





The Uses of Dependency Information in Database Development
Whether you are using Flyway, or a more state-based approach, it is easy to become exasperated with the task of running scripts that create or alter databases. In particular, the database's 'safety net' errors, triggered to prevent you breaking references between objects, are a common source of frustration. These errors will stop the build script and, unless you run the entire script within a transaction, you will be faced with a mopping-up task to roll back any changes. One of the virtues of Flyway is that it will run each script in a transaction, if the RDBMS you use allows it, and force a rollback on any error. This leaves the result at the previous version.
I'll show how to use database dependency information (sys.sql_expression_dependencies system catalog view) to avoid errors during database build, database tear-down or object-level builds, and to avoid accidentally breaking references during Flyway migrations, leading to 'invalid object' errors.
Avoiding execution errors in Data-definition Language (DDL) scripts
When you're building a database, or making changes to it, you've got to do things in the right order. For example, whenever SQL Server executes a CREATE or ALTER statement for a table, it checks all references that it makes via constraints to any other objects. It will raise an "invalid object" error on the referencing object if the referenced object doesn't yet exist.
This most often happens if the relationship between tables is enforced by a foreign key constraint. Even though you know that you're about to define that missing table that is referred to in a constraint, the database doesn't, so it gives an error. Databases, annoyingly, deal with objective reality rather than 'your truth'. Things must be done in the correct sequence: You can't, for example, do much else in a database until you have your schemas created.
When working out the correct place in a build for tables to be created, isn't just foreign key constraints that can trip you up. You might have, in SQL Server, a computed column or check constraint that uses a function. If that function isn't yet created, your build is toast. The same goes for user-defined types.
You'll face a similar problem in the process of dropping database objects: you can't drop an object if there are other objects still referring to it. I use the word 'objects' because it isn't just a matter of creating or dropping each type of object in the right order, so you do 'user types' first, then tables, then views and so on. It will often work out, but not always. Some database systems, such as SQL Server, will allow tables to have constraints that contain schema-bound user functions. That means that the user function can't be deleted until the table is deleted.
All of us who develop relational database will have experienced the difficulties of getting the order of making changes right. Those of us who are old enough to have created build scripts without handy tools will know that you only add a table when all the tables that it references via foreign keys are already created. As a more general rule, don't create an object until you've created the objects to which it refers.
Many RDBMSs allow you to break this rule, but it is still a good way of working that makes it easier to read a script. Otherwise, the experience of reading a script becomes like watching an irritating film that gets into the action without giving the audience the slightest clue as to who the various characters are, and how they relate.
Another way of breaking the rule in build scripts is to create all the tables first and then subsequently alter them to add the foreign key constraints. That works fine but if you are used to 'reading' table creation scripts, it is confusing to have to look outside of the CREATE TABLE statement to find all the ALTER statements that complete the 'story' about the table. To write code that is easy to maintain, all keys and constraints should be contained within the table definition.
Don't even think about leaving out constraints because they cause hassle. Foreign key constraints are essential for databases. Although they complicate CREATE and DROP DDL code, they 'shift-left' the errors into development where they are, perhaps irritating, but harmless. Above all else they are our best defense against bad data, but they also help performance by informing the query optimizer and they cause the supporting indexes to be created.
Detecting broken 'soft references' (a.k.a Avoiding 'invalid object' errors)
We must clarify what is meant by 'hard' and ‘soft' dependencies. Hard dependencies occur in tables and are defined explicitly by a foreign key constraint. Soft dependencies happen when you refer, within an object, to another object. You'll get an immediate error from a breaking a hard dependency, or hard reference, because it is enforced by a constraint. However, broken soft references can sneak into non-schema-bound objects, such views, table-valued functions, triggers or stored procedures, without you noticing.
Let's say you've created a module (e.g., a view, procedure or function) that references a table, and then someone removes or renames an object, such as a column, that the module references. Depending on your RDBMS, you may not hit the "invalid object" errors until the module is next used.
Some RMBMSs have bespoke ways of checking for broken soft references, in SQL Server's case by using the sp_RefreshSQModule system stored procedure, as I explain in Checking for Missing Module References in a SQL Server Database Using Flyway. PostgreSQL has metadata that will do the same thing (see here)
Some also allow you to protect these 'soft references' by using schema binding for a routine. If you have a SQL Server routine that relies on the existence of, or attributes of, a column in a table, you can use WITH SCHEMDABINDING to ensure that the referenced table can't be removed, or altered in a way that would break these references. If you attempt to do so, you'll get a 'binding' error. Schema binding will protect all objects that use the schema-bound routine. Where you can refer to a schema-bound user-defined function in a computed column of a table (PostgreSQL's generated columns don't allow this), that function must be deleted after the table.
If you accidentally prevent a SQL expression from working in, say, a view, the RDBMS will know about it, but is assuming that you'll put things right before the view is next used. If not, then the view will error out. If you are executing SQL directly from an application, then you're at a huge disadvantage because you can't be certain that the object you've changed or deleted isn't being occasionally used in SQL DML from the application. It is much better for an application to use just an interface to the database, using views, procedures, and functions, so that you know for certain the objects that can be accessed).
We can, in SQL Server, detect these missing 'soft dependencies' using the sys.sql_expression_dependencies system catalog view (we can do the equivalent in other RDBMSs). We can illustrate what can go wrong and show how to detect these 'invalid objects' when we create them. We'll create a table and a function that references it, and then do some unkind things to see what happens.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
/* create a test table with just a couple of columns */
CREATE TABLE dbo.DeleteThisTestTable (column_1 INT NOT NULL, column_2 CHAR(5));
GO
/* create a test function with a SQL query that acces the table */
CREATE FUNCTION [dbo].[DeleteThisTestFunction] (@MyFirstParam INT, @MySecondParam CHAR(5))
RETURNS TABLE
AS
RETURN
(SELECT column_1, column_2
FROM dbo.DeleteThisTestTable
WHERE
column_1 = @MyFirstParam AND column_2 > @MySecondParam);
GO
PRINT '---- both objects created. DeleteThisTestFunction is dependent on DeleteThisTestTable';
PRINT '---- We execute the function';
SELECT * FROM dbo.DeleteThisTestFunction (2, 'test');
PRINT '---- Hmm. That works. We now test to make sure there are no broken dependencies';
/* no worries with this so far */
SELECT Object_Name (referencing_id) AS No_Object_In_Trouble,
referenced_entity_name AS No_Missing_Object
FROM sys.sql_expression_dependencies
WHERE
referenced_id IS NULL
AND referenced_database_name IS NULL
AND referenced_entity_name NOT IN ('inserted', 'value', 'deleted'); -- temp results used in triggers etc
GO
PRINT '---- We now drop the table so that the function will produce an error';
DROP TABLE dbo.DeleteThisTestTable; -- ooh! no error
GO
PRINT '---- Has SQL Server found the broken dependency?';
SELECT Object_Name (referencing_id) AS Object_In_Trouble,
referenced_entity_name AS Missing_Object
FROM sys.sql_expression_dependencies
WHERE
referenced_id IS NULL
AND referenced_database_name IS NULL
AND referenced_entity_name NOT IN ('inserted', 'value', 'deleted');
GO
PRINT '---- We re-execute the function. This should produce a binding error';
GO
SELECT column_1 AS That_Went_Badly FROM dbo.DeleteThisTestFunction (2, 'test');
GO
PRINT '---- Yup. Error. We now drop the functiopn';
DROP FUNCTION dbo.DeleteThisTestFunction;
GO
PRINT '---- The broken ''soft'' dependency has disappeared.';
SELECT Object_Name (referencing_id) AS No_Object_In_Trouble,
referenced_entity_name AS No_Missing_Object
FROM sys.sql_expression_dependencies
WHERE
referenced_id IS NULL
AND referenced_database_name IS NULL
AND referenced_entity_name NOT IN ('inserted', 'value', 'deleted');
GO
PRINT 'Now we create the same function but with schema binding'
/* create a schema-bound test function with a SQL query that acceses the table */
GO
CREATE TABLE dbo.DeleteThisTestTable (column_1 INT NOT NULL, column_2 CHAR(5));
GO
CREATE FUNCTION [dbo].[DeleteThisTestFunction] (@MyFirstParam INT, @MySecondParam CHAR(5))
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(SELECT column_1, column_2
FROM dbo.DeleteThisTestTable
WHERE
column_1 = @MyFirstParam AND column_2 > @MySecondParam);
GO
DROP TABLE dbo.DeleteThisTestTable; -- This time we get an error!
PRINT 'Msg 3729, Level 16, State 1, Line 72'
PRINT 'Cannot DROP TABLE ''dbo.DeleteThisTestTable'' because it is being referenced by object ''DeleteThisTestFunction''.'
/*Clean up*/
DROP FUNCTION dbo.DeleteThisTestFunction;
go
DROP FUNCTION dbo.DeleteThisTestTable;
GO
|
This gives the following results
---- both objects created. DeleteThisTestFunction is dependent on DeleteThisTestTable ---- We execute the function (0 rows affected) ---- Hmm. That works. We now test to make sure there are no broken dependencies (0 rows affected) ---- We now drop the table so that the function will produce an error ---- Has SQL Server found the broken dependency? (1 row affected) ---- We re-execute the function. This should produce a binding error Msg 208, Level 16, State 1, Procedure DeleteThisTestFunction, Line 8 [Batch Start Line 41] Invalid object name 'dbo.DeleteThisTestTable'. Msg 4413, Level 16, State 1, Line 42 Could not use view or function 'dbo.DeleteThisTestFunction' because of binding errors. ---- Yup. Error. We now drop the function ---- The broken 'soft' dependency has disappeared. (0 rows affected) Now we create the same function but with schema binding Msg 3729, Level 16, State 1, Line 74 Cannot DROP TABLE 'dbo.DeleteThisTestTable' because it is being referenced by object 'DeleteThisTestFunction'. Msg 3729, Level 16, State 1, Line 72 Cannot DROP TABLE 'dbo.DeleteThisTestTable' because it is being referenced by object 'DeleteThisTestFunction'. Msg 3705, Level 16, State 1, Line 79 Cannot use DROP FUNCTION with 'dbo.DeleteThisTestTable' because 'dbo.DeleteThisTestTable' is a table. Use DROP TABLE. Completion time: 2022-08-03T15:11:14.7396017+01:00(0 rows affected) As you'll see from the result, the RDBMS knows when there is an unsatisfied reference but isn't going to rear up on its hind legs unless you attempt to use it (delayed compilation). You'll also see the effects of adding schema binding. It means that the table cannot be deleted while the function is referring to it. If one of our Flyway migrations scripts accidentally breaks a soft reference made by a non-schema-bound object then, even though SQL Server knows about it, we won't find out about it until a user runs the broken function. To avoid this, it's best to run a check for broken soft references such as the one for SQL Server described here, as part of the migration, and roll it back if any are detected.
The tear-down
Take, as an example, a problem where you need to tear down a database that you've used for a test. Real-life examples are often more complicated because you may need to allow certain schemas or objects such as tables to be retained. Again, we'll use SQL Server, because it is easy to find soft dependencies, either schema-bound or non-schema-bound, using sys.sql_expression_dependencies. In my DropAllObjects procedure, below, the first objects to be deleted are those to which no other object refers. Having done so, we find that there are now more objects to which no other object refers (because we just deleted the referring objects). We just repeat until all the objects are deleted. This stored procedure will even delete itself, which is very thorough. To try it out, restore a copy of AdventureWorks, or whatever sample database you have, and double-check that you are logged into the right database and not accidentally logged into the company's payroll database as admin.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
/***
Summary: >
This is a batch that deletes an entire database. Before using it please make sure
that everything is backed up. It assumes that the login that uses the procedure has
the rights to drop database objects.
Author: Phil Factor
Date: Friday, 17 June 2022
Revision: Friday, 5th August 2022
**/
DECLARE @AllTheDeletes NVARCHAR(MAX) = N'';
DECLARE @ThereAreMoreToDo INT = 20; --we limit the number of loops in case of
DECLARE @NumberOfDeletions INT;
--start by deleting the object types that just have dependencies and EPs on the database.
SELECT @AllTheDeletes=N''
SELECT @AllTheDeletes=@AllTheDeletes + N'print ''dropping ' + Type + N' ' + fullname + N''';
DROP ' + Type + N' ' + fullname + ' ' + scope + N';'
FROM
( SELECT 'TRIGGER' AS "Type", QuoteName (name) AS fullname, 'ON DATABASE' AS scope
FROM sys.triggers tr WHERE parent_id=0)f
SELECT @AllTheDeletes=@AllTheDeletes +'EXEC sp_dropextendedproperty @name = N'''+name+''';'
FROM sys.extended_properties WHERE major_id=0 AND minor_id=0;
SELECT @AllTheDeletes=@AllTheDeletes + 'EXEC sp_dropextendedproperty N'''+ep.name+''', ''Filegroup'', '''+data_spaces.name+''';
' FROM sys.data_spaces
INNER JOIN sys.extended_properties ep
ON ep.major_id = data_spaces.data_space_id
WHERE class_desc = 'dataspace'
EXEC sp_executesql @AllTheDeletes; --- AND do them all
--awkward SQL just in case more crop up.
WHILE (@ThereAreMoreToDo > 0) -- we loop through, deleting objects
BEGIN
PRINT @ThereAreMoreToDo;
SELECT @AllTheDeletes = N'';
SELECT @AllTheDeletes =
@AllTheDeletes + N'print ''dropping ' + type + N' '
+ QuoteName ("SCHEMA") + N'.' + QuoteName ("name") + N''';
DROP ' + type + N' ' + QuoteName ("SCHEMA") + N'.'
+ QuoteName ("name") + N';'
--this generates the DROP statement for the object that is then executed as a string
FROM -- we get a table source consisting of all the tables, views and routines.
(SELECT CASE WHEN TABLE_TYPE = 'BASE TABLE' THEN 'TABLE ' ELSE
TABLE_TYPE END AS "type",
TABLE_SCHEMA AS "schema", TABLE_NAME AS "name"
FROM INFORMATION_SCHEMA.TABLES
UNION ALL
SELECT ROUTINE_TYPE, ROUTINE_SCHEMA, ROUTINE_NAME
FROM INFORMATION_SCHEMA.ROUTINES) entities("type", "SCHEMA", "name")
LEFT OUTER JOIN
(SELECT DISTINCT referenced_schema_name + '.'
+ referenced_entity_name AS "entity_name"
FROM
sys.sql_expression_dependencies
INNER JOIN sys.objects
ON referencing_id = objects.object_id
WHERE
referenced_schema_name IS NOT NULL
AND referenced_minor_id = 0
AND referenced_class = 1 --assume types done last.
AND referencing_id <> referenced_id
AND is_schema_bound_reference = 1
--need to filter out self-references!
AND
(Coalesce (Object_Name (parent_object_id), objects.name) <> referenced_entity_name
OR Coalesce (
Object_Schema_Name (parent_object_id),
Object_Name (object_id)) <> referenced_schema_name)) referenced("entity_name")
ON referenced."entity_name" = "SCHEMA" + '.' + "name"
LEFT OUTER JOIN
(SELECT DISTINCT Object_Schema_Name (referenced_object_id) + '.'
+ Object_Name (referenced_object_id) AS referenced_name
FROM sys.foreign_keys) fks(referenced_name)
ON fks.referenced_name = "SCHEMA" + '.' + "name"
WHERE
"entity_name" IS NULL AND fks.referenced_name IS NULL;
SELECT @NumberOfDeletions = @@RowCount;
SELECT @ThereAreMoreToDo =
CASE WHEN @NumberOfDeletions > 0 THEN @ThereAreMoreToDo - 1 ELSE 0 END;
IF (@ThereAreMoreToDo > 0)
BEGIN
IF (@ThereAreMoreToDo = 1)
BEGIN
RAISERROR (
'Couldn''t delete the database because of mutual references',
16,
1);
SELECT @ThereAreMoreToDo = 0;
END;
EXEC sp_executesql @AllTheDeletes;
END;
END;
SELECT @AllTheDeletes = N'';
SELECT @AllTheDeletes =
@AllTheDeletes + N'print ''dropping ' + Type + N' ' + fullname
+ N''';
DROP ' + Type + N' ' + fullname + ' ' + scope + N';'
--this generates the DROP statement for the object that is then executed as a string
FROM
(SELECT 'XML SCHEMA COLLECTION' AS "Type",
QuoteName (Schema_Name (xc.schema_id)) + '.'
+ QuoteName (xc.name) AS fullname,'' AS scope
FROM
sys.xml_schema_collections xc
INNER JOIN sys.schemas
ON schemas.schema_id = xc.schema_id
WHERE schemas.name <> 'sys'
UNION ALL
SELECT 'TYPE' AS "Type",
QuoteName (Schema_Name (schema_id)) + '.' + QuoteName (name) AS fullname,'' AS scope
FROM sys.types UT
WHERE
UT.user_type_id <> UT.system_type_id
AND Schema_Name (UT.schema_id) <> 'sys'
UNION ALL
SELECT 'SCHEMA' AS "Type", QuoteName (name) AS fullname,'' AS scope
FROM sys.schemas sch
WHERE
sch.schema_id > 4 AND sch.name NOT LIKE 'DB%') f;
EXEC sp_executesql @AllTheDeletes;
|
Flyway does its best to perform the same trick with its Clean command and it works well with most of my sample databases. However, as I write this, it fails with AdventureWorks, SQL Server's sample database, due to SQL Server's useful schema-binding feature.
Building from object-level scripts
One of the most important uses for dependency information about a database is for building databases from object-level scripts. For just building a database, it is easier to generate a single-file build script, but sometimes it is more convenient to do it from object-level source.
The migration-based approach to building databases, used by Flyway, has many advantages, but you lose the useful feature of committing object-level source to source control, which means that you can no longer track changes to individual objects over time. This is mainly useful for table, which will often get altered, in several places, in a sequence of migrations. Where, for example, a table has a change of index, this will then be picked up as a change in source control.
Redgate's UI that combines Flyway and schema comparison functionality, called Flyway Desktop, also maintains the object-level source as well as migration scripts. Flyway command line allows you to get over this by supporting callbacks that allow you to save an object-level source for the entire database, after every migration run. I've included a $CreateScriptFoldersIfNecessary task in my Flyway Teamwork framework that generates the object-level scripts (see Creating Database Build Artifacts when Running Flyway Migrations).
When you write out an object-level script using the tools provided to go with the RDBMS, it is usual with SQL Server to provide a manifest. You don't need this if you have Schema Compare for Oracle or SQL Compare for SQL Server because they can work with this source directly, to build a database - but for other RDBMSs, you would need to do it manually. There are plenty of uses for a having a manifest generated, every time you migrate a database to a new version. I'll explore these in a later article.
A manifest is just a list of all the files that must be executed to build the database from the object-level scripts. Normally, the manifest is generated via SMO, the programmatic interface into SSMS. However, it is a lot quicker and easier to do this in SQL. Unless you have a Redgate Compare tool, you are forced to prepare your manifest from the live database. My Flyway Teamwork has a script task ($SaveDatabaseModelIfNecessary) that generates a table manifest for you from the JSON model of the database.
Unlike a schema compare tool, this type of manifest cannot deal with a build if you add object script files or make changes that change the dependencies. Here is the code to generate a manifest to go with your object-level source. It relies on you creating the schemas and types first, as it is only concerned with order of building schema-based objects.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
CREATE FUNCTION dbo.CreateManifest
/**
Summary: >
This is a Table-valued function that produces a manifest(list) of all the objects
in the current database in the order of build so that there are no errors due to missing
references.
Author: Phil Factor
Date: Tuesday, 21 June 2022
Examples:
- Select * from dbo.CreateManifest()
- Select '\'+case theType
when 'procedure' then 'Stored Procedures'
else upper(substring(TheType,1,1))+lower(rtrim(substring(theType,2,80)))+'s' end
+'\' +TheSchema+'.'+TheName+'.sql' from dbo.CreateManifest()
Returns: >
nothing
**/
()
RETURNS @ManifestList TABLE (TheOrder INT IDENTITY, --the order in which you build. Actually the objects in
--the same 'layer' can be built in any order.
TheLayer INT NOT NULL DEFAULT 0, --the group of objects that can be built
TheSchema sysname NOT NULL,
TheType sysname NOT NULL,
TheName sysname NOT NULL,
TheObject_ID INT NOT NULL UNIQUE)
AS
BEGIN
DECLARE @objectList TABLE (TheType sysname NOT NULL,
TheSchema sysname NOT NULL,
TheName sysname NOT NULL,
TheObject_ID INT NOT NULL UNIQUE)
-- we gather all the important objects (views, tables and routines into a table
INSERT INTO @objectList (TheType,
TheSchema,
TheName,
TheObject_ID)
SELECT CASE WHEN TABLE_TYPE = 'BASE TABLE' THEN 'TABLE ' ELSE
TABLE_TYPE END AS TheType,
TABLE_SCHEMA AS TheSchema, TABLE_NAME AS TheName,
Object_Id (
QuoteName (TABLE_SCHEMA) + '.' + QuoteName (TABLE_NAME)) AS "TheObjectID"
FROM INFORMATION_SCHEMA.TABLES
UNION ALL
SELECT ROUTINE_TYPE, ROUTINE_SCHEMA, ROUTINE_NAME,
Object_Id (
QuoteName (ROUTINE_SCHEMA) + '.' + QuoteName (ROUTINE_NAME))
FROM INFORMATION_SCHEMA.ROUTINES;
-- we now make a table of all the relationships
DECLARE @Relationships TABLE (Referencing_id INT NOT NULL,
Referenced_id INT NOT NULL);
INSERT INTO @Relationships (Referencing_id,
Referenced_id)
SELECT DISTINCT referencing_id, Referenced_id
FROM -- we get all the hard relationships indicated by FKs
(SELECT parent_object_id AS referencing_id,
referenced_object_id AS Referenced_id
FROM sys.foreign_keys
UNION ALL --and all the 'soft' relationships
SELECT SED.referencing_id, SED.referenced_id
FROM sys.sql_expression_dependencies SED
INNER JOIN sys.objects
ON SED.referencing_id = objects.object_id
WHERE SED.referenced_schema_name IS NOT NULL
AND SED.referenced_minor_id = 0
AND SED.referenced_id IS NOT NULL
AND SED.referenced_class = 1 --assume types done first.
AND SED.referencing_id <> SED.referenced_id
--AND SED.is_schema_bound_reference = 1
) f;
--at any point, we need to know what objects aren't in the manifest
DECLARE @Unbuilt TABLE (TheSchema sysname NOT NULL,
TheName sysname NOT NULL,
TheType sysname NOT NULL,
TheObject_ID INT NOT NULL)
DECLARE @TheLayer INT = 1; --the current layer determining the order of build
WHILE (@TheLayer < 20)
BEGIN
--find out all objects not yet in the manifest
DELETE FROM @Unbuilt; --we refresh the unbuilt list
INSERT INTO @Unbuilt (TheObject_ID,
TheSchema,
TheName,
TheType)
SELECT AllObjects.TheObject_ID, AllObjects.TheSchema,
AllObjects.TheName, AllObjects.TheType
FROM @objectList AllObjects
LEFT OUTER JOIN @ManifestList RemovedObjects
ON AllObjects.TheObject_ID = RemovedObjects.TheObject_ID
WHERE RemovedObjects.TheObject_ID IS NULL;
INSERT INTO @ManifestList (TheSchema,
TheType,
TheName,
TheObject_ID,
TheLayer)
SELECT DISTINCT unbuilt.TheSchema, unbuilt.TheType,
unbuilt.TheName, unbuilt.TheObject_ID, @TheLayer
FROM @Unbuilt unbuilt
LEFT OUTER JOIN (SELECT DISTINCT Referencing_id
FROM @Relationships Relationships
LEFT OUTER JOIN @ManifestList manifestList
ON Relationships.Referenced_id = manifestList.TheObject_ID
WHERE manifestList.TheObject_ID IS NULL) f
ON f.Referencing_id = TheObject_ID
WHERE f.Referencing_id IS NULL;
SELECT @TheLayer = @TheLayer + 1;
END;
RETURN
END
GO
|
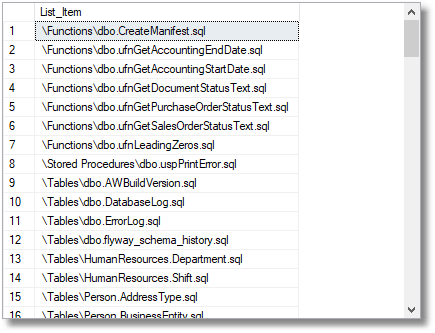
When calling this in AdventureWorks, using the following expression …
|
1
2
3
4
|
Select '\'+case theType
when 'procedure' then 'Stored Procedures'
else upper(substring(TheType,1,1))+lower(rtrim(substring(theType,2,80)))+'s' end
+'\' +TheSchema+'.'+TheName+'.sql' as List_Item from dbo.CreateManifest()
|
…it will give …
Summary
The way that relational databases police dependencies and references can strike fear into the heart of a database novice. It is the same terror with which a child might face a life-saving inoculation. To the experienced database developer, the terror of bad data and broken references or dependencies is far, far greater, and we therefore apply constraints to guard against even the most unlikely of events. If you neglect this, fate has a way of illustrating your carelessness with a public and humiliating disaster.
The disentangling of the complex interrelationships between database objects is therefore a soothing activity, like mending your safety net. A slight inconvenience during a build, deletion or alteration, involving the rollback of a migration, is a small price to pay for a powerful defense against bad data or broken processes.
Manifests, which are ordered lists of database objects, originally were just used for building databases from object-level script files. However, they have a surprising number of uses. Flyway Teamwork can generate table manifests, which just include tables, for all the RDBMSs that it supports. These are valuable for any tasks that involve all or most of your tables, such as importing data, exporting data, clearing out data, finding out how many rows there are in each table and so on. From this introduction, we'll explain all this in more detail when we demonstrate how to change your datasets.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Comparing and Syncing Data using SQL Data Compare Command Line
Robert Sheldon demonstrates how to start automating data comparisons between two databases, from the Windows command line or PowerShell. With a single command, you can easily compare and sync data such as test data sets, or static data used for reference or lookup purposes.

Article
New Flyway Migration Report
As of version 9.17 of Flyway when running flyway migrate or flyway info a new report.html report will be written to your current folder. The migration report is designed to provide confidence that a Flyway deployment has run as expected, and in the case that it hasn’t, provides the necessary detail to help understand and troubleshoot the issue. … Read more in the full post on the Flyway documentation site

Article
Using SQL Compare with Row Level Security
As you test your row-level security in various environments, you can use SQL Compare to script out and deploy those changes to other databases.

Article
Reviewing SQL Migration Files Before a Flyway Migration
Your finger is hovering over the 'enter' key to set off the Flyway "migrate" command, but you hesitate. There is a large stack of migration files for this project: don't all these files need to be checked first? Yes, they do, but how? This article demonstrates how, once armed with the file path locations of all the scripts, you can use PowerShell to search them for various purposes such to review them for potentially disruptive changes, or run code quality checks, or to verify documentation standards.
Article
SQL Change Automation Scripting: Getting Data into a Target Database
Your strategy for loading a freshly built database with data will depend on how much you need. If just a few rows, then single-row INSERT statements will be fine, but for more than that you'll need to build insert the rows using native-format BCP. Fortunately, SQL Change Automation (SCA) can be used with either strategy, as Phil Factor demonstrates.
Article
Running DOS Scripts as Callbacks with Flyway
How to perform a range of useful database tasks automatically during Flyway migrations, using a DOS callback script. We provide a demo script that will collect all the necessary information from Flyway, run the task and then save any file with the appropriate name. You can use it to automate tasks such creating backups or DACPACs or generating a build script, each time Flyway creates a new database version.
Loading comments...