





Monitoring your database schemas with pipelines
DLM Dashboard tracks changes to your database schemas across different environments. In this blog post, we’ll talk about organizing your databases into pipelines, and how this can help you to better understand your workflow.
How was it organized before?
Grouping databases by category
In the first version of DLM Dashboard, databases were grouped by category - or environment - to distinguish stages in the workflow from development to production. For example:

Grouping databases by server
In the next version, you could group databases by their parent server. Many users had a different server for each environment, so it made sense to keep their production servers separate:

What could we improve?
Grouping by category or server worked fine for users who were only tracking one or two database schemas. But what about users monitoring more than one application? When they added more databases, DLM Dashboard grouped database schemas from different applications together. The workflow wasn’t clear, and it wasn’t easy to see which changes were moving from development to production. We knew we could do better.
Grouping databases by pipeline
We started developing a new version of DLM Dashboard that would group databases into pipelines according to their schemas. By grouping databases that share similar schemas, it’s easy to track schema changes as they progress through the stages of your database’s lifecycle.
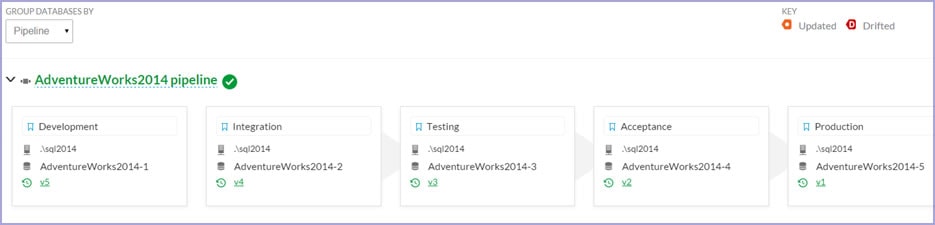
How does it work under the hood?
DLM Dashboard compares the schemas being monitored and groups those with similar database structures into pipelines. This calculation is based on a distance measurement between the two databases: the more differences there are between two database schemas, the further the distance between them.
For example, look at the FinanceDev and FinanceProd databases below. They use Database/Table/Column to define the objects present in the database schema.

The databases aren’t equal but they’re similar, so they’re grouped into a single pipeline named Finance. The distance between them is small.
Say that we then start to monitor another database, EmployeesProd:

EmployeesProd is placed in its own pipeline (called EmployeesProd) because it’s not similar enough to be grouped with FinanceDev or FinanceProd.
What do users think of pipelines?
We added in-app feedback along with this new feature, to find out how accurately DLM Dashboard groups different users’ databases.
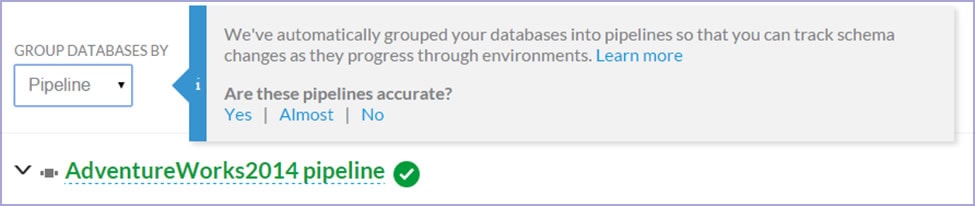
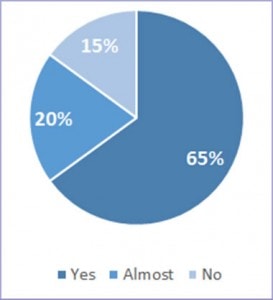
The questionnaire has been live for five weeks and, with over 600 responses, the results have been largely positive:
What’s next?
The team are now exploring ways to make pipelines even better. We've already added the ability to apply a filter to the databases in a pipeline, so you can define what drift means to you, and ignore changes you're not interested in. We’re currently working on support for manually configured pipelines, so you can control exactly how your database schemas are grouped.
Comments or questions? We’d love to hear from you. Please send your feedback to dlmdashboardsupport@red-gate.com
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like
Article
Dealing with production database drift
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies, this article shares some of our thoughts about how to deal with production database drift. If you’re using automated deployment for your databases, direct changes to your production environment can cause a headache. These unmanaged changes are known as database drift. To better understand the issues this can cause, our team created a test application we could work with; this was a
Article
How to get Slack alerts when your database schemas change with Slack and DLM Dashboard
Setting the scene In my last post, I explained how it’s possible to integrate DLM Dashboard with just about every service you use at work. Now that’s all very good in principal, but how do you actually go about configuring DLM Dashboard to trigger an automated task in another app or service? In this post, I’ll show how you by connecting DLM Dashboard to Slack in order to send team IM alerts when unexpected database changes occur. Why Slack? While DLM Dashboard’s email notifications are really versatile, if you’re anything like me, you don’t necessarily spend all day in your
Article
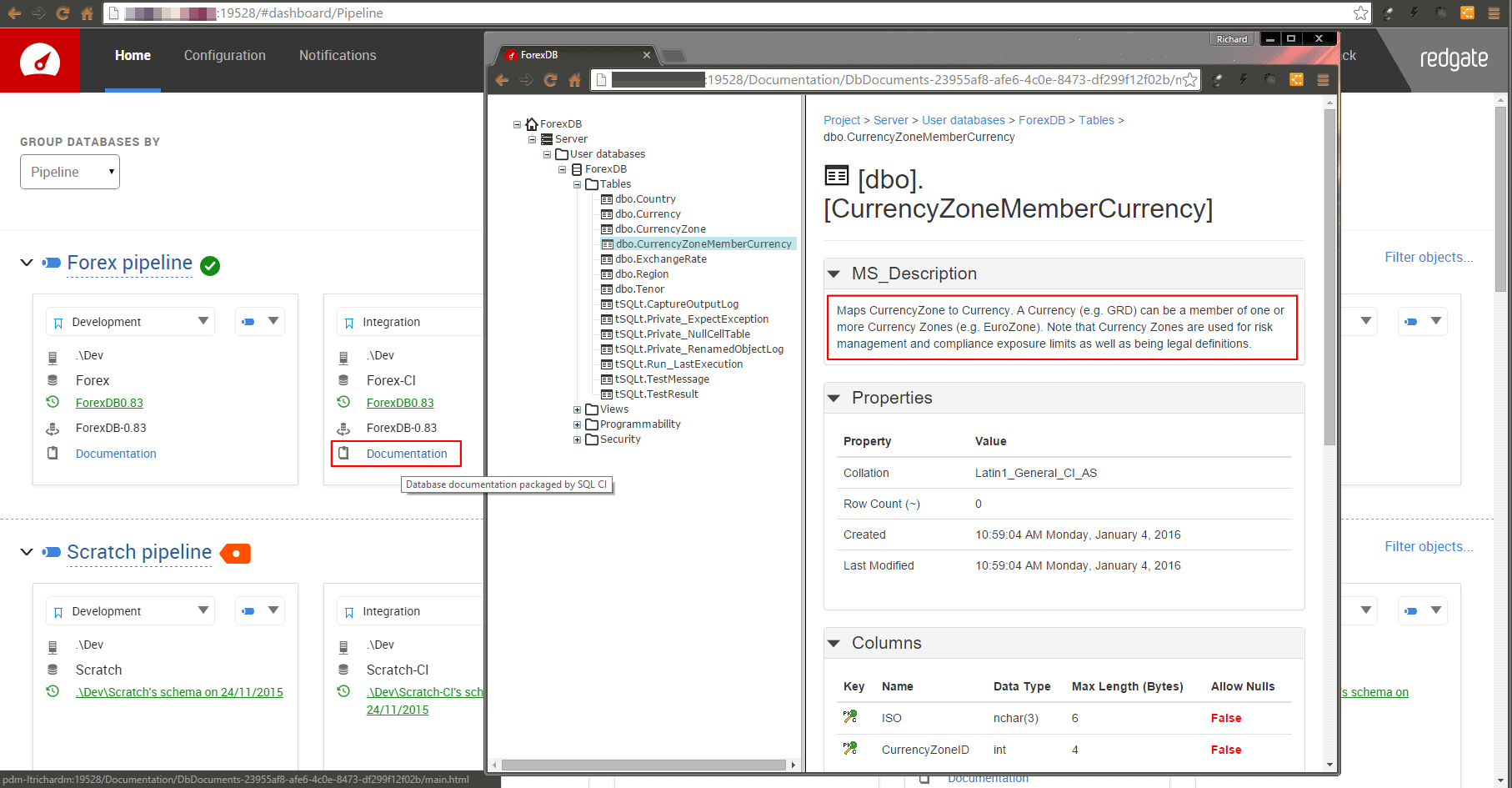
We don't need no documentation - automating schema docs in SQL Change Automation
“Understanding the existing product consumes roughly 30 percent of the total maintenance time.” Facts and Fallacies of Software Engineering by Robert L. Glass. You should be documenting your database schema. I know it, you know it. Having current, accurate documentation available accelerates time-to-resolution for faults, aids tech-to-business conversations, and is a regulatory requirement for a great number of firms. Yet a majority of 214 respondent to our survey admitted that while they didn’t always have up-to-date docs, they knew they should. Do you work in a US-listed organization? Sarbanes-Oxley (SOX) clearly requires up-to-date documentation on where the financial data resides within your firm and how it’s
Article
Monitoring your database schemas with pipelines
DLM Dashboard tracks changes to your database schemas across different environments. In this blog post, we’ll talk about organizing your databases into pipelines, and how this can help you to better understand your workflow. How was it organized before? Grouping databases by category In the first version of DLM Dashboard, databases were grouped by category – or environment – to distinguish stages in the workflow from development to production. For example: Grouping databases by server In the next version, you could group databases by their parent server. Many users had a different server for each environment, so it made sense
Loading comments...