





When to use the SELECT…INTO statement (PE003)
We can use SELECT…INTO in SQL Server to create a new table from a table source. SQL Server uses the attributes of the expressions in the SELECT list to define the structure of the new table.
Prior to SQL Server 2005, use of SELECT…INTO in production code was a performance 'code smell' because it acquired schema locks on system tables of the database, causing SQL Server to appear unresponsive while the query was being executed. This is because it is a DDL statement in an implicit transaction, which is inevitably long-running since the data is inserted within the same SQL Statement. However, this behavior was fixed in SQL Server 2005, when the locking model changed.
SELECT…INTO became popular because it was a faster way of inserting data than using INSERT INTO…SELECT…. This was mainly due to the SELECT…INTO operation being, where possible, bulk-logged. Although INSERT INTO can now be bulk-logged, you may still see this performance advantage in SQL Server 2012 and 2014, because SELECT…INTO can be parallelized on these versions, whereas support for parallelization of INSERT INTO only emerged in SQL Server 2016. However, with SELECT…INTO, you still have the task of defining all required indexes and constraints, and so on, on the new table.
A recommendation to avoid use of SELECT…INTO, for production code, is included as a code analysis rule in SQL Prompt (PE003).
Creating tables using the SELECT INTO statement
The SELECT…INTO feature in SQL Server was designed to store or 'persist' a table source as part of a process. Here is a simple example:
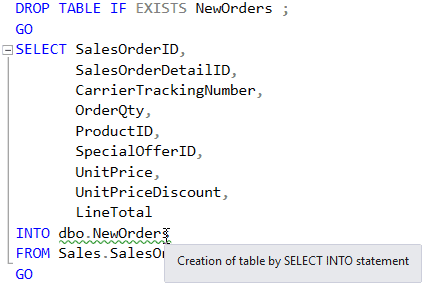
However, a table source can be many things other than a conventional table, such as a user-defined function, an OpenQuery, an OpenDataSource, an OPENXML clause, a derived table, a joined table, a pivoted table, a remote data source, a table variable or a variable function. It is with these more exotic table sources that the SELECT…INTO syntax becomes more useful.
Is SELECT INTO part of the ANSI standard?
The ANSI standards do support a SELECT…INTO construct; it is called a singleton select and it loads a single row with values, but it's very seldom used ( Thanks to Joe Celko for pointing this out).
People often use SELECT…INTO with the misunderstanding that it is a quick way of copying tables, and so it comes as a surprise that none of the indexes, constraints, calculated columns, or triggers defined in the source table are transferred to the new table. They can't be specified in the SELECT…INTO statement either. It also does nothing about nullability or preserving computed columns. All these tasks must be done retrospectively with the data in place, which inevitably takes time.
You can, though, use the function IDENTITY (datatype, seed, increment) to set up an identity field, and it is possible, when the source is a single table, to make a column of the destination table into an identity column. It is this fact that probably leads developers to assume that it will transfer other column attributes.
Furthermore, it also can't create partitioned tables, sparse columns, or any other attribute inherited from a source table. How could it when the data might be coming from a query involving many joins, or from some exotic external data source?
Since SQL 2012 SP1 CU10, SELECT…INTO can be executed in parallel, However, since SQL Server 2016, Parallel Insert has been allowed on the conventional INSERT INTO…SELECT statement, with certain restrictions, so any performance advantage of using SELECT…INTO is now rather diminished. The INSERT INTO process can also be speeded up if it can be bulk-logged, rather than fully-recovered, by setting the recovery model to simple or bulk logged, inserting into an empty table or a heap, and setting the TABLOCK hint for the table.
The following summarizes some of the restrictions and limitations when using SELECT…INTO.
- The
IDENTITYproperty of a column is transferred, but not if:- The
SELECTstatement contains joined tables (using eitherJOINorUNION),GROUPBYclause, or aggregate function. If you need to avoid anIDENTITYproperty from being carried over to the new table, but need the values of the column, it is worth adding aJOINto your table-source on a condition that is never true, or aUNIONthat provides no rows. - The
IDENTITYcolumn is listed more than one time in theSELECTlist - The
IDENTITYcolumn is part of an expression - The
IDENTITYcolumn is from a remote data source
- The
- You cannot
SELECT…INTOeither a table-valued parameter or a table variable as the destination, though you can selectFROMthem. - Even if your source is a partitioned table, the new table is created in the default filegroup. However, in SQL Server 2017, it is possible to specify the filegroup in which the destination table is created, via the
ONclause. - You can specify an
ORDERBYclause, but it is generally ignored. Because of this, the order ofIDENTITY_INSERTisn't guaranteed. - When a computed column is included in the
SELECTlist, the corresponding column in the new table is not a computed column. The values in the new column are the values that were computed at the timeSELECT…INTOwas executed. - As with a
CREATETABLEstatement, if aSELECT…INTOstatement is contained within an explicit transaction, the underlying row(s) in the affected system tables are exclusively locked until the transaction is explicitly committed. In the meantime, this will result in blocks on other processes that use these system tables.
There is some confusion about problems that can happen with the use of SELECT…INTO using temporary tables. SELECT…INTO has gained a somewhat unfair reputation for this, but it was part of a more general problem involving latch contention in tempdb under a heavy load of small temp table creation and deletion. When SELECT…INTO was adopted with enthusiasm, it could greatly increase this type of activity. The problem could be easily fixed in SQL Server 2000 onwards with the introduction of the use of trace flag TF1118, which is no longer required from SQL Server 2016 onwards. For a full explanation, see Misconceptions around TF 1118.
Summary
In summary, SELECT…INTO is a good way of making a table-source temporarily persistent as part of a process, if you don't care about constraints, indexes or special columns. It is not a good way of copying a table because only the barest essentials of the table schema can be copied. Over the years, there have been factors that have increased or decreased the attraction of SELECT…INTO, but overall it is a good idea to avoid using it whenever possible. Instead, create a table explicitly, with the full range of features that the table possesses that are designed to ensure that data is consistent.
Tools in this post
You may also like

Article
Driving up database coding standards using SQL Prompt
A strategic view of how a development team can use SQL Prompt to establish and share coding standards, through code analysis rules, formatting styles and code snippets.
Article
Avoid using constants in an ORDER BY clause
Phil Factor explains why an ORDER BY clause should always specify the sort columns using their names, or aliases, rather than using an integer to specify the position of a column in the SELECT list.
Article
SQL Prompt Code Analysis: Table does not have clustered index (BP021)
If SQL Prompt alerts you to a table without a clustered index, investigate the reason for its absence carefully. It is rare indeed to find a table where data retrieval is faster without one.

Article
SQL Prompt Product Updates – December 2025
SQL Prompt’s December release brings support for SSMS 22 and SQL Server 2025. SSMS 22 support SQL Prompt v11.2 now supports SSMS 22 on both ARM64 and x64 architectures (ARM64 support was re-introduced as one of the key new features in the SSMS 22 release.) If you’re installing SSMS 22 alongside an existing version of SQL Prompt, please note: you’ll need to reinstall or upgrade to v11.2 (or later) after installing SSMS 22 for SQL Prompt to appear in SSMS. SQL Server 2025 support We’re pleased to announce that SQL Prompt now supports the GA release of SQL Server 2025.
Article
Removing the Square Bracket Decorations with SQL Prompt
If you avoid illegal characters and reserved words in your identifiers, you'll rarely need delimiters. Sadly, SSMS applies square bracket delimiters indiscriminately, as a precaution, when generating build scripts. Phil Factor provides a handy function that adds quoted delimiters only where they are really needed and then sits back and lets SQL Prompt strip out any extraneous square brackets, in a flash.
Article
Quick SQL Prompt tip - picking the columns you need for speedy results
One of the poor practices that I see so many people doing in code is using SELECT *. This is poor practice because it takes more time to complete for clients, it’s an unnecessary use of resources on the client, server and network, and it can fill the buffer cache with rarely-used data. For example, if someone wants the title of a document and the product it goes with, I’ll see queries like this: There are a lot of fields in these tables, and most aren’t used. I can see this if I use the Expand Wildcards feature of SQL
Loading comments...