





Avoid use of the MONEY and SMALLMONEY datatypes (BP022)
The MONEY data type confuses the storage of data values with their display, though its name clearly suggests the sort of data it holds. It is proprietary to SQL Server and allows you to specify monetary values preceded by a currency symbol, but SQL Server doesn't store any currency information at all with the actual numeric values, so the purpose of this is unclear.
It has limited precision; the underlying type is a BIGINT or, in the case of SMALLMONEY, an INT, so you can unintentionally get a loss of precision due to rounding errors. While simple addition or subtraction is fine, more complicated calculations that can be done for financial reports can show errors. Although the MONEY datatype generally takes less storage, and takes less bandwidth when sent over networks, via TDS, it is generally far better to use a data type such as the DECIMAL or NUMERIC type, which is less likely to suffer from rounding errors or scale overflow.
A recommendation to avoid use of the MONEY or SMALLMONEY datatypes is included as a "Best Practice" code analysis rule in SQL Prompt (BP022).
Rounding errors when using MONEY datatype
The MONEY and SMALLMONEY data types are accurate to roughly a ten-thousandth of the monetary units that they represent. SMALLMONEY is accurate between - 214,748.3648 and 214,748.3647 whereas MONEY is accurate between -922,337,203,685,477.5808 (-922,337 trillion) and 922,337,203,685,477.5807 (922,337 trillion).
Although MONEY can be represented with a currency symbol, this information isn't stored. Under the covers, MONEY is stored as an integer data type. A decimal number, the more usual choice for storing a monetary value, can range accurately between -10^38 +1 through 10^38 - 1. Several sqillion!
The scientific world can tolerate tiny rounding errors and margins of error, but in finance a monetary calculation is either right or wrong. It is futile to argue that the odd cent or pence isn't worth worrying about; I have, myself, been laughed at when I was a smidgen out from the right answer.
Take the calculation in Listing 1, which is the simplest I can think of that illustrates the problem.
|
1
2
3
4
5
6
7
8
|
DECLARE @MoneyTable TABLE (Total MONEY, Portion MONEY);
INSERT INTO @MoneyTable (Total, Portion)
VALUES
($271.00, $199.50), ($4639.00, $4316.00), ($8031.00, $7862.00), ($7558.00, $7081.00),
($9912.00, $9547.00), ($389.00, $179.00), ($4495.00, $4214.00), ($2844.00, $2398.00),
($265.67, $124.33), ($4936.56, $967.54);
SELECT Portion, Total, (Portion / total)*100 AS Percentage FROM @MoneyTable
|
Listing 1
Here are the results:
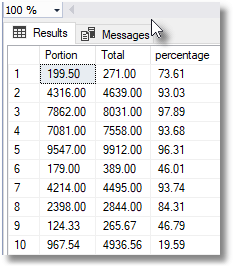
Notice the lack of any currency symbols for the Portion and Total values. The currency isn't stored. It was useful in the VALUES clause because it indicated to SQL Server that it should parse the scalar literal values such as $124.33 into the MONEY datatype. Aside from that, though, are the percentage values correct? Let's check that in Excel:

Hmm: doesn't look quite right. Let's rerun the calculation with decimal arithmetic (you'll need to round the total or cast to numeric with a scale of two).
|
1
2
3
4
5
6
7
8
9
10
|
DECLARE @MoneyTable TABLE (Total DECIMAL(19, 4), Portion DECIMAL(19, 4));
INSERT INTO @MoneyTable (Total, Portion)
VALUES
(271.00, 199.50), (4639.00, 4316.00), (8031.00, 7862.00), (7558.00, 7081.00),
(9912.00, 9547.00), (389.00, 179.00), (4495.00, 4214.00), (2844.00, 2398.00),
(265.67, 124.33), (4936.56, 967.54);
SELECT Portion,Total,
cast((Portion / Total) * 100 as numeric(19,2)) AS percentage
FROM @MoneyTable
|
Listing 2
This time, the answers are the same as we saw in Excel:
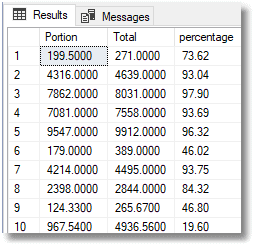
Incidentally, if you rerun Listing 2 but with the currency symbol in front of each of the values we're inserting for Total and Portion, then you'll still get the correct percentage values (under the covers, SQL Server implicitly converts the monetary values to DECIMAL (19,4) before inserting them into the table variable).
The following figure shows the results of doing the reverse calculations i.e. calculating the portion values, from the total and percentage. The fact that we cannot calculate the portion (or total) exactly, from the percentage values produced using the MONEY datatype (Listing 1), confirms that there are rounding errors in those percentage values.
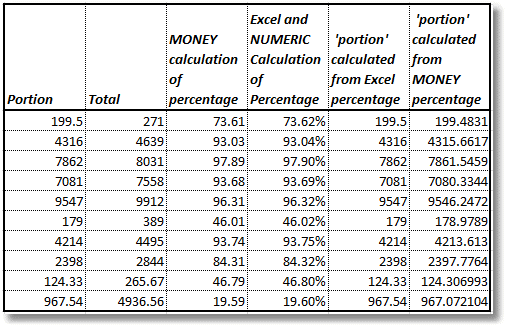
Other errors when using MONEY
You can also get scale overflow errors if you try to calculate correlations the classical way, when using MONEY values. The values stored in the intermediate sum of the squares calculations can get enormous, if you are trying to find relationships between monetary values and other variables over many rows. This will cause errors in the value of the correlation. If you cannot avoid the MONEY datatype then it is far better to use the built-in StDevP() aggregate function to get the correlation.
Summary
Basically, it pays to do calculations in DECIMAL (a.k.a. NUMERIC) with as many digits to the right of the decimal point as practical, and only using two or three decimal places to display the result. A scale of four digits to the right of the decimal point isn't always sufficient for a datatype that is involved in any operations beyond addition or subtraction. Be aware also of 'Bankers rounding' in calculations.
MONEY can be made to perform well and accurately if you know all the constraints and workarounds, such as using the NUMERIC datatype within calculations using division or multiplication, or employing the built-in aggregate functions. MONEY uses integers under the covers, so it is fast, and will generally use less storage, and is particularly suited to being transmitted across a network as TDS. However, it is for experts only.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Driving up database coding standards using SQL Prompt
A strategic view of how a development team can use SQL Prompt to establish and share coding standards, through code analysis rules, formatting styles and code snippets.
Article
Avoid using constants in an ORDER BY clause
Phil Factor explains why an ORDER BY clause should always specify the sort columns using their names, or aliases, rather than using an integer to specify the position of a column in the SELECT list.

Article
SQL Prompt Product Updates – April 2026
SQL Prompt’s March releases focused on Prompt AI improvements and SSMS 22.4 compatibility. Prompt AI is now SQL Server version-aware SQL Prompt v11.3.7 makes Prompt AI requests include the SQL Server version of the connected database alongside its schema. This meaningfully increases the chance of AI-generated T-SQL being compatible with the version you’re actually working against, rather than quietly leaning on newer language features that won’t run. The Prompt AI window also displays the detected version as a grey suffix after the database name, so you can see at a glance what context the model is working with. Prompt AI
Article
Cleaning up common T-SQL coding issues with SQL Prompt
Some SQL coding habits are just annoying. Commas in front of column names? No way! Others are actively harmful; they’ll make your code error prone, harder for others to read and understand, and even harder to edit without making mistakes. This article covers five harmful problems that I see regularly in T-SQL code, and shows how you can use SQL Prompt to avoid or remove them. Object owners When you construct your T-SQL statements, it’s good practice to supply the owner of a given object. Every table reference should supply the schema to which the table belongs. Every column reference
Article
Exploring Auto-fix in SQL Code Analysis
Phil Factor presents a useful but slightly flawed 'table report' script as an adventure playground for exploring SQL Code analysis issues. He demonstrates use of the auto-fix feature, to arrive at a pristine script free from wavy green underlines.
Article
Removing the Square Bracket Decorations with SQL Prompt
If you avoid illegal characters and reserved words in your identifiers, you'll rarely need delimiters. Sadly, SSMS applies square bracket delimiters indiscriminately, as a precaution, when generating build scripts. Phil Factor provides a handy function that adds quoted delimiters only where they are really needed and then sits back and lets SQL Prompt strip out any extraneous square brackets, in a flash.
Loading comments...