How to Automate Cross-Platform Database Development
In order to focus on their primary task of developing databases, the development team need to automate as many as possible of the routine tasks that are essential for database delivery, such as testing, scripting, version control, documentation, code review, reporting and so on. This article gives some advice on how to do it, faced with the added challenge of needing to use several different relational databases.
I’ve spent some time exploring the ways in which one can automate as many as possible of the time-consuming and tedious tasks that face a team-based database developer, when trying to implement DevOps practices. Nowadays, I use PowerShell, though for many years I used DOS batch files and BASH.
What adds to the interest is the increasing requirement for cross-platform, or ‘polyglot’, database development, meaning for use of different relational databases. This is particularly when many of an organization’s applications are cloud-based, and they tend to go for the most economically hosted database system!
Automation is a way of getting work done. It isn’t any longer enough to be clever or quick with SQL DML or DDL. You need to maximize the time you can spend developing databases and remove any distractions via automation.
The Requirements
Before we get into details, what should a database developer be doing in addition to the primary task of developing databases? It is an uncomfortable thought, because when you try to answer the question the list gets long, and there is always an item in the list that pricks the conscience: some chore that gets neglected because it is tedious.
We need to automate database development mainly because a team is then less likely to forget or ignore tasks that are essential for delivery, but wearisome to do, such as testing. Some tasks really can’t be neglected because they are part of the team workflow. Sanitizing, verifying, or scrubbing test data, dataset import, dataset export, bug tracking, issue management, liaison with other teams as well as users, source management, stress testing, integration testing, and signoff are obvious examples.
To make this happen, communication is not enough: various people will require access to database servers and will expect to be provided with databases at the right version with the right data, with the correct information about the database, at the appropriate level of detail. If you don’t deliver, there is a delay and occasionally recriminations.
Developers will require backups and restores for test runs and experiments, as well as those ‘bad days at work’. For test runs, they will need access to datasets for the various types of tests. They need documentation and not just cryptic messages in source code, but in a form appropriate for its intended audience.
Depending on the sort of database you are developing, there will be other people who must be kept up to date. This can become daunting. When managing major corporate database projects, I’ve had to generate reports and materials for user-interface experts, technical authors, security experts, accessibility advisors, trainers, lawyers and even trades unions.
What database development tasks do we need to automate?
Lets’ step back and list some of database development chores that are difficult to avoid.
- Build scripts – for every version there should be a source script that can be run to create the database at that version.
- Version control – the means by which the database was originally created at that version must be archived in version control.
- A ‘model’ of every version of the database – that can be used to compare different versions of the database and work out what changes were made to the database metadata and when. In a polyglot system, I like to store this as a structured document (JSON, XML or YAML and to accompany this with the object-level source code for every version that can be used to investigate why a function stopped working at a particular version. The object-level source can be the fodder for version control.
- Automated code review process – I’m as guilty as anyone of writing poor SQL Code so it is great to get the reproach from a machine rather than a smug colleague. There will be non-standard code, badly formatted code and deprecated code. It is very common to fine accidentally unindexed tables, or tables without a primary key (heap). Have I missed out a foreign key constraint? Have I done the essential comments and documentation of the database objects and the changes to them? They’ve got to be there, and attached to the metadata when the relational database that you’re using allows it.
- Documentation – it must be possible to generate appropriate documentation of a database, so that it is clear at a casual glance what every column holds, and the purpose of its table, The same goes for functions, procedures and parameters. I’d include groups of tables, interfaces and features. To make this worthwhile, it all needs to be retained, extracted and turned into documentation: otherwise, it is wasted time, and the database becomes mysterious to anyone except the initiated few ‘cognoscente’.
- Testing – we need a test harness that can perform an integration test run for that version of the database. I like to run a performance test as well to catch problems early.
- Test data management – a way of easily managing test data, including exporting datasets, comparing datasets, importing datasets, and modifying them.
Designing a system for automation
So, we need to automate each of these chores, as far as possible, in a ‘polyglot’ (multilingual) database environment, meaning that there are several different flavors of relational databases within our care. This is easy to express as a lofty ambition but hard to achieve, so how do we design a system that can do it?
I’ll explain the essential components of such a system, and some of the challenges you’ll face. A lot of my recommendations are based on lessons I’ve learned from experience, and in creating the Flyway Teamwork framework, which currently works with Oracle, PostgreSQL, MySQL, MariaDB, SQL Server, and SQLite.
Running database statements and queries and processing the results
This is the first consideration. Each RDBMS has both connection-based methods and CLI-based ways of doing it. Applications generally use connection-based methods. Flyway is no exception, basing all connections on JDBC. Let’s run through the alternatives.
ODBC
Aha, you think, a short article. All you need is a good set of ODBC drivers and the job is done. Not so fast. Database vendors provide ODBC drivers, usually free of charge, so that software developers can write code to connect to the specific database vendor’s database without having to worry about vendor-specific coding. ODBC was designed for client connection by an application to a server. It is not an administrative tool like PL/SQL. You can’t use it to create a build script, do a backup or restore, or even to do a fast import or export of data. It just provides the connection, a language-independent subset of SQL to act as a common denominator, and a model of the database that is sufficient to get an understanding of the layout of the tables and columns. I’ve illustrated how these can be used to obtain and compare the metadata of two databases on different RDBMSs.
Associated with it is an information schema that allows you to elicit the information about the design of the database by simple SQL Calls. All these are excellent aspirations, but if you wish to work with more than one relational database, then the devil is in the detail. It is rare indeed to find an ODBC driver that is correct according to the published specification, and the information schemas, in particular, are different for every RDBMS.
The people who designed ODBC allowed different levels of conformance. Human nature did the rest of the destruction of the noble aspirations of ODBC in providing a consistent interface to the different relational database systems. There are one or two commercial products that provide a Command Line SQL Statement Execution Tool using ODBC, but I’ve not tried them.
JDBC
JDBC is the Java equivalent of ODBC. A JDBC driver is built as a collection of Java classes and possibly native software. Like ODBC, it deals with the task of connecting to and communicating with a database. I get the impression that it has fared better than ODBC in maintaining consistency. However, even if you could use this easily within PowerShell, without installing the JDK, you still have the problem that it isn’t an administrative tool. It can’t, for example, provide you a build script or do a backup or restore of the database.
There are tools such as Razor that can do a lot with JDBC, such as providing data import, comparisons, and script-based backup. It can connect to forty different database systems, so is a useful tool if nothing specific for a particular RDBMS can be found.
Vendor-supplied CLI tools
Every database vendor provides command line tools for Windows, and usually Linux, to allow databases to be set up, torn down, backed up, imported, and exported. There is no consistency between them; they go their own way. However, they provide almost everything one needs. The downside is that, with the notable exception of SQLite, they are very slow for simple statement or query execution.
We tend to use bcp.exe, SqlPackage.exe and sqlcmd.exe CLI executables for SQL Server, psql.exe and pgdump.exe CLI executables for PostgreSQL, sqlite.exe CLI executable for SQLite, the sql.exe CLI executable, which includes SqlCl, for Oracle, and mysqldump.exe and mysql.exe, the CLI executables for MySQL and MariaDB. These utilities vary a great deal in what they can do. If you use this approach, it is best to make as much use as you can of the built-in features and make your code consistent between RDBMSs via abstractions at a higher level of your script application so that, for example, an object-level model is generated by a single command whatever is required within subroutines that support this. Take a look at the $SaveDatabaseModelIfNecessary task in my Framework resources, for an example of how I did this in PowerShell.
Scripting modules
SQL Server developers will be used to the SMO library, now the power behind the PowerShell sqlserver module. As the SMO library provides the functionality for the SSMS, you can be sure that it provides everything you could possibly need, and a lot that you don’t. Unfortunately, there is nothing directly equivalent for any other RDBMS. The nearest equivalent is Oracle’s SqlCl.exe. It provides most of the functionality of Oracle SQL Developer, but uses just a PLSQL script as interface and has no concept of an open connection, which means that it is slow to run single SQL statements.
There are several Python libraries for SQLite, MySQL, SQL Server and PostgreSQL but these are limited to providing just database connections. You couldn’t get them to provide build scripts or do a backup. For Java-based scripting, Flyway can be thought-of as a specialized code module for running SQL Migration scripts and maintaining a version and can be integrated with Maven or Gradle.
What should I use for automation in a Polyglot database environment?
Right now, there is only one viable solution for scripted automation with Python, PowerShell, Bash or DOS Script, in a polyglot development environment, and that is to use the CLI tools provided by each database vendor. It is to manage the more complex tasks such as backup and restore or bulk import and export that make it an easy decision. Basically, you’ve got to do it anyway.
Also, your version control tool is likely to be CLI-based too. The delivery systems for cloud-hosted database servers, such as Azure Pipelines, are too diverse for any other automation system. It also means that automation scripts are more easily ported between Linux and Windows.
The downside is that you must manage the widespread differences by ‘layering’ the code so that you can run batches, modules or script blocks that work the same way with each database system. One should, for example, be able to run a module, script block or whatever that produces a standard JSON file of a result from a standard SQL Query whatever RDBMS you’re using.
The biggest problem with this sort of solution, at least on a Windows workstation, is that the Java-based CLI tools take a while to load, because of the requirement to heave in the Java environment. This means that each SQL query or statement is very slow. At one point I despaired of the difficulties of automating Oracle with PowerShell, but there is an interesting feature of PLSQL that makes the slowness tolerable. You can batch up a whole lot of queries in one PLSQL session so that each result is saved under a separate filename that you choose. Where a process takes several SQL Calls to initiate, it can be done by a single invocation of Oracle’s SQL.exe and so it is just one measured loading of the Java environment that you must wait for.
Polyglot build/migration systems
The most common way to design, build and deploy each new version of a database is to use ‘evolutionary’ techniques based on migration scripts. The two most used, migrations-based build systems are Flyway and Liquibase. Whereas Flyway is based on the idea of a linear database versioning system, Liquibase chooses instead the master changelog.
I use Flyway and it’s worth trying out because of the value that a strict database versioning system provides, such as avoiding wasted time in testing, or from changing the wrong copy of the database, and it makes bug-reporting much, much easier. It also has a callback system that allows us to run many routine tasks automatically, on successful completion of a migration.
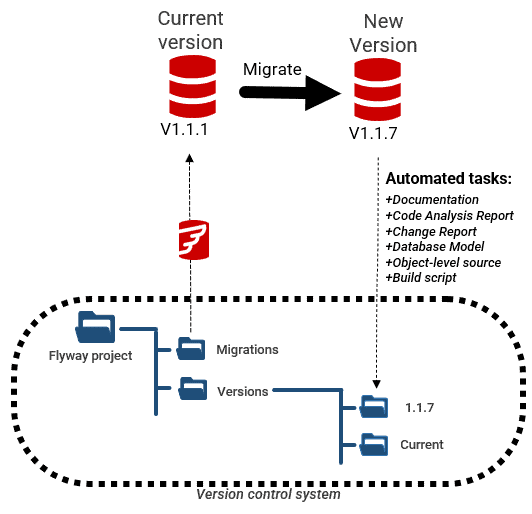
Standard SQL Coding?
In the Flyway Teamwork Framework, I created a single script block routine called Execute-SQLStatement that would execute SQL whatever the RDBMS. One of the advantages of having a single routine for making SQL queries to a range of relational databases is that one can quickly find the SQL dialect that suits the most relational databases and executes with the fewest errors. You can try queries out on Oracle, PostgreSQL, MySQL, MariaDB, SQL Server, and SQLite in quick succession. See Cross-RDBMS Version Checks in Flyway for an example.
With queries, and a test harness that allows you to execute SQL to a range of relational database systems, you can quickly get into the habit of writing to the ISO SQL-92 standard, where possible, with semi-colons, case sensitivity, and with the full syntax. Don’t think about using square bracket delimiters for non-standard object names. Stick to the standard double quotes.
However, this only helps with the declarative SQL query syntax. You can save yourself a lot of time by concluding correctly that the procedural extensions in stored procedures and batches really aren’t going to port in any way between implementations. You are also likely to become frustrated by the different ways of querying the metadata. You’d have thought that if a database implements the information schema correctly, you are in the clear, but sadly not. Oracle, for example, doesn’t even get as far as implementing it.
Conclusion
In the past, I’ve developed database-driven web-based applications that assume a particular RDBMS, only to be told that the organisation has decided to use a different RDBMS, normally because there is a cheap cloud-based hosting provider for it. Fortunately, it is possible to develop relational databases that can be easily implemented on a variety of relational database platforms, but it pays to use as little procedural logic in the database as possible, because each RDBMS will need its own version, usually radically different. For many website applications, though, it pays to be able to opt for the cheapest, handiest, more robust or most secure relational database that is available, but it isn’t a pain-free process!
Tools in this post
You may also like
-

Article
Using a GitHub Tagged Release for a Flyway Migration
Why not just build the latest version of any branch of the database by pulling the scripts from the latest tagged release on GitHub? While it is easy to get the files via the GitHub site, it gets tedious to do so repeatedly, via the GUI. It is, however, possible to automate this via the Rest API, using a script. If you are using PowerShell, I've done it for you.
-
Article
Building an AWS DevOps Pipeline for Databases
The first time you try to automate a database deployment using any of the available flow control tools, all the moving parts makes the task look insanely difficult and this is not any different within the AWS Developer Tools. However, after you get over that initial shock, the processes are not nearly as difficult as
-
Article
The Flyway Info Command Explained Simply
If you need the current version of your Flyway database, and a history of the changes that were applied to build that version, then the info command is the place to go. It allows you to review applied and pending migrations, track migration status, and troubleshoot any issues that may have occurred during the migration process.
-

Article
What’s under development in Redgate Flyway
In my recent posts, I looked back at the major features we shipped in 2025, highlighted all the exciting things going on in Flyway for Oracle databases, and shared the recent improvements to tracking dependencies for both SQL Server and Oracle databases. But that’s only part of the story. With four development teams working on
-

Live training session
Flyway 101: Solving hotfixes and environment specific deployments
When the process evolves and more people are collaborating with more frequent releases, how can teams stay reactive and continue the agile approach? Using cherry pick to select specific migrations and rollbacks, teams can prioritize certain deployments above others, whilst still working in the designed framework. In addition building additional complexity such as marking scripts already deployed and setting migrations to only be executed against specific locations.
-
Article
Using JSON Output to Track and Log Flyway Migration Activity
Flyway's JSON output provides a lot of useful information about the migrations files, database, and version changes, in a format that automated processes can read and use. This article demonstrates how we can create a Flyway callback that uses this JSON output to automatically send simple, human-readable notifications of what happened during a migration, helping developers stay informed about version changes that could impact their work.