





The risks – and rewards – of using production data for testing
Data, and the way enterprises use data in areas like development and testing, has not traditionally been a focus for business leaders but that’s now changing. Data is more varied and complicated than ever before, for example, with enterprises using two or more different database platforms – and 40% using four or more. It’s also spread wider and further, with enterprises hosting their databases in a combination of cloud and on-premises infrastructures.
This in turn has led to increasing concerns about the safety of the data, with the Thales 2024 Data Threat Report highlighting that over the last four years data classification issues have persisted … and persisted:
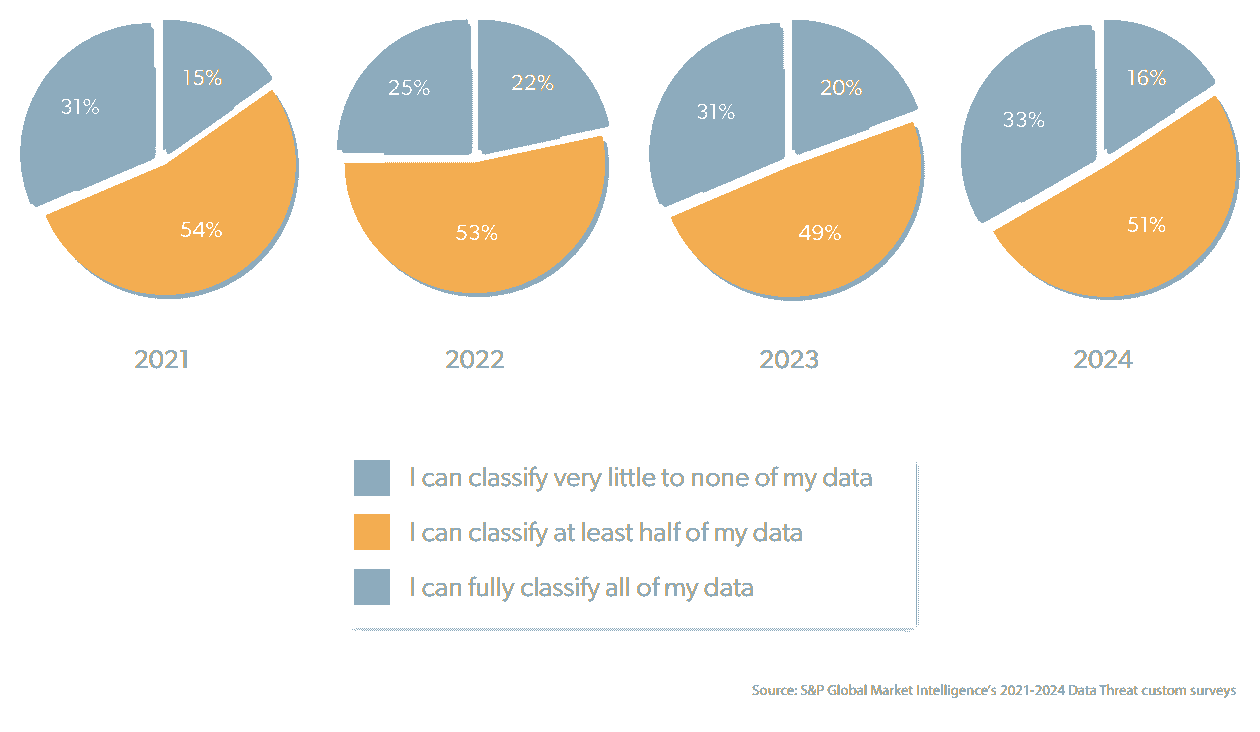
One in six enterprises have been able to classify little or none of the Personally Identifiable Information (PII) and sensitive data used in their production databases. Half say they can only classify around 50% of the data. Just a third can fully classify all of their sensitive data. And those figures have remained pretty much static from 2021 through to 2024.
There’s a lot of data around, and more is being generated and collected all of the time, yet two thirds of enterprises are having problems identifying and classifying it. Perhaps as a result of this, sensitive data discovery and classification is the top-cited security technology that managers plan to implement in the next 12 months.
Once PII and sensitive data is identified and classified, every database that contains the data needs to be protected by methods like masking, de-identification or anonymization. Not just to comply with any legislative requirements but also to meet customer expectations. The 2024 Thales Consumer Digital Trust Index Report explains why perfectly:
“Most customers (89%) are willing to share their data with organizations, but that comes with some non-negotiable caveats. More than four in five (87%) expect some level of privacy rights from the companies they interact with online.”
Recognizing where the risks are
Identifying and classifying data in production databases is only half of the story because the data itself spills out far beyond production databases which are the main focus for efforts to prevent data breaches. It’s spread across the business in many other environments where security measures are typically less stringent.
One of those, and perhaps the most important, is in development and testing, where developers are under constant pressure to update, maintain and add new features to applications along with the databases that collect and store the data they generate.
In order to do this, they need a copy of the production database to test their changes against. Not an actual copy containing all of that PII data. Instead, they need a copy that matches the volume, distribution characteristic and referential integrity of the original data, with any PII data masked, de-identified or replaced with synthetic data. That way the testing will reflect what will actually happen when changes reach production. Without it, errors creep in, bad code reaches production and the chances of failed deployments increase.
We’ve already seen, however, that two third of enterprises have problems making this happen and this was highlighted in The 2024 State of the Database Landscape report from Redgate, a global survey over 3,000 IT professionals. It revealed that nearly three quarters (71%) of enterprises use a full-size production backup or a subset of their production data in development and testing environments which are less well protected and monitored than production environments. Rather than data masking or anonymization techniques, 41% also have no approach for how they handle PII and sensitive data or are unsure.
So that one production database at risk highlighted by Thales in its Data Threat Report isn’t one database. It’s often all of the database copies used in development and testing as well. That’s a lot of databases and a lot of data at risk.
Mitigating the risks
The resolution to the issue comes down to changing the way production data is protected in development and testing environments. Where IT teams do make an effort, it typically relies on inefficient workarounds and laborious, manual attempts to mask PII and sensitive data. Developers are provided with database copies but they are inaccurate, out of date, and don’t truly reflect what impact proposed changes will have when they are deployed to production. Infrastructure constraints and space issues also result in shared development environments often being used, with many developers sharing the same database copy.
As a result, developers end up treading on each other’s toes, overwriting someone else’s changes, or waiting for an opportunity to test their changes. Development is slowed, inefficiencies creep in, and breaking changes lead to failed deployments.
A more structured approach is required. One where data classification and masking is automated, and developers can be provisioned with sanitized copies of the production database. To avoid any space limitations and time pressures, virtualization and container technologies should also be taken advantage of so that the copies are a fraction the size of the original and can be provisioned in minutes.
If it sounds like a big ask, it’s not. This test data management (TDM) approach is well-proven and has been shown to deliver big benefits to IT teams. Surgical Information Systems used Redgate TDM technology to provision masked and virtualized copies of its production database that can be created, updated and refreshed on demand. This saved a minimum of 12 hours a day across all of its team, equating to savings of $268,320 per year.
Reaping the rewards
The rewards of introducing an automated, simplified, easy to manage TDM process are many. Firstly, PII and sensitive data is protected in development and testing environments – the environments where it is most at risk.
Secondly, by introducing a TDM process, an audit trail is provided which demonstrates how and when database copies were provisioned, and the measures taken to mask, de-identify or replace sensitive data. Compliance with legislative frameworks becomes the default position and is a natural part of the development pipeline rather than being an awkward add-on.
Thirdly, rather than waiting sometimes hours for an opportunity to test their changes with unreliable database copies, developers can self-serve their own development environments which are accurate and take seconds to refresh. Freeing them from inefficient processes, increasing their confidence in the quality of the code they produce, and enabling them to work faster.
And finally, it leads directly to further cost savings. By automatically classifying and masking the PII and sensitive data used in development and testing, security is integrated into the software development process. This is often called DevSecOps and IBM’s Data Breach Report reports that enterprises with high DevSecOps adoption save $1.68m compared to those with low or no adoption.
Find out more about Redgate Test Data Manager
Redgate Test Data Manager simplifies the challenges that come with TDM and modern software development across multiple databases. It automates data classification, masking and test data provisioning through a straightforward, integrated approach. By doing so, it enables any enterprise to introduce reliable and compliant test data delivery to its development process, which in turn improves the quality of code, minimizes risk, reduces failed deployments, and enables teams to release features and updates to customers sooner.
Find out how test data management is one of the key ways enterprises can deploy changes on-demand while also doing so reliably and safely, reducing their change failure rate – and gaining a demonstrable ROI. Read the blog post, Where’s the money? The ROI of test data management.
Learn why the leading independent analyst and research house, Bloor, thinks enterprise-level organizations are increasingly and acutely aware of the benefits of a TDM solution. Download Bloor’s Test Data Management 2024 Market Update.
Read more about how enabling DevOps Test Data Management can improve your release quality, reduce your risk, and deliver value to customers sooner. Visit the resource page.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
 Redgate Test Data Manager
Redgate Test Data ManagerYou may also like

Blog
Why Organizations choose Flyway

Blog
Managing Test Data for Database Development

Blog
Loading comments...