





Why data anonymization is important to organizations – and their customers

The rise of the digital era has led to increasing concerns among individuals around the protection of their personal data. In 2022, for example, 24% of individuals exercised their right to Data Subject Access Requests, and this rose to 28% in 2023 according to Statista research results.
Alongside this has been the creation and ongoing development of laws and regulations such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), the Health Insurance Portability and Accountability Act (HIPPA), and the Australian Privacy Principles (APP).
Though these regulations do not explain in detail what is allowed or not allowed, they do indicate that to be compliant, organizations must prove that they have taken reasonable steps to protect data, wherever that data lives within your organization.
That includes development environments where database copies are used to test proposed changes. This test data also needs to be protected and it can be done through data anonymization, as suggested in recital 26 of the GDPR:
THE PRINCIPLES OF DATA PROTECTION SHOULD THEREFORE NOT APPLY TO […] PERSONAL DATA RENDERED ANONYMOUS IN SUCH A MANNER THAT THE DATA SUBJECT IS NOT OR NO LONGER IDENTIFIABLE
What is data anonymization?
Data anonymization is the deidentification of data to protect the privacy of individuals. This normally involves erasing, encrypting, or replacing Personally Identifiable Information (PII) like names, social security numbers, and e-mail addresses. The UK Information Commissioner’s Office puts it perfectly in its ‘Introduction to anonymisation’:
It’s interesting here how the potential of using data to innovate is highlighted as a good thing ... provided privacy is at the core of efforts to harness that potential.
Difficulties with data anonymization
When it comes to testing, developers and Quality Assurance Engineers (QAs) want a quick and easy way to self-serve a compliant copy of a production database on demand for testing purposes.
Ideally this copy should resemble the production database as closely as possible because production data provides valuable insights into user behaviour. By testing with realistic data, teams can proactively identify how the application behaves in edge cases and unexpected user interactions before deploying it to the live production environment.
However, individuals in roles such as Database Administrators (DBAs) often find that provisioning a compliant copy of data can be a time-consuming task, demanding an in-depth understanding of the database.
Data anonymization starts with scanning the database to identify any PII and subsequently generating replacement data that maintains the integrity of the original data while ensuring privacy. However, the complexities do not end there. Production databases are dynamic and change constantly as new transactions are processed. Meaning that test databases must be regularly updated to provide an accurate representation of production.
How Redgate Test Data Manager can help
Redgate Test Data Manager was developed and built from the ground up to specifically help organizations get started with an iterative, maintainable and repeatable pipeline towards achieving compliant test data.
A big part of that is its anonymization capability where it takes a fresh copy of a database, scans the schema for any PII, creates a set of masking instructions, and masks the PII in place.
It is accessible through the Graphical User Interface (GUI) which is a suitable place to start. It offers an intuitive approach to learning about Redgate Test Data Manager by providing an end-to-end workflow from provisioning through to subsetting and anonymization. Alternatively, the different capabilities like anonymization are available through a Command Line Interface (CLI) which can be wired into existing release pipelines to automate the process.
Either way, it can be broken down into 3 steps.
1. Classify
The classify operation analyses the schema of a given database to identify any PII, producing a JSON or YAML file describing where in the database the PII lives. This provides a quick and repeatable alternative to finding and annotating potential PII in a database.
The use of JSON or YAML files also ensures that the results of the analysis are structured for easy organization-wide sharing, the human-readable format allowing users to understand its content and make modifications without specialized tools.
Out of the box, it supports the classification of PII defined by the National Institute of Standards and Technology (NIST), but this is not set in stone and can be configured to catch information outside of the NIST definition. More on this later.
2. Map
The map command takes the classification file and translates it to a set of instructions called the masking file to be used by the masking engine. This translation step also has some default behaviour such as enabling determinism for certain datasets like FamilyNames, GivenNames and Cities.
3. Masking
Using the masking file, the mask operation anonymizes and replaces the identified sensitive contents of a given database, ensuring that they are no longer identifiable while maintaining the context and characteristics of the original data.
To achieve this, the operation uses a dataset to generate the replacement values. Out of the box it comes with datasets required by default classifications and common use cases such as Lorem Ipsum and Null Values. This means that users can get their databases to an anonymized state quickly, with little to no configuration.
This operation also support determinism when generating replacement values. Here, the tool will always generate the same value for a given input (e.g., every instance of “John Doe” will be replaced by “Jane Doe”).
The tool also accepts a deterministic seed which allows it to always map the same input to the same output across different runs, and across multiple databases. This ensure consistency and can be useful in cases where the same data is living in various locations.
With determinism, users can maintain the referential integrity of their data, and it also plays a big part in generating reliable test data. Constant changes in test data can affect the confidence and quality of tests, and being able to consistently generate the same data makes it easier to reproduce test scenarios and maintain the integrity of test cases.
Configuration
Some organizations may have anonymization requirements outside of the NIST definitions, due to industry or internal data privacy and security policies. Taking that into account, Redgate Test Data Manager is highly configurable.
Users can create their own datasets or even overwrite existing ones to tailor the tool towards their needs. For example, this is a custom pattern-based dataset for a hypothetical 'MembershipId' which will generate values such as ABC-456-78:

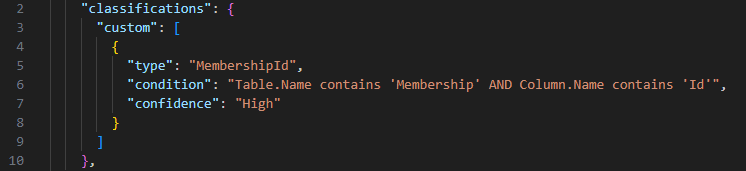
Users can also create their own classification rules with the same logic the tool uses internally for its default rules. For example, this is a custom classification rule to catch 'MembershipId', which also uses the custom dataset defined previously:
This is all contained in an options file that is identical across the commands and can be passed through at any time. This means users can have a centralized location for all the options between the different steps, making it easier to maintain. As a result, there is no need for different development teams at different times to create or configure their own classification rules. This both speeds up development and makes development processes consistent and repeatable, across both teams and databases.
Summary
Data anonymization can be a complex and time-consuming process, but it is also important if organizations want to achieve compliance and reduce the reputational and financial risks of a data breach. Out of the box, the anonymization capability of Redgate Test Data Manager provides users with the ability to get started with identifying and masking PII in their databases. The configurability of the anonymization feature allows them to iteratively move towards full compliance and tailor the tool to the context of their organization.
To discover how Redgate Test Data Manager can help you mask and anonymize your data and streamline your test data management processes, check out Redgate Test Data Manager here, or get in touch.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
 Redgate Test Data Manager
Redgate Test Data ManagerYou may also like

Blog
Loading comments...