A Programmer’s Guide to Flyway Configuration
Phil Factor offers a programmer's guide to Flyway's configuration settings, explaining the different categories of parameters, the role of each of parameter within each category, and how to exploit Flyway's multi-level configuration file system.
As well as reading any relevant environment variables and parameter values, Flyway can collect all the details it needs to run any database migration from a configuration files. These configuration parameters provide it with, for example, the location of the migrations files, connection details for the target database, and the schemas that Flyway needs to manage and update. They also determine the way that Flyway does its tasks, such as how it executes a migration run, and how it responds to and reports errors.
My general approach to working with Flyway is to use PowerShell scripting, supplying the values for the required configuration settings directly from PowerShell parameters. When using callbacks, I read the runtime values of environment variables passed to the script by Flyway. However, there are times when it’s best to specify some of the required settings in one or more of Flyway’s configuration files. For example, if you wish to use Flyway interactively, with minimal typing, or if you need to maintain several different versions of the same database, to support each of the various branches of development. For me, the use of Flyway’s configuration files is limited only by my extreme reluctance to ever place credentials unencrypted in a file or environment variable.
Using Flyway’s multi-level configuration system
Flyway works most comfortably with a series of flyway.conf files, each of which is a text file with series of lines providing key/value pairs for each parameter.
By default, Flyway reads three configuration files in succession. Each file is read and any keys that aren’t commented-out are parsed, and their values assigned. These files are in three locations: Flyway’s installation directory, in the user directory, and in the current working directory, which is normally the project that you’re working on.
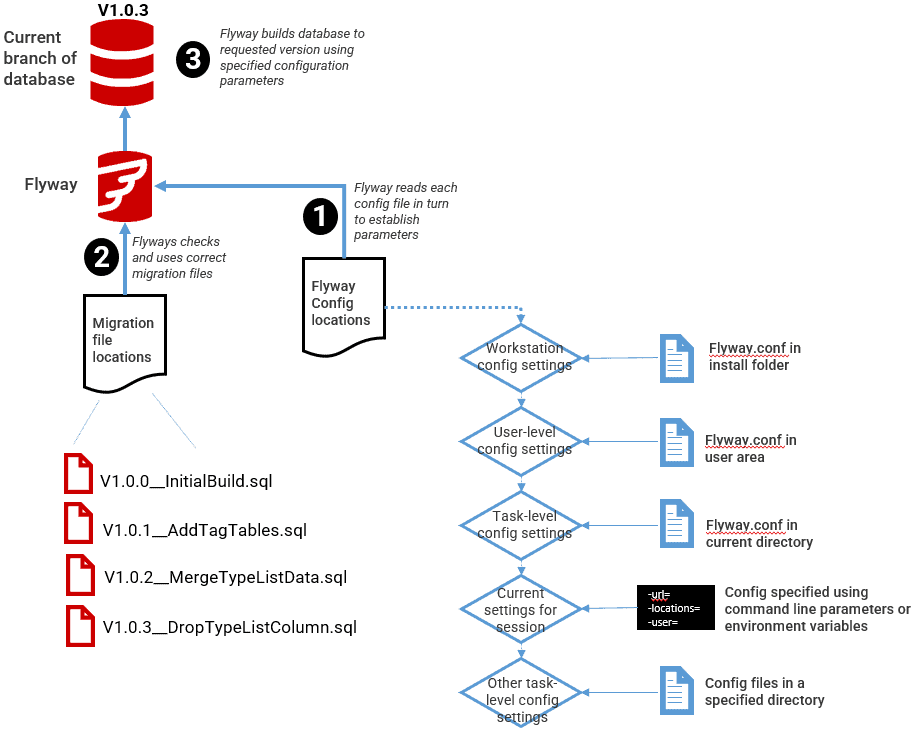
The reason that there are three different files is that you might need to set the way that the tool behaves on the workstation, set the information about the user, and set the information about the project that you are working on.
If you need further Flyway configuration files to provide new information or to overwrite the values you’ve provided for Flyway, you can provide these in a list as a value to the –configFiles parameter when you execute Flyway.
By making the development branch you are working on the current working directory and having the appropriate information in the three levels of flyway.conf file, including one in the branch directory, you can then move easily between branches without having to make any other changes. If you are doing team-based development with Flyway, this may have to be supplemented with your specific credentials for the development database you are working on.
Navigating the Flyway configuration parameters
The range of configuration settings, almost all of which have corresponding parameters, is large, and can be a bit bewildering at first. My aim with the remainder of this article is therefore to provide a “programmer’s guide” to the various configuration settings, making it easier to understand the different categories of config parameters and the role of each of them within that category.
I’ll cover the the configuration options in the following categories:
- Connection Details
- Schemas and flyway_schema_history
- Configuring migration files
- Controlling Flyway behavior
- Executing Migrations
Establishing the connection information
Flyway uses JDBC drivers to connect to databases. These are loaded dynamically according to the database connection strings that you specify. Certain JDBC drivers are packaged with Flyway and are well tested with it on every release. However, you can use alternative drivers for your RDBMS by installing them in Flyway’s installation folder, and we can specify these via flyway.conf settings.
A database connection will involve a number of settings such as ANSI-compatibility, and error-handling which are either added to the URL or set in SQL (see flyway.initSql). The user credentials need to be in the user area to provide reasonable security against access by other users, whereas the database details need to be in the flyway.conf within the project. If you have a single login to all the databases used by all projects, then it is all easy. With Flyway Teams you can use Secrets Management; otherwise the credentials will need to be provided security either by parameters or environment variables (the $FetchAnyRequiredPasswords task in my PowerShell library encrypts passwords and stores them in the user area), or by referencing a flyway.conf file for that specific server/database in the user area.
Specifying the database connection
| flyway.url | The JDBC URL (connection string) used to connect to the database, usually including the host, port and database, but this depends on the RDBMS. SQLite just requires a filepath, for example whereas a hosted cloud service may require several additional key-value pairs. No user credentials should be in this string. There are specifications for each type of connection URL in the installation flyway.conf.
Only certain JDBC drivers are packaged with Flyway. If the driver you need isn’t there, then you need to ensure it is available on the classpath (see Adding to the classpath) and provide the path to the driver in flyway.driver before you can specify it here. |
| flyway.driver | If you don’t specify a value for flyway.driver, Flyway will autodetect the correct JDBC driver provided by Flyway to connect to the host based on the value you provide for flyway.url.
If you need to use a different driver to the default one provided for a connection, you can specify in this parameter the fully qualified classname (path) of the JDBC driver, which must match the database type that is specified in the URL. |
| flyway.user | Unless you are using a connection that avoids password credentials such as Windows authentication, or you have provided the user parameter in the URL, or the database doesn’t need a password (SQLite), you need to supply the User ID for the database connection. This is the user_id assigned by the database and will not necessarily be the same as the workstation User ID. If the user_id is not specified, but is required, Flyway will prompt you to enter it. |
| flyway.password | The password to use to connect to the database. Flyway will prompt you to enter it if it has not yet been specified within the URL, and if the JDBC connection is not using a password-less method of authentication. It is far better if passwords are provided by more secure means, such as aws secrets. |
| flyway.connectRetries | Normally there is no need for Flyway to retry a failed database connection, but if it should, then you specify the number of retries it should make. This should not be too generous, because Flyway will wait 1 second after the first failed attempt before attempting to connect again. The wait time will then double for each subsequent retry up to a value of two minutes. |
| flyway.connectRetriesInterval | If you specify a value for connection retries in flyway.connectRetries, Flyway will oblige; but it may not have the effect you want because the wait-time interval between retries doubles for each retry up to 120 seconds. You can however specify the maximum time in seconds between retries when attempting to connect to the database |
| flyway.initSql | Different database systems may require different initialization settings for the connection. This is to set values for the connection such as the language. These connection settings can affect the way that SQL is parsed or executed. It may change the way errors are handled. If there are general settings that must be made, then you can provide general settings as SQL statements that Flyway will run to initialize a new database connection immediately after opening it. This removes clutter from the start of migration files and makes them more portable between RDBMSs |
| flyway.jdbcProperties.myProperty | JDBC properties to pass to the JDBC driver when establishing a connection. (Flyway Teams only) |
| flyway.oracle.sqlplus | Set to ‘true’ to activate Flyway’s support for Oracle SQL*Plus commands (Flyway Teams only) |
| flyway.oracle.sqlplusWarn | Set to ‘true’ to make Flyway issue a warning instead of an error whenever it encounters an Oracle SQL*Plus statement it doesn’t yet support. (Flyway Teams only) |
| flyway.kerberosConfigFile | When connecting to a Kerberos service to authenticate, the path to the Kerberos config file. (Flyway Teams only) |
Schemas, default schemas and the flyway_schema_history table
Flyway always puts the flyway_schema_history table in the default schema. On start-up, Flyway sees whether you have specified what schema should be the default schema, which you do using the flyway.defaultSchema config setting. If you haven’t specified a default schema, Flyway creates its schema history table in the first schema in the list you provide in flyway.schemas. If you haven’t specified these, Flyway uses the default schema for the database connection, if the database system supports this. Schema names are case-sensitive. I’ve explained in detail how Flyway uses the schema history table in Exploring the Flyway Schema History Table.
If Flyway is asked to clean a database of all its contents, then Flyway creates and fills a fresh flyway_schema_history table. If Flyway creates a schema, it will then drop the schema when performing the ‘clean’ action.
| flyway.schemas | This is a Comma-separated (no spaces) list of the schema or schemas that are managed by Flyway. These schema names are case-sensitive. If flyway.defaultSchema is not specified, then the first schema of the list acts as the default schema.
Once it knows the schema or schemas that it is managing, Flyway will automatically attempt to create all these schemas, unless they already exist. If you ask Flyway to clean a database, each schema will be cleaned in the order of this list. If the schema were created by Flyway, the schemas will be dropped along with their contents when cleaning. |
| flyway.defaultSchema | This is needed only if you don’t want Flyway to assume that the default schema is neither the schema of the database connection, or the first schema specified in the list provided by flyway.schemas. You can override both, by specifying the default schema explicitly. This is most often used to change the location of the flyway history table. |
| flyway.createSchemas | You can specify whether Flyway should attempt to create the schemas specified in the flyway.schemas property if they don’t already exist. It will do so unless you specify false to this configuration item. |
| flyway.table | If you want a different name for the schema history table than flyway_schema_history you can specify it here. By default (single-schema mode), the schema history table is placed in the default schema for the connection provided by the data source. |
| flyway.tablespace | The tablespace (the storage location where the actual data underlying database objects can be kept) where the schema history table used by Flyway should be created. If not specified, Flyway uses the default tablespace for the database connection. This setting is only relevant for databases that support tablespaces. Its value is simply ignored for all others. |
Specifying the migration files
Migration files can be in several different ‘locations’, which are just places, such as directories, where you can store files. You might need to do this if some of your migration files are cloud-based, or you may have a branching strategy that requires this. You might need to keep callback scripts or Java/PowerShell scripts separately. Flyway will work out the correct sequence wherever they are stored.
Specifying the locations
| Flyway.locations | This is a comma-separated list of locations to scan recursively for migrations. The location type is determined by a prefix that tells Flyway whether they are Java classpaths or file directories. By default, they are the former and can contain both SQL and Java-based migrations, but if you prefix your list of Locations with ‘filesystem:’ then each one will point to a directory on the filesystem and its subdirectories. These will contain SQL migration files, with the SQL filetype, and a filename that follows the Flyway naming conventions.
If these locations follow the naming convention s3:<bucket>(/optionalfolder/subfolder) then they point to a bucket in AWS S3 and are scanned recursively for SQL migration files obeying the Flyway naming conventions. Likewise, those starting with gcs: point to a bucket in Google Cloud Storage, may only contain SQL migrations, and are also scanned recursively. They are in the format gcs:<bucket>(/optionalfolder/subfolder). Wildcards can be used within the elements of the path string to reduce any possibility of duplication of location paths. (e.g. filesystem:migrations/*/oracle). You can specify all subdirectories via ‘**’, and do conventional wildcards via * and ? (* represents any number of characters, ? represents a single character). See Organizing your Migrations for the details. |
| flyway.jarDirs | Comma-separated list of directories containing JDBC drivers and Java-based migrations for the command-line version of Flyway. (default: <INSTALL-DIR>/jars) |
Specifying the naming conventions
Migrations have the following file name structure: prefixVERSIONseparatorDESCRIPTIONsuffix. You can, if necessary, change the prefix, separator and suffix for the migration files you use for a project. You may be moving gradually from an older build/migration system and so need compatibility with it.
| flyway.sqlMigrationPrefix | File name prefix for versioned SQL migrations (default: V), For example, V1_1__My_description.sql if the default naming is used. |
| flyway.undoSqlMigrationPrefix | The file name prefix for undo SQL migrations (default: U) that reverse the effects of the versioned migration with the same version. By default, these look like U1.1__My_description.sql. (Flyway Teams only) |
| flyway.repeatableSqlMigrationPrefix | This specifies the Filename prefix for repeatable SQL migrations (default: R) which would look like R__My_description.sql |
| flyway.sqlMigrationSeparator | File name separator for SQL migrations. The default is a double underscore (__) which would look like V1_1__My_description.sql |
| flyway.sqlMigrationSuffixes | This is a comma-separated list of file name suffixes for SQL migrations. (default: .sql). Using the defaults, this looks like V1_1__My_description.sql. This allows several different suffixes (like .sql, .pkg, .pkb) for easier compatibility with other tools that require specific file types for use. |
Controlling Flyway’s behavior
This concerns the way that Flyway logs events, the way that it handles exceptions or resolve migrations. It also deals with compatibility issues such as text encoding and the way that long SQL migrations are handled.
| flyway.failOnMissingLocations | You can tell Flyway to fail whatever action you’ve specified if any of the locations in the flyway.locations option doesn’t exist or can’t be accessed. This is generally a good idea even though the default is to just warn you |
| flyway.loggers | If you require more sophisticated logging than that used by Flyway (console logging) you can switch to a special-purpose logger. This can be useful if you need to maintain a large number of systems, running as services.
By default, Flyway auto-detects the logger that you wish to use (auto). However, you can specify the logger that you wish to use such as:
Alternatively, you can specify the fully qualified class name for any other logger. If you are specifying JSON output for Flyway, the console will not be available for output, so you only get the errors reported via JSON, but not the logging messages. If you are using Flyway within Java and have several instances of the Flyway object with different configurations, you must ensure they all have the same loggers configured. |
| flyway.resolvers | A comma-separated list of fully qualified class names of a custom MigrationResolver to use for resolving migrations. The resolver must be available on the classpath |
| flyway.skipDefaultResolvers | If set to ‘true’, then default built-in resolvers (jdbc, spring-jdbc and sql) are skipped and only custom resolvers as defined by flyway.resolvers are used. |
| flyway.stream | If you set this to ‘true’, then Flyway will stream SQL migrations when executing them. Streaming avoids having to load the entire migration in memory at once. Instead, each statement is loaded individually, which is particularly useful for very large SQL migrations composed of multiple MB or even GB of reference data because this dramatically reduces Flyway’s memory consumption (Flyway Teams only) |
| flyway.batch | By setting this to ‘true’, you can require Flyway to batch SQL statements when executing them. By default, it doesn’t. However, batching can speed up large migrations by saving up to 99 percent of network roundtrips by sending up to 100 statements at once over the network to the database, instead of sending each statement individually. This is particularly useful for very large SQL migrations by drastically decreasing the network overhead. This is supported for INSERT, UPDATE, DELETE, MERGE and UPSERT statements. All other statements are automatically executed without batching. (Flyway Teams only) |
| flyway.encoding | By default, Flyway reads UTF-8 files. You can specify a different encoding, but this will result in the checksums of the files to change. Flyway uses this checksum to detect a change in the file and, if it is a versioned file, will report an error rather than execute the migration. This will require a ‘flyway repair’. |
| flyway.detectEncoding | Flyway can try to automatically detect the text-encoding of SQL migration file if you set this value to ‘true’ (Flyway Teams only) |
Executing migrations
There are several configuration items that determine the way that migration files are executed. These determine the format of placeholders, the way that Flyway arranges and executes the migration run, and the way that Java-based callbacks are done.
Placeholders
Placeholders greatly extend the usefulness of Flyway. They work like macros, where you embed locations in text, into which you substitute values at runtime. Flyway provides some default placeholders, referenced in your SQL scripts using ${flyway:Placeholder}. These provide information such as the date when Flyway ran a script, the database name, username, and the location of the flyway schema history table.
In the Flyway.conf file, you can also define your own placeholders and configure the value for these placeholders using, for example, flyway.placeholders.superuser=Philip J Factor. You can then reference these user-defined placeholders in a SQL migration script or callback, using ${superuser}.
Similarly, your placeholder values will also be passed to script migrations (i.e. those written in a scripting language such as PowerShell or bash) and script callbacks, but in this case the values just get passed as environment variables and you have to use your own scripting methods to insert these variables into the code.
| flyway.placeholderReplacement | Generally, you will want placeholders to replace the value for the placeholder in text, but you can prevent that by setting this to ‘false’ |
| flyway.placeholderPrefix | Prefix of every placeholder. (default: ${ ) |
| flyway.placeholderSuffix | Suffix of every placeholder. (default: } ) |
| flyway.scriptPlaceholderPrefix | Prefix of every script placeholder. (default: FP__) |
| flyway.scriptPlaceholderSuffix | Suffix of every script placeholder. (default: __) |
Migrations
You can specify a specific version to which the database is migrated and ask Flyway to stop at the end of the chain if that version isn’t yet represented by a migration file. You can also run preliminary checks on a migration chain before you execute the chain or cherry-pick the files that get executed.
| Flyway.target='<version>’ | This will override Flyway’s default of migrating through to the latest version. The <version> specifies the target version up to which Flyway should consider migrations. Special values are:
|
|
| flyway.target='<version>?’ | This value must end with a ‘?’, and it instructs Flyway not to fail if the target version doesn’t exist but instead just take the migration up to that point. By default, Flyway will fail the migration run if it finds that the target version doesn’t exist. | |
| Flyway.cherryPick= | This defines a custom migration run that uses a comma-separated list of migrations that Flyway should use where necessary. Migrations are considered in the order they are provided in the list of migration files to cherryPick. However, when used in conjunction with undo, the migrations are undone in reverse to how they are specified to cherryPick. In other words, flyway undo -cherryPick=3,2,1 will undo migrations in the order 1,2,3.
Leave the list blank if you wish to use all discovered migrations where necessary for the migration. Values should be the version for versioned migrations (e.g. 1. 2.4, 6.5.3) or the description for repeatable migrations (e.g. Insert_Data, Create_Table) – (Flyway Teams only) |
|
| flyway.validateOnMigrate | Set this to false if you don’t want Flyway to call validate when running the migrate command. This stops Flyway checking whether a file has been changed. There may be occasional circumstances where you need to do this to fix a development problem. The reformatting of SQL, insertion of comments and documentation into a migration will cause validation to fail even when there is no change to the database. | |
| Flyway.cleanOnValidationError | Set this to ‘true’ if you want Flyway to automatically call the clean action when a validation error occurs. Basically, this allows you, in development, to alter a migration file that has already been applied. This will result in a complete rebuild of the database before the updated migration is applied. This should, obviously only be used in development when in a branch, where a change in a migration script doesn’t affect the parent branch. Because the database, and all its data, will be wiped clean automatically, the next migration run will provide the database with a live version that reflects the changes that you’ve made. Clean should, obviously, never be done on a production database. | |
| Flyway.cleanDisabled | Set to ‘true’ to disable Flyway’s clean command. This is especially useful for production environments, where running clean can be quite a career-limiting move. | |
| Flyway.baselineVersion | The baseline version is the version with which to tag an existing database in the Flyway schema history table when executing a baseline action. If nothing is provided, the version is set to 1. | |
| Flyway.baselineDescription | The description with which to tag an existing schema in the Flyway schema history table when executing a baseline action. | |
| Flyway.baselineOnMigrate | Whether to automatically call the baseline action when a migrate command is executed against a non-empty schema with no schema history table. This schema will then be initialized with the baselineVersion before executing the migrations. Only migrations above baselineVersion will then be applied. This is useful for initial Flyway production deployments on projects with an existing database. Be careful when enabling this as it removes the safety net that ensures Flyway does not migrate the wrong database in case of a configuration mistake! | |
| Flyway.skipExecutingMigrations | Set this value to ‘true’ if Flyway should skip executing the contents of the migrations and only update the schema history table. This is generally used to update the history table with the migrations if you’ve already executed the migration(s) manually by executing the SQL yourself, without using Flyway, and just want the schema history table to reflect this. (Flyway Teams only) | |
| flyway.outOfOrder | By setting this to ‘true’, migrations can be run “out of order” rather than being ignored. If, for example, you already have versions 1 and 3 applied, and now a version 2 is found, it will be applied too instead of being ignored. | |
| Flyway.outputQueryResults | If set to ‘false’, Flyway will not output a table with the results of queries when executing migrations. (Flyway Teams only) | |
| flyway.ignoreMigrationPatterns | allows you to provide a comma-separated list of types of migration that should be ignored. Any migrations that match this comma-separated list of patterns when validating migrations will be ignored. Each pattern is of the form <migration_type>:<migration_state> e.g. repeatable:missing,versioned:pending,*:failed. See Ignore Migration Patterns for full details | |
| flyway.validateMigrationNaming | Set this to ‘true’ if you wish Flyway to fail fast with an exception when validating migrations and callbacks whose scripts do not obey the correct naming convention. This can be useful to check that errors such as case sensitivity in migration prefixes have been corrected. | |
| Flyway.mixed | This is best used as a file-level config. Set to ‘true’ to allow both transactional and non-transactional statements within the same migration. Flyway attempts to run each migration within its own transaction. If Flyway detects that a specific statement cannot be run within a transaction, it won’t run that migration within a transaction. This means that the entire script will need to be run without a transaction. This is only applicable to PostgreSQL, Aurora PostgreSQL, SQL Server and SQLite which all have statements that do not run at all within a transaction. This only applies to explicit transactions: Implicit transactions, as they occur in MySQL or Oracle, where even though a DDL statement was run within a transaction, the database will issue an implicit commit before and after its execution. | |
| Flyway.group | Set this value to ‘true’ to tell Flyway to group all pending migrations together in the same transaction when applying them so that they are committed or rolled-back together. (only recommended for databases with support for DDL transactions). | |
| Flyway.installedBy | The username that will be recorded in the schema history table as having applied the migration. If not set, then the current database user of the connection is used. | |
| Flyway.errorOverrides | Rules for the built-in error handler that let you override specific SQL states and errors codes in order to force specific errors or warnings to be treated as debug messages, info messages, warnings or errors. Each error override has the following format: STATE:12345:W. It is a 5-character SQL state (or * to match all SQL states), a colon, the SQL error code (or * to match all SQL error codes), a colon, and finally the desired behavior that should override the initial one.
The following behaviors are accepted:
For example:
|
|
| flyway.dryRunOutput | This specifies the output file for the SQL statements of a migration dry run. If the file specified is in a non-existent directory, Flyway will create all directories and parent directories as needed. You can send the output directly to Amazon S3 or Google Cloud Storage. Paths starting with s3: point to a bucket in AWS S3, which must exist. They are in the format s3:<bucket>(/optionalfolder/subfolder)/filename.sql. Paths starting with gcs: point to a bucket in Google Cloud Storage, which must exist. They are in the format cs:<bucket>(/optionalfolder/subfolder)/filename.sql <<blank>> (Flyway Teams only) |
|
| flyway.lockRetryCount | When attempting to get a lock for migrating, the number of attempts (at 1 second intervals) to make before abandoning the migration. By default, it tries fifty times. Specify -1 to try indefinitely. | |
Callbacks
There are three types of callbacks, the java extensions that hook into the Flyway Lifecycle, the SQL callbacks, and in Flyway Teams the script callbacks
SQL callback files that match the correct name pattern are loaded from the file locations that you specify.
| flyway.callbacks | This allows you to extend Flyway with custom Java code and logic to hook into the Flyway lifecycle, or for notifications (default: empty). You can provide a comma-separated list of fully-qualified class names of org.flywaydb.core.api.callback.Callback implementations, or packages to scan for these classes. |
| flyway.skipDefaultCallbacks | If set to true, default built-in callbacks (SQL) are skipped and only custom callback as defined by flyway.callbacks are used. (default: false) |
Conclusions
In looking through all the possible parameters for configuration files, it becomes obvious that it is very much a design decision as to where to put configuration information for Flyway. Generally, the ephemeral values, such as the nature of a migration, are best supplied as parameter values rather than being placed in a flyway.conf file. The project-level or branch-level values need to be kept with the project location so that they are read in as part of the work. The installation parameters such as the license key, custom database drivers, or the Java callback extensions should be in the installation folder, and identity information should be in the user area’s configuration file. Credentials and other ‘secrets’ need to be managed carefully, either using Flyway Teams, or by hand-crafted ways of encrypting and restricting access to passwords and accessing them when necessary.
If you can get all this right, then Flyway is a great deal easier to use for the larger database projects.
Tools in this post
You may also like
-

Article
Making AI scalable with database change management and Redgate Flyway
With the rise of AI and machine learning comes data. Lots of it. For organizations today, AI is radically changing the way data is accessed, maintained and operationalized. For heads of architecture and development teams, it offers opportunity and responsibility. Opportunity to: Accelerate development team productivity AI can be a collaborative force to speed up
-
Article
Redgate Flyway’s Product Updates – February 2026
This month’s highlights include smarter dependency handling in Flyway Desktop, and a look at how we’re starting the year strong for Oracle users. Plus: last call to share your feedback in our Flyway user survey (the prize draw closes soon!). Even more control for your dependencies in Flyway Desktop One of Flyway’s strengths is tracking
-
Article
Building an AWS DevOps Pipeline for Databases
The first time you try to automate a database deployment using any of the available flow control tools, all the moving parts makes the task look insanely difficult and this is not any different within the AWS Developer Tools. However, after you get over that initial shock, the processes are not nearly as difficult as
-
Article
Log4Shell: What does it mean for Flyway?
There has been a lot of attention on Apache Log4J in the past week due to the discovery of the Log4Shell vulnerability. As Flyway allows utilization of Log4J we felt we should address this vulnerability and reassure our users. What is Log4Shell? It has recently been discovered that there is a high severity vulnerability in
-
Article
Flyway's Validate Command Explained Simply
The Validate command aims to ensure that Flyway can reliably reproduce an existing version of a database from the source migration scripts by warning you if files are retrospectively added, removed or altered that would prevent it from doing so. Validation errors are Flyway's warning that "the source for this version has changed".
-

Web Panel
Accelerating Digital Transformation: The Role of Automation in Database DevOps
Across every industry sector, Technology teams are under pressure to release features faster and deliver value to customers sooner. Often the database is excluded from the software delivery process, increasing the risk of failed deployments that negatively impact customers. To overcome this challenge, development and operations teams rely on solutions like Flyway to bring DevOps