





The Sins of SELECT * (BP005)
This is an update of an article first published in June 2018.
The first thing I ought to say about SELECT * is that we all use it. I use it every day for development work but hopefully it seldom escapes into production unless there is a good reason for it. Outside of development, SELECT * has only a few valid uses within a batch. Using SELECT * FROM within IF EXISTS statements is fine, as are SELECT COUNT(*), SELECT * FROM…FOR XML or SELECT * FROM…FOR JSON.
Elsewhere, a query using an asterisk as a column specifier will work fine for a while but can introduce vulnerabilities and performance problems. If you assume the column order is 'set in stone', by transferring data using INSERT INTO…SELECT * FROM statements, then when that order changes your best hope is that it is causes errors, but at worst you'll see the dire consequences of assigning the wrong data to a column. Also, queries that select all the columns in a table, even when the application doesn't need them all, can cause unnecessary network load and query performance problems. It also makes queries very hard to index, leading to inefficient execution plans.
Finally, SELECT * will also make your code less readable, and harder to maintain. All of this explains why SQL Prompt implements a 'best practice' code analysis rule (BP005), which will prompt you to replace the asterisk(*) with an explicit list of columns, in SELECT statements.
Using SELECT * for development work
SELECT * is ideal for ad-hoc work, seeing exactly what is in a result at the point of starting to refine a query, or for debugging, but it is a development device that was intended for interactive use. Without SELECT *, development work in SQL Server would be more painful, because there is no quicker way of finding out about the data and metadata that is being returned from a table source, meaning anything that can go into a FROM clause. This will include base tables, views, TABLESAMPLE, derived tables, joined tables and table functions.
In short, SELECT * is still indispensable for eye-balling the data. Sure, sp_help will give you information about tables and other objects, and you have SSMSs browser and, hopefully, SQL Prompt, but nothing beats seeing that SSMS data grid when you're investigating the result of a query, table-valued function or procedure.
It is still a popular way of getting a list of column names from tables, views or TVFs. However, if all you need is a column list for a table or view (but not a TVF), you can just drag the Columns subfolder of the table from SSMS object explorer into the query pane. Alternatively, within the context of the target database, in this case Adventureworks2016, you could investigate tables using:
|
1
2
3
4
5
6
|
SELECT col.name
FROM sys.objects obj -- from all the objects (system and database)
INNER JOIN sys.columns col --to get all the columns
ON col.object_id = obj.object_id
WHERE obj.object_id = OBJECT_ID('[Person].[Address]')
ORDER BY col.column_id;
|
The advantage of SELECT * is that you can copy and paste the column names of any result, regardless of its source. However, nowadays it's better to use sys.dm_exec_describe_first_result_set for a statement or sp_describe_first_result_set for a batch. If, for example, we want to see what columns are there in the Person.Address table in AdventureWorks, we could use:
|
1
2
3
4
|
SELECT f.name
FROM sys.dm_exec_describe_first_result_set
(N'SELECT * FROM adventureworks2016.Person.Address;', NULL, 0) AS f;
-- (@tsql, @Params, @include_browse_information)
|
Why is SELECT * bad in production code?
Once you're beyond the investigation phase, SELECT * should be replaced by an explicit column list, otherwise it can cause problems:
- Indigestion: There is a cost for every column of data you request, within both the database and the application. When you want a glass of water, you don't turn on every tap in the house. When, in an application, you specify all the columns rather than just the columns you need, you will initially know, and maybe accept, the extent of the wastage. If someone subsequently extends the width of the table with more columns you get a whole lot more columns that aren't needed, and your application will slow down with the increased memory management task.
- Torpidity. A query that retrieves information will probably use an index, especially if your query uses a filter. SQL Server's query optimizer will want to get the data from the covering index, if possible, rather than having to rummage around in the clustered index. If you use
SELECT*, then the chances are high that no index won't be covering. Even if you were wacky enough to cover the entire table with a non-clustered index, this will be rendered entirely useless if the table gets increased still further in size. - Misinterpretation: If you reference the columns by order rather than name, using
INSERTINTO…SELECT*, then you must hope the column order never changes. If it does, and it is possible to coerce the values into the datatype you are anticipating, then data can end up in the wrong columns without triggering an error. - Binding Problems. When you
SELECT…INTOwith a query that has been sprinkled with the asterisk fairy-dust, you can easily hit the problem of a duplicate name for a column. If you specify the columns, you will know up-front of duplicates and can alias them. If, instead, you pass such a query to an application, it has no easy way of knowing which column is the one with the correct value. - Maintainability: Anyone reading your code, and seeing
SELECT *, will have to search the metadata to fine the names of the columns being referenced by the query. If you list them, and they are meaningful names, it will be clearer what is going on and the purpose of the query will be more obvious.
Indigestion
In applications, the worst habit I've seen is probably that of specifying data that isn't needed. There is a misapprehension amongst some developers that databases are slow, but every query takes around the same amount of time. By this false logic, it makes sense to grab all you can in the one query and SELECT * means just that: 'give me all you've got'. It is like a sales shopper who has had to queue and grabs more bargains off the shelf than they could possibly need or afford.
Ironically, a lot of the apparent slowness in queries turns out not to be "the database being slow" but the local memory management crumbling under the weight of unnecessary data being pulled across the network and having to be squirreled away in large objects. If you want to load data into an object from a database, it is usually better to use lazy loading, especially if the object is large. Passing data across a network is surprisingly expensive in terms of the time taken, and so it is much better to request just what you immediately need in a query. Several fast queries are faster than a single vast super-query.
Even within SQL Server, though, SELECT * will bite you. It cuts across the general principle that, for performance reasons, you reduce the result as soon as possible when you are filtering and projecting data. This means that you cut down both the columns and rows to what is needed first, before you do the fancy stuff such as aggregation. The use of SELECT * in derived tables within a query is now less harmful to performance than it was because the optimizer can now generally restrict the columns to what is necessary, but it is still wrong, especially in the outer query. Results should always consist of just the columns you need.
To demonstrate the impact, here I create in a timing harness two temporary tables, by using SELECT…INTO with a temporary table, and fill them with two million rows of data from a Directory table. In one I specify just the columns I need, and in the other one I shrug and just type * instead.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
--set up
DECLARE @log TABLE (TheOrder INT IDENTITY(1,1),
WhatHappened varchar(200),
WhenItDid Datetime2 DEFAULT GETDATE())
----start of timing
INSERT INTO @log(WhatHappened) SELECT 'Starting to time select into'--place at the start
--end of setup
SELECT * INTO #myTempDirectory FROM Directory;
INSERT INTO @log (WhatHappened)
SELECT 'SELECT INTO with wildcard took';
--copy and paste in anywhere
SELECT Name, Address1, Address2, Town, City, County, Postcode, Region
INTO #AnotherTempDirectory
FROM Directory;
INSERT INTO @log (WhatHappened)
SELECT 'SELECT INTO with fields specified took ';
--where the routine you want to time ends
SELECT ending.WhatHappened,
DateDiff(ms, starting.WhenItDid, ending.WhenItDid) AS ms
FROM @log AS starting
INNER JOIN @log AS ending
ON ending.TheOrder = starting.TheOrder + 1
UNION ALL
SELECT 'Total', DateDiff(ms, Min(WhenItDid), Max(WhenItDid)) FROM @log;
--list out all the timings
--tear down
DROP TABLE #myTempDirectory;
DROP TABLE #AnotherTempDirectory;
|
The version where we specified the columns took only 20% of the time of the other one, even though we only reduced the amount of data by 30%.
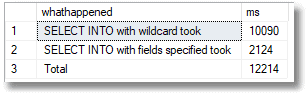
Putting it slightly differently, for this test, using a wildcard SELECT…INTO takes five times longer than a SELECT…INTO that returns only the required columns.
Torpidity
It is almost impossible to provide a covering index for SELECT * queries, and even if you were to try, it would be far harder than if your queries simply spelled out the required columns, explicitly.
If you are just retrieving information, SQL Server will generally use an index. For your frequent, important and expensive queries, you probably want it to have an index available from which it can retrieve all the columns requested by the query. If it doesn't have one, it may get the available columns from the index and then lookup the other column values in the clustered index, or it may simply resort to scanning the clustered index. If the tables are big and the queries return many rows, you'll start to notice a performance hit.
Say we wanted to search the Directory table to find all the pubs called the 'something' arms, in a given city. We could, do this
|
1
|
SELECT Name, Address1, Address2, Town, City, County, Postcode, Region FROM Directory WHERE name LIKE '% arms%' and city ='Cambridge'
|
Or we could do this…
|
1
|
SELECT * FROM Directory WHERE name LIKE '% arms%' and city ='Cambridge'
|
The first query might have a covering index like this:
|
1
2
3
4
|
CREATE NONCLUSTERED INDEX IX_Directory_City
ON [dbo].[Directory] ([City])
INCLUDE ([Address1], [Address2], [Town], [County], [Postcode], [Region])
GO
|
However, no sensible indexing strategy can help much if the queries are SELECT *. The second version would only be covered by an index that included every column!
Using the same test harness as before, you'll see that even though most of the work was searching for the word 'arms' within the name of all the businesses in Cambridge, it was faster to specify the columns. In the first case, the index is a covering index for this query, whereas with the SELECT * version, it is not. The execution plan still uses it, since the query returns only 19 rows in this case, but SQL Server must perform additional key lookups for each row, to return the column values that aren't included in this index.
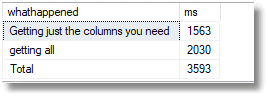
With more general queries on this database, the queries specifying the columns ran, on average, in two thirds of the time of those that used the same index but required additional key lookups.
Misinterpretation
With SELECT *, you aren't ensuring that your code always returns the the same columns in the same order, which means it isn't resilient to database refactoring. Upstream modifications to the table source can change the order or number of columns. If you're transferring that data using an INSERT INTO…SELECT * then the best result would be an error, for the consequences of data being assigned the wrong destination column can be dreadful
I'll demonstrate just how dangerous this can be, if you use it in production code and then need to do some database refactoring. Here, we will make a mistake in copying sensitive information. It is frighteningly easy to do and could cause financial irregularities without any errors being triggered. If you are of a nervous disposition, please look away now.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
/* we create a table just for our testing */
CREATE TABLE dbo.ExchangeRates --lets pretend we have this data
(
CurrencyRateDate DATETIME NOT NULL,
AverageRate MONEY NOT NULL,
EndOfDayRate MONEY NOT NULL,
FromCurrency NVARCHAR(50) NOT NULL,
FromRegion NVARCHAR(50) NOT NULL,
ToCurrency NVARCHAR(50) NOT NULL,
ToRegion NVARCHAR(50) NOT NULL
);
/* we now steal data for it from AdventureWorks next-door */
INSERT INTO dbo.ExchangeRates
SELECT CurrencyRate.CurrencyRateDate, CurrencyRate.AverageRate,
CurrencyRate.EndOfDayRate, Currency.Name AS FromCurrency,
CountryRegion.Name AS FromRegion, CurrencyTo.Name AS ToCurrency,
CountryRegionTo.Name AS ToRegion
FROM Adventureworks2016.Sales.CurrencyRate
INNER JOIN Adventureworks2016.Sales.Currency
ON CurrencyRate.FromCurrencyCode = Currency.CurrencyCode
INNER JOIN Adventureworks2016.Sales.CountryRegionCurrency
ON Currency.CurrencyCode = CountryRegionCurrency.CurrencyCode
INNER JOIN Adventureworks2016.Person.CountryRegion
ON CountryRegionCurrency.CountryRegionCode = CountryRegion.CountryRegionCode
INNER JOIN Adventureworks2016.Sales.Currency AS CurrencyTo
ON CurrencyRate.ToCurrencyCode = CurrencyTo.CurrencyCode
INNER JOIN Adventureworks2016.Sales.CountryRegionCurrency AS CountryRegionCurrencyTo
ON CurrencyTo.CurrencyCode = CountryRegionCurrencyTo.CurrencyCode
INNER JOIN Adventureworks2016.Person.CountryRegion AS CountryRegionTo
ON CountryRegionCurrencyTo.CountryRegionCode = CountryRegionTo.CountryRegionCode;
GO
/* so we start our test by creating a view to show exchange rates from equador */
CREATE VIEW dbo.EquadorExhangeRates
AS
SELECT ExchangeRates.CurrencyRateDate, ExchangeRates.AverageRate,
ExchangeRates.EndOfDayRate, ExchangeRates.FromCurrency,
ExchangeRates.FromRegion, ExchangeRates.ToCurrency, ExchangeRates.ToRegion
FROM dbo.ExchangeRates
WHERE ExchangeRates.FromRegion = 'Ecuador';
go
/* now we just fill a table variable with the first ten rows from the view and display them */
DECLARE @MyUsefulExchangeRates TABLE
(
CurrencyRateDate DATETIME NOT NULL,
AverageRate MONEY NOT NULL,
EndOfDayRate MONEY NOT NULL,
FromCurrency NVARCHAR(50) NOT NULL,
FromRegion NVARCHAR(50) NOT NULL,
ToCurrency NVARCHAR(50) NOT NULL,
ToRegion NVARCHAR(50) NOT NULL
);
INSERT INTO @MyUsefulExchangeRates (
CurrencyRateDate, AverageRate, EndOfDayRate,
FromCurrency, FromRegion,ToCurrency, ToRegion)
SELECT * --this isn't good at all
FROM dbo.EquadorExhangeRates;
--disply the first ten rows from the table to see what we have
SELECT TOP 10 UER.CurrencyRateDate, UER.AverageRate, UER.EndOfDayRate,
UER.ToCurrency, UER.ToRegion, UER.FromCurrency, UER.FromRegion
FROM @MyUsefulExchangeRates AS UER
ORDER BY UER.CurrencyRateDate DESC;
GO
/* end of first part. Now someone decides to alter the view */
alter VIEW dbo.EquadorExhangeRates
AS
SELECT ExchangeRates.CurrencyRateDate, ExchangeRates.AverageRate,
ExchangeRates.EndOfDayRate, ExchangeRates.ToCurrency, ExchangeRates.ToRegion, ExchangeRates.FromCurrency,
ExchangeRates.FromRegion
FROM dbo.ExchangeRates
WHERE ExchangeRates.FromRegion = 'Ecuador';
GO
/* we repeat the routine to extract the first ten rows exactly as before */
DECLARE @MyUsefulExchangeRates TABLE
(
CurrencyRateDate DATETIME NOT NULL,
AverageRate MONEY NOT NULL,
EndOfDayRate MONEY NOT NULL,
FromCurrency NVARCHAR(50) NOT NULL,
FromRegion NVARCHAR(50) NOT NULL,
ToCurrency NVARCHAR(50) NOT NULL,
ToRegion NVARCHAR(50) NOT NULL
);
INSERT INTO @MyUsefulExchangeRates(
CurrencyRateDate, AverageRate, EndOfDayRate,
FromCurrency, FromRegion,ToCurrency, ToRegion)
SELECT * --bad, bad, bad
FROM dbo.EquadorExhangeRates;
--check that the data is the same. It isn't is it? No sir!
SELECT TOP 10 UER.CurrencyRateDate, UER.AverageRate, UER.EndOfDayRate,
UER.ToCurrency, UER.ToRegion, UER.FromCurrency, UER.FromRegion
FROM @MyUsefulExchangeRates AS UER
ORDER BY UER.CurrencyRateDate DESC;
GO
/* now just tidy up and tear down */
DROP VIEW dbo.EquadorExhangeRates
DROP TABLE dbo.ExchangeRates
|
Here are the 'before' and 'after' results….
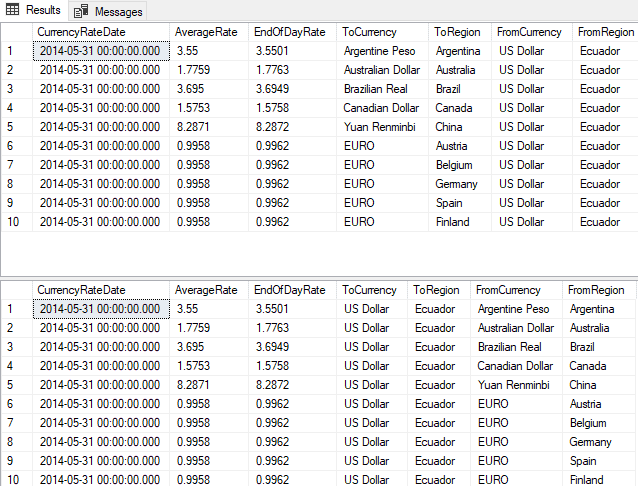
As you can see, we have 'unintentionally' corrupted the data by switching the 'to' and 'from' columns. Quoting the column list is extra bulk in your code. However, it performs as quickly, or even quicker than if you just airily specified all the columns with an asterisk, assuming that they remain in a particular order.
Binding Problems
When we use SELECT * with lots of joined tables we can, and probably will, have column names that are duplicated. Here is a simple query from AdventureWorks:
|
1
2
3
4
5
6
7
8
9
|
SELECT *
FROM HumanResources.Employee AS e
INNER JOIN Person.Person AS p
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh
ON e.BusinessEntityID = edh.BusinessEntityID
INNER JOIN HumanResources.Department AS d
ON edh.DepartmentID = d.DepartmentID
WHERE (edh.EndDate IS NULL);
|
And this code will reveal the column names that are duplicated:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
DECLARE @SourceCode NVARCHAR(4000)='
SELECT *
FROM HumanResources.Employee AS e
INNER JOIN Person.Person AS p
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh
ON e.BusinessEntityID = edh.BusinessEntityID
INNER JOIN HumanResources.Department AS d
ON edh.DepartmentID = d.DepartmentID
WHERE (edh.EndDate IS NULL);
--'
SELECT Count(*) AS Duplicates, name
FROM sys.dm_exec_describe_first_result_set(@SourceCode, NULL, 1)
GROUP BY name
HAVING Count(*) > 1
ORDER BY Count(*) DESC;
|
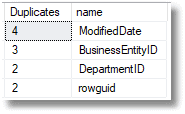
This will cause problems to an application trying to make sense of such a result when selecting a named column. If you try to create a temporary table from the result, using SELECT…INTO, it goes bang.
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT * INTO MyTempTable
FROM HumanResources.Employee AS e
INNER JOIN Person.Person AS p
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh
ON e.BusinessEntityID = edh.BusinessEntityID
INNER JOIN HumanResources.Department AS d
ON edh.DepartmentID = d.DepartmentID
WHERE (edh.EndDate IS NULL);
Msg 2705, Level 16, State 3, Line 19
Column names in each table must be unique. Column name 'BusinessEntityID' in table 'MyTempTable' is specified more than once.
|
Again, this means that your SELECT * code is fragile. If someone changes a name in one table, it could create a duplicate column in a SELECT * INTO, somewhere else, and you are left scratching your head and wondering why a working routine suddenly crashes
There is one place where SELECT * has a special meaning and can't be replaced. This is when converting a result into JSON and you want a result that has the joined tables embedded as objects.
|
1
2
3
4
5
6
7
8
9
|
SELECT *
FROM HumanResources.Employee AS employee
INNER JOIN Person.Person AS person
ON person.BusinessEntityID = employee.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory AS history
ON employee.BusinessEntityID = history.BusinessEntityID
INNER JOIN HumanResources.Department AS d
ON history.DepartmentID = d.DepartmentID
WHERE ( history.EndDate IS NULL) FOR JSON AUTO
|
This will give you… (I'm showing only the first document in the array)
|
1
2
3
4
5
6
7
8
9
10
11
|
[{"BusinessEntityID": 1,"NationalIDNumber": "295847284","LoginID": "adventure-works\\ken0","JobTitle": "Chief Executive Officer","BirthDate": "1969-01-29","MaritalStatus": "S","Gender": "M","HireDate": "2009-01-14","SalariedFlag": true, "VacationHours": 99, "SickLeaveHours": 69, "CurrentFlag": true, "rowguid": "F01251E5-96A3-448D-981E-0F99D789110D","ModifiedDate": "2014-06-30T00:00:00",
"person": [{
"BusinessEntityID": 1, "PersonType": "EM","NameStyle": false, "FirstName": "Ken","MiddleName": "J","LastName": "Sánchez","EmailPromotion": 0, "Demographics": "0<\/TotalPurchaseYTD><\/IndividualSurvey>","rowguid": "92C4279F-1207-48A3-8448-4636514EB7E2","ModifiedDate": "2009-01-07T00:00:00",
"history": [{
"BusinessEntityID": 1, "DepartmentID": 16, "ShiftID": 1, "StartDate": "2009-01-14","ModifiedDate": "2009-01-13T00:00:00",
"d": [{
"DepartmentID": 16, "Name": "Executive","GroupName": "Executive General and Administration","ModifiedDate": "2008-04-30T00:00:00"
}]
}]
}]
}}
|
There is no clash here because the ModifiedDate column, for example, is encapsulated inside an object representing the source table
The equivalent FOR XML gives this:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<employee BusinessEntityID="1" NationalIDNumber="295847284" LoginID="adventure-works\ken0"
JobTitle="Chief Executive Officer" BirthDate="1969-01-29" MaritalStatus="S" Gender="M" HireDate="2009-01-14" SalariedFlag="1" VacationHours="99"
SickLeaveHours="69" CurrentFlag="1" rowguid="F01251E5-96A3-448D-981E-0F99D789110D" ModifiedDate="2014-06-30T00:00:00">
<person BusinessEntityID="1" PersonType="EM" NameStyle="0" FirstName="Ken" MiddleName="J" LastName="Sánchez" EmailPromotion="0"
rowguid="92C4279F-1207-48A3-8448-4636514EB7E2" ModifiedDate="2009-01-07T00:00:00">
<Demographics>
<IndividualSurvey
xmlns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey">
<TotalPurchaseYTD>0</TotalPurchaseYTD>
</IndividualSurvey>
</Demographics>
<history BusinessEntityID="1" DepartmentID="16" ShiftID="1" StartDate="2009-01-14" ModifiedDate="2009-01-13T00:00:00">
<d DepartmentID="16" Name="Executive" GroupName="Executive General and Administration" ModifiedDate="2008-04-30T00:00:00"/>
</history>
</person>
</employee>
|
Maintainability
When laying out code, the columns you specify not only avoid mistakes in assigning values to the correct columns or variables, but they also make the code more readable. Wherever you can, it is worth spelling out the name of the columns involved just for the sake of you-in-the-future, or the poor soul who is one day tasked with maintaining your code. Sure, the code looks a bit bulkier but if a fairy appeared at your shoulder and said that your code would be more intelligible and reliable if you typed it out twice, you'd do that wouldn't you?
SELECT * in the application
Sometimes you'll see long-running queries that request all columns and that originate from an application, often one that uses LINQ. Usually, it isn't deliberate, but the developer has made a mistake, leaving out the specification of the columns, and an innocent-looking LINQ query translates into a SELECT *, or a column list that includes every column. If the WHERE clause is too general, or is even left out altogether, then this compounds the consequences, because the network is always the slowest component, and all that unnecessary data is being heaved across the network.
For example, using Adventureworks and LinqPad, you can do this in LINQ:
|
1
|
Persons.OrderBy (p => p.BusinessEntityID).Take (100)
|
… which LINQ translates to this query that is what is actually executed. You’ll see that it selects all the columns…
|
1
2
3
|
SELECT TOP (100) [t0].[BusinessEntityID], [t0].[PersonType], [t0].[NameStyle], [t0].[Title], [t0].[FirstName], [t0].[MiddleName], [t0].[LastName], [t0].[Suffix], [t0].[EmailPromotion], [t0].[AdditionalContactInfo], [t0].[Demographics], [t0].[rowguid] AS [Rowguid], [t0].[ModifiedDate]
FROM [Person].[Person] AS [t0]
ORDER BY [t0].[BusinessEntityID]
|
Likewise, this expression…
|
1
|
from row in Persons select row
|
…will deliver every column from every row in the entire table.
|
1
2
|
SELECT [t0].[BusinessEntityID], [t0].[PersonType], [t0].[NameStyle], [t0].[Title], [t0].[FirstName], [t0].[MiddleName], [t0].[LastName], [t0].[Suffix], [t0].[EmailPromotion], [t0].[AdditionalContactInfo], [t0].[Demographics], [t0].[rowguid] AS [Rowguid], [t0].[ModifiedDate]
FROM [Person].[Person] AS [t0]
|
By contrast, this…
|
1
|
from row in Persons.Where(i => i.LastName == "Bradley") select row.FirstName+" "+row.LastName
|
…translates to the more sensible:
|
1
2
3
4
5
6
7
|
-- Region Parameters
DECLARE @p0 NVarChar(1000) = 'Bradley'
DECLARE @p1 NVarChar(1000) = ' '
-- EndRegion
SELECT ([t0].[FirstName] + @p1) + [t0].[LastName] AS [value]
FROM [Person].[Person] AS [t0]
WHERE [t0].[LastName] = @p0
|
Conclusions
A general code smell is to ask for more data than you need. It is almost always better, and quicker, to allow the source of the data to do the filtering for you. The use of SELECT *, which is perfectly legitimate in some circumstances, is often a sign of this more general problem. It is tempting for a developer who is competent in C# or VB, but not SQL, to download a whole row, or even an entire table, and do the filtering in more familiar territory. The extra network load and latency should, by itself, be enough to deter such a practice, but this is often mistaken for a 'slow database'. A long column list, often listing all columns, is almost as pernicious as a SELECT *, though SELECT * has the extra risk when there is any refactoring.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
The '= NULL' Mistake and other SQL NULL Heresies
The SQL Prompt Best Practice rule checks whether a comparison or expression includes a NULL literal ('NULL'), which in SQL Server, rather than result in an error, will simply always produce a NULL result. Phil Factor explains how to avoid this, and other SQL NULL-related calamities.
Article
Driving up database coding standards using SQL Prompt
A strategic view of how a development team can use SQL Prompt to establish and share coding standards, through code analysis rules, formatting styles and code snippets.
Article
SQL Prompt to the rescue with tab coloring
When you’re hard at work, it’s all too easy to make a mistake as you rush to get a job done. Say, for example, you have a QA database you need to get rid of. You run a query to drop it and then… oh no! You’ve accidentally run it in Production. Your day just got even busier. You have to stop whatever you’re doing, restore to a point in time on your Production server and start over. If only there were an easier way to tell which environment you were working in. Good news: there is! Tab coloring with
Article
SQL Prompt code analysis: avoid non-standard column aliases (ST002 and DEP021)
If you declare a column alias using equals SQL Prompt will raise a violation of a style rule (ST002). It's best to follow the ANSI-SQL92 standard of assigning aliases using the AS keyword. If the alias is not a standard identifier, delimit it with double quotes. using single quotes has long been deprecated (DEP021).
Article
SQL Prompt Hidden Gem: Auto-fill the GROUP BY clause
Writing
GROUPBYclauses is a very common, but tedious, activity for a SQL programmer. SQL Prompt will fill it in for you, with all non-aggregated columns returned by the query.Article
SQL Prompt as a Layout Tool: A Survival Guide
Phil Factor's guide to taming SQL Prompt code layout options, and getting it to format code exactly the way you like it.
Loading comments...