





Creating Custom Regex Rules for Code Analysis in Flyway
Code smells are the mistakes, omissions, and vulnerabilities in the SQL code that makes it harder for a team to subsequently modify and extend the work and can also lead to unpredictable behavior and performance. They are one measure of the extent of the 'technical debt' in existing code. If you remove these issues before they enter the main migration chain, you'll experience fewer deployment issues and, over time, reduce maintenance costs.
Flyway will help you detect these SQL code smells by running static code analysis on the database and the Flyway migration scripts, using the check -code command. This command uses a SQL linter called SQL Fluff for parser-based analysis and regex rules that allow teams to provide custom checks to analyze SQL migration scripts. It produces a JSON report of any rule violations.
This article is about the regex rules. My previous article described the basics or running the rules, and this one is about writing custom rules, and how to grow your regex rule library in a structured and manageable way. Regex search is a relatively crude instrument because cannot parse SQL syntax in the way a SQL linter does. They treat SQL as plain text, meaning they can't distinguish between keywords, identifiers, literals, comments or operators. A string may be perfectly legal as a literal but not as an operator; the type of token is relevant. However, the GREP-style Regex search is an easily customized way of indicating parts of SQL Code that need 'checking out'.
What code smells do we need to find?
Flyway provides, as examples, a set of built-in rules, focused mostly on security and data protection, such as detecting DROP TABLE, overly permissive GRANT statements, or missing WHERE clauses in UPDATE or DELETE commands.
The built-in rules provide a foundation, but every team has its own standards for ensuring SQL is clean, efficient, and consistent across projects. They will quickly want to extend these rules to enforce and maintain their standards for:
- Code style and maintainability – such as naming conventions, code headers and comment, avoiding SELECT *
- Performance best practices – e.g. discouraging non-SARGable queries
- SQL hygiene – e.g. catching forgotten
PRINTstatements orTODOcomments - RDBMS-specific standards – SQL Server teams banning
SETFMTONLYON, PostgreSQL teams flaggingUSINGin joins
It is important to note, though, that SQL is not a procedural language. Unlike procedural languages, which define a sequence of operations to be executed, SQL focuses on declaring what data to retrieve or manipulate and leaves the optimizer to determine the most efficient way to perform that operation. This means that team standards should not get too involved in code formatting as such.
Crafting custom regex rules
Writing effective SQL regex for is not always straightforward. SQL is a structured language, but regex treats it as plain text, meaning false positives can occur if you're not careful. There are also subtle differences between various types of regex engine that can trip you up.
Flyway uses a Java regex engine, and there are a few nuances that might catch out any developers coming from .NET regex. For example, although Java's regex engine works with single \ just like .NET, Java string literals require escaping \ as \\ before sending the string to the regex engine.
Consider the regex that Flyway uses to detect use of SELECT *:
|
1
|
(?i)SELECT\s+\*
|
When reading the rule from a TOML rule file, you need to escape the backslash because although Java regex works with a single \, but Java requires the double \\ for string literals, so Flyway (being written in Java) requires the double \\, to read in the TOML values correctly:
|
1
|
(?i)SELECT\\s+\\*
|
If you're storing rules in a JSON file then generating TOML files dynamically (as I demo later) then you need to do double-escaping, because the backslash is a JSON escape character:
|
1
|
(?i)SELECT\\\\s+\\\\*
|
If you're working with basic regex patterns, Java and .NET are nearly identical, but for complex parsing tasks, .NET is better due to its advanced lookbehind, balancing groups, and inline conditionals. Regardless of regex engine, there are also certain regex patterns to be aware of, such as use of greedy quantifiers like * (wildcard match), that in large scripts can cause excessive backtracking and performance issues.
Developing and testing your rules
I try out all my regexes using a Regex IDE (RegexBuddy), because that allows me to program in the Java dialect of Regex. I can develop the regex in the top section and use the SQL code in the bottom section to test ideas with some sample queries.
As an example, a development team might decide to create a Flyway regex rule to verify the presence of the structured headers in SQL migration files. These headers would detail the purpose of the migration script, the author, and the creation date. A sample regex pattern to check for these headers, formatted as block comments (/*...*/) at the beginning of a SQL script, could look like this:
|
1
|
(?i)\A\s*/\*\s+Purpose:.{3,500}?Author:.{3,30}?Date:.{3,30}?\*/
|
Or, if the team prefer single-line comments:
|
1
|
(?i)^--\s*Purpose:\s.*\n--\s*Author:\s.*\n--\s*Date:\s.*
|
This GREP-style regex search can be customized further to meet specific team requirements and help maintain consistent documentation across all migration files.
Here we are testing out this rule in Regex Buddy:
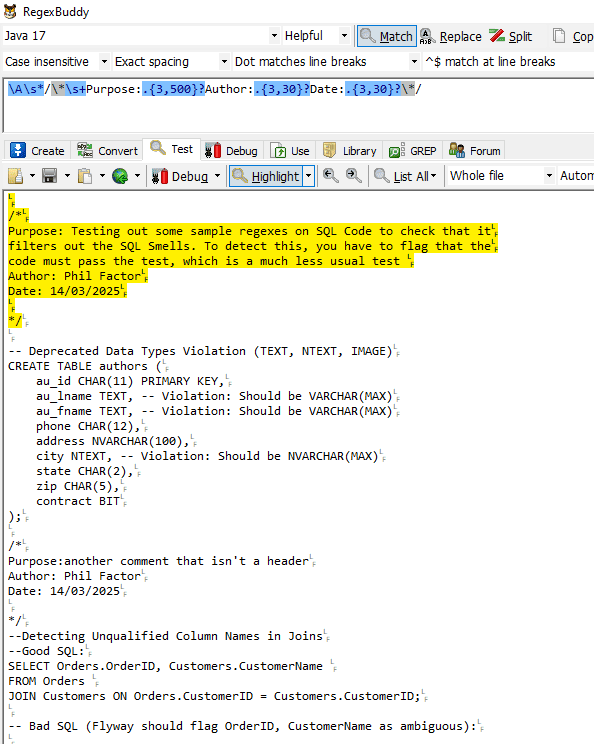
I have plenty of bad SQL, because I do a lot of trial work where I need to try out a database design very quickly. I don't scrap the code because it is handy for this sort of task.
Building your custom regex library
It is a slippery slope to try to enforce too many rules, because nobody ever agrees on what standards are required. However, there are a few sensible regex rules you can enforce to ferret out some of the common code smell offenders, as well as to help maintain consistency across scripts, making it easier for teams to review and troubleshoot them.
To get you started, and to delve into the nuances or creating and maintaining new rules, I've created custom regex rules for a section of code smells from my SQL Code Smells book (there is also a GitHub site containing a GitHub version of the book). The following table summarizes those that we can sniff out with custom regexes. These are just examples of the sort of smells you can catch; they work but one or two (like "Non-SARGable Queries") use wildcard (*) searches that may not perform well on large SQL scripts. You'll need to test and potentially refine these examples, based on the size and types of scripts you need to analyze.
You can find the individual rules files (.toml) in my Flyway GitHub project. However, I prefer to maintain the rules in a single JSON file and then auto-generate the individual TOML files using PowerShell (more on this shortly):
| Name | Dialects | Rules (Regex) | Description | ||
|---|---|---|---|---|---|
| SELECT Star | All | (?i)SELECT\s+\* | Avoid using SELECT *; specify columns explicitly. | ||
| Implicit Joins | All | (?i)FROM\s+\w+(\s*,\s*\w+)+ | Use explicit JOIN syntax instead of comma joins. | ||
| Deprecated outer join syntax | Oracle, TSQL | \(\+\) | Old-Style Outer Joins - Proprietary syntax (e.g., Oracle's (+)). | ||
| Unqualified Column Names in Joins | All | (?i)SELECT\s+?([]\[\w]+[,\s]+)+FROM\s+?([]\[\w]+\s+?)+JOIN | If a query involves a join, it is safer to specify the table origin of a column | ||
| Be Explicit About JOIN Type | All | (?i)\bJOIN\b | Use INNER JOIN, LEFT JOIN, RIGHT JOIN explicitly. | ||
| Avoid RIGHT JOIN | All | (?i)RIGHT\s+JOIN | Prefer LEFT JOIN for better query readability. | ||
| Non-SARGable Queries | All | (?i)WHERE\s+.*(upper|lower|substring|replace|coalesce|mod|round|nullif) | Non-SARGable Queries | ||
| UNION instead of UNION ALL | All | (?i)UNION(?!\s+ALL) | Use UNION ALL unless explicitly removing duplicates. | ||
| No WHERE Clause on DELETE or UPDATE | All | (?i)(DELETE|UPDATE)\s+(?!.*\bWHERE\b) | No WHERE Clause on DELETE or UPDATE | ||
| Primary Key Naming (PK_) | All | (?i)\bCONSTRAINT\s+(?!PK_)[a-zA-Z0-9_]+ | Primary key constraints should start with 'PK_'. | ||
| Foreign Key Naming (FK_) | All | (?i)\bCONSTRAINT\s+(?!FK_)[a-zA-Z0-9_]+ | Foreign key constraints should start with 'FK_'. | ||
| Index Naming (IX_) | All | (?i)CREATE\s+INDEX\s+(?!IX_)[a-zA-Z0-9_]+ | Index names should start with 'IX_'. | ||
| Avoid Short Table Aliases | All | (?i)FROM\s+\w+\s+[a-zA-Z]$ | Use meaningful table aliases instead of single letters. | ||
| ORDER BY without LIMIT/OFFSET | All | (?i)ORDER\s+BY\s+[^;]*$ | Inefficient for large datasets without limits. | ||
| SET FMTONLY ON (SQL Server) | TSQL | (?i)SET\s+FMTONLY\s+ON | Deprecated in favor of sp_describe_first_result_set. | ||
| small VARCHAR sizes | All | (?i)VARCHAR\s*\(\s*[1-3]\d?\s*\) | flag small VARCHAR sizes (suggest CHAR for small fixed-size strings) | ||
| ToDo_Test | All | (?i)toDo|toTest|tearDown | possible unfinished alteration or Test artefact | ||
| End-of-line comments without space | All | --\\S | end of line comments without a leading space (Style not error) | ||
There are several ways where one might usefully expand this even further. We can, for example, also use regexes to search for deprecated features, or superseded features such as RAISERROR (we should use THROW) or CONNECT BY (rather than WITH RECURSIVE). It can be used with features that the team would like to discourage, such as ENUM and SET types.
Running the custom code checks
First, copy all the built-in Flyway rules from the install directory to a Rules subdirectory in the Flyway project, alongside your custom regex rules. This directory must be accessible from all branches of your project.

To test the rules, I'm using the same SQL assault course that I provided in the previous article. It is geared for SQL Server. Just save it to the migrations folder, with a version number that is higher than the current version.
We're now ready to run Flyway's check -code command and inspect the results. Flyway needs to know what dialect of SQL you're using, so we need to create an environment (the connection details for your database). Flyway will get the dialect from the URL of the current environment to work out which dialect of SQL you're using. Please refer to my previous article or the documentation for further details.
I'm saving the connection details and credentials for each branch database in individual TOML files in the secure user area in Windows. If you are using TOML environments, then instead you'll just need to define your database 'environment' in the flyway.toml file, indicates which environment Flyway should use as a parameter or environment variable, and uses resolvers on credentials or connection details within the flyway.toml file.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
'' $Project = 'Pubs' # for working directory and the name of the credentials file
$Branch = 'Main' # the branch. We use this just for suitable login credentials
$Server = 'Philf01'
$RDBMS = 'SQLServer'
# You'll need to define your own $env:FlywayWorkPath
$credentialsFile = "$($RDBMS)_$($Branch)_$Server"
#we specify where in the user area we store connections and credentials
$currentCredentialsPath = "$env:USERPROFILE\$($Project)_$($credentialsFile).toml"
#go to the appropriate directory - make it your working directory
if ($Branch -eq 'main')
{cd "$env:FlywayWorkPath\$Project"}
else
{cd "$env:FlywayWorkPath\$($Project)\branches\$Branch"}
<# $current just contains your current environment.
If you call it something different, you'll need to change it in the subsequent code #>
$current = "-configFiles=$CurrentCredentialsPath"
$SQLSmells = (flyway $current check -rulesLocation='.\rules' '-outputType=json' -code)|convertFrom-json
if ($SQLSmells.error -ne $null) { Write-error "$($SQLSmells.error.message)" }
$Smellyfile=($SQLSmells.individualResults[0].results[0].filepath -split '\\')|select -Last 1
$Smells = $SQLSmells.individualResults|where {$_.operation -eq 'code'} | foreach{$_.results}| foreach{ #code operation
$file = ($_.filepath -split '\\') | select -Last 1; #get the filename
$_.violations #get each violation
} | foreach{
[pscustomobject]@{
'File' = $file; 'Line' = $_.line_no;
'Col' = $_.line_pos; ; #'Code' = $_.code;
'SQL Smell' = "$($_.code) ($($_.description))"
}
} | Sort-Object -Property @{Expression={$_.file}}, @{Expression={$_.line}}, @{Expression={$_.col}}
$Smells| Out-GridView -Title "SQL Code Smells for $Smellyfile"
|
So, we run the dummy SQL files and get the following violations reporting in the code smells report.
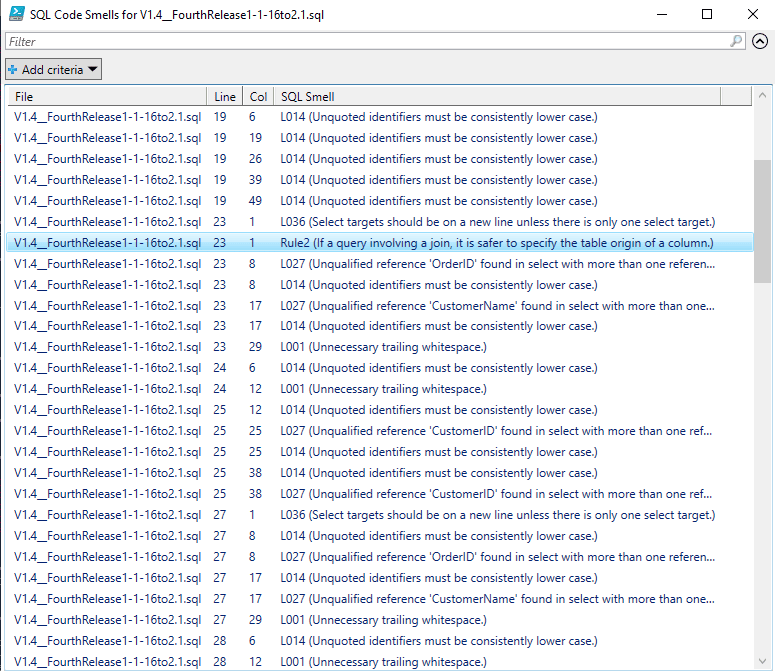
You'll see that the $SQLSmells array can be checked by any pipeline process, or fed into an alerting system before the migration is run. There is also an HTML report generated for Flyway Desktop, if prefer that for visual checks. I prefer to be notified via the iPhone, so I'll settle for the 'SQL Code smells' output in CSV or JSON format that can be read by a notification system.
Maintaining your regex library in a single JSON file
Flyway doesn't currently support TOML files that contain a collection of rules. It requires each rule to be in a single TOML file, which can be stored and maintained in version control. Personally, however, I prefer to maintain all my rules in a single file. Regex rules don't generally just "stay written". You have an infrequent but necessary maintenance role whenever you hit a shortcoming with a rule. Fortunately, with a little bit of scripting, we can easily adapt the Flyway code analysis workflow to support this.
I keep all my custom regexes in a JSON document and simply generate these as single TOML rule files, within a PowerShell script, when I need to run them. I don't add the built-in rules because those might be changed in an updated version. It is safer to load in the ones you want and check for any changes when you update.
In my Flyway Teamwork GitHub project, I've provided a single Rules.json file, containing a selection of custom regex rules from the previous table. We store it within the Flyway project, in a subdirectory of the main branch. I use 'Scripts' but its name will be defined in the $ProjectLevelResources variable. Don't put it in your rules directory because Flyway tries to read any file, not just a TOML file, and then 'errors out' because it's JSON not TOML.
The following PowerShell script will read the JSON file and write each rule as an individual TOML file to the Rules directory (ensuring Flyway-friendly encoding in Windows-1252). It deletes any existing version before saving the new one.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
$workingDirectory=<path to my project>;
$ProjectLevelResources='Scripts'; #the name of the project level resources
$win1252 = [System.Text.Encoding]::GetEncoding(1252) # rules must be in this format
$Rules=type "$workingDirectory\$ProjectLevelResources\Rules.json"|convertFrom-JSON
$rules.rules| foreach -begin {$ii=1}{
$RuleFilename="$workingDirectory\Rules\Rule$($ii)__$($_.name).toml"
$AmbiguousRuleFilename="$workingDirectory\Rules\Rule*$($_.name).toml"
# we'll remove the old version if any
if (Test-Path $AmbiguousRuleFilename -PathType Leaf)
{
write-verbose "deleting $RuleFilename"
Del $AmbiguousRuleFilename
}
$TheRules=($_.regex -join '","')
$TheDialects=($_.dialects|foreach{if ($_ -eq 'All'){'TEXT'}else{$_.ToUpper()}}) -join '","'
$Contents=@"
dialects = ["$TheDialects"]
rules = ["$TheRules"]
passOnRegexMatch = $(if ($_.passOnRegexMatch -eq $null) {'false'} else {$_.passOnRegexMatch})
description = `"$($_.description)`"
"@
[System.IO.File]::WriteAllText($RuleFilename, $Contents , $win1252)
$ii+=1
}
|
When we want to add a new rule to the archive or edit an existing rule, we do it in JSON:
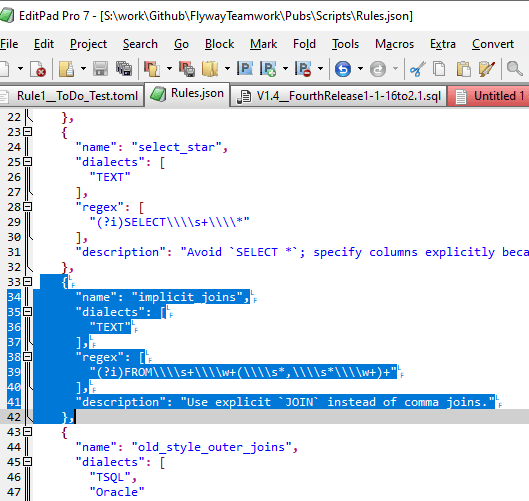
You'll notice that each backslash character in the regex has to be repeated four times to get past the Java import routines, as I described earlier.
Each time you add new rules to your JSON rules document, or edit existing rules, you simply run the previous PowerShell script to regenerate the individual TOML files. If Flyway progresses in later releases to allow all the rules in one TOML file, we can easily generate the TOML from our JSON file of rules, like this:
|
1
2
|
$Rules=type "$workingDirectory\Scripts\Rules.json"|convertFrom-JSON
$rules|convertTo-TOML
|
I'm using the convertTo-TOML from the Flyway Teamwork framework in GitHub.
Conclusion
I hope that I've given you a flavour of my views about a useful tool that replaces all the GREP clutter that we seasoned database programmers tend to accumulate. What's there to like? Well, you get a checklist of SQL code that might just need a bit of tidying up before your careless code gets enshrined in a migration. Because the checklist is in a structured document (JSON) it can be read accurately by other participating CLI applications in the release pipeline.
Unlike the SQL Fluff code analysis, a Regex check can be configured exactly to the requirements and styles agreed by the team doing the development. This will include security and operational concerns as well as development issues. Sure, this iteration of the tool has a few rough edges, such as the strange requirement for the text encoding of the TOML rules, but there is a place for a simple and configurable system for doing regex searches for coding issues.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Flyway 7.3.0 Released
Flyway 7.3.0 is out! This release contains new features and improvements over Flyway 7.2.0. Highlights You can find a detailed list of the changes in the release notes. Migration filename placeholder It can be useful to know the full name of a migration file at the time it’s executed, for auditing purposes. The migration description is of course preserved in Flyway’s history, but this wasn’t available to the migration itself. You can now use the placeholder ${flyway:filename} and the migration’s full name will be substituted. See the documentation for more details. Script config files A new option for script configuration files is shouldExecute. This can be set

Live training session
Bare Bones of DevOps in AWS
In this session Grant Fritchey introduces the absolute baseline needed to start your database DevOps journey within the AWS ecosystem. He starts with how you can get your database into source control and ends with the start of a Continuous Integration (CI) process. These are the fundamentals of any extended DevOps process including CI and Continuous Delivery (CD). With the fundamentals in place, building more advanced processes is simply a matter of the labor to build on that foundation.
Article
Maintaining Variants of a Database using Flyway Locations
In this article, I'll explain why we often need to maintain variants of the same database, at a particular version. I'll demonstrate how useful variants can be for creating slightly modified installations of a database, for special uses, or even for the simple task of provisioning multiple copies of the same version. In doing so, I'll show how we can use Flyway
locationsto overcome problems that would otherwise require complicated solutions. Flyway can make the whole matter of maintaining database variants very easy.Article
Automating Flyway Development Chores using Database Diagrams
If you can produce a quick Entity-Relationship diagram for any version of a database, you'll have a simple way to 'sanity check' it for unreferenced tables, missing keys and other design flaws. This article shows how to auto-generate these diagrams when running a migration, using Flyway Teams and PowerShell.
Article
Defining and Using Multiple Flyway Environments in TOML
This article shows how to define environments in your TOML files, use resolvers to provide secure connection details, and configure per-environment overrides and placeholders. It explains how this approach simplifies automation, makes CI/CD pipelines easier to manage, and helps teams work consistently and securely across multiple databases.
Article
A Test Data Management Strategy for Database Migrations
This article will help you understand the steps to better test data management, when using a migrations-based approach to database development and deployment. It explains the different types of data required and why, the need for separation of DDL and DML code, and the most efficient way to create, load and switch between the different required data sets.
Loading comments...