





Data privacy next steps: Compliant Database DevOps
Over the last few years we’ve seen a shift in customer concerns around personal data, brought about by frequent reports of breaches involving famous brands and the growth in new legislation designed to combat this trend.
The Facebook Cambridge Analytica scandal in early 2018 was a wakeup call for many. Here was a platform that we’d put our trust in to share intimate moments of our lives with friends, supposedly in private. Suddenly this data was being used for purposes outside of what we’d signed up for. Unsurprisingly consumers started to question the security of their data across the board. If personal data wasn’t safe with tech giants like Facebook, Twitter and LinkedIn, where was it safe?
This has had a dramatic effect on IT teams. A fear of being the next headline has stalled the rollout of digital transformation programs, with IT teams being extra careful when it comes to changing anything to do with the database. But the solution doesn’t lie with maintaining the status quo at the expense of progressing DevOps or similar initiatives.
In its 2018 End-of-Year Data Breach Report, the Identity Theft Resource Center (ITRC) found that the total number of exposed records containing personally identifiable information (PII) increased by 126% from 2017 to 2018. What’s interesting is that over the same period the percentage of breaches originating from hacking fell from 59% to 39%, while those due to unauthorized access grew from 11% to 30%. So while we may have done a good job strengthening perimeter defenses and educating employees on email and web security, sensitive data continues to flow out from IT systems.
Taking a ‘lock it down’ approach to database development isn’t the answer. By aligning DevOps through the entire stack, IT teams are better equipped to handle vulnerabilities, speed up remediation, and drive up quality to prevent errors in the first place. With Database DevOpDs, data privacy and protection is baked into the development and release cycle to strengthen an organization’s ability to meet regulations and mitigate the impact of any breaches.
Start with version control
The implementation of even the most basic DevOps concepts like version control – commonplace in application development – has been slow for databases. Redgate’s 2019 State of Database DevOps survey found that only 55% of organizations version control their database code:
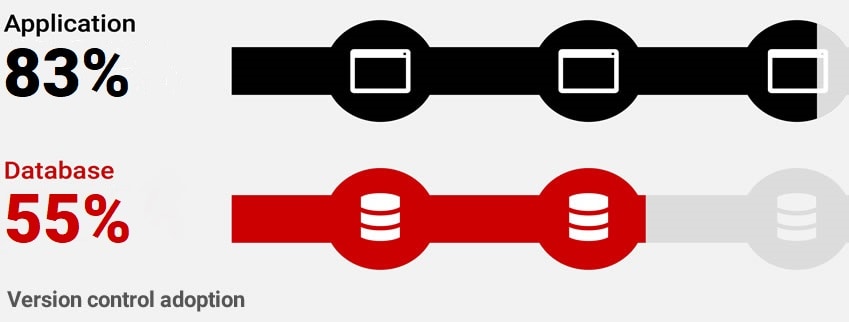
This presents a huge gap in knowledge for the history of the database – what changed, when, by who, and what version of the application it corresponds to, etc. This knowledge is crucial when troubleshooting and resolving errors, and vital for building up an audit trail when responding to a data breach.
Another concept that lags behind is sandboxed database development. Redgate’s research found that in nearly half of teams, developers work on a single shared database. Working in shared development environments makes experimentation difficult. By contrast, providing developers with their own dedicated copy of the database gives them the freedom to try out new things, risk-free. This often leads to faster resolution of bugs, and improved code quality. Version control also provides the communication bridge for dedicated development teams, handling the merging of changes and keeping everyone in sync.
Standardize development
By establishing a single source of truth for the latest version in Development, via version control, we know precisely what code should progress through the different development environments, and from here we can automatically check that this code can be built. By continuously merging and integrating changes from across the team and validating them in this way, we dramatically shorten the feedback loop for developers. Removing manual steps for testing and building out database changes also speeds up the rate at which fixes progress through the release pipeline.
Key to making this efficient is standardizing how the team works even further. Adhering to a common framework and toolset for configuring development environments, formatting code and testing changes helps to avoid merge conflicts and facilitates team-based collaboration. Better quality code going into the version control system will lead to a higher pass rate for builds, and subsequently a faster transition through later environments.
Shift testing left
‘Shift left testing’ is another useful concept here. The idea is to shift left production behaviors and processes, not just to staging environments, but as far as possible into development:

If an application is never fully tested against real data until it reaches Production, it will likely encounter data-related issues and suffer performance problems. By shifting left, code can be tested against an expected range of values, and a volume and distribution of data comparable to Production so that data-related problems are caught earlier.
However, the shift left concept also introduces security and administration challenges. Without the right approach, provisioning copies of production-like data to development teams can be difficult and resource-heavy, resulting in high storage costs, long wait times for up-to-date data, and an increased risk of exposing sensitive information.
Introduce data masking and virtualization
A solution is to combine data masking and data virtualization so that development environments can be refreshed with a trustworthy copy of the latest production dataset, void of any PII, quickly. These lightweight copies, or clones, also ensure efficient use of disk space, and mean that test data is delivered reliably in the same way, every time.
As soon as we have a build that’s been validated, we know that we can deploy it to other environments for further testing. By automating the updating of environments, we remove the risk of human error that comes with hand-written scripts. And by taking a combined data masking and data virtualization approach to provisioning test data, we build security into our release process.
In the latest Accelerate State of DevOps Report, DORA found that: Building security into software development improves software delivery and operational performance and security quality. Low performers take weeks to conduct security reviews and complete the changes identified. In contrast, elite performers build security in and can conduct security reviews and complete changes in just days.
Automate where possible
Automating the integration, testing and deployment of database changes upstream facilitates smaller and more frequent updates, and increased confidence in the success of our next deployment to production. Teams that release frequently deliver valuable features to their users more often, and in doing so gather continuous feedback on their products. A database monitoring tool is a vital piece of kit here too, and everyone on the team should have insight into the impact of their work on the production environment.
Application teams have long followed this process; it’s been refined, optimized and has evolved to be the norm. Aligning the database release process means that software delivery can be streamlined, putting application and database versions in sync and driving up quality and safety through more frequent and rigorous testing and shorter release cycles.
Align database development with application development
The goal of DevOps is to break down barriers and bottlenecks within software teams to increase throughput and stability. Solutions such as Redgate’s Compliant Database DevOps approach exist to bring the database testing and release process in line with the application and ensure that this transition is successful.
What’s more, far from being a risk when it comes to data privacy concerns, DevOps actually enables organizations to better protect customer data in the event of a breach and defend themselves against the growing tide of global legislation.
To learn more about extending DevOps to your database while complying with regulations and protecting your data, visit Redgate’s Compliant Database DevOps solution pages.
You may also like

Blog
Test Data Management and SOC 2 Compliance

Blog
Redgate Flyway’s Product Updates – March 2026

Blog