





Branching and Merging in Database Development using Flyway
When scaling up a team-based development of an application or database, it becomes increasingly important to be able to work on several different aspects or features simultaneously. For rapid development work, you'd be likely to require that several independent activities, involving perhaps bug-fixes, performance enhancements, re-engineering exercises, exploratory work and new feature development, are all being done at the same time, each one in a separate strand of work. This is particularly important in database development.
By separating these strands of work, usually by assigning each strand to a separate branch in Git, you allow the team to postpone features, accelerate hotfixes, and generally be more accommodating and timelier in delivering the requirements of application development.
A Flyway database development is no different; there comes a time, as the number of people working on the development increases, that you'll want to starting separating work into branches. This can result in multiple separate 'strands' of versioned migration scripts that you'll somehow need to merge back into the main development branch, while preserving the correct sequence and without altering any files that are already in place. As you'll see, it's a formidable task.
This article describes how Flyway (Enterprise edition) provides a different approach where, instead, you avoid creating a migration file until the changes are ready to merge. You then use SQL Compare, which provides two services to make the merge much easier: it describes succinctly the differences between the two branches that merge and generates a first-cut migration script to perform the merge. You can test this merge script, repeatedly, using the 'disposable databases' provided by SQL Clone, to maximize the chances of a painless merge operation.
Scaling up from trunk-based development
Trunk-based development is fine when there is just one developer, or maybe a handful preferably within shouting distance of each other. It requires close cooperation. The most I've ever managed this way was a team of four. As the scale of the work grows, teams can't manage this level of cooperation while doing parallel working on several tasks simultaneously. They might try to all work on the same aspect of the coding but 'hunting in packs' is never productive. Instead, individual developers need to work reasonably independently on their objectives without being distracted continuously with problems of interdependencies, pending features, and code-clashes. I've described elsewhere some ways to help avoid these problems as far as possible during branch-based development.
Nowadays, when branching and merging is no longer associated with branch-bafflement and merge-misery, it is common to use version control to allow parallel threads of work, and to release finished work at the right time by merging.
Each thread of work must be allowed a generous degree of autonomy in its branch. A developer can pull changes from other branches if needed, but also has the option of working on the branch as if there were no other changes. The task of reconciling any conflicts in the changes that emerge from testing, and are highlighted by source control, is postponed until the merge. It is at this point that the team can apply their specialized skills to review the code, and deal with any code conflicts and dependencies, to ensure that a merge is problem-free. Success hinges on the merge.
When you are working with application or database source code in the conventional way, creating and altering files and committing the changes, then this branching and merging is easier to manage. With Flyway migrations, however, databases are built in a strict sequence of immutable migration script files. This is a very different model of coding to the method Git was designed for. There is no direct parallel in conventional procedural coding: you don't change a C# application with migration scripts, for example, you build it. How then can you manage teamwork in such a way that developers can work in different branches independently, and then merge?
The strength of a migrations-based approach to databases
Even if you adopt a build-first approach, the upgrade of a production relational database of any size is inevitably done with a migration script. It has become "nature's way" that the deliverable for any upgrade of a database is a migration. This wasn't always so: there was once a time when releasing a new version meant taking a production database offline and rebuilding it. This involved exporting the existing data, building a new version of the database with a build script, and importing the data into it. This process had to be rehearsed in staging until the process went with military precision.
However, nowadays we do database deployments by changing the live system with a migration script that must preserve the existing data, without downtime. It is a very different process and culture. By using migrations in development, the developers become attuned to the challenges they must face when the database is deployed, and make sure problems are fixed as early as possible in development. They will have plenty of opportunities for fine-tuning and testing the migration process during development.
Semantic versioning for database migrations
When executing migrations, Flyway must know the correct order for applying migration scripts to a database. It will accept almost any string as a filename-prefix, which it will then use to determine the order in which it sorts the migration files. In all the examples in my previous articles, I've used a three-part version number (V1.1.3, V1.1.4 etc.) as the filename-prefix without fully explaining why. It is an example of a semantic version because it tells you what are breaking and non-breaking changes.
The first number is the major version, which you increment if you make changes that break the API, the second is the minor version, for when you add functionality in a backwards compatible manner, and the third is the patch version when you make backwards compatible bug fixes or 'tweaks'. There is no limit to the numbers in major, minor or bugfix parts of the string, though anything more than three figures is frowned on.
When working with a database and application that needs to be used together, the idea of a 'breaking change' is a change to the interface between database and application. If the application is allowed unfettered access to all the database objects without any access control, then almost all changes are liable to be breaking changes. If the interface between the application is carefully planned and maintained, then it is possible to do a great deal of development on either side without the noise of breakage.
One of the big challenges we face when scaling up the migration approach to use branch-based development is in maintaining the correct migration sequence.
Problems with managing versions in database migrations
The migrations approach to database development envisages a small team, maybe one or two active developers. The method doesn't scale easily, as developments involve more and more people, unless you add practices that make it easier to avoid conflicts.
I'll explain some of the issues you'll encounter.
Migration script immutability and sequencing
Even when only two developers are working on the same database in Flyway, they can hit problems. For example, to build a version of a database, Flyway just executes each migration file in the order dictated by the prefix on the filename (commonly a version number, as I 'll discuss a little later). Each developer will be producing migration scripts with version numbers, and then committing the files into the main development branch. What if a colleague saves a file with the same version number? Flyway will rightfully protest because the order of execution is now ambiguous.
Basically, Flyway will only agree to run a migration file if it knows the state of the database represented by the previous migration. It needs to be certain about what went before. To help ensure this, each migration file must be immutable. If you edit an existing migration file in order to rename a table, for example, you'll break any subsequent migration that use the old name. Flyway Migrations are, for good reason, protected with checksums to prevent such tampering. If a mistake becomes apparent in a migration only after it is successfully committed and then included in a migration, it cannot then be altered. Instead, you merely add a 'roll-forward' version that corrects it, just as you would in a release to an existing production system. You hope to get it right first time, and so avoid a build-up of successive migration files as you home in on the best fix. This 'immutability' of migration scripts also prevents team members from clarifying code with formatting, comments and documentation.
Not only is each file immutable, the sequence in which the files are executed must be also preserved. Flyway is only happy when you add to the end of the queue of pending files, growing your codebase like a chain. It does this because a migration must be from a known version as well as being to a known version. This checking of the sequence is necessary because the version number in the filename only tells you the final version that the migration creates, if executed successfully, not the version from which it started. This source version must be implied from the sequence so you can't change the sequence.
If you're committing a sequence of migrations and another developer commits, saving their migration files between yours in the version order, like a shuffled pack of cards, then Flyway will protest that the order of files pending execution has changed from what it was at the last migration.
Here are some of the alternative versioning techniques and flyway "workarounds" that have been used or suggested to tackle these problems). However, these are really ways of 'cheating' the migration system in development, to get things done, and when overused they compromise the value of control that you get with Flyway.
Time-based versioning
To solve this problem, some teams simply abandon the idea of a semantic versioning system, and instead simply use the time that the migration file was saved to the project directory as the prefix. Flyway then obligingly orders the migrations according to the time they were saved into the project. If you save it and it works, and doesn't harm other concurrent work, then the immediate problem is solved. However, by jettisoning the whole purpose of semantic versioning, this is an invitation to dependency hell, because one can no longer be certain of what versions of database and application(s) are compatible. It also locks you into having to save your files in the order in which they will be executed, even if it turns out to be wrong.
Predicted Versions
This technique attempts to preserve semantic version sequences by pre-planning the order of migration. You use blank migration files for each job of work in the order with which you plan to push it to origin, and then update them with the migration code for that feature. When ready to do a migration, you then run Flyway 'repair'. This is bad news because Flyway realigns the checksums, descriptions and types of all the applied migrations with the ones of the available migrations. Because it recalculates all checksums, you will lose the audit trail of whether any migrations have been modified. It also fails if events overtake your predicted ordering and you must delay the release of a feature, or if you need a sudden patch.
Disordered Processing:
This Flyway feature allows you to insert a migration file in the correct logical place within the file sequence and then do an 'out of order' processing. This requires a configuration change: flyway.OutOfOrder=true. This setting allows any valid, pending migration script that is detected to be migrated when a Flyway migration is run. This lowers the risk of version collisions, but you need to remember to switch it off once the deed is done and let Flyway subsequently use the version order.
Cherry-picking
The CherryPick feature of Flyway Teams allows you to specify the files to be used and the order in which they are executed. You can specify them either by their description or version number.
File-renaming
One might instinctively just change the names of the files to give them the right sequence, but this would present difficulties for your source control system and would require a drastic 'Flyway clean' or you would have to manually patch up the metadata table in the database to avoid any validation errors
Maintaining a history of changes to each object
Migration-first also makes it more difficult for a developer to get up-to-speed with the history of developments for a group of related tables, a procedure or an interface. You might think that a well-functioning team will be able to manage any type of subsequent code conflict by checking on previous changes: Maybe, but how do you investigate changes that have been made to the individual objects in the database, especially when the migration files grow into the hundreds?
To explain some of these problems, let's take the example of an alteration to a table function. The ALTER keyword hides the fact that the body of the function is adopted in its entirety, obliterating all of what was there. If two different developers alter the same function, the one with the later version number wins all. One team adds a parameter and adds logic, the other adds a column and maybe changes the name of another. You get one or the other, but not both. It is an easy mistake to make because in any migration-first approach, you don't find differences in different versions of the same file, but you are, instead, obliged to scan a collection of files in order looking for changes to that object. Good luck with that, and your 'agility'.
With large teams of developers making changes to individual modules or other database objects this problem worsens. It becomes much easier if you generate a build script on every migration and save this in a source control repository so that it can track changes to the file over time. For larger projects, it is possible to maintain a secondary archive of the individual build scripts, either at database level, schema level or object level, using SQL Compare. This will allow you to get a change-by-change perspective of every object in the database. If you maintain a reference version for each major version of a database, built only from these scripts, you'll also be able to use it in comparisons to detect drift in migrated databases.
Team-coordination with larger databases: branch and merge
To illustrate the problems we need to solve, we'll start by imagining two branches in Git, 'master', or 'main', which represents the database that is in production, and 'develop' which has the current development work. Each branch is represented by a copy of the database which is copied from the parent branch at the time of branching.
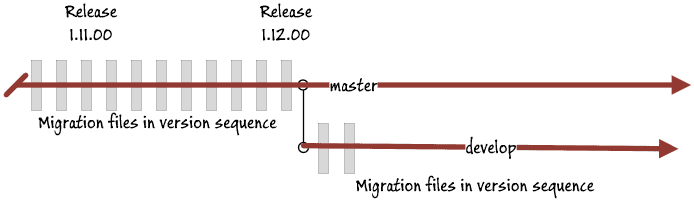
Each grey bar represents a migration file. Master represents the current release and is represented by one or more file directories. The sequence of migration files is there in the master branch. The developers are making progress and have done two commits since the release into the develop branch.
Hotfix branches
Oops! There is a bug with production that needs a hotfix, so we do a temporary hotfix branch from the current release.
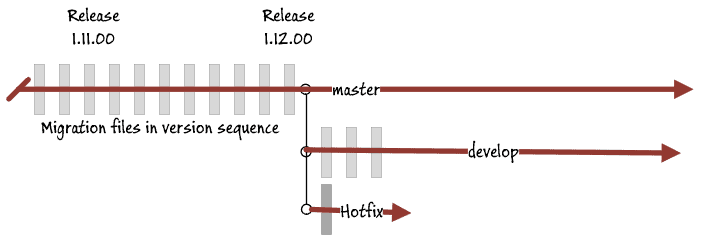
The developer works in the Hotfix branch, tests the migration and confirms that it works. The team then merges this hotfix file into master so that the hotfix can be applied to production, and closes the branch. The ops guys then apply the patch from the master which is then at a new version of 1.12.01
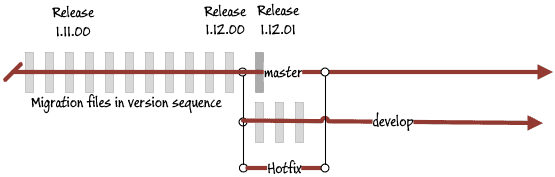
As the develop branch originated before the hotfix, 'Develop' now must pull this hotfix otherwise it is in danger of undoing the hotfix on the next release. The natural way is to insert the file into the beginning of the chain in develop. You may need to rename all the migration files in 'develop' if you haven't left gaps in the version sequence. This needs to be done as well in your version control system (see here for how to do it in Github). You must, of course, manually patch up the metadata table of the database as well to avoid any validation errors.
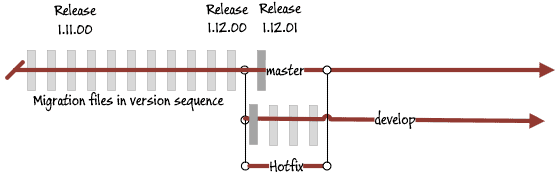
Even if you don't have to rename any files, Flyway will protest the next time you do a migration in develop, because it has no way of knowing the effect that the hotfix will have on any database updated by the altered chain of files. It could, in some circumstances, break what's been done. You can, of course, over-ride Flyway and insert it anyway, but you are still in the position of the develop branch originating from the previous release rather than the current one.
Here is where the advantage of Flyway kicks in. As long as it executes the hotfix against the develop database in the develop branch, it doesn't matter to Flyway. The worst that could go wrong is that there are no 'gaps' in the bug-fix part of the version number in the migration files for the 'develop' branch, so you have to re-name the subsequent migration files. Whatever you do, you must check that the hotfix has caused no consequential problems to the later files.
Feature and topic branches
Let's now look at a team development. You want each part of the development to have one or more people working on it. Fine. You also have a feature you've been working on for a while and the application teams have said they are at last ready for it. You have bug fixes, and performance work that delivers no new functionality but clears up some technical debt.
With Git, the teams are likely, then, to be working with different "topic branches" of the develop branch, with a topic branch for each aspect of development and only one or two developers to a topic branch. The important point is that a topic branch is not based on the developer or team but is dedicated to the feature being developed, with each developer pulling changes when necessary from other their peers in the team that are working on the topic branch. Ideally, each topic branch will have its own copy of the database, which prevents premature conflicts before they are finally ironed out at the time of merge.
You might get something like this, which may help you visualize the challenges with merges when using a migrations-approach to developing feature and topic branches:
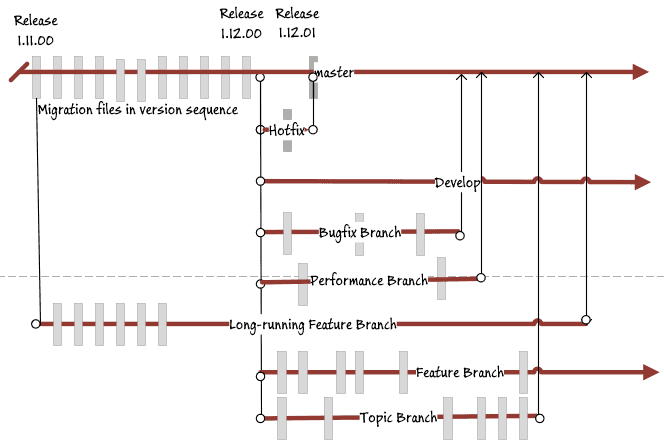
Now, imagine we are at the point where we applied the patch to master so we could upgrade production to 1.12.01 Not only have we a bugfix branch to merge, a performance branch, and a couple of topic branches, we also have a feature branch that was delayed from the last release.
All these migration files are going to have to be slotted into place in the develop branch. We must do this because we need to do a whole suite of integration tests before we can release. We then need to create a release branch that gets checked over, signed off and finally gets merged into master to represent the next release.
Even if you are working on entirely different branches, only the first team can merge their migration files into the develop branch without having to check, and possibly change, their version numbers in the filenames. Flyway will police any change in the sequence or content of pending files in its directory by maintaining a list of files already executed and of those pending, all of which have checksums. If it detects an insertion into the list of pending files rather than an appending to the end of it, Flyway will complain, for reasons described earlier.
You might think that you can get around this by allocating each team a range of version numbers so they can merge these into the develop branch, doing a Flyway repair to stop it nagging. This is the "predicted version" model that I described earlier. The trouble is that you cannot predict when a feature branch is going to be made live. It might be delayed or pulled forward. By giving each feature branch a non-conflicting sequence, you doom them to be merged in that order come what may. The chances of guessing the correct sequence of the migrations when your feature finally makes it to release is negligible.
After looking at this diagram for a while, you will suddenly realize why spiders don't use teams of spiders to build webs. With a whole lot of dependencies, you just can't do it.
A different way to do branching and merging with Flyway
To get past these problems, I propose that we change the rules a bit. Why not postpone, until the merge the creation of the migration file that will pass to the 'develop' branch? You are likely to have to work on conflicts whichever way you do it.
In each branch, rather than saving your work in versioned scripts, you simply save the latest 'state' of each object, in the way the developers prefer, via a build script, object-level script, or your own branch-specific migration scripts. A merge to 'develop' then consists of a migration script as a deliverable which has a version number that specifies its position at the current end of the sequence of delivered and unit-tested code. If you use Flyway for a branch, the resulting files are rolled up into a single migration from the current state of the 'develop' branch to the next but beware: the 'develop' branch database will probably have changed from the point of the branch and possibly introduced a conflict.
SQL Clone makes it much easier to provision copies for each branch. You can work on a topic branch and then use SQL Compare to run a comparison with the topic branch database as the source and a clone of the current develop branch as the target. This will give you a summary list of all the changes, and a first-cut migration script.
Because you see the differences, you can more easily see where the potential conflicts will be. Because this merge might also span a release, as it does in our final diagram, you might also benefit from doing a comparison of the database as it was at the time of the branch and the 'target' database. This will tell you what's changed. If you filter for code that your branched code alters or relies on, this will flag any major potential conflicts.
SQL Compare will also warn you of any changes that mean that data won't be preserved, unless you add extra code to the migration script. You can develop and test this extra data migration code across into SQL Compare's migration file
Exploring changes at the object level
I believe that a team should consider what benefits they need from a source control over and above merely archiving code safely. We need to be able to track changes over time to individual database objects such as tables. We need to see who has done what, and when. We need to be able to compare releases to see what has changed. When we do a Flyway development, we can get a lot from migration files, especially if each migration file deals with a particular feature or aspect. However, we don't hit all our objectives unless we also save object-level creation scripts.
In theory, if Flyway uses only a chain of immutable files to build a database and checks the integrity of all the files before it allows a migration, then it doesn't need a source control system. Migration files, for example, don't change and don't require 'differencing'. However, it is too simple to subvert this simple migration model by using 'repair' and 'clean', as well as by configuration changes.
To also save object-level scripts and build scripts, you'd need an automated system that does it for you. I've provided this for SQL Server in a series of articles. You would need to commit the generated scripts to source control committing it on every merge. If these are in source control you get from Git the information on who changed what and when. You also get changes between releases. With an object level directory, you can get SQL Compare to generate migration scripts between two of them, or between the current database and a version of the scripts directory.
Summary
Flyway is excellent for team-based developments using DevOps practices because it can help to provide a system that is resilient, secure, repeatable, quick and visible. It does just one thing and does it well. In tandem with other tools, it can be a much less confusing system than a 'static' system based only on changing source code files, because it emphasizes the need to be able to upgrade a system while preserving the data. With help from other tools such as SQL Compare, it allows you to exploit to the full the resilience of Git, and especially with branching and merging.
Tools in this post
You may also like

Article
Running SQL Clone on an Azure VM with Azure File Storage
How to use SQL Clone in the Azure Cloud, installing it on an Azure Virtual Machine, storing a copy of your SQL Server database as an 'image' on an Azure File Share, and then deploying multiple clones to another Azure VM or to a remote machine.

Article
Redgate's support for Azure SQL Database Managed Instances
Today Microsoft released the public preview of Azure SQL Database Managed Instances – an exciting new option for running SQL Server workloads in the cloud. I’m pleased to say that initial support for this new offering is already available across the development tools in Redgate’s SQL Toolbelt, as well as in Redgate Monitor. This support will continue to improve as the platform evolves throughout its public preview. What are Managed Instances? Managed Instances (or Azure SQL Database Managed Instances, to give them the long name) are a new PaaS database offering, joining the Azure SQL Database and Elastic Pool services.
Article
Introduction to Analyzing Waits using Redgate Monitor
Phil Factor sets out with the modest aim of giving you enough of an introduction to waits to better understand the wait information you get from a SQL Server monitoring tool like Redgate Monitor, and the rather overwhelming amount of information available in the underlying DMVs and Extended Events.

Article
Flyway 7.1.0 Released
Flyway 7.1.0 is out! This release contains new features and improvements over Flyway 7.0.0. Highlights You can find a detailed list of the changes in the release notes. Filtering info output Flyway Teams In the Flyway CLI output from info can be filtered to only the parts of the history that you care about using the following 4 parameters, or a combination thereof: Example: > flyway info -infoSinceDate="01/12/2020 13:00" See the documentation for more details. Configuring lock retries Sometimes you may want multiple instances of Flyway to run, each executing potentially very long lived migrations. Flyway will ensure only a single instance executes at once, but

Article
Building a Database with Flyway
Flyway, especially Flyway Teams edition, can be used in several different ways to accommodate a database development that was originally based on builds rather than migrations. This article explores four different ways to use Flyway to build a particular version of a database, from the ground up, using a single migration script. It should help teams select the best way to incorporate Flyway into an existing database build system, during development, while benefitting from use of Flyway's versioned migration system for deployments and releases.
Article
A Programmer's Guide to Flyway Configuration
Phil Factor offers a programmer's guide to Flyway's configuration settings, explaining the different categories of parameters, the role of each of parameter within each category, and how to exploit Flyway's multi-level configuration file system.
Loading comments...