







How to monitor backups and other SQL Agent jobs using SQL Monitor
How to monitor any SQL job that runs on the SQL Server Agent so that you're alerted quickly if SQL Agent goes offline, or if a job fails, or fails to start, or is running slow.
How many times, when reading a report of some highly public case of data loss or corruption, do you inevitably stumble across a line like “unfortunately the backup job had not been running for the last three months, and no-one noticed“. It’s not enough just to set up jobs to run database backups, or other critical maintenance tasks; you also need to be sure they are always running smoothly. You need to know when a job fails, and the error condition that caused the failure, but that’s not all. You also need to be alerted if the duration of a job is unusual, or if it fails to start or the email step of the job doesn’t fire.
Ways to monitor SQL Agent jobs
The job activity monitor in SSMS offers some basic monitoring and the Log File Viewer will show you the history of any job, though it’s a time-consuming, manual task to do it this way.

You can also script some basic monitoring by querying the SQL Server Agent Tables, such as sysjobs and sysjobhistory.
While it might be possible to set up custom monitoring and alerting to cover all these eventualities, for all your SQL Servers, it will be a considerable administrative burden. This article shows how with the built-in alerts in Redgate’s SQL Monitor, plus perhaps a few simple custom alerts, you can keep a very close eye on the activities of SQL Server Agent with minimal effort.
Is the SQL Agent service running?
If the Agent service is offline for some reason, no process controlled by SQL Agent is going to run. In other words, all jobs on that instance are going to fail! You need to be notified immediately, restart the service, and then investigate fully the cause of the service interruption.
SQL Monitor’s built-in SQL Server Agent Service Status Alert is enabled by default and fires when the SQL Agent service is offline on any instance it is monitoring. By default, SQL Monitor will raise a medium level alert if the service stops running, and send an email notification.
TIP: Sending Slack or SNMP notifications for important alerts
Find out how SQL Monitor also integrates with various other notification systems, such as Slack or SCOM.
You can customize the alert level, and also modify the alert so that you get notified if the service is paused as well as stopped (using the When the service is: dropdown). You can even add an additional alert to know that the service has been restarted.
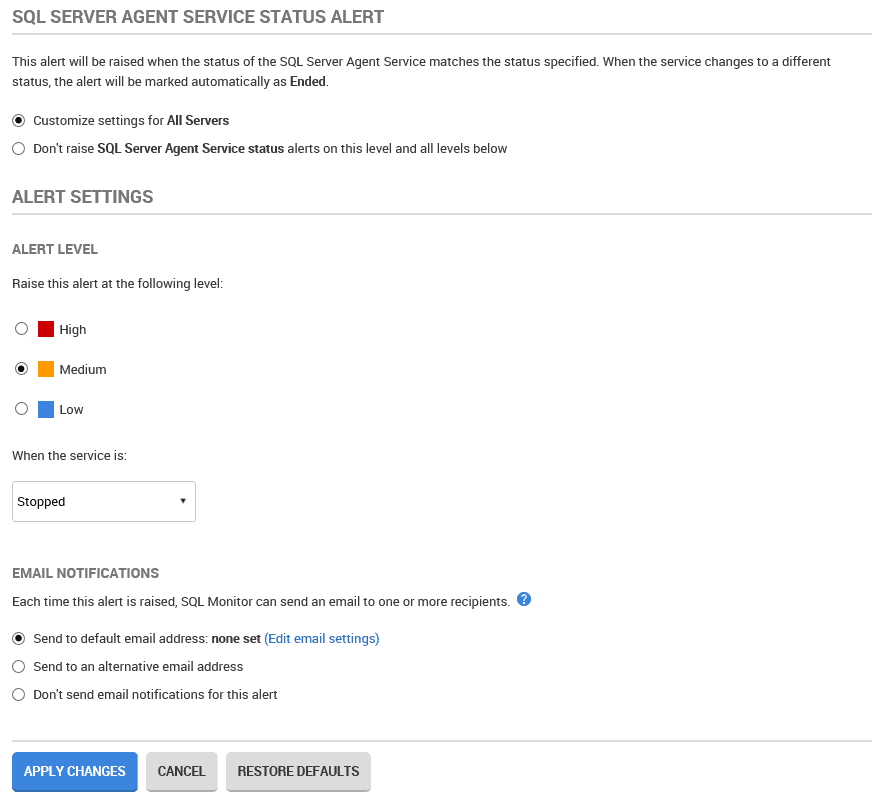
Figure 1
If this is a production box, subject to a sensitive Service Level Agreement (SLA), you might want to change that to a High level alert. After all, if log backups are missed while the service is down, it could affect the ability to recover to a point in time.
For development boxes, or any others that either don’t have scheduled jobs or where the jobs are low priority, you can disable the alert or set it to Low priority.
TIP: Group your servers and customize alerting levels per group
Simply navigate to Configuration | Groups, create your groups, add instances to each group, then customize alerting as appropriate for each instance within that group. See Organizing monitored servers into groups
Did a SQL Agent job fail?
There’s nothing worse than being in the middle of an emergency on a server only to find that backups have been failing for several months. You need to know if a job fails, and you need to know why it failed, and SQL Monitor’s built-in Job Failing alert does just that.
As soon as you open SQL Monitor, you get to see all your monitored instances and their current status.
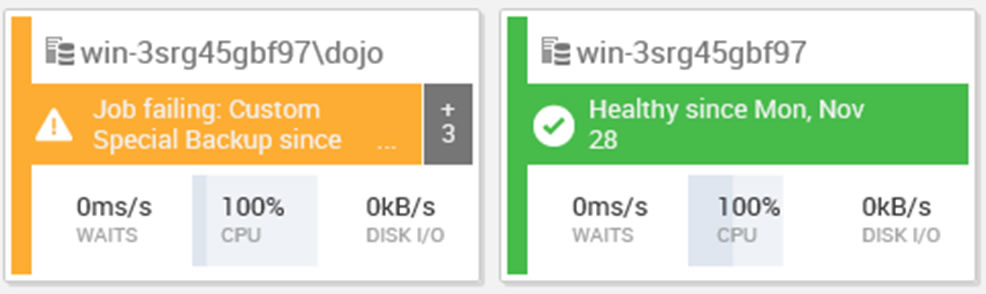
Figure 2
You can see that a ‘Custom Special Backup‘ job failed recently on the first of these two instances. The ‘+3’ on the right hand side indicates there are three additional active alerts for that server.
Click on the alert in question and it will open up a detail screen for that occurrence of the alert. The top half of the screen shows when the job failed, when it’s scheduled to run again, and more. The Occurrences tab will show you any previous failures for this job, on this instance.
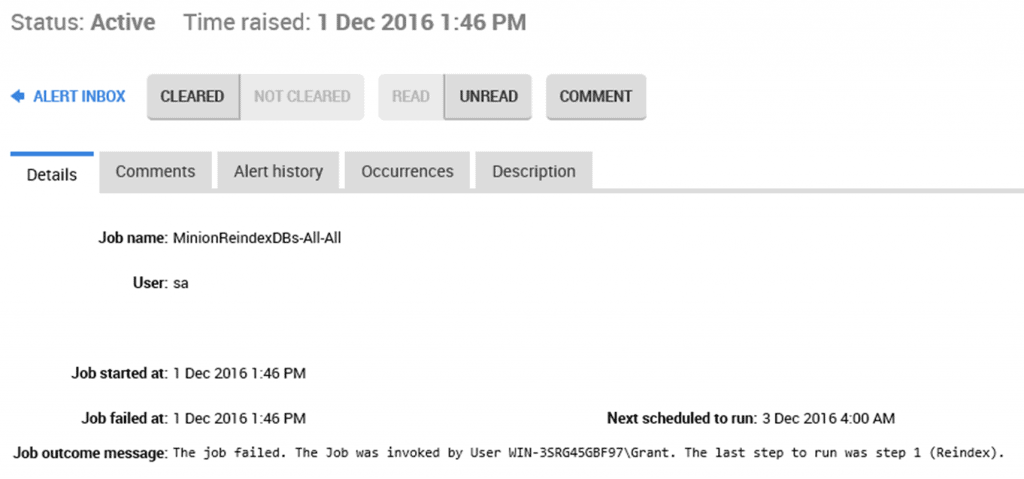
Figure 3
I won’t show the bottom of the screen in this case, but it summarizes some performance metrics collected around the time the job failed, which may help with troubleshooting the cause of failure.
The ‘Job outcome message’ in Figure 3 tells us the job failed, who invoked the job, and the last job step to run. However, this message doesn’t always hold enough information to diagnose what exactly failed and why.
Armed with knowledge of which job failed and when, we can switch to SQL Server Management Studio, navigate to SQL Server Agent | Jobs, right-click the failing job and select View History.
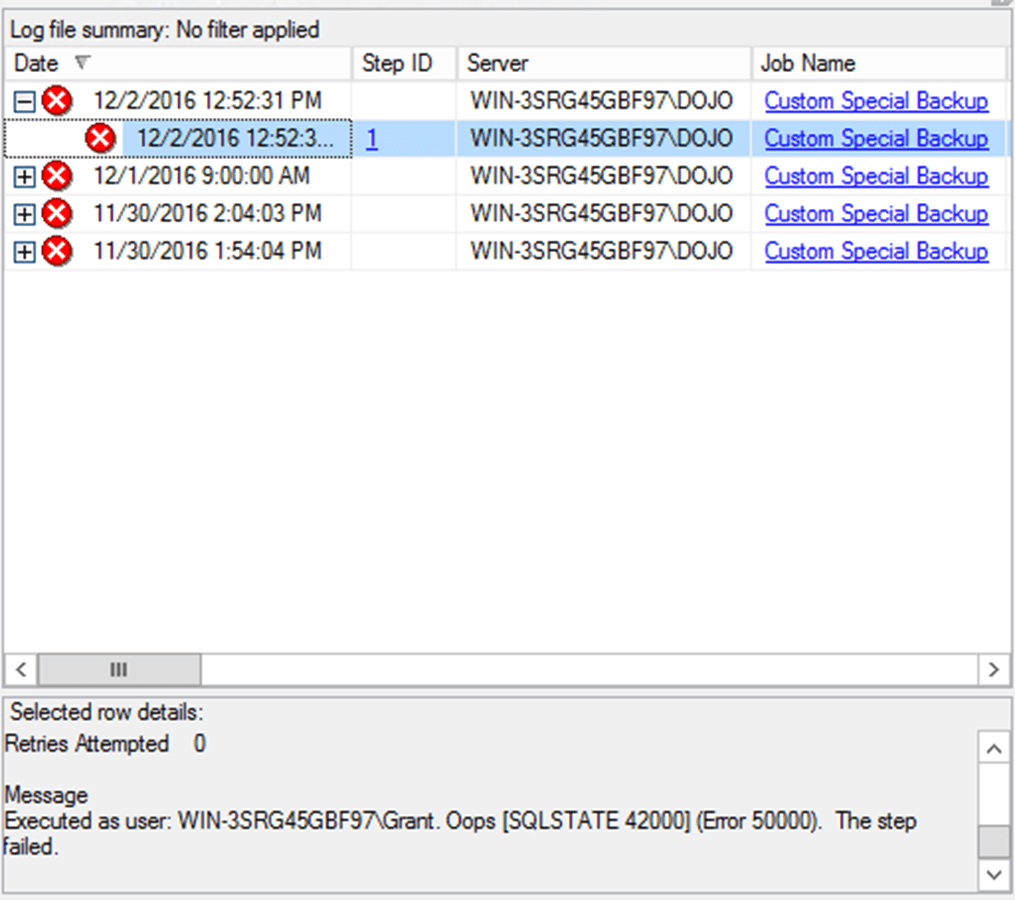
Figure 4
This job has never succeeded in all the times it’s been run. Highlight one instance and expand it to see details of the job step that failed, including the error messages raised. There at the bottom of the screen, you can see that for demonstration purposes, I sabotaged my own backup job by including a RAISERROR command within the script, and passing in an error saying ‘Oops’.
Nevertheless, SQL Monitor let me know immediately that there was a problem. For vital jobs, such as backups on production servers, adjusting the alert from Medium to High would probably be a very good choice.
Did the Agent job fail to run?
While SQL Monitor does not provide a generalized alert for jobs that fail to run at all, it does have the Backup Overdue alert. This checks the age of the backups for all databases on the monitored instance, and will raise a medium-level alert or any that are over the threshold limit (7 days, by default, but adjust this to suit your own SLAs). On any boxes that don’t have a regular backup schedule, you might consider adjusting both the alert level and threshold level.
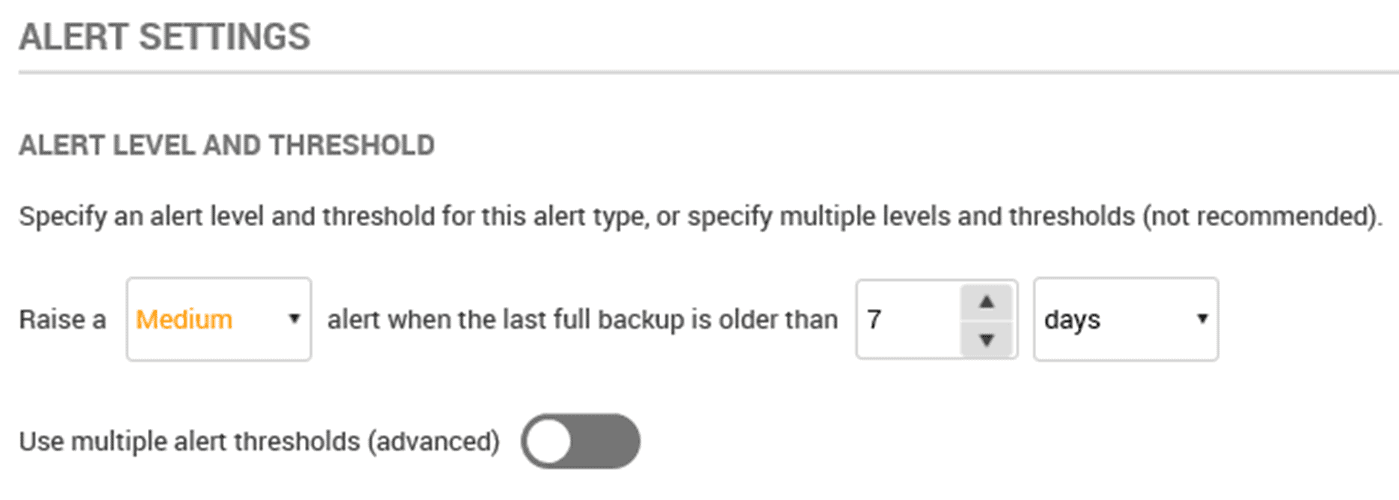
Figure 5
If a backup failed to run, you obviously need to investigate the cause. You might consider setting up a SQL Monitor custom alert to receive a notification if someone disables a backup, for example.
Was a job duration unusual?
If all your jobs are completing successfully, that’s great, but what happens when a job suddenly takes a lot longer than usual to run? It could be explained easily, such as by a recent data load causing a backup job to run long, or the cause could be subtler and more worrying.
SQL Monitor has the Job Duration Unusual alert, by default set to fire a low-level alert if a job deviates from its baseline duration (based on previous 10 executions) by more than 50%, for any job that runs over 120 seconds.
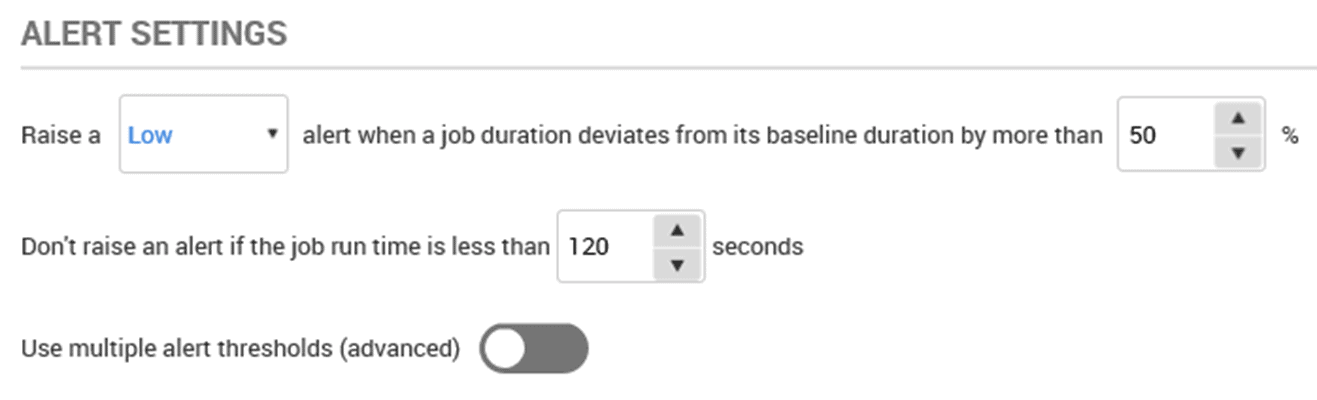
Figure 6
All this can be adjusted, very simply, and we can activate and set multiple alert thresholds, as shown in Figure 7.
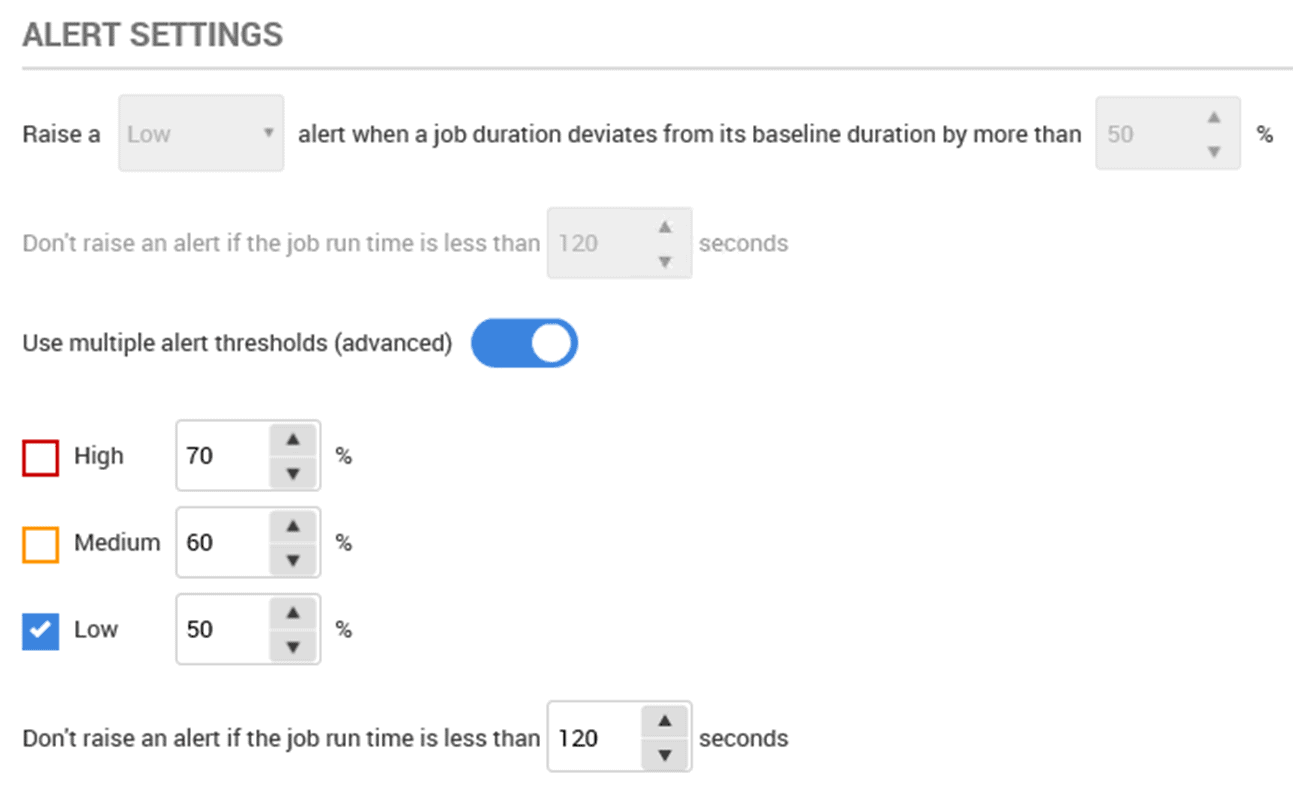
Figure 7
When the Job Duration Unusual fires, you can bring up the details for that instance of the alert simply by clicking on it.
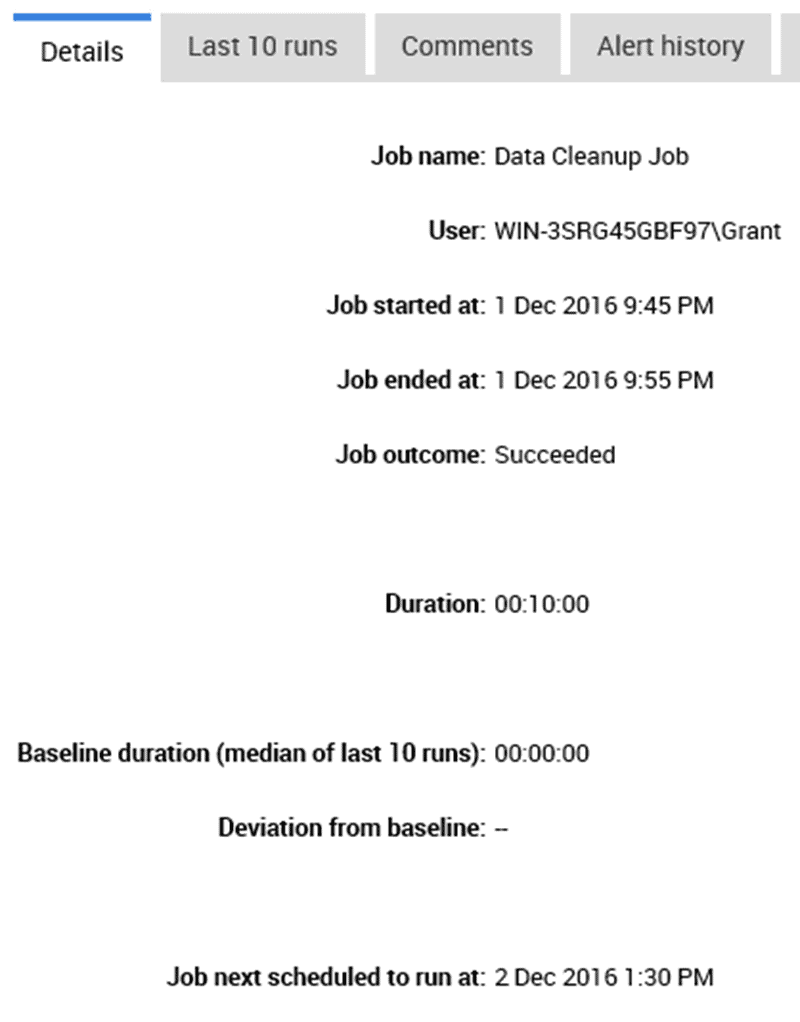
Figure 8
You can see that a Data Cleanup job ran took 10 minutes to run, against a median runtime of approximately zero. Click on the Last 10 runs tab to see the details of each of the previous job executions.
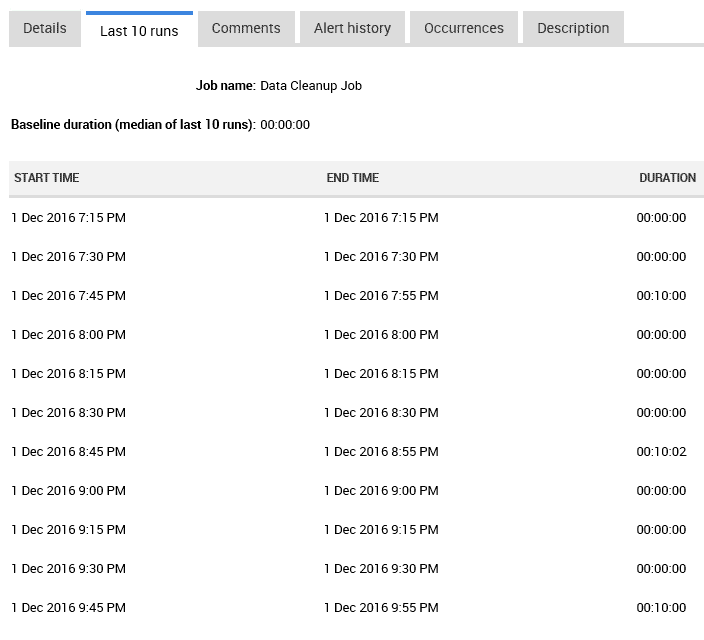
Figure 9
Most of the time the job runs instantly, but in some cases it takes 10 minutes. For demo purposes, on my isolated test server, I simply configured the job to be delayed by 10 minutes every fourth time it runs.
DECLARE @currenttime TIME;
SET @currenttime = GETDATE();
IF DATEPART(mi,@currenttime) > 40
BEGIN
WAITFOR DELAY '00:10:00';
END
However, the most common cause of this sort of problem on a real production instance is that, at certain times, one job is blocked by another job, or by system processes, or by a long running query. This is where SQL Monitor’s Performance Data, showing resource use and activity of other processes, around the time a specific alert was raised, becomes highly valuable for troubleshooting.
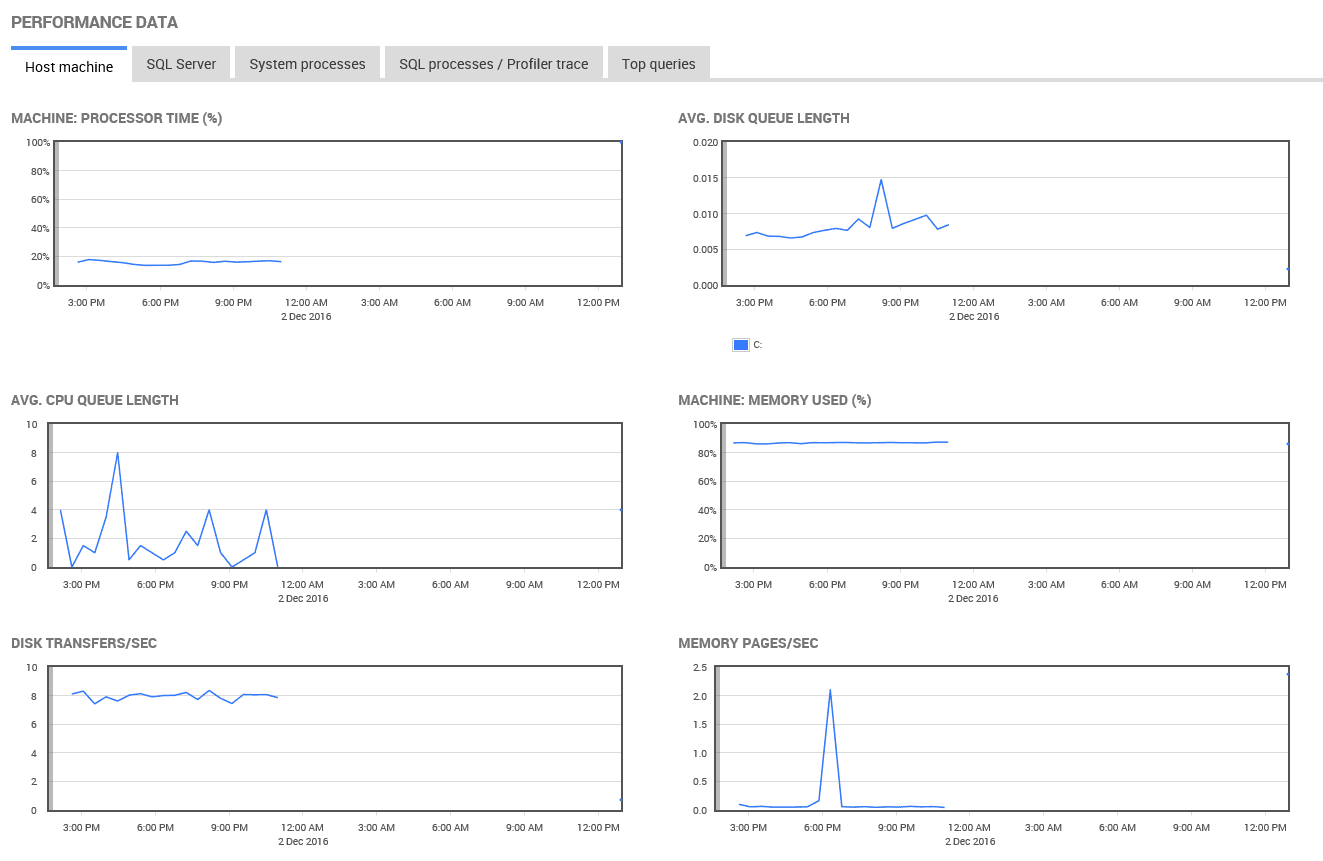
Figure 10
If the built-in Job Duration Unusual alert doesn’t provide quite what you need, you might consider creating a custom metric, such as Job Overran or Long Running Job.
Conclusion
Alerts are the database’s early warning signal of the possibility of failure. As DBAs, we must be aware of these signals immediately, and respond as quickly as possible. If SQL Agent is offline or paused, we need to know. If a job fails, or fails to start, or performs erratically, we need to know.
SQL Monitor provides customizable alerting systems, plus a wide range of performance metrics to help troubleshoot the underlying cause of an alert. All this combines to give you the information you need to keep your servers up and operating efficiently.
Tools in this post
Redgate Monitor
Real-time multi-platform performance monitoring, with alerts and diagnostics
You may also like
-

Business leaders webinar
In conversation with Troy Hunt: Database Security and Compliance
Join Troy Hunt, Information Security Author & Instructor at Pluralsight, Microsoft Regional Director & MVP, and Founder of Have I Been Pwned, in conversation with Steve Jones, Microsoft Data Platform MVP as they discuss the critical and complex role of monitoring in organizational data security and compliance.
-

Article
Tagging SQL Server Changes in SQL Monitor
How to use RAISERROR() in T-SQL to send annotations to SQL Monitor, so you can observe the direct impact of application tasks, or server changes, on the SQL Server metrics.
-
Article
Redgate launches Enterprise edition of Redgate Monitor, enhancing security and compliance and addressing the challenges of scale and complexity for large organizations
CAMBRIDGE, UK, April 17, 2024 – Redgate, the end-to-end Database DevOps provider, has launched an enterprise version of its popular database monitoring tool, providing a range of new features to address the challenges of scale and complexity faced by larger organizations. Redgate Monitor Enterprise offers the most comprehensive and advanced capabilities for monitoring large, complex
-
Article
Investigating problems with ad-hoc queries using SQL Monitor
Phil Factor demonstrates the performance problems that overuse of ad-hoc queries can cause and then how SQL Monitor can warn us when they are the cause of these problems on your SQL Servers, using built-in metrics such as SQL Compilations/sec metric and Batch Requests/sec.
-

Workshop
Monitor in the Morning - Sydney
Registrations are now closed for this event. Please email eventsAPAC@red-gate.com for more information, or check out our other workshop happening in Sydney, DevOps in a Day. The Monitor in the Morning workshop is the perfect opportunity to get hands-on with SQL Monitor, our solution to ensuring you stay ahead of the challenges that your servers





