Avoid running out of Disk Space ever again using Redgate Monitor
Redgate Monitor not only collects all the disk and database growth tracking data you need, automatically, but also analyses trends in this data to predict accurately when either a disk volume will run out of free space, or a database file will need to grow.
If your SQL Server runs out of disk space, and it is running a database for an enterprise’s trading application, then the company can’t take money until the DBA fixes the problem. Even the worry of that ever happening is enough to keep a DBA up at night. No wonder, then, that the recent State of SQL Server Monitoring survey confirmed that in 2018 disk space management is still the DBA’s seconds biggest administrative challenge.
Of course, it is rare for a database to suddenly run out of space. It is usually a predictable event, if you are aware of the rate of growth of the database, and of the changes in the free space on the storage. Therefore, it’s a good idea to monitor these metrics, and to set up alerts to warn you when:
- Free disk space dips below a threshold value
- Unallocated space in a database file dips below a threshold value
- Database files grow, physically, in size
By monitoring each of these metrics you will, firstly, cut out all the unplanned downtime caused by ‘unexpectedly’ running out of disk space; an event that can adversely affect a DBA’s career. Secondly, you’ll increase the time available to react. If you can predict when a database is going to need to grow, you can schedule in maintenance time, to increase capacity, at a point when it will have the least impact on your business. It will also help you avoid file auto-growth occurring at unpredictable times, when it could block and disrupt important business processes. Finally, you’ll also be able to investigate and fix any problem that may be causing excessive database growth. All this will result in much less disruption to business processes, and a drastic reduction in time spent on ad-hoc disk space management.
Monitoring free space on disk
If a database’s data file fills its allocated disk space, and can’t grow, you’ll see the infamous 1105 error, and the database will be read-only until more space is made available. If the transaction log file fills up, and can’t grow, you’ll see the equally-infamous 9002 error. This again puts SQL Server into read-only mode, or into “resource pending” mode, if it happens during database recovery.
These can be catastrophic events for the organization, and so the DBA needs to avoid them altogether. Therefore, they must monitor the available free space on the disk volumes holding the data and log files of their database and ensure there is sufficient available for the files to grow, if required.
They also need to monitor the free space available on the disk volumes that house the database backups and log backups, to avoid the possibility of backup failures that would compromise their ability to recover a database, when required.
Ad-hoc disk space tracking
There are various ways to use TSQL to get the data about the amount of free space left. You can still use the age-old xp_fixeddrives stored procedure, which will just tell you how much free space is on each drive. However, the sys.dm_os_volume_stats dynamic management function provides a lot more information about the space available in the various disk volumes housing each file, in each database in the instance. Alternatively, there are numerous published scripts showing how to track disk space using PowerShell.
A DBA can write a few scripts to track disk space use and set alerts to fire when a disk approaches full capacity. Each time the script runs, they could even save the collected data to a table in a central repository, for trend analysis, using Excel. However, this sort of ‘manual’ data collection and analysis, while it might be straightforward for small operations, becomes increasingly difficult to maintain, as the number of SQL Servers increases. This is where a tool such as Redgate Monitor is invaluable.
Proactive disk space monitoring
Redgate Monitor, of course, supplies a built-in Disk space metric and alert that will warn the team when used disk space rises a above a threshold percentage value, or when available disk space falls below a threshold amount (in MB or GB). I’ll refer to Steve Jones’s article, How to never lose track of disk space for examples of how to use this metric.
This should give the DBA some ‘breathing space’ to install more disk capacity, or to make more space available within the current disk volumes. However, this can still feel like a reactive and time-consuming approach, when applied to the demands of monitoring bigger databases and many SQL servers.
In Redgate Monitor 9, and later, you can use the Disk Usage page, within the Estates menu, to monitor disk space usage, and plan capacity requirements, across all servers. The summary graph shows the current total disk capacity, alongside recent growth in disk space use, across the monitored estate. It also projects the growth trend over the coming months. You can filter the data in this graph, and on the rest of this page, by server group (such as “production” or “test”), or by disk volume. You can also filter the data simply by typing in the server name.

Figure 1
To the right of the graph you’ll see an Estate Summary (not shown), which gives you the figures, and a warning of any disks volumes that will exceed their capacity, within the growth forecast. Below the graph, you’ll find a list that breaks down disk space use on each monitored SQL Server instance. Figure 2 shows that we have a clustered SQL Server instance that is rapidly using up its available disk space.

Figure 2
The administrative team’s urgent concern here will be the possible need to allocate more disk space, to avoid unplanned downtime. However, they will also need to investigate which files, database-related or otherwise, are consuming the disk space.
What are the biggest databases? Are they growing abnormally rapidly? If so, why? By clicking on any of the disks, the team can see a detailed breakdown of space allocation on that disk. Figure 3 shows the breakdown for the F: drive, which Figure 2 tells us could be full within 2 months.

Figure 3
In this case, there has been a couple of large jumps in the allocation of space to database files, and the result is that over 1 TB of the space on a 1.9 TB disk is now allocated. However, the used space is only 400 GB. Below the graph, we get details of the current size of each database and log file on the volume, the space used within each.

Figure 4
We can see that the majority of the 400 GB of used space is being consumed by two databases (BIDataCache and ODS_LOB). The primary data file for ODS_LOB is close to full and will need to grow again soon. The big difference between the used and allocated space is explained largely by the BIDataCache file size and usage. It looks like both the data and log file grew substantially in size, and the log file was subsequently truncated, which explains why 250GB is allocated but only 1.1GB is being used. This data is a useful starting point for deeper investigation into the growth and activity on these databases, and I’ll explain how to monitor database growth later in the article.
Sometimes, the space isn’t being consumed by database files at all. Perhaps a ‘rogue’ developer with server access is storing ad-hoc backups on the same disk volume, or an ETL process is failing to do its housekeeping.
Either way, the earlier the team are aware of impending disk space issues, the more time they have available to investigate the cause and plan a response.
Monitoring free space in database files
When we create a database, we establish the initial physical size of the data and log files, and the automatic filegrowth increments. Initially, of course, most of the space in the files will be free space, but over time it will be used (allocated) to store data, and in the transaction log, records describing changes to the data.
As we add new data, the space within the data file will be allocated to the tables and indexes storing that data. When the data file is full, it will need to grow. If we monitor the rate at which space within the data file is being used, and how much free space remains, we can predict when the file will need to grow, and can plan accordingly, rather than rely on unpredictable, and expensive, file autogrowth events (more on this later).
We can also monitor free space in the transaction log file, though this is more complicated because the log behaves more like a ring-buffer. Once it’s full, it will circle round and start overwriting the log records for previously committed transactions, unless there is a reason why it can’t do so, in which case the log will need to grow.
By tracking space use in our database files, over time, we’ll understand better the growth characteristics for each database, and be able to size the files more accurately, to accommodate future data growth.
Ad-hoc tracking of space use in database files
For ad-hoc checks on how disk space is being used by a database, we can use the built-in SSMS reports. Simply right-click on any database and select Reports | Standard Reports. The Disk Usage report provides details of total space reserved for the database, and data and log file individually, then pie charts showing current space usage within the files. It also shows any recent file auto-grow events. The Disk Usage by Top Tables report will show you what tables have the most allocated space, and so are using up most disk space.
For scripted checks, you can query the sys.database_files view to get both the total database size (covered later), as well as granular detail on the size of the individual data and log files for each database, and the space used within each. You can also fine the amount of space within the data file that is currently allocated to database objects, using the sys.dm_db_file_space_usage DMV (which is also used in the space used by database objects custom metric in Redgate Monitor).
If a database is growing unexpectedly quickly, you will want to know to which objects (tables and indexes) within the database, the space is being allocated. You can use the sys.allocation_units view to see a breakdown of space allocation for all objects within a database. Alternatively, you can use the sp_spaceused system stored procedure, supplying the name of the table that you wish to investigate.
Monitoring space use in the data file with Redgate Monitor
On Redgate Monitor’s Overview page for any monitored SQL Server instance, within the Databases section, we can see the current physical size of the data and log files for each database on the instance, and the projected time until a file is full, and will need to auto-grow, or the disk itself is full.

Figure 5
To avoid being taken surprise by database files that are ‘suddenly full’, we can track data file use, in Redgate Monitor, via the built-in database file usage metric.
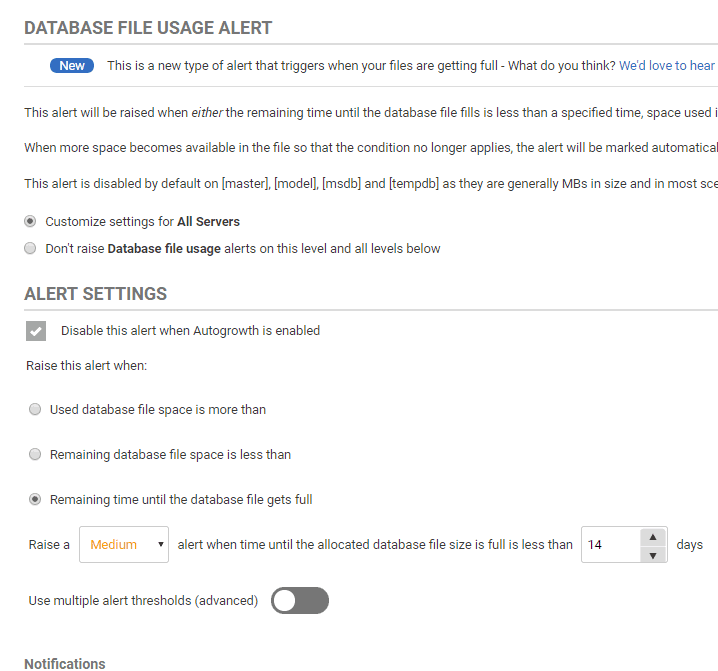
Figure 6
The idea behind this metric is to warn you well in advance when a database file will need to grow. Rather than simply wait till it auto-grows, which can be very disruptive, depending on when the auto-growth even occurs, you have time to study the trend is growth, the cause of any abnormal growth, and plan in maintenance time to grow the file, as required.
Currently, this alert is disabled for log files, as the log file use patterns are not predictable based on historic growth (more on this in the next section). It is also disabled for the master, model, msdb and tempdb databases. You can choose to alert when one of three different thresholds are breached, for a database’s data file:
- Time Remaining: This is the default and is raised when the remaining time until the data file fills is less than a specified time. Time Remaining is calculated by deriving a line of best fit using 30 days of data for the data file and using this linear regression to project forward to the file’s current size.
- Percent Full: Raised when space used in a data file is above a specified percentage.
- Space Remaining: Raised when the available space is less than a fixed amount.
So, for example, you can choose to receive an alert when time until the file is full is less than 2 weeks, or it reaches 90%, or less than 500 MB is available.
You can also configure this alert so that it automatically escalates when space used increases. For example, you could specify a Low alert when space used is 70%, and then escalate to Medium when it increases to 85%, and High when it is above 95%. Within the alert you will see a graph displaying file usage history.
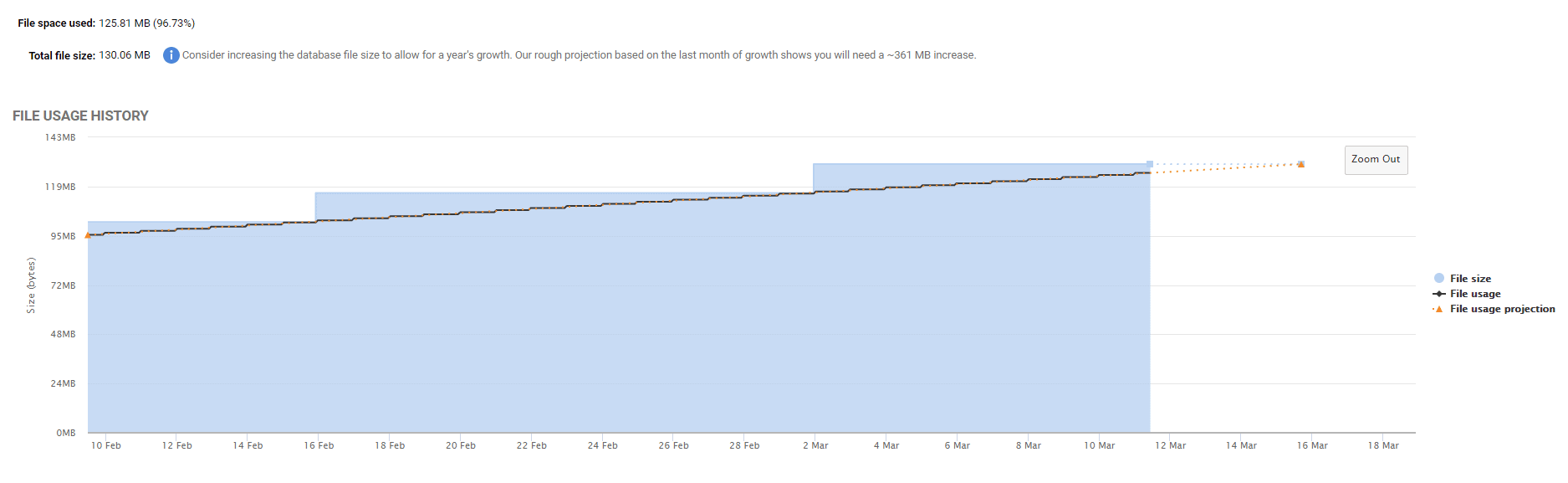
Figure 7
This light blue line, and shaded blue area shows the actual file size, and you can see the “jumps” where the file has grown. The dark line shows growth in space allocation within the file, and the orange dotted line shows the projected file usage
Where the orange and light blue lines intersect indicates when the file will be full, and so the next file auto-growth event will be triggered (assuming the disk is not full). If that time is inconvenient to your business, then you can plan in a time to manually increase the file size.
By examining the alert history, the frequency and timing of alerts, you can assess growth patterns for your data files and how you may be able to make optimizations. As with all Redgate Monitor alerts, you also a lot of other useful performance statistics for the host machine, at the time an alert was fired, such as processor time, average disk queue length, memory usage, transfer speed and more.
If space within the data file is being used abnormally quickly, you’ll need to investigate. If you know that certain tables within your databases are hotbeds of data growth, then you can track their growth over time using the Table size (MB) custom metric in Redgate Monitor (which queries sp_spaceused).
Monitoring space use in the log file with Redgate Monitor
Tracking space use in the log file, to predict when it will need to auto-grow, is more complicated. When we modify data (insert, delete or update), or any database objects, SQL Server writes a log record describing each change, into the transaction log. When the log file is full, SQL Server will reuse space in the log by overwriting old log records, providing nothing is preventing it from doing so, such as a long-running transaction, or a lack of log backups (for databases using FULL or BULK LOGGED recovery model).
Assuming there is no other reason why it can’t do so, SQL Server will truncate the log regularly, so that existing space can be reused, either after a log backup, or after a CHECKPOINT process (for a SIMPLE recovery model database), and so log space will be reused in a cyclical rather than linear fashion.
However, if you know how full you expect a log file for a particular database to get, given the frequency of database modifications, and the frequency of log backups, then you may want to use Redgate Monitor’s Percentage of used log space custom metric to receive an alert if it goes above a certain threshold.
Monitoring database file growth
If initial data and log sizing is done correctly, and you are monitoring file usage carefully, as described above, then increases in physical file size will be anticipated, rather than ad-hoc, using file auto-growth.
However, projecting data storage requirements for new databases is notoriously hard, and even established databases can sometimes auto-grow unexpectedly for a variety of reasons. Unanticipated data imports, software bugs that cause transactions to remain open endlessly (preventing log truncation), maintenance operations, and more, can all cause unexpectedly rapid growth. When a database grows explosively, it will cause file autogrowth events that can consume a lot of CPU resources. If the happen during a busy period, it can cause blocking and disruption of application processes.
Reliance on auto-growth is not a good file size management strategy. It should be enabled but used only to provide a ‘safety net’, to accommodate cases of sudden, and unexpectedly rapid file growth (assuming they also ensure that the disk volumes housing the data and log files have adequate space to accommodate unexpected growth).
In other words, auto-growth occurs, you need to be aware of the it, and to investigate the cause.
Ad-hoc tracking of database growth
A classic approach to tracking database growth was to capture database growth from the nightly full backup for each database, using msdb.dbo.backupset, and to track it over time in Excel. Alternatively, the sp_databases system stored procedure will give you the total size (in KB) of all databases on instance, or you can use various system tables and views.
The size column of the sys.database_files catalog view provides the size of each database file in 8-KB pages, so calculating the total size of the database, in GB, is simple:
|
1 2 |
SELECT SUM(size) * 8.0 / 1024.0 / 1024.0 AS SizeInGB FROM sys.database_files; |
You can find out which database experienced recent auto-growth (or also auto-shrink) events by querying the data collected by the default trace. However, the default trace file does roll over, so historical data is overwritten, and you’ll only see recent auto-growth events, since the last rollover.
Monitoring database growth in Redgate Monitor
The total database file size custom metric in Redgate Monitor collect and analyse data from sys.database_files (using the previous query), over time. If this metric detects a change in overall database size, then a database is probably growing at an unexpected rate, and the DBA needs to understand why. Was the database growth caused by data or log file growth?
Redgate Monitor makes available a database autogrowth custom metric, which will collect the data from the default trace on a schedule. If the metric data is collected on a shorter cycle than the trace file rollover, then you won’t miss any growth events, and you can set an alert on this metric, so you’re immediately aware that an unexcepted auto-growth event occurred.
Monitoring data file growth
When data files grow, they can use instant file initialization, allowing SQL Server to allocate more disk space, without needing to zero-initialize all this space before any data can be written to it. This makes each growth event relatively efficient, but if the file needs to expand frequently, it can still cause blocking problems, because other database processing must pause until the growth event completes. Over time, it can also lead to physical file fragmentation.
The previously-described database file usage metric and alert gives you the diagnostic data you need to monitor data file growth, as well as space use within the file. However, you can also use the database file size custom metric, which collects values from the sys.dm_os_performance_counters Dynamic Management View (DMV), to track changes in data file size.
Monitoring log file growth
SQL Server writes to the log in response to every transaction that adds, removes or modifies data, as well as in response to database maintenance operations such as index rebuilds or reorganization, statistics updates, and more. Even the most diligent DBA might occasionally be caught out by unexpectedly rapid log file growth for a database, so we’ll consider log growth in a little more detail.
In contrast to data files, transaction log files cannot take advantage of instant file initialization, so each log growth event is relatively expensive, in terms of time and resources. While it’s happening, no other transactions will be able to use the transaction log, and the database will be “read-only” until growth event completes.
Rapid log growth can result from large-scale data or database modifications, such as caused by index rebuilds, or by long-running data purge or archiving processes, for example, or by uncommitted transactions preventing space reuse in the log.
Figure 8 shows an Analysis Graph in Redgate Monitor. I’ve plotted on the graph just two metrics, the total log file size for one of my test databases (MyTestDB), and the machine processor time for the instance. It shows a period of explosive transaction log growth.
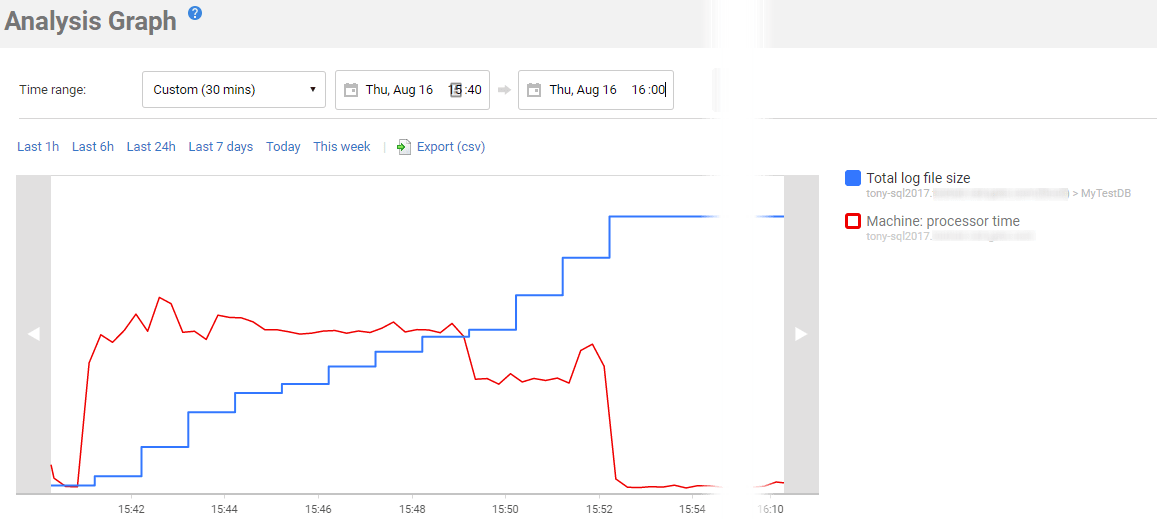
Figure 8
Figure 9 shows the server metric graphs, over the period of explosive log growth, along with the most expensive queries that ran over that period.
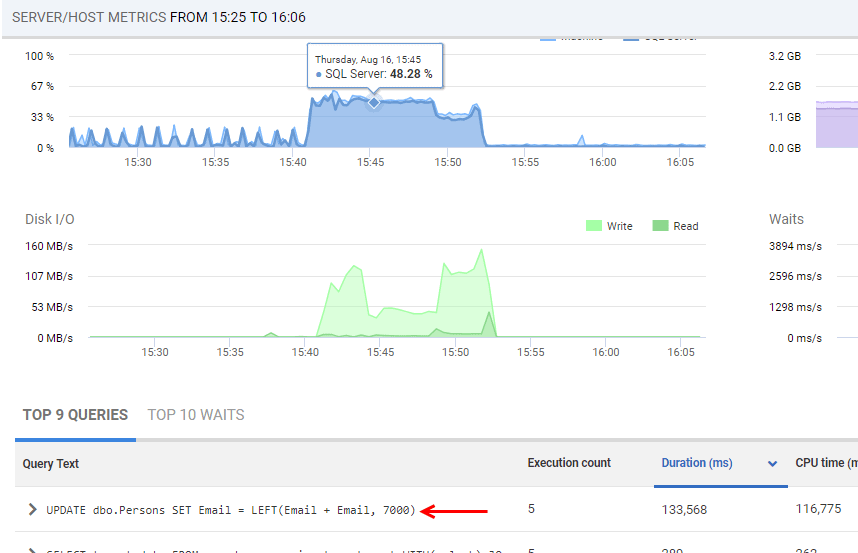
Figure 9
In this case, the (contrived) cause was a series of updates on a Persons table containing several million rows. However, large-scale data purges, when archiving data, can have a similar impact. SQL Server must log the changes to every row of data, and the situation is exacerbated by the presence of constraints and triggers exacerbates the problem.
For example, if you’re performing a data purge, and tables reference the target table, via FOREIGN KEY constraints designed to CASCADE ON DELETE, then SQL Server will also log details of the rows deleted through the cascading constraint. If the table has a DELETE trigger on it, for auditing data changes, SQL Server will also log the operations performed during the trigger’s execution. All of this can lead to explosive log growth that will occasionally defeat even the most diligent growth projection calculations.
Controlling log growth during large-scale data changes
It’s a good practice to run large-scale data operations in small batches, giving the transaction log a chance to truncate in between, either when the next CHEKPOINT runs, if the database uses the SIMPLE recovery model, or the next log backup, if the database uses the FULL or BULK_LOGGED recovery model.
In my example, the MyTestDB database was operating in FULL recovery model, so the transaction log can be truncated, and existing space reused, only after a log backup has occurred. The database grew to over 20 GB in size (from an initial size of under 1 GB), due entirely, in this case, to log file growth (the previous data file usage alert did not fire, because no space was used in the data file).
Redgate Monitor offers a custom Large transaction log files metric that alerts when the number of databases with a large log (over 10 GB, but configurable) increases.
When something is preventing reuse of log space, you’ll need to query the log_reuse_wait_desc column in sys.databases, to find out what. It is often due to either a long-running transaction, or a lack of log backups (Redgate Monitor should have alerted you to that too!), but there are other possible causes.
An associated problem with uncontrolled log growth, especially when the log file is configured to grown in small increments, is that it can lead to log fragmentation, where the log is composed internally of a very large number of Virtual Log Files (VLFs). In my example above, the log grew repeatedly and rapidly in size, and ended up with over 2000 VLFS, as revealed by running DBCC LOGINFO. An “internally fragmented” log can degrade the performance of operations that read the log, such as log backups, or replication and mirroring processes. It can also slow down crash recovery, because SQL Server must open the log and read each VLF before it starts recovering the database.
When setting the FILEGROWTH value for the log, you’ll both want to avoid the fragmentation that can result from allowing it to grow in small increments. Don’t overdo it though because, if you set the increment too high, then you risk a timeout occurring during normal transaction log growth events (due the need to zero-initialize all the space). A fixed auto-grow size of 512MB is often suggested as a guideline, but it is much better to understand the log growth characteristics and behavior on your own system and set the autogrowth size accordingly.
Summary
Manually, you can set up alerts to be warned when your disk space is running low, and hopefully make more space available in time to avoid any database ‘outages’. However, this sort of reactive disk space management only gets you so far, because it gives you no idea about how soon this will happen.
The diligent DBA wants to avoid any chance of running out of disk by being aware how rapidly space is being used within database files. A tool like Redgate Monitor makes it very easy to capture this data, but it also does a lot more. It analyses the data it collects to capture data growth trends and uses them to predict accurately when you will run out of space. This gives the chance to plan, rather than just react, and to minimize any disruption caused by either the file filling up, or file auto-growth being triggered.
As you monitor this disk and database growth data, over time, you’ll understand better the growth characteristics of your databases and improve the accuracy of your disk capacity sizing and planning. This way, file auto-growth events will remain an exception, rather than the norm, and as such you can track auto-growth events and be alerted when they occur and investigate what caused the unexpected growth.
Tools in this post
Redgate Monitor
Real-time multi-platform performance monitoring, with alerts and diagnostics
You may also like
-

Webinar
Maximize Your SQL Server Efficiency with Redgate Monitor
Managing your SQL Server estate has never been more critical. Join our webinar to explore how Redgate Monitor offers a holistic solution for monitoring your database performance, availability, and security from a single pane of glass. Key features include: Global Overview: Monitor all your servers at a glance. Diagnosis: Quickly identify root causes of issues.
-

Live training session
Lou Test 2
With database estates growing faster than ever, deployment rates increasing, and constant demand for fast fixes and high availability, using the right monitoring tool is the only way to keep track of what’s going on across all of your databases, instances, and servers. In this webinar, discover how SQL Monitor can provide answers to the
-

Business leaders webinar
How estate monitoring enables Vistaprint and their 17 million global customers
Vistaprint Senior DBA, Adam Brenden joined Microsoft Data Platform MVP, Grant Fritchey to discuss how proactive estate monitoring and reporting enable the Vistaprint team to detect, diagnose, and resolve issues before they impact operations or customers.
-

Article
Migrating Between Monitoring Systems
This question comes up all the time: How do you migrate between monitoring systems? The answer is both simple and complicated. In order to understand this better, rather than just rely on my own knowledge, I reached out to a number of people to see how they accomplished this. I’m going to summarize their process
-
Article
Automate Responses to Bad Deployments with Redgate Monitor
Jamie Wallis explains how Redgate Monitor can both reveal quickly who ran a deployment, and when, and automate the incident-response workflow to ensure it's dealt with swiftly. By extending such workflows to development and test servers, as well as production, the feedback cycle starts earlier, and you can stop problems from ever reaching the users.





