





Evaluating SQL Data Catalog using Docker Containers
Like many other database developers these days, I have switched to an entirely container-based SQL Server test lab. I love having a demo environment for SQL Server available locally, which I can easily persist and restart, or flush away and start again. Why would I ever go through that "next-next-ok-next" installation sequence, which is joyless even in the best software? Or, sometimes even worse, the protracted process of ensuring the software uninstalls cleanly.
If you're of the same mind, then it will also make sense to you to evaluate new database software, such as SQL Data Catalog, using the same approach. We've tried to make this as quick and easy as possible by providing SQL Data Catalog as a Docker image, which you can install and configure simply, using docker compose. As we release updates to SQL Data Catalog, we'll refresh the Docker images, so installing these will be very simple too.
SQL Data Catalog creates the data classification metadata that describes the data that your organization uses. It will apply classification and labeling to any personal or sensitive data in each data source, revealing where, throughout the organization or elsewhere, this sort of data is stored and used. The types of data, the business owners, the purpose and the sensitivity of the data will come naturally from any competent data cataloging. – Josh Smith. Data Categorization for AdventureWorks using SQL Data Catalog
The Docker Set up
The first step will be to install a SQL Server 2019 image into a Docker container, in my case called SQL2019, get it running and then install into it the demo databases we wish to categorize.
We then need to get SQL Data Catalog running in a container, within the same VM. We'll do this using docker-compose. This in fact creates two containers, one for the application (sqldatacatalog) and another one (sqldatqcatalog_storage) where the SQL Data Catalog service can create the SQL Server instance and database it needs, for storing state. Docker creates a virtual network (sqldatacatalog_default) for these two containers.
The final step is to connect the SQL2019 and sqldatacatalog containers, simply by using docker network connect to connect the SQL2019 container to the default network.

At this point, you'll be able to open SQL Data Catalog in your web browser, add the SQL2019 instance and evaluate how SQL Data Catalog can help you discover and categorize your data.
1. Set up a SQL Server 2019 instance in a Docker container
To set up my SQL2019 instance, running in a docker container, I followed the guidance already laid down by a few SQL community authors:
- Andrew Pruski sets out the fundamentals:
- Catherine Wilhelmsen adds in some examples to help you pull in Microsoft's sample databases:
- Phil Factor shows how to set up a SQL Server instance inside a Linux Docker container, create some sample databases, and persist data locally:
- Running Linux SQL Server as a Container
- Database Delivery with Docker and SQL Change Automation – how to automate database builds into these containers, though this task isn't required for this article.
Following their instructions, I'm soon ready to start my SQL Server container, using the -v command to specify a persistent, named volume from which I can restore some database backups, without first needing to copy them into the container filesystem:
docker container run --name SQL2019 -p 1433:1433 -v ~/Dev/Docker/SQL:/sql -e ACCEPT_EULA=Y -e SA_PASSWORD=My*Very*StrongP@ssw0rd! -d mcr.microsoft.com/mssql/server:2019-latest
Next, we install sample databases into container simply by restoring backups, moving the files to the filesystem of the container.
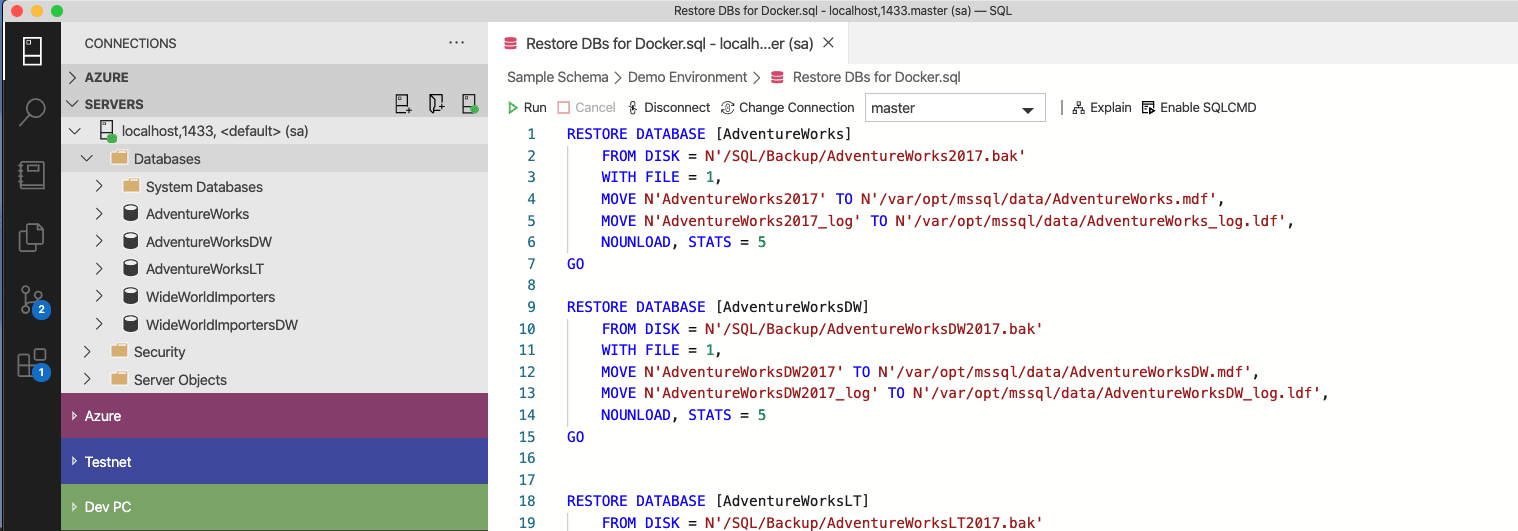
That done, I'm good to go; I've got an instance of SQL Server 2019 with some sample databases.
2. Running SQL Data Catalog in a container
The next step is to get SQL Data Catalog running in a container, within the same VM. According to the instructions on the Docker Hub, https://hub.docker.com/r/redgate/sqldatacatalog, I can either run the application and configure its connection to a database for its backend SQL store, or allow Docker to do that for me by using docker-compose.
I'm going to go for the latter option, so the first thing I need to do is copy and save the example docker-compose.yml file provided on the Docker Hub page (changing the sa password, of course):
version: '3.7'
services:
datacatalog:
image: "redgate/sqldatacatalog:1"
command: IAgreeToTheEULA
environment:
- REDGATE_SqlDataCatalog_StateStorage__ConnectionString=Server=storage;Database=DataCatalog;User=sa;Password=Str0ngP@ssw0rd!;
ports:
- "15156:15156"
depends_on:
- storage
storage:
image: "mcr.microsoft.com/mssql/server:2019-CU1-ubuntu-16.04"
environment:
SA_PASSWORD: "Str0ngP@ssw0rd!"
ACCEPT_EULA: "Y"
Then, from Docker cmd line, navigate to that folder where you saved it and run docker-compose up.
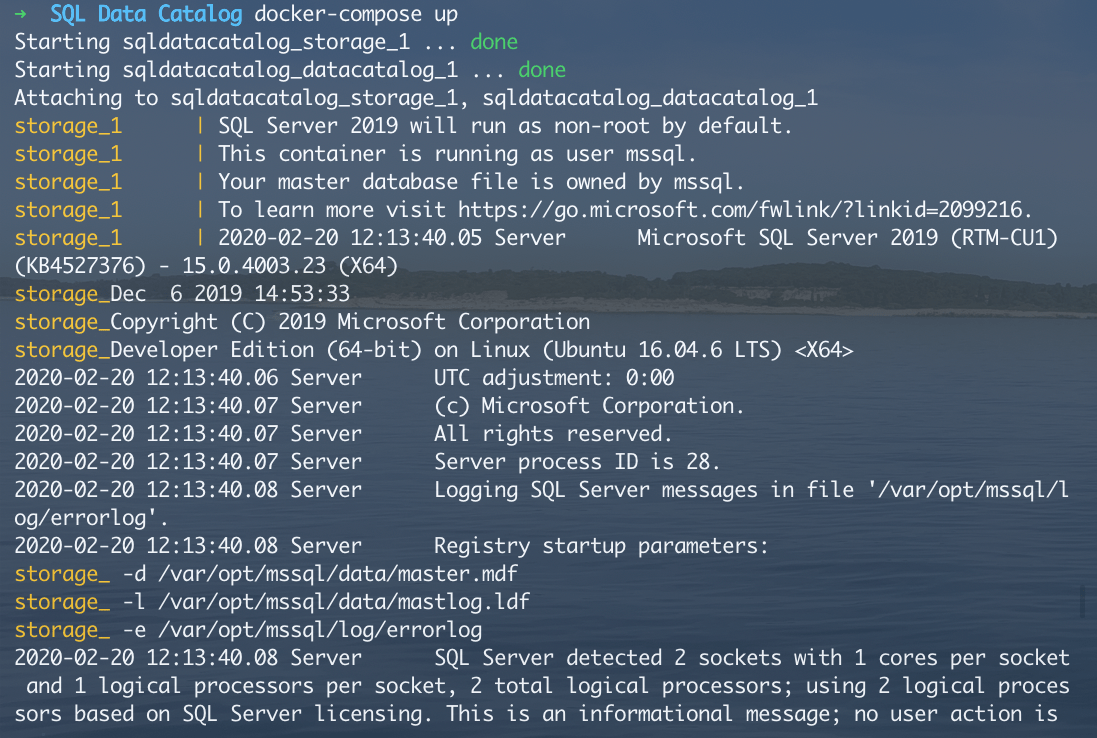
I'll see in my terminal window that Docker is creating the database backend and the application container for my evaluation of SQL Data Catalog.
One that's running (give it a few seconds), I'll have an instance of SQL Data Catalog available at http://localhost:15156/.
Note that, with the current configuration, it is possible to encounter a race condition where SQL Data Catalog starts before the backend is ready. If you see an error when you connect in your browser, just stopping the process with ctrl-c and running the docker-compose command again will usually fix it. Alternatively, open a new command window in the folder containing the docker-compose.yml file, then run:
docker-compose restart datacatalog
3. Connecting the containers
So far, so good, but it's looking a little empty in there. What I need are some SQL Server instances so I can try out data classification.
Here's where some more Docker magic is going to help.
I already have my SQL2019 container, and now I've created two other containers for the application and database, as required to run SQL Data Catalog. When we spun up SQL Data Catalog in a container, with a dependency on a storage container, Docker automatically established a virtual network (sqldatacatalog_default) through which the two could communicate.
However, this network does not yet know about our SQL2019 container. However, this is easily fixed, by simply connecting my SQL2019 container to that network, by running the following in a command window (like MacOS Terminal or Windows cmd):
docker network connect sqldatacatalog_default SQL2019
I can check that has worked by running:
docker inspect sqldatacatalog_default
In the network section of the output, I can see that this network knows about 3 containers:
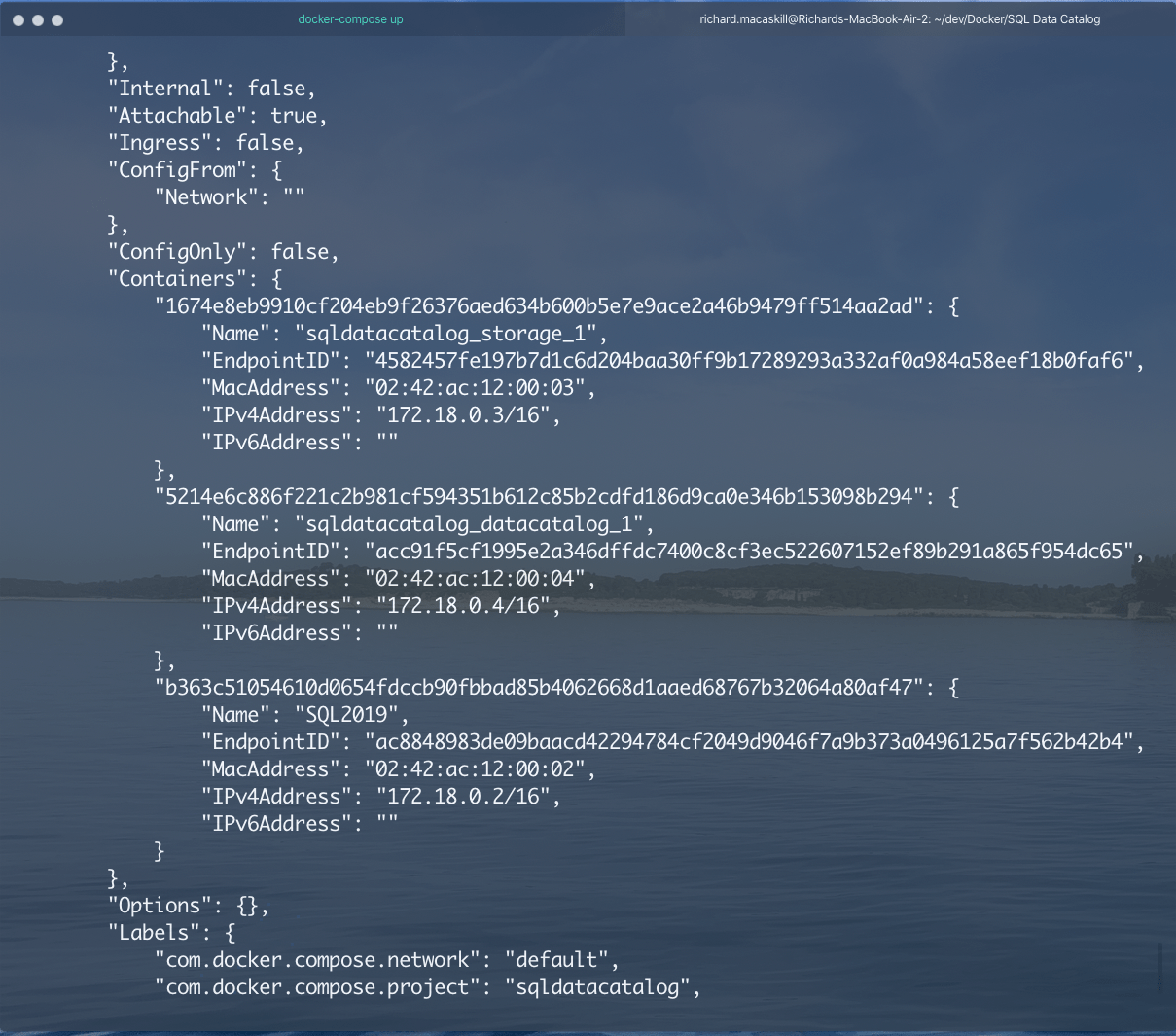
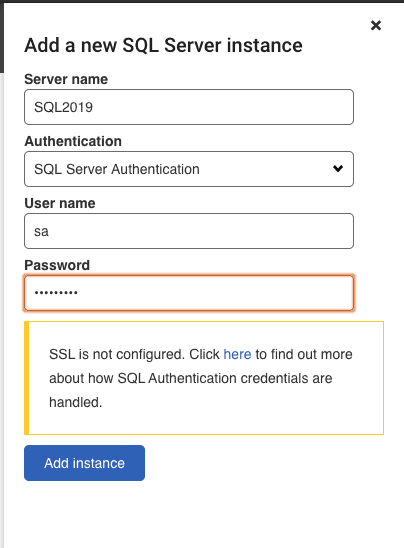
Now, in SQL Data Catalog, I can add my demo SQL Server instance using SQL Server authentication (Windows authentication doesn't work when running SQL Data Catalog in a Docker container) and connect using the password I specified for it in my Docker command earlier:
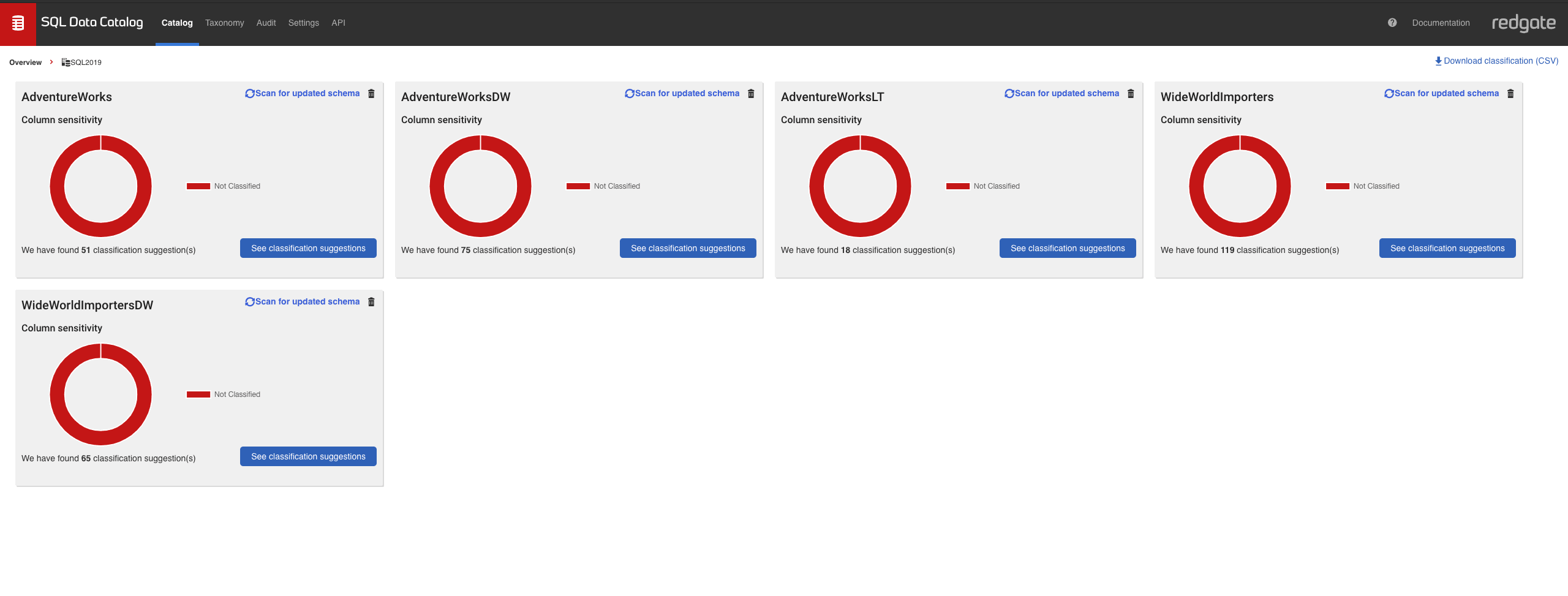
SQL Data Catalog will connect and start scanning each schema in my demo environment. Allow that task to complete, and when we click on the SQL 2019 instance, we'll see our sample databases ready for us to try out data classification.
Next Steps in Evaluating SQL Data Catalog
Try accepting some of the suggestions, customizing the taxonomy, and using the REST API and PowerShell to see how SQL Data Catalog can help you classify your SQL Server estate. I'd recommend checking out the documentation here and especially the PowerShell worked examples (there's one to automatically classify AdventureWorks, here).
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
The Need for a Data Catalog
In the event of a breach of personal data, any organization must produce proof that they understand what data they hold and where, and how it is being used, and that they have enforced the required standards for access control and security. To make all this possible, it is essential to build a complete model of the data and its lineage, and a data catalog is the first step in this process.
Article
What is a Data Catalog?
A data catalog allows an organization to discover and record the facts about its data, where that data is held and how it used. William Brewer explains the details.
Article
Documenting a SQL Server Data Catalog in HTML and Git Markdown
Dave Poole explains the need for high quality database documentation and then demonstrates how to document the SQL Server database for a data catalog, in both HTML and Git Markdown, using SQL Doc, SQL Data Catalog, PowerShell, and a few helper scripts to ensure consistency and correctness.
Article
Practical steps for end-to-end data protection
If you plan to make production data available for development and test purposes, you'll need to understand which columns contain personal or sensitive data, create a data catalog to record those decisions, devise and implement a data masking, and then provision the sanitized database copies. Richard Macaskill show how to automate as much of this process as possible.
Article
Data Governance: Joining the Dots
Every organization must perform data governance. This requires planning, oversight, and control over the management, security, resilience and quality of data and over the use of data by the organization. In larger organizations, it can be a complex task. William Brewer explains what's involved.

Article
Meeting your CCPA needs with Data Classification and Masking
This article will explain how to import the data classification metadata for a SQL Server database into Data Masker, providing a masking plan that you can use to ensure the protection of all this data. By applying the data masking operation as part of an automated database provisioning process, you make it fast, repeatable and auditable.
Loading comments...