A behind the scenes glimpse of SQL Clone
It has always been a difficult task to provision development and test environments so that they reflect as closely as possible what’s present in production. With the rise of containerization and Infrastructure as Code (IaC) technologies, some parts of this are becoming much easier. We can automate the process of spinning up and configuring new virtual machines, of installing and configuring SQL Server, and so on. However, we still have one missing piece here: data. This final step of being able to deploy and then tear down, on demand, a database filled with realistic volumes of data, on multiple development and test environments, is still a long and slow process.
Most of us have rolled our own solutions for this, due to lack of tooling help in this space, but there are plenty of reasons why we need to find better ways to solve this problem. Firstly, it makes it much easier to diagnose production problems, without needing to access the live production database. Secondly, it makes it possible to have realistic testing environments, where developers can perform test runs quickly and in parallel, to verify that the application integrates, performs, and scales as required.
Fortunately, it turns out that we can use the technological advances that underlie virtualization to make the database provisioning process a simple, quick task. SQL Clone uses established disk virtualization technologies that are built into Windows to allow us to make clones – “editable copies” – of a SQL Server database within seconds, using very little additional disk space.
From SQL Server’s perspective, the database clone we create is just a normal database, complete with data, and we can query it and update it just as we would any other database. The Redgate website outlines the basics of what SQL Clone can do, and some of the use cases, but in this article I want to explain how SQL Clone actually works.
Core SQL Clone concepts
Before trying to understand how SQL Clone works, we should first understand the two core concepts behind it, which are data images and clones.
A data image is a point-in-time representation of your SQL Server database, which can be created from a backup file or a live SQL Server database. It contains a copy of the MDF (schema and data) and LDF (transaction logs) files of the database. A SQL Clone data image is immutable and cannot be altered after it’s created.
Producing the data image takes as much time as a backup or restore, depending on the size of the source backup file or database. Of course, we can automate and schedule this process so that it runs overnight, if required.
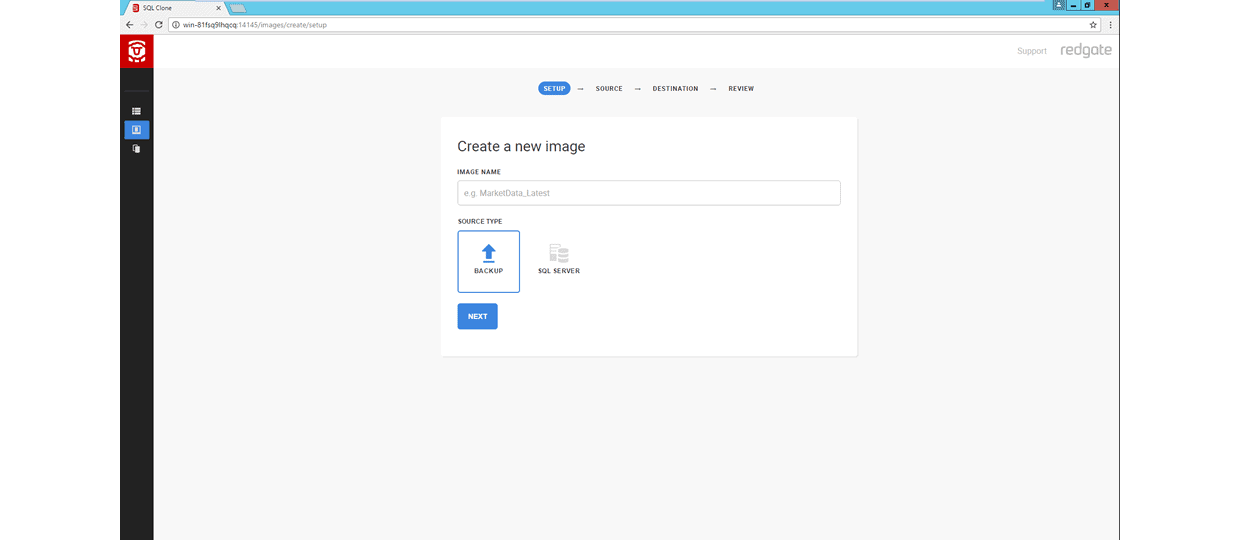
A clone, on the other hand, is an isolated copy of the database which is derived from a data image. One of the most magical parts about a clone is that it’s blazingly fast to produce one, no matter the size of the source database. For example, the clone of a several-hundred Gigabyte database will be tens of megabytes in size.
We can create multiple clones from the same data image and all of them will be isolated from each other. That means that any change we perform on a clone database will have an effect only on that clone, and will be isolated from the immutable, point-in-time data image of your database.
This means that we can easily create multiple isolated clones, each deriving from the same data image. This is very useful in many cases, but it’s especially valuable in a team environment where, for example, multiple developers can work with their own clones at the same time without affecting each other.
How SQL Clone works
SQL Clone takes advantage of several native Windows disk virtualization features such as Volume Shadow Copy and Differencing Virtual Hard Disk. These technologies form the core of SQL Clone, and it is the Differencing Virtual Hard Disk technology that allows us to isolate changes to a virtual hard disk.
SQL clone works at the file system level and creates a database clone that is essentially just a Virtual Hard Disk (VHD) mount point, which holds the source data image of the database, plus a differencing disk. When we modify anything in a clone database, SQL Server writes the change to the virtual differencing disk files. When we query data, the operating system reconstructs the required data pages from the differencing disk files plus the database files in the original data image.
All of this is transparent to SQL Server, which works with the clone just as it would any other database. Conceptually, we can compare this to the process of creating and then modifying a file in a version control system (VCS). The VCS does not create a new copy of the file each time we modify it. Instead, it stores the ‘deltas’ and then uses these plus the original source file to reconstruct the file at the correct version.
SQL Clone Architecture
At the architectural level, SQL Clone has two essential components. The first is the SQL Clone Server, which acts as source of all truth and the message router. It runs as a Windows Service and you can interact with it through its beautiful web client on a browser:
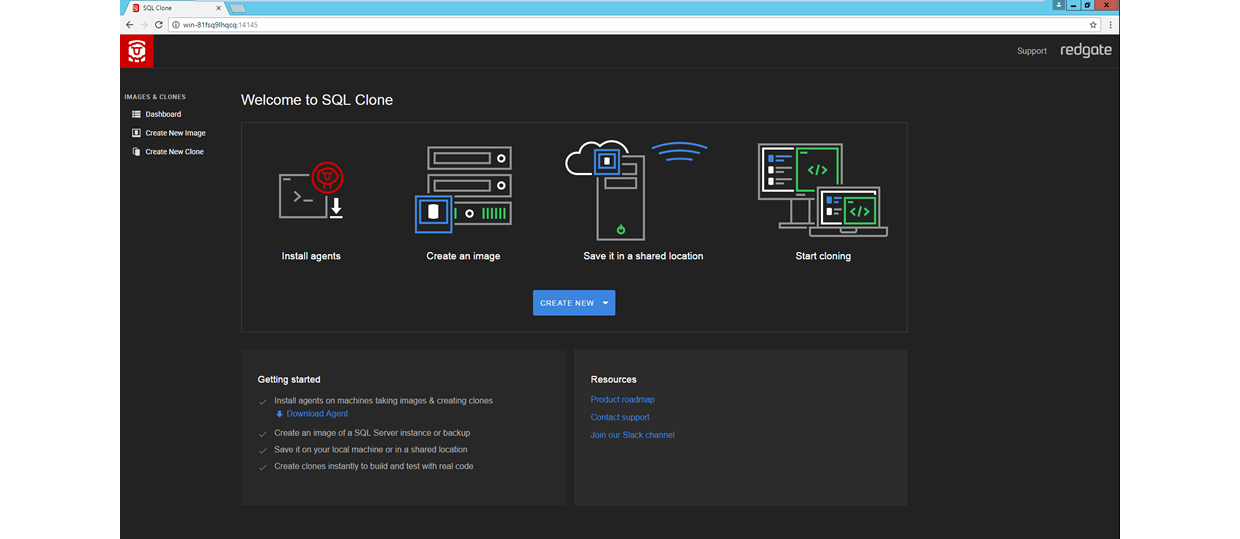
Ideally, you would install this component on a server that everyone on your team can then access.
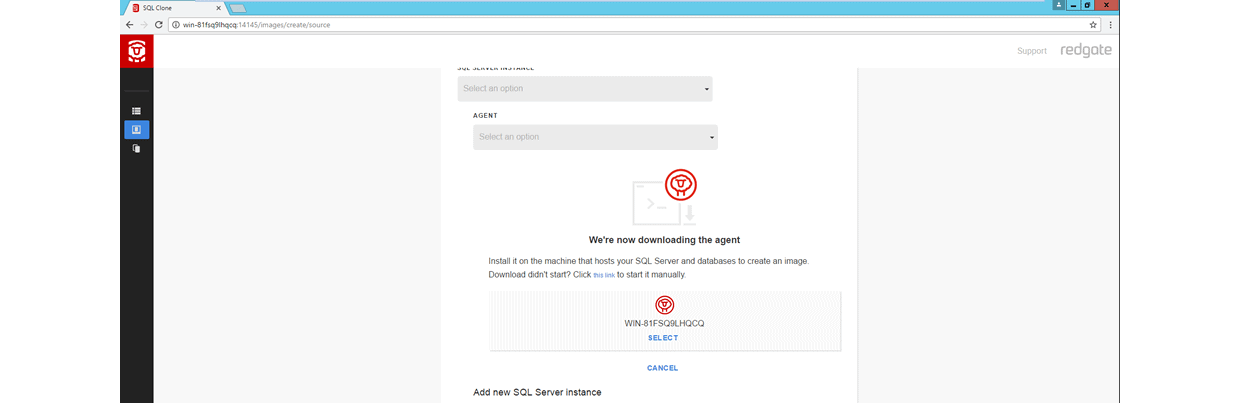
The second important component is the SQL Clone Agent, which acts as the gateway between several resources (SQL Server Instances, Backup Locations, Image Destination Locations, etc.) and the SQL Clone Server.
The Agent component is responsible for performing the work you request through the SQL Clone Server, such as taking a data image from a backup file or creating a clone from a data image. You can obtain an Agent installer through the SQL Clone Server web client to install on machines which have access to your resources.
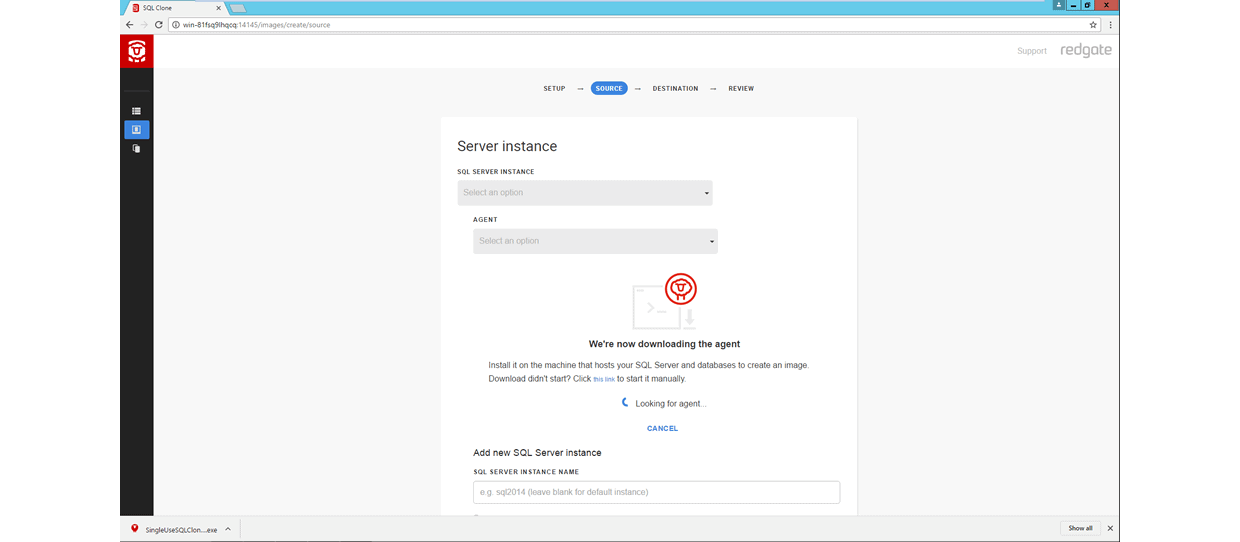
The SQL Clone Agent installer is packed with the necessary information to ensure all communication between itself and the SQL Clone Server is secure and legitimate.
Once you install the SQL Clone Agent, it should do the necessary handshake with the SQL Clone Server instantly to establish a trusted, secure connection and the SQL Clone Server should discover the newly installed Agent.
If you think about SQL Clone in terms of a restaurant for a moment, it can get a lot easier to digest how its components function.
The SQL Clone Server in this analogy is the waiter or waitress. It’s the face of the restaurant, and takes your order, records the order in a safe place and lets you know when it’s ready.
The Agent is the chef who does the heavy lifting and is actually responsible for cooking your meal.
However, all parts need to work in a coherent manner to function seamlessly and give you the best experience; in both the restaurant and SQL Clone case.
After you have both SQL Clone Server and Agent in place, you can now start taking SQL Clone data images.
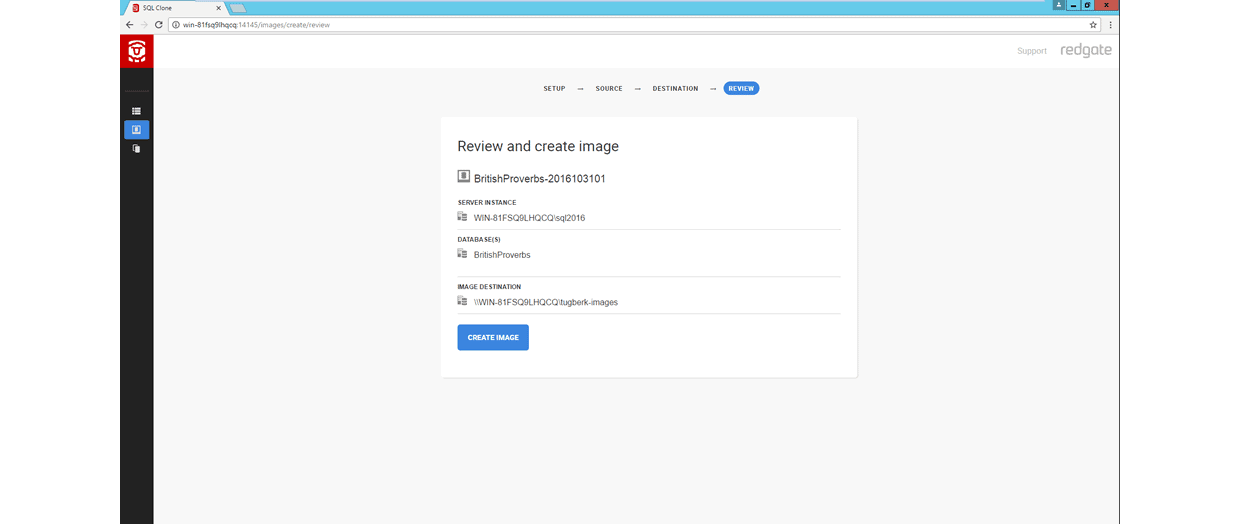
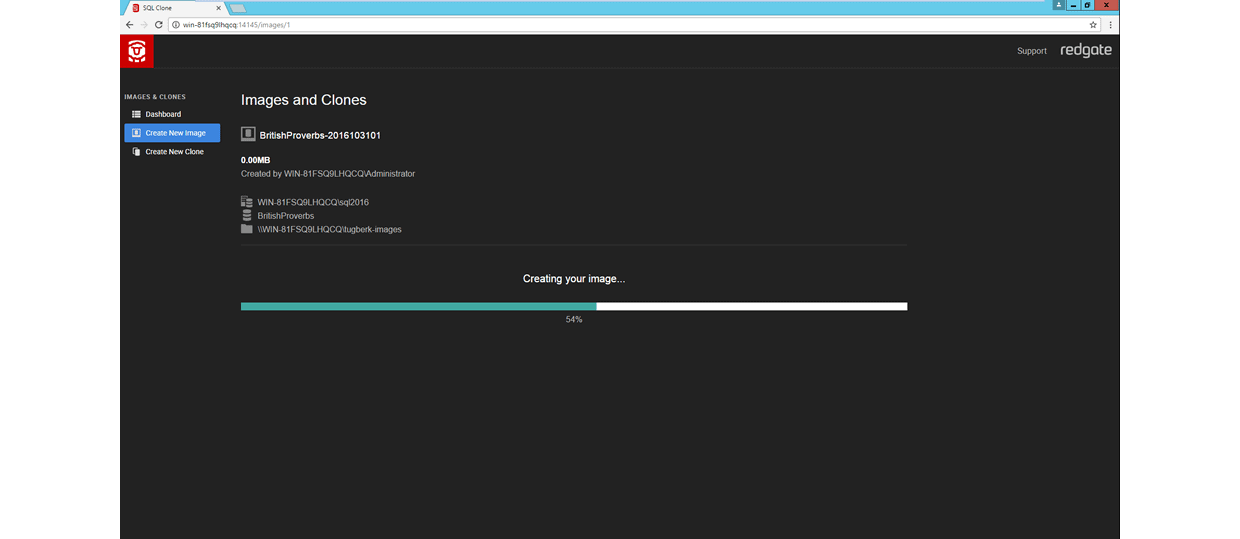
Once the data imaging operation has completed, you can produce clones from that data image.
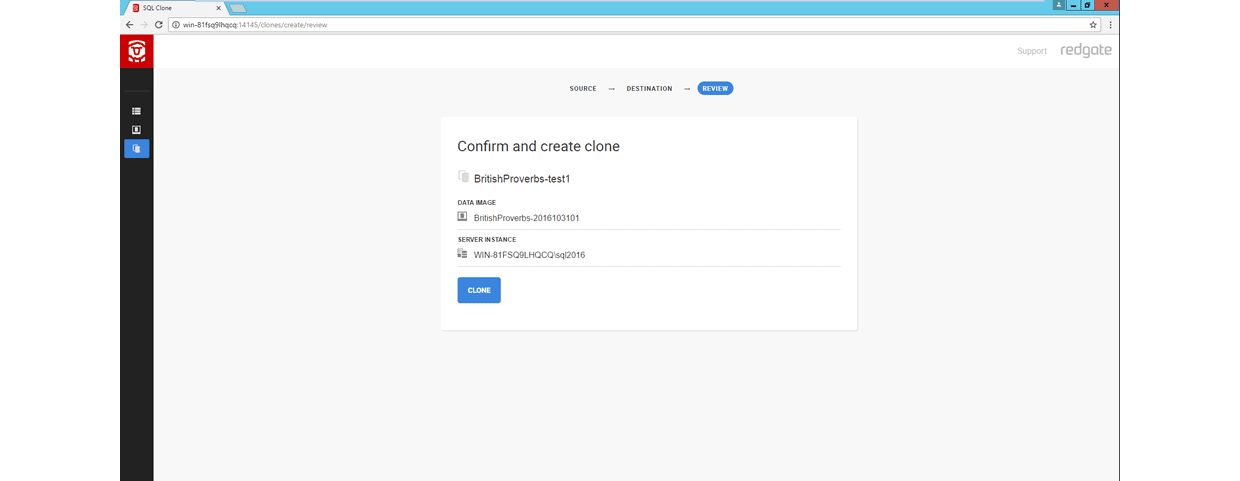
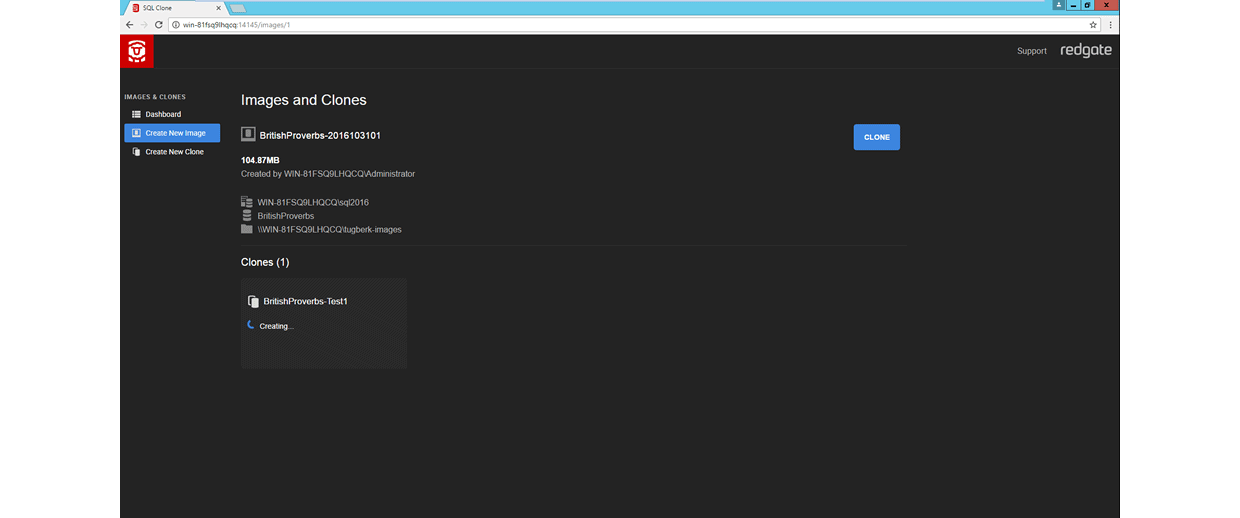
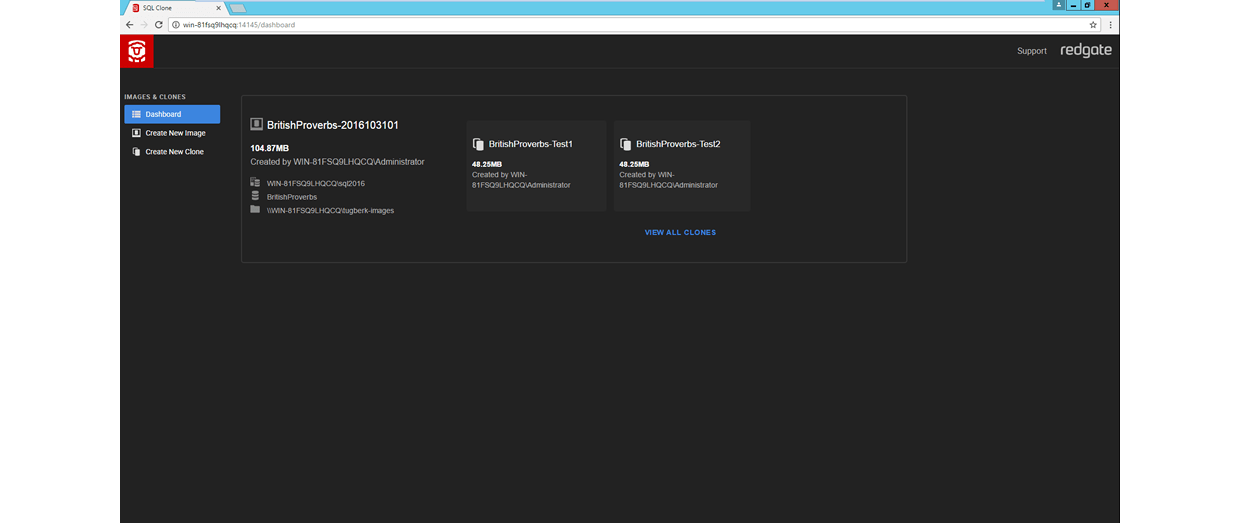
At any point, you can jump to the SQL Clone dashboard view to see your data images and clones associated to those images.
Summary
Provisioning test and development environments with large databases can be a painful and time-consuming task. SQL Clone exploits built-in disk virtualization technologies within Windows in order to create multiple, isolated clones of the original data images, each of which is a fraction of the size of the original source database or backup, but works just like any other normal database.
It has the potential to reduce to minutes the time taken to provision environments, makes it feasible for each developer to work in an isolated environment, performing testing against realistic data, and has many other possible uses.
Download the beta now and start creating database copies in seconds. Interested in finding out more? Visit the product page or take a look at the documentation prior to the release.
Tools in this post
You may also like
-

Article
SQL Clone PowerShell Scripting: The Basics
Phil Factor demonstrates some simple examples of how to use SQL Clone's PowerShell library to pass objects between cmdlets, and simplify common tasks, such as creating and deploying clones from various images. He then documents the objects and cmdlets, and illustrates their inputs and outputs.
-
Article
How to reset your development database in seconds using SQL Clone
Owen Hall describes the new "clone reset" feature, how it works and the database development and testing processes it enables, or makes simpler and quicker.
-
Article
DevOps Self-Service for Databases with SQL Clone
Phil Factor describes the freedom of being able to "self-serve" databases, during testing and development, and explains how it works with SQL Clone.
-
Article
Using striped backups with SQL Clone
Can we use a striped backup as the source for a SQL Clone image? Yes we can!
-

Webinar
POPIA - getting started
-
Webinar
POPIA - round up