





Basic Functional Testing for Databases Using Flyway
This article is part of a series on the requirements and practicalities of database testing, with Flyway:
- Testing Databases: What’s Required?
- Planning a Database Testing Strategy for Flyway
- Test-Driven Development for Flyway Using Transactions
- Basic Functional Testing for Databases using Flyway
- Running Unit and Integration Tests during Flyway Migrations
- Performance Testing Databases with Flyway and PowerShell
- Running Structured Database Tests in Flyway
- Running Database Assertion Tests with Flyway
Also relevant are the series of related articles on Test Data Management.
A test-first approach to database development
Imagine it. You do a Flyway migration run to bring a database to a particular version. Immediately, like a well-oiled machine, it checks the basic functions of the database and lets you know of any obvious problems, maybe even rolls back the migration if any of the tests fail. Good Test-Driven Development (TDD), eh? Database testing is essential but if you depend on doing it manually, you'll end up only doing the interesting tests, or the ones that you think are the most essential. Fate often decrees that the most insidious bugs are revealed by commonplace boring routine tests, and these are the ones to automate.
In this article I'll demonstrate how we can use Flyway, with a few simple additions, to introduce the 'routine' unit and integration tests, the ones the verify that all parts of your database code, and every process, continue to function correctly, as you make changes. These sorts of tests are the minimum requirement for any professional database development. With the principal features in place, subsequent articles in the series will demonstrate a more realistic test-driven migration, using different RDBMSs.
Building datasets for testing
Firstly, why generate datasets for testing when you have the real thing? For someone coming fresh to development work, it may seem an obvious strategy to take a copy of all the existing data of a production database and use that to test an updated database.
While there are advantages to having test data that mimics the volume, characteristics and distribution of the real thing, there are some drawbacks too, for certain types of test. Even if the data contains no personal information, or sensitive financial information, it is likely to perpetuate existing bugs where existing data has been changed to avoid triggering a known bug such as a data overflow. It also doesn't allow us to check that our code still responds correctly when it encounters 'edge cases' such as names like Mr Null, Hubert Blaine Wolfeschlegelsteinhausenbergerdorff Sr, or Mrs O'Brien.
For testing financial processes, I believe that the correct way, which certainly has served me well, is to work with the organization to agree on the correct results for a standard set of inputs. For example, when implementing a database-driven purchase process, we would create an input, such as a list of purchases, and then agree with the business on the values that it would expect to see in all the ledgers, shipping notes, invoices and delivery notes, at the end of the process. Your tests then need to prove that, for your test inputs, you always get the expected results.
Test datasets should be generated and then loaded into a newly built database, at the correct version. These datasets should be reused and amended as necessary as the database develops, not regenerated, because many tests will rely on checking the output from a process for a particular dataset. It is relatively easy to import a dataset, split tables and alter or add columns, with the data in-situ, and then export the result as the dataset for the new version. Datasets are usually valid for a range of versions.
Generating the test datasets
SQL Data Generator was created for just this sort of work. Although it impresses people when they see it "auto-magically" fill a database with data, its real use is slightly more mundane: it creates datasets. You can use all sorts of tricks for generating realistic text here, as I demonstrated in How to Complain Bitterly using SQL Data Generator and in Spoofing Data Convincingly: Text Data. In Getting your SQL Server Development Data in Three Easy Steps, I explained some of the ways that I generated the titles of the books and the notes about them for the Pubs sample database.
You may think that it is trivially easy to do this, but the hard part is to generate all the keys so that the relationships are right and to generate data that conform to existing constraints.
Loading the test datasets
For general use with relational database systems, I first build datasets in SQL Server and from this original SQL Server target database, I create generic scripts that use SQL92 standard INSERT statements. These scripts use standard SQL that can then be used by most RDBMSs. I've demonstrated this technique in my article, Adding Test Data to Databases During Flyway Migrations, which uses SQL Data Generator to generate the test dataset and then SQL Data Compare to produce an INSERT script that Flyway can use to load the data during a migration. While this works well for smaller datasets, for larger volumes, it will be much faster to bulk-load the data that is appropriate to the database version, once the migration run is finished. with SQL Server, for example, Bulk Loading Data via a PowerShell Script in Flyway demonstrates by far the quickest approach.
Development Testing
There are many shades of opinion on the type of testing that need to be done for the database in the development branch. I prefer to start with the broad sweep of 'black-box' tests that cover all the vital processes, rather than with clever, targeted, precision tests.
Your development team will, hopefully, deliver a unit test for every significant table source (view/table/procedure/table-valued function) that can be used, and there will be integration tests that are added on every development cycle. Every added feature, as it is introduced, will have 'test coverage' provided by an appropriate associated test. As well as running these, we re-run the integration tests. This may seem unnecessary, but things can, and do go wrong. I've sometimes had a basic test suddenly fail unexpectedly. On one occasion I had to sit down for a while to think through what would have happened had the bug gotten through to production. 'How the heck did that happen?' one thinks. In databases, everything is related. Someone, in the example I remember, had tidied up the datatypes in a function that introduced a rounding error in summing up currency in a well-established part of the application. Moral. Assume that the 'build' will fail in unexpected ways.
Testing with Flyway
I like the technique of having a single test directory of scripts where each test file will indicate in its filename the range of database versions for which it is appropriate. Most tests can run on a range of versions, and I tend to make them project-based rather than branch-based. I run them within my Flyway Teamwork framework, but you can easily impose your own structure on these tests.
The first, and most important information you need, is the version of the database. If you are running your tests on every migration, then this will be the version that the migration run produces. When a migration run completes, we run a PowerShell script that automatically gets the latest version number and then uses it to search within the Tests directory and run any tests that, according to the version number range in their filenames, are relevant for the new database version. In this article, I'll just run that PowerShell script in the IDE, but in Running Unit and Integration Tests during Flyway Migrations I'll show how to use it as a afterVersioned callback script so that the tests run automatically on every migration run.
This technique allows you plenty of versatility. You can always add a special Tests directory in a branch or a variant. Flyway Teamwork will find this first and use it rather than the project version. You can even run both. This would allow you to have just one pool of tests for the development test run, and possibly one for each branch.
The tests themselves, whether unit or integration tests, will spend a lot of time comparing data. Often, a test will need to confirm that the resultset derived from running the process or report on the database matches the expected results (those agreed with the business), saved on disk. My approach is to save both the actual and expected resultsets as JSON documents and then use PowerShell to tell us whether the two resultsets are the same. It's nice to know how they varied, but at a certain point you're debugging rather than testing, so you'll used the specialized tool for that where possible or use SQL.
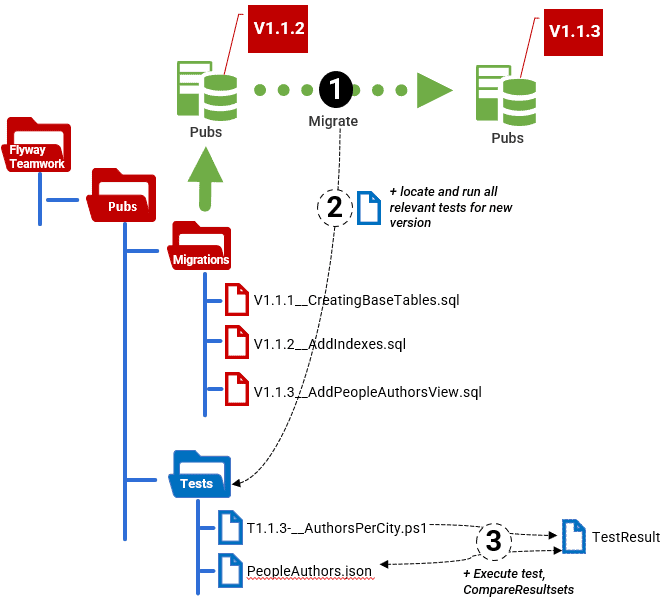
The simplest tests can be boiled down to a SQL Query to produce the test results, and a file containing a JSON document representing what the result should be. In this article, I'll just provide a generic way to compare the test result to the correct result and report differences.
Of course, it is likely that you'll soon want to make it more complicated than that, maybe with several batches and with separate sections for setup, execution, validation and cleanup. Each test should leave the database unchanged, by using temporary tables, for example or by doing mopping-up even after a SQL error. I'll cover all this in later articles.
Creating the test
In this first example, the test itself is as simple as it gets. We want to ensure that the people.authors view is generating the correct results. Here is the existing view:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
CREATE VIEW People.authors
AS
SELECT Replace (Address.LegacyIdentifier, 'au-', '') AS au_id,
LastName AS au_lname, FirstName AS au_fname, DiallingNumber AS phone,
Coalesce (AddressLine1, '') + Coalesce (' ' + AddressLine2, '') AS address,
City, Region AS state, PostalCode AS zip
FROM People.Person
INNER JOIN People.Abode
ON Abode.Person_id = Person.person_ID
INNER JOIN People.Address
ON Address.Address_ID = Abode.Address_id
LEFT OUTER JOIN People.Phone
ON Phone.Person_id = Person.person_ID
WHERE People.Abode.End_date IS NULL
AND phone.End_date IS null
AND Person.LegacyIdentifier LIKE 'au-%';
go
|
The test merely runs a reporting query on the PeopleAuthors view and saves the test results in JSON so that we can compare it to the expected result, which I've saved in a PeopleAuthors.json file, in the Tests directory.
The easiest way to do this is to compare save the actual and expected results as ordered JSON documents and then compare them. You can do this where there is no unique key field specified. You merely iterate through the "test result" JSON document and compare each row with the corresponding row in the "correct results JSON document. The trouble is that this sort of comparison can only tell you if the two results are the same, or different, but no more. A missing row will seem as if the whole of the rest of the result is wrong.
A better approach, and the one I use here, is to provide the name of a unique key column ($TheKeyField) that PowerShell can then use to work out what rows are different, added or missing. I provide a function that does this comparison for you, either way, called Compare-Resultsets. This will check two objects that are converted into PowerShell from JSON resultset from SQL Expressions. Each element (row) in the array has the same keys (columns).
If you want to try this out, you can get everything you need from my FlywayTeamwork-Pubs GitHub project. The migration files and test files you need are in the Develop branch of the Pubs database. You'll need to migrate your copy of the Pubs database to at least V1.1.0, which is the version that introduces this view. You can then run this in the IDE, to try it out, assuming you're in the correct working directory and you've executed the preliminary.ps1 file first.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<#
cd <MyPathTo…>\Pubs\Branches\develop
. '.\preliminary.ps1'
Write-Output @"
Processing the $($dbDetails.variant) variant of $($dbDetails.branch) branch of the $($dbDetails.project) project using $($dbDetails.database) database on $($dbDetails.server) server with user $($dbDetails.installedBy)"
"@
#>
#We provide the name of the test file with the correct result in it.
if ($MyInvocation.MyCommand.Path -ne $null)
{
$Test1="$(Split-Path $MyInvocation.MyCommand.Path -Parent)\PeopleAuthors.json"
}
else
{
$Test1="$($dbdetails.TestsLocations[0])\PeopleAuthors.json"
}
# the SQL is SQL Server specific.
# For other RDBMSs, you need to tweak the SQL.
# to execute raw queries. I'd stick to running JSON
# To get json from SQLCMD, the query needs the FOR JSON clause but
# is then modified, so leave out the terminating semicolon!
$TheSQL=@'
SELECT city, Count (*) AS authors
FROM people.authors
GROUP BY city
ORDER BY authors DESC,city
FOR JSON AUTO
'@
$TheKeyField='city'
if (-not(Test-Path $Test1))
# normally, we'd error out at this point because the correct result has to be
# created and checked before we implement the object that we are teasting
# but here we are merely demonstrating the plumbing of the system so we will
# create a result that passes. We can always edit it to see what happens
{ #create it first time around
execute-sql $dbDetails $TheSQL >"$Test1"
} #check that it actually exists in the test directory
$correctResult=convertFrom-JSON ([IO.File]::ReadAllText($Test1))
# now get the result from the database under test
# This returns JSON.
$TestResult=execute-sql $dbDetails $TheSQL |convertFrom-JSON
#we now report any differences
compare-Resultsets -TestResult $TestResult -CorrectResult $correctResult -KeyField $TheKeyField
|
I've engineered an error, by editing the PeopleAuthors.json result a bit, just to demonstrate what would happen. In a real database, we'd ask the user representative to provide a manual summary for us to check against. Here is the result. It has detected the errors.
We checked 96 records and only 95 of them were the same
extra test row {"city":"Colorado","authors":26} not in correct result
for row with the city 'Fort Wayne', the values for the authors column, 26 and 25 don't match
missing record {"city":"Coloralo","authors":26}
If we want to run this test automatically, as part of a flyway migration run, we must save it in the Tests directory with a specially formatted filename. The filename must start with letter T, followed by the earliest version for which the test is applicable, followed by the dash ('-') character, followed by the latest version, followed by a double underscore and then a description what the test does (which we can use to label the results correctly).
The earliest and latest versions can both be blank. In this example, I've called the file T1.1.10-__Authors_Per_City.ps1, which means it's valid for any version from 1.1.10 onwards. We would add an end-version number after the '-' character. If I'd called it T-__AuthorsPerCity.ps1, it would mean it was valid for any version.
Running the tests
All we need to do now is to make sure that this test, and every other valid test in the Tests directory (there is only one test right now), runs on every Flyway migration. It gets the version number of the newly migrated database, locates the Tests directory and runs all tests where the version range specified in its filename includes the version under test (1.1.10, in this example).
This code is intended to be run in the IDE or as a separate script.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
# test this on SQL Server
cd S:\work\Github\FlywayTeamwork\Pubs\Branches\Develop
. '.\preliminary.ps1'
Process-FlywayTasks $DBDetails $GetCurrentVersion
#report on exactly who and on what and where
Write-Output @"
$($Env:USERNAME) Testing the $($dbDetails.variant) variant of $($dbDetails.branch) branch
of the $($dbDetails.RDBMS) $($dbDetails.project) project using $($dbDetails.database) database
on $($dbDetails.server) server with user $($dbDetails.installedBy)"
"@
#firstly we make sure that this version of 'preliminary.ps1' is not an old one
if ($dbDetails.TestsLocations -eq $null)
{ Throw "Please upgrade the Preliminary.ps1 to the latest version" }
#double-check that the version is properly in place. We're going to need that
if ([string]::IsNullOrEmpty($DBDetails.Version))
{ Process-FlywayTasks $DBDetails $GetCurrentVersion }
#now we just scoop up all the test files that are relevant, collect their information and execute them
Dir "$($dbDetails.TestsLocations[0])\T*.ps1" |
foreach{
if ($_.Name -cmatch '\A(?m:^)T(?<StartVersion>.*)-(?<EndVersion>.*)__(?<Description>.*)\.ps1\z')
{
@{
#turn blank strings into nulls so we can process underfined starts and ends properly
'StartVersion' = switch ($matches.StartVersion) { ''{ $null }
Default { $_ } };
'EndVersion' = switch ($matches.EndVersion) { ''{ $null }
Default { $_ } };
'Description' = $matches.Description;
'Filename' = $matches.0;
}
}
else
{ throw "could not parse $_.Name" }
} |
where {
[version]$DBDetails.version -ge ($_.StartVersion, [version]'0.0.0.0' -ne $null)[0] -and
[version]$DBDetails.version -lt ($_.EndVersion, [version]'999.0.0.0' -ne $null)[0]
} | foreach {
"executing $($_.Filename) ($($_.Description))"
# now we execute it
. "$($dbDetails.TestsLocations[0])\$($_.Filename)"
}
|
Of course, Flyway provides the means of running a PowerShell script like this one (or a Bash or DOS script), automatically, as a callback script. It wouldn't need the 'hardwired' specification of the working directory because Flyway would execute the callback in the right place anyway.
We would add this callback file (e.g., afterVersioned__RunTests.ps1) to the to the migrations directory, for the development branch. This would ensure that you execute a test run every time there is a version change, including when performing a merge, which is where you're likely to want it the most.
I've not used it as a callback in this article because, I'll be introducing a better design in another article, where the above code forms the basis of a cmdlet that I've added to the Flyway Teamwork framework, and the callback script is, as a result, much shorter and simpler. The new design will also allow you, if you need to, to execute code in several test directories in parent branches so that you can execute all the tests associated with the development database.
Summary
It is quite common to find developers who seem surprised that it is part of their role to test the database. Sure, in my experience they will usually perform some informal tests, but it is a pleasant surprise to come across a good database test strategy. I spent a lot of my professional career working alongside specialist testers, who were often exceptional developers who happened to get their kicks from breaking things. As a developer, I was always determined to avoid the possibility of hearing whoops of joy from the "Test Cell", because managers are often skeptical of my reasonable argument that the greater a developer's productivity, the greater the chance of them introducing a bug.
In truth, a test team merely double-checks, on the behalf of higher management, that the release candidate is bug free and meets the specifications set by the users or clients. They try to find aspects of the database without test coverage via exploratory testing. They don't do, and shouldn't do, development testing or debugging. That's a development task.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Handling multiple schemas in the same database with Flyway
We’ve had some users ask recently about multi-schema deployments. There are a number of possible scenarios, some of which are supported naturally by Flyway and some not. This blog post summarises the current state of play on the matter, but we’re keen to make sure we cover popular use cases. If you have any feedback for us, there’s an ongoing discussion on Github Issues. Configuration There are two main configuration parameters: flyway.schemas and flyway.defaultSchema. In this post we’ll talk about them as being in flyway.conf, but of course the same will apply whether you choose to use them in configuration files, environment variables, the Java
Article
New Flyway Migration Report
As of version 9.17 of Flyway when running flyway migrate or flyway info a new report.html report will be written to your current folder. The migration report is designed to provide confidence that a Flyway deployment has run as expected, and in the case that it hasn’t, provides the necessary detail to help understand and troubleshoot the issue. … Read more in the full post on the Flyway documentation site
Article
The Flyway Migrate Command Explained Simply
The 'Migrate' command automates the process of applying the database schema changes that are defined in migration scripts, while Flyway tracks the version of every copy of the database. This makes it much easier to maintain consistency across different database environments, and so facilitates continuous integration, continuous deployment, and database version control practices.
Article
Flyway and SSDT: Extracting a DACPAC from a Flyway-managed Database
When you are integrating Flyway into an existing SQL Server SSDT development, you don't necessarily have to change everything at once. The development team might continue to use the SSDT tools, but Flyway will soon take over the deployments. This means that any automated processes will need to be able to handle both DACPACs and Flyway migration scripts with equal grace. In this article, I'll demonstrate how to automatically extract a versioned DACPAC from each new Flyway version of a database.
Article
Introducing the shouldExecute script configuration option
Have you ever wanted more customizable control over when your migrations are executed? In Flyway Teams Edition 7.3.0 we released the shouldExecute script configuration option which lets you achieve just that! What is the shouldExecute option? shouldExecute is a new script configuration option, and if you aren’t already familiar with this concept you can read about it here. With this new option, you gain the power to easily customize when a migration should execute. Unlike skipExecutingMigrations, this will not update the schema history table. In order to use this option, you first have to create a script configuration file which contains the line: expression must evaluate to a
Article
Bulk Loading Data via a PowerShell Script in Flyway
The test data management strategy for any RDBMS needs to include a fast, automated way of allowing developers to "build-and-fill" multiple copies of any version of the database, for ad-hoc or automated testing. The technique presented in this article uses a baseline migration script to create the empty database at the required version, which then triggers a PowerShell callback script that bulk loads in the right version of the data.
Loading comments...