





How We Ate Our Own Dog Food To Level-Up Internal Testing with Redgate Clone
![]() Most applications have large and complex databases at the back end, making it hard for developers to adequately test their work before it goes out. Having a fast, repeatable process to deliver data on demand is an essential part of an effective software development lifecycle, ultimately leading to improved customer satisfaction. In this article, we’ll explore the journey our own engineering team went on to leverage our own tool, Redgate Clone, to spin up short-lived database instances in containers for automated testing.
Most applications have large and complex databases at the back end, making it hard for developers to adequately test their work before it goes out. Having a fast, repeatable process to deliver data on demand is an essential part of an effective software development lifecycle, ultimately leading to improved customer satisfaction. In this article, we’ll explore the journey our own engineering team went on to leverage our own tool, Redgate Clone, to spin up short-lived database instances in containers for automated testing.
By shifting left, we’ve levelled up our testing process, boosting deployment success rates. Being able to spin up full-size database instances as part of our CI pipeline gave us feedback within minutes on whether our changes would be successful when deployed for real. This allowed us to break free from the constraints of shared database environments, using ephemeral dev and test databases that can be spun up and torn down in seconds.
Adapting internal practices for improvement
I’m going to talk you through how we used the Redgate Clone technology internally to improve our own development experience in developing Flyway, the popular database migrations tool, and how it improved the speed and reliability of our build pipelines.
For context, Flyway contains a mixture of database-agnostic layers, and database-specific sub-systems. It offers general support for 20+ database flavors and enables richer development workflows for databases supported by the Redgate Compare technology, currently SQL Server, Oracle, and PostgreSQL, with MySQL in preview.
We have a raft of automated tests and need to test the application against real databases, as well as more intensively testing database-specific behavior. We may need to develop features like static data support against specific databases, for example, with a lot of manual testing and iteration. And we certainly need to be responsive if any issue comes in against a specific database, attempting to reproduce the issue locally, before getting a fix out.
Realizing the need for change
We used to run our automated tests on every branch, using self-hosted build agents with Vagrant installed. When we needed a simple database, we’d use Vagrant to create a Virtual Machine with an empty database and then run SQL to set up the test. Where we needed more complex databases and the tests were read-only, we had some shared self-hosted databases in a known state.
A lot of this was quite slow and resulted in flaky environments. Even fairly simple Vagrant test suites would take upwards of ten minutes with setup and tear down, and the shared database tests could perform badly if a lot of tests were run at once. All of this would slow down our builds in general: if too many build agents were taking a long time to run tasks, we’d have wait times for available agents.
We began switching over our build process to containers running on cloud agents. This had a bunch of positive implications, the primary ones being that they were not dependent on the infrastructure of the self-hosted build agents, and build server behavior could be easily replicated locally, while also not tying us down hard to a particular build server.
As part of this, we switched all our database tests to Redgate Clone. Simple tests clone an empty database, and more complex tests may clone an entire database image. We did this for Flyway Desktop well over a year ago, using the Redgate Clone CLI, and have been gradually moving across the complex sub-systems underneath.
As a result, we’ve seen huge improvements to both build performance and consistency. Part of the process improvement was due to the general switch to containerization rather than only Redgate Clone, but it was an important contributing factor.
This screenshot shows a real example of one set of integration tests run in our pipeline last week. It runs 17 relatively simple SQL Server integration tests:
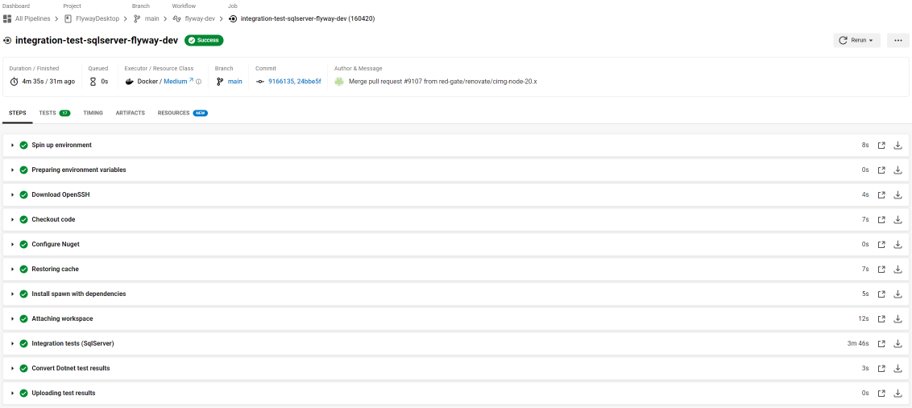
This test suite used to take over 10 minutes to run and the success rate for the old system wasn’t good. It now runs in about four minutes. In the last 90 days, it ran 344 times on main with a 99% success rate.
Automation provided many benefits for the team
A couple of years ago, all of our builds used to take around 40 minutes. Now most of our builds on branches run in about five minutes end-to-end, and this saves a lot of developer time. In general, a faster build helps the team work faster.
One obvious benefit is that developers are rarely stuck actively waiting on builds. We no longer come to merge a pull request (PR) or trigger a release and discover that part of a workflow needs rerunning because of flakiness. If we do hit an issue which is picked up by the build server tests, we can now easily run exactly the same test locally, without having to try and simulate the test using a local database.
New procedures encouraged good practice
It used to be tempting to batch work into a single PR because the overhead of generating a request and getting a green build made short PRs unappealing. Now with less disincentive, we can more easily adhere to short-lived branches. It also used to be a case of raising a PR, inviting a review, and then starting on the next piece of work on a new branch to avoid wasting time waiting for the build. With much faster builds, it’s more worthwhile getting a review and merging the work faster, reducing concurrent work in progress.
But Clone has had more internal benefits than just pipeline usage. As developers, we use databases every day for feature development and for support. In the past it was up to every developer to install all of the necessary databases locally. We favor the dedicated approach, with every developer having their own playground, but this does mean that there is an overhead in setting various databases up and keeping them working. It also means that replicating an environment or feature test setup from one machine on someone else’s machine can be a pain, because it is often fiddly to correctly expose local databases for access by other developers.
Breaking free from the constraints of shared database environments
We now have an internal service built around Redgate Clone which allows us to quickly spin up self-serve databases. We can easily add personal images for reuse as well. This allows us to quickly get hold of populated databases of various different flavors at a moment’s notice, with no need for local setup. These can also all be accessed by anyone at Redgate who is set up on the system so we can test using each other’s databases when necessary.
This is not a cure-all for all testing, as there are some scenarios such as various types of authentication which require more dedicated setups, but we are able to use this for the vast majority of our run-of-the-mill database activity.
This screenshot shows the UI for our internal service, which is just a convenience layer on top of some simple command lines:
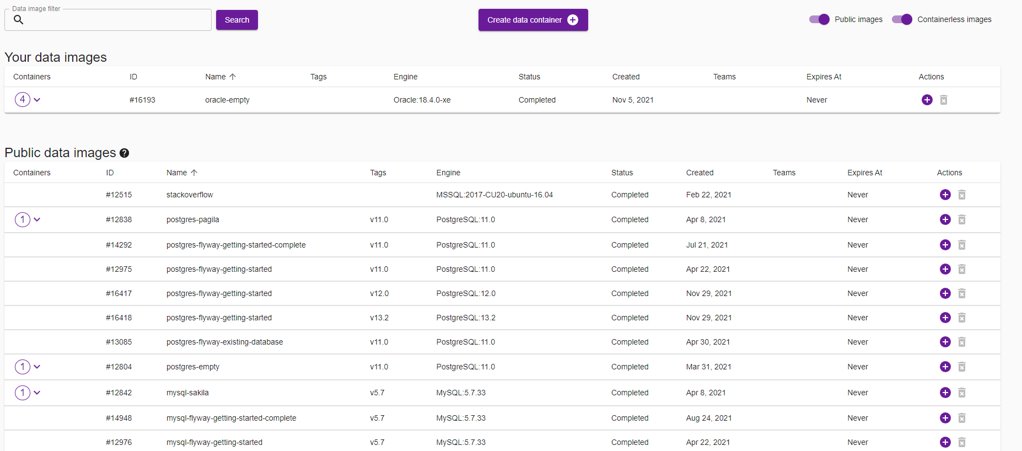
The same command lines which are used underneath this simple UI are being called during the test runs in our automated pipelines.
Circling back to the test run mentioned earlier, the following screenshot shows the detail and where the magic happens:
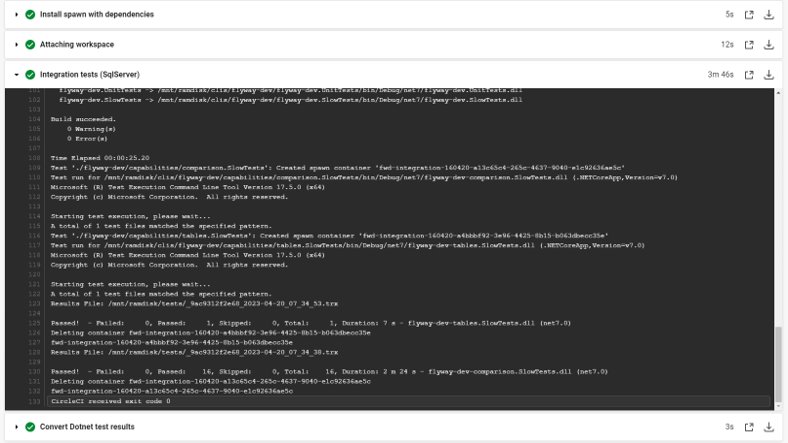
If we expand the detail of the main test run, we can see the output calls spinning up and tearing down database containers using Redgate Clone. This is done in our build script by calls to the Redgate Clone command line, making the whole process far easier and more streamlined than if were still using Vagrant or interacting with shared databases.
Want to learn more about database cloning? Check out our blog post on ‘7 ways businesses can improve the quality and speed of database releases’. You can also find out more about our cross-database tool, Redgate Clone.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Read next

Blog post
7 ways businesses can improve the quality and speed of database releases
The quality of database releases relies on thorough initial testing in development with teams needing access to fast, reliable data. While database testing is one of the most challenging aspects of development, processes which utilize database clones can overcome these issues. A database clone is a complete and fully functioning copy of a database that is identical to the original in terms of the metadata and the data. The big difference is that the clones are a fraction of the original size of the database, and so can be created and reset in seconds. Clones work by exploiting data virtualization

Blog post
Redgate opens the doors to cross-database DevOps Test Data Management
A constant challenge for many development teams is how to include test data management in the development process. Testing with consistent, realistic and compliant datasets, and bringing the database into CI and DevOps pipelines, has been shown to catch data-related issues long before they reach customers. The result: an increase in efficiency, a reduction in costs, and an improvement in the quality of software releases, enabling value to be released to customers faster. The problem, as Bloor points out in its guide to Test Data Management is that: “Operations is frequently seen as an obstacle to providing test data, while
Tools in this post
You may also like

Blog
To learn and improve, we cannot be afraid to fail

Blog
Why Organizations choose Flyway

Blog
Loading comments...