





How to Avoid Rollbacks in Database DevOps
One of the most common questions we hear from teams working to improve their database development and delivery processes is how they can best react when things go wrong.
Because data is often a company's most valuable resource, lost or incorrect data can cause dramatic problems and great expense. Having experienced this in the past, teams are often required to be prepared for problems. They need to react quickly and remediate problems with as little manual work as possible.
This need often causes teams to ask further questions: can the popular Blue/Green deployment model be used with databases? If not, what's the best approach?
In this post, we dig into these topics:
- What is the Blue/Green deployment model?
- Why the Blue/Green deployment model doesn't work for databases
- Why prepared or automatic rollbacks can cause data loss or other undesirable consequences
- The case for avoiding rollbacks with the Expand / Contract model
- Reality: some organizations need training wheels
- Further reading
What is the Blue/Green deployment model?
Blue/Green and Red/Black deployment models are widely used for deployments of centralized apps such as web services. In these deployment models, a load balancer and multiple versions of an application are used to perform a deployment.
For example, let's say a production component is at version 2.0. We wish to deploy version 2.1. Using a Blue/Green or Red/Black deployment model....
A. Our load balancer is currently pointing traffic to "Blue" components
This is a group of resources in production running version 2.0.
B. We deploy version 2.1 to "Green" components
This is a separate set of resources which are in the production environment, but which are NOT currently active. We may test the "Green" components to our own satisfaction before proceeding.
C. We cut over from "Blue" (version 2.0) to "Green" (version 2.1) by redirecting the load balancer
This directs traffic to the "Green" resources now, and not the "Blue". This may be done gradually or all at once, depending on your implementation.
One of the incredibly attractive things about the Blue/Green model is that after the deployment you may leave all of the resources in production for some time to let the deployment burn in. If something unexpected occurs and you'd like to "undo" the deployment, you can...
D. Roll back by directing the load balancer back to the "Blue" resources (version 2.0)
Many teams have automated this process so that production deployments and roll backs of this type are quick and easy to perform.
Why Blue/Green doesn't work for databases
Using the Blue/Green model alone doesn't enable simple rollbacks for changes that impact databases. This is due to the stateful nature of a database. Here are some considerations:
What about data written after the change?
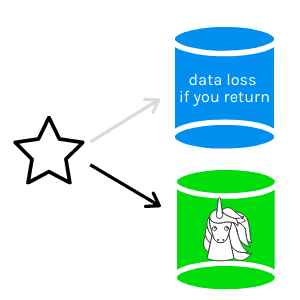
Let's say that we have a "Blue" copy of the database, and we create a "Green" copy of the database to deploy to. Maybe we work some storage magic and can do this with a SAN snapshot or some other form of cloning so that we can create a new writeable "Green" copy of the database very quickly, deploy to that, and cut over immediately.
Note: for most teams, we would need to somehow get this done with a very small downtime window, and perhaps have written our application to go into a read-only mode briefly to compensate -- but even that might be considered downtime and be problematic for many teams. For the sake of this example, assume it works.
As soon as we are live after cutting over to "Green", data can change anywhere in that database based on user activity. As soon as this data starts being written, we have a problem:
- The "Blue" database is MISSING all data modifications that have happened since the cutover
- Data loss is almost always unacceptable as part of the default rollback strategy -- it is usually a worst-case scenario and most want to avoid it entirely
Often when thinking about this, it's natural for people to ask: what if there's a way for data to be replicated / transmitted between the "Green" database and the "Blue" database, so that you can switch back?
Data replication makes blue/green even harder to implement
Most databases simply aren't designed to make this work for all types of changes. Here's a limited (but not exhaustive) list of changes that would be difficult to handle:
- What if we change the datatype of a column in the "Green" database -- how does that get written to the "Blue" database?
- What if part of the deployment is running a data modification script against the "Green" database, and then data changes in the modified data afterward? How would that be replayed against the "Blue" database?
- What if we move a column from one table to another in the "Green" database? How would the database know to replay modifications to that column against the "old" table in the "Blue" database?
- If we did have a way to "fork" all application traffic and send it to both databases, what if the data diverged on them? This could be due to timing/traffic issues, such as a deadlock occurring in one of the databases and not the other, for example. How would we know that the data was in sync and that it was safe to move back?
In other words, while some databases do allow a form of scale-out writes, this is often for the purpose of write performance and is not designed with features to enable a Blue/Green database deployment model with rollbacks.
Why prepared or automatic rollbacks can cause data loss or other undesirable consequences
After discussing the Blue/Green deployment model, another question often comes up right away: can we easily generate code to roll back to the prior database state? Manually creating code to undo a deployment is time consuming and error-prone, so teams naturally are interested in a way to automate this.
There are a couple of ways that rollback scripts can be prepared in advance of a deployment...
- Comparison, aka "state based" tooling can automatically generate code to revert a database to the previous state -- this is generally generated as one large rollback script
- "Undo" scripts may be automatically generated for changes that use migrations by some tooling -- these are generally generated as individual rollback scripts for each step of the change
There are two problems.
 First problem: some of these scripts could cause data loss
First problem: some of these scripts could cause data loss
Most teams don't want to "undo" certain types of changes, because of the risk of data loss. Typically, these are changes to table structures.
On example is a deployment that adds a data structure: perhaps it adds a new column in a table, or maybe it adds a whole new table. If data starts being added into the new data structure, is it OK to run a rollback script that drops that data structure and loses the data? Sometimes it is OK, but often it will NOT be OK.
There are similar problems with many other schema changes for tables.
Second problem: how do you generate a rollback for data modification scripts?
Not all changes are schema changes. Sometimes we need to include changes to data in our deployments as well.
In some cases, data modification scripts are combined with a schema change, such as moving a column from one table to another table and needing to move the data along with it as well. In other cases, the data modification script is a data correction or a data loading task.
In all cases, it's usually not obvious how to "undo" the data modification after the deployment has completed and writes have begun against the database. Should an undo script attempt to reset the data to exactly how it was before? How would it do that? Should it try to somehow account for the changes that have been made since the deployment completed?
These questions require careful thought and attention from the team designing the change -- and the more complex the deployment is, the trickier it is to address this question.
The case for avoiding rollbacks with the Expand / Contract model
The Expand / Contract pattern for database changes goes by a few names. It is frequently called the "Parallel Change" model. In this video, it's referred to as the "N -1" model. When I first learned this pattern more than 15 years ago, we didn't have a name for it at all -- it was just what we did.
 In the Expand/ Contract model, we focus on only deploying backwards compatible database changes.
In the Expand/ Contract model, we focus on only deploying backwards compatible database changes.
This is achieved by deploying database changes in phases:
Phase 1 – Expand: Introduce changes to existing structures in a backwards compatible fashion.
Phase 2 – Transition: Modify existing code to use the new structures. This is often combined with feature toggles in applications with the idea that if anything goes wrong, the feature toggle may be easily disabled by a business user.
Following phase two, there is a waiting period in which the change burns in.
Phase 3 – Contract: Remove / clean up older structures.
A great benefit of the Expand/Contract model is that there are terrific free online resources:
- Evolutionary Database Design by Pramod Sadalage and Martin Fowler gives a comprehensive overview of an Expand / Contract approach in the context of agile methodologies
- Refactoring Databases: Evolutionary Database Design by Pramod Sadalage digs into refactoring patterns in the Expand / Contract model for everything from adding indexes to merging columns to splitting tables
I personally have had great success working in teams using the Expand / Contract model. My experience is that this pattern works best when a team can deliver a steady stream of deployments where each deployment contains only a few changes.
This makes it much easier to understand what each deployment does and what it could potentially impact. This improvement in ease to review changes well is a major factor in why I believe the Expand / Contract model helps teams avoid rollbacks.
Small batches of changes also mean that if something does go wrong, it's simpler to identify what should happen to correct the situation and to prepare a selective fix for it. This speed of diagnosis enables teams to be better able to use a "roll forward" approach, and quickly set up a reactive deployment to respond to a problem identified in production.
Note: there is a reason that the Evolutionary Database Design patterns above pair with Agile methodologies: practices such as Continuous Integration and automated testing help teams ensure that a roll-forward approach has quality changes flowing through the pipeline.
Reality: some organizations need training wheels
Not every team can expect success if they announce, "we don't need to prepare rollback plans or scripts because we are using the Expand / Contract model for database changes."
Some teams work in a regulated environment where they are required to prepare rollback scripts due to documented internal procedures which have been established for years. Procedures like this don't change other night.
Other teams work in organizations which every second of downtime or poor performance has extremely high costs for both the organization and its customers, where teams will never want to wait for a build to run if they can potentially avoid it.
Many teams who are currently deploying large groups of database changes on an occasional basis using manual methods will also have a hard time instantly moving to frequently deploying small batches of database changes. It takes time to implement the process changes related to CI/CD and to adjust to new ways of working!
For these reasons, many teams take the following approach:
- Evaluate the Expand / Contract pattern and its suitability for their team, discussing with team members how they can take on these patterns
- Investigate how the team can implement Continuous Integration for the database and begin implementing automation to remove manual work from the deployment process -- this automation is typically done in non-production environments initially and can be undertaken on a gradual basis if needed
- Set goals toward moving towards smaller, more frequent deployments for database changes and implementing the Expand / Contract model
While working through this time period, rollback scripts (whether automatically or manually generated) are often used as "training wheels."
During this time period, it is helpful to track the following metrics:
- How much time is spent preparing rollback scripts
- How much time is spent testing rollback scripts
- How many times rollback scripts are used in the production environment
As your team becomes more skilled at implementing the Expand / Contract pattern -- and in my experience this is a pattern which teams get better at over time -- you should not only be able to improve these metrics, but you can also use these metrics in support of changing those entrenched policies and mindsets which declare "you must have a rollback for a database change."
Further reading
- Implementing a Rollback Strategy - How rollbacks work with Redgate Deploy
- Zero Downtime Database Deployments are a Lie
- Evolutionary Database Design by Pramod Sadalage and Martin Fowler
- Refactoring Databases: Evolutionary Database Design by Pramod Sadalage
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
You may also like

Blog
Why Organizations choose Flyway

Blog
Loading comments...