comparison, the team will also review the merge migration script that was generated. Are there any warnings in the script? Is the script doing puzzling things, and making changes that aren’t anything to do with the work of the branch? Are the changes what you’d expect? Source control should be able to confirm your understanding of changes to all the objects and dependencies.
Armed with all this information, they can alter the merge migration script in the light of the subsequent merges.
Testing the ‘merge migration’ script
Once the team are happy that the script is changing only the required objects and won’t cause conflicts or broken dependencies, they need to do integration testing. Do all business processes continue to respond exactly as required? Does your new feature comply with the specification? If the migration script refactors existing tables, and therefore affects existing data, you’ll want to make sure that by applying it to the current release you get a database in exactly the state you expect and where equivalent queries (before and after refactoring) return the same results.
If you’re using a tool like Flyway to run the migrations, then you can exploit clever tricks like Testing Flyway Migrations Using Transactions to test a tricky migration repeatedly until it’s right.
Conclusion
Branching and merging in database development requires more controls than the traditional shared approach. There are two important elements to allow easy merging of branch work in a database.
- You need to know what objects were changed by the branch, in order to be able to tell SQL Compare, or whatever synchronization tool is appropriate for your RDBMS, what objects need to be the ‘players’ in the synchronization.
- You need databases and scripts to be properly ‘versioned’, using a tool like Flyway, so that there is no doubt or guesswork.
To handle merges serenely, it is extremely useful to be clear about dependencies, especially interim changes in any objects in the database, such as tables, views and routines, that the objects in the branch rely on.
A tool such as one of Redgate’s schema comparison tools works if it has the right information and is asked the right question and will produce forward and backward migrations with no difficulties and overcomes most of the issues that can appear at the point of the merge of team-based development work.
Further reading:
- Branching and Merging in Database Development using Flyway – how to exploit the branching and merging capabilities of Git for scaling up team-based development, when doing Flyway migrations.
- Flyway Branching Walkthrough – a demo of using Flyway Teams to support database branching and merging, where the team split the development effort into isolated, task-based branches, and each branch has its own development database.
- A Simple Example of Flyway Development using GitHub Branching –demonstrates one way to do branch-based database development with Flyway, using GitHub to manage the branches and Flyway configuration files to allow Flyway to switch smoothly between databases, when we move between branches in GitHub.
- Database Testing in a Flyway Development – If you can test and evaluate databases, and database objects, at every phase of the database development lifecycle, then you are much more likely to be able to adopt continuous delivery. The further down the delivery pipeline that bugs appear, the more costly in time and resources they are to fix.
Tools in this post
You may also like
-

Article
Flyway for SQL Server Data Tools Users
If you are using SSDT for authoring, building, debugging, and publishing a database project, how do you change to, or preferably migrate towards, a Flyway-based database development? Flyway doesn't need to replace any code part of SSDT, but if allowed to manage every release candidate, it does allow for much cleaner branching, merging, and deployments.
-

Article
A Real-world Implementation of Database DevOps: People, Processes, Tools
This series of articles describes a path you can take to transforming an existing, manual and error-prone database development and release process into an automated and reliable Database DevOps 'pipeline', starting here with an overview of what we set out to achieve, and the people, processes and tools involved.
-

Article
Simple Safeguards for PowerShell Scripting with Flyway
This article demonstrates simple techniques to security-check any processes that use Bash or PowerShell scripts to automate database tasks, when using Flyway. These checks help ensure a script is trusted, hasn't been tampered with since creation, and doesn't contain commands commonly used with malicious intent. They add a valuable layer of protection, without sacrificing the power and flexibility that makes Flyway so effective.
-

Live training session
Flyway 101: Using version control
Talking about how migration scripts are powerful but when we expand a workflow to the wider team and processes version control is crucial for collaboration and how we can set this into a project.
-
Live training session
Redgate Flyway: How to deploy using a state-based approach
Join us for an in-depth training session on State-Based Deployments with Redgate Flyway. This webinar will guide you through the fundamentals and advanced techniques of the state-based deployment model, a powerful approach for managing database changes.





