Why is my clone so small?
How is it possible that the cloned databases could be so small and lightweight, and yet behave exactly like any normal database, complete with all the data? It sounds like magic, but it's not. It simply makes clever use of native Windows virtualization technology.
If you have a very large database, up to 64TB in size, SQL Clone will let you copy, or ‘clone’, that database many times, very quickly, making the full database available in multiple SQL Server instances across your development and test environments. And yet in each of these instances, the cloned database takes up only a few tens of megabytes, and creating the clone takes seconds, rather than minutes or hours. How? Is a clone like a snapshot? Are we using some strange compression techniques? No, SQL Clone does all this using only of technologies built into Windows.
The heavy lifting of traditional database provisioning
All developers and testers would like to work with a database that is as close as possible to production, in terms of data volume and distribution. There are many advantages to being able to perform integration and acceptance testing with realistic production-like data, from as early as possible in the development cycle.
However, for databases of any size, this means copying a lot of bytes of data onto every development or test environment that needs a copy of the database. It also usually means a slow, manual process of restoring the latest backup of the production database onto each of the target SQL Server instances.
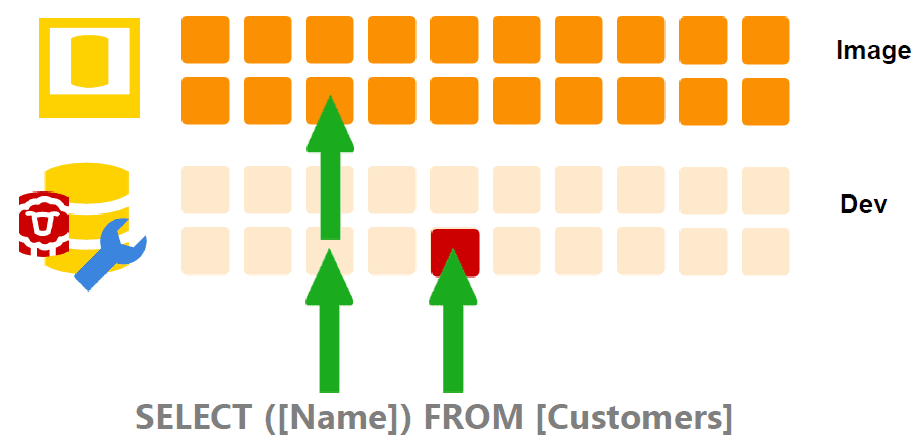
Figure 1 shows a 200GB production database that we’ve restored to both the QA and Development environments, therefore requiring 600GB of disk space in total. Each of the orange squares represents the same 10GB ‘block’ of data in the MDF and LDF files (the blocks in this diagram are purely conceptual). The red square represents data that has been modified in the QA environment.

Part of the problem is that we’re copying around the same bytes, unchanged, again and again. We might, in the QA environment for example, make a few changes to the data, to perform scenario testing. Likewise, in development we might make a few changes to get the data into a state where you can reproduce a bug. However, the rest of the data will be the same.
Database provisioning with SQL Clone
The simple answer to the question Why is a clone is so small? is that SQL Clone uses disk storage virtualization technologies, built into Windows, to remove the need to copy of all these same bytes onto each instance. Instead, SQL Clone works to ‘virtualize the data’ on each instance.
SQL Clone creates one full copy of all the data and metadata that makes up the source database. This is called an image. We copy the bytes only once. From this image, it can then create clones on each of the QA and Development SQL Server instances. Each clone has access to all those same bytes by reading from the image. The only data stored locally for each instance are data pages containing changes made directly to the local clone database.

In Figure 2, we have around 10GB of data changes in the QA clone, so that clone is roughly 10GB in size. Currently, there are no changes made to the Development clone, so it’s negligible in size. Of course, there is some overhead associated with managing clones, and there may be local changes made to the clone if, for example, SQL Server had to upgrade the database version to create the clone on that instance. However, it will still only a be few tens of MB in size.
In short, virtualizing the data allows us to reuse the data in the image in each clone rather than copying them around to every environment. This means we have a very lightweight way to create as many clones as we like, in as many SQL Server instances as we like.
Remember that the more local changes you make, the bigger the clone will grow. Each time you modify a row, the page containing that row is copied locally. If you decided to rebuild every index on the database, for example, this will result in copying a lot of data pages from the image file into the clone.
Working with clones
We can use a clone just like any normal database: we can read and modify data in the clone, perform standard operations such as database backup and restore, and so on.
How does this work though, if there is little, or no, data in the clone? In fact, it’s reading any changed data pages from the local clone and all other data pages from the remote image.
All of this is completely transparent to SQL Server; it just sees the full 200GB database. Ask SQL Server to perform a database backup of a clone, and it will perform just a normal database backup of all 200GB.
Under the covers, SQL Clone is using standard disk virtualization technologies to ‘trick’ SQL Server into thinking all the data is local. Let’s see how all this works in more detail.
How SQL Clone works
SQL Clone uses no bespoke technologies; it’s all done using the 64-bit virtualization technologies built into the Windows operating system. The image is just a Virtual Hard Disk (VHD) mount point, which holds the copies of the MDF and LDF files from the source database. For each clone, we have a differencing disk and then create a mount point, using virtualization technology, allowing us to access those same bytes from the image.
1. SQL Clone makes an image
This is the time-consuming, byte copying stage of the operation, but it only needs to be performed once. When SQL Clone creates an image of a source database, it creates a point-in-time copy of the MDF and LDF files, which is isolated from the source database.
It can create an image either from a live database, or from a full database backup. Please refer to the referenced articles for details of creating the image by either technique; here, we focus more on the underlying technology that makes SQL Clone work.
Logically, we can break down the process of creating an image into 2 steps:
- Creating a Virtual Hard Disk (VHD) – using the Windows Virtual Hard Disk Service
- Copying the database MDF and LDF files into that VHD
- Using the Windows Volume Shadow Copy Service if creating the image from a database
- Using native SQL Server backup and restore or Redgate SQL Backup, if creating the image from a backup
2. SQL Clone creates the VHD
A Virtual Hard Disk (VHD) is a file, of .VHD format, which acts like a physical hard disk, and can host native file systems and support standard disk and file operations. A VHD is often used as the hard disk of a Virtual Machine.
SQL Clone uses the Windows Virtual Hard Disk Service to create the Image VHD, which is initially empty.

SQL Clone creates a ‘mount point’ on the machine hosting the source database, basically a physical location on the local drive on which it mounts the root directory of another volume, in this case the empty Image VHD.
3. SQL Clone copies the database files into the VHD
In this step, SQL Clone needs to capture a transactionally-consistent, point-in-time image of the source database’s MDF and LDF files and copy them into the Image VHD created in the previous step. It’s important that SQL Clone does this in a way that causes minimal interference with SQL Server, and minimal disruption for other applications that are accessing the source database, while Clone is capturing a copy of it. It can capture the image either from a live database, or from a database full backup.
Database size limit
SQL Clone uses the original VHD format when creating images from source databases up to 1.8TB. To make images of databases up to 64TB, SQL Clone uses the newer VHDX format, which is compatible with Windows Server 2012/Windows 8 and above.
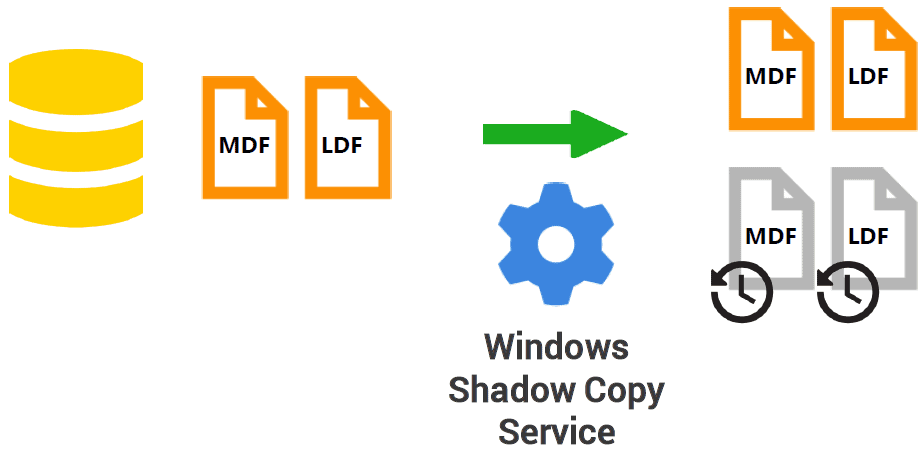
When capturing an image from a live database, SQL Clone uses the Windows Volume Shadow Copy Service (VSCS) to capture copies of the MDF and LDF files. This service is designed specifically to take backup copies or ‘snapshots’ of a file, even if another application, in this case SQL Server, is still writing to that file.
SQL Server understands the VSCS; it is used by various backup programs as well as SQL Server’s own snapshotting functionality. Rather than interrupt access to the database files for the entire duration of the copying process, which could take minutes or even hours for very large databases, the VSCS interrupts access briefly to allow the SQL Server processes responsible for disk IO to establish a consistent ‘on disk’ state from which to capture a copy of the files. SQL Clone then creates a ‘shadow copy’ of the files, and SQL Server can continue to modify the files during this process because it uses the ‘copy-on-write’ mechanism to copy any changes elsewhere on the disk.
SQL Clone places these point-in-time copies of the MDF and LDF files into the Image VHD, which are stored on a file share.
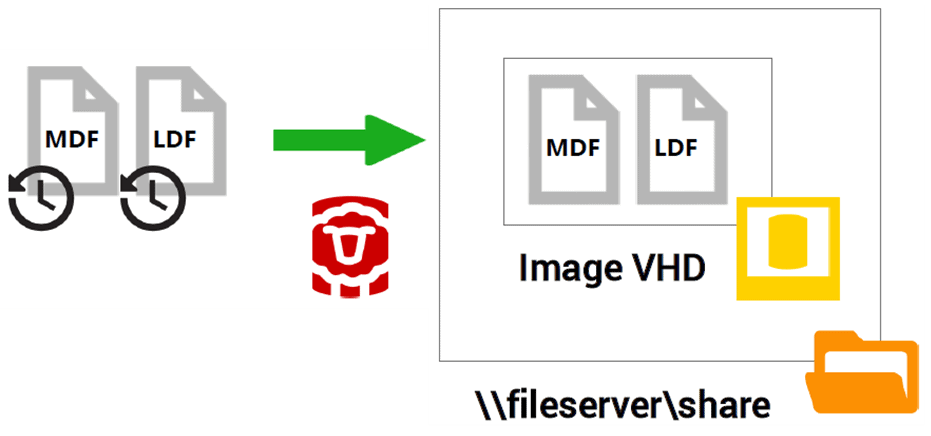
Even though the shadow copy service minimizes disruption to other applications needing to access the original database, while SQL Clone is making the copy, many DBAs would not allow direct access to a production database in this way, and instead would likely capture the image from a nightly database full backup.
In such cases, SQL Clone uses SQL Server’s native backup restore functionality or Redgate SQL Backup, rather than VSCS, to capture the image, as described in Database Provisioning from Backups using SQL Clone. As the backup is restored directly into the image VHD, no temporary storage is required, and the imaging process takes about as long as restoring a backup.
4. SQL Clone creates the clones
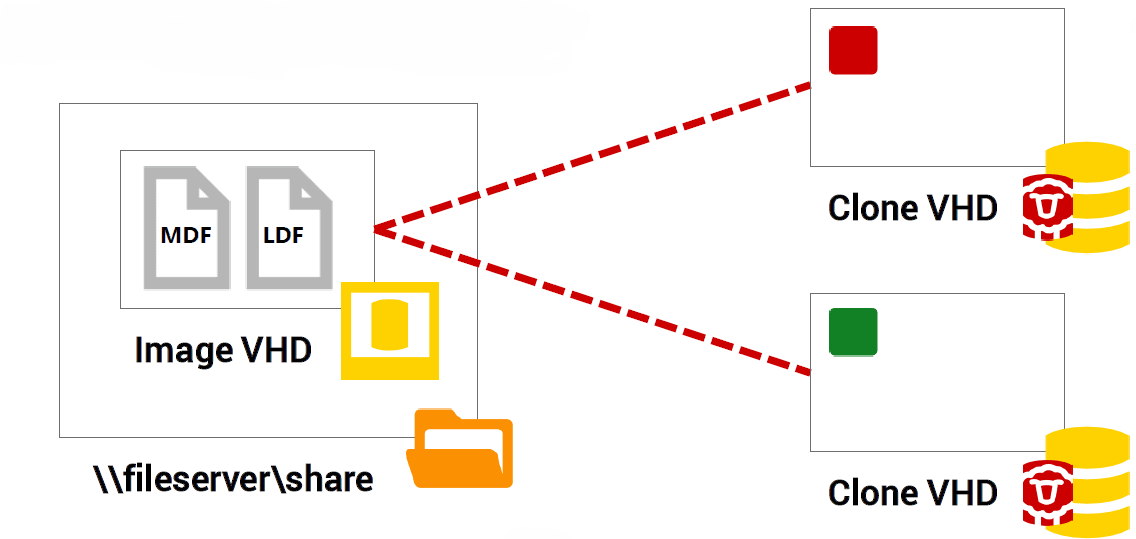
Now we have an Image VHD, which contains a point-in time copy of the source MDF and LDF files but is entirely isolated from the original database. This image is immutable, and from it we can create many database clones.
To do this, SQL Clone again uses the Windows Virtual Hard Disk Service, but this time to create a Clone VHD, which is initially empty, located on the local SQL Server instance on which we wish to create the clone.
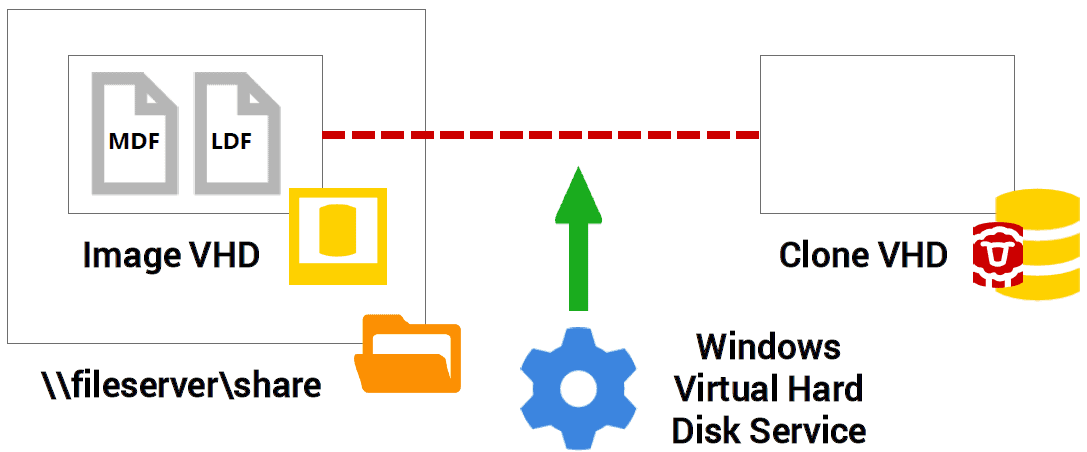
The Clone VHD is a differencing VHD, essentially a ‘child’ disk in which we’ll store changes made to the clone, and which is associated with a ‘parent’ disk, in this case the Image VHD. SQL Clone does this by creating a mount point on the local machine hosting the clone with a connection to the Image VHD.
When SQL Server accesses the Clone VHD, what it sees is any pages stored locally plus what’s inside the image. In other words, to SQL Server, the clone just looks like a normal database on a local disk.
We can create many child-parent associations in this manner; in other words, we can make multiple clones that all point to the same Image VHD. However, Clone VHDs are all independent from each other. Changes to each clone database will be stored inside each of the local Clone VHDs – the image itself never changes.
This means that each developer can work independently on his or her local clone, treating it just as any normal database, but one that takes up a fraction of the space of the original database.
The isolation of each clone, and the immutability of the image, means it’s perfectly safe to destroy a local clone and create a new one to get a database clone back to the same point in time as the original image, and this will take a matter of seconds, rather than the minutes or hours that it would take to restore a fresh copy from backup.
Summary
SQL Clone uses the virtualization technologies built into Windows to make clones small by only storing the bytes that make up the source database once. It uses the Shadow Copy Service or backup restore in order to make a point-in-time copy of these bytes, which are stored in a VHD. Clones are created using the Virtual Hard Disk Service, which links a local Clone VHD to a parent Image VHD.
SQL Server can then read unchanged data from the image, while saving changes locally in the clone, without ever changing the image. SQL Clone coordinates this process and allows you to manage images and clones across your organization, enabling isolated development on lightweight databases which you can create and destroy in seconds.
Find out more about how SQL Clone makes database provisioning easy with a 14-day, fully functional free trial.
Tools in this post
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like
-

Article
Bloor 2019 Market Update for Test Data Management lists Redgate as an innovator
Bloor has published its 2019 Market Update for Test Data Management, listing Redgate as an innovator, and scoring SQL Provision 4.5 stars out of 5 for test data provisioning. If you’re not familiar with Bloor, it’s an independent research and analyst house founded to help organizations choose optimal technology solutions. As database teams grapple with shortening
-
Article
How to Provision a Set of Databases to Multiple Azure-based Servers
Grant Fritchey shows how to provision a group of interdependent databases, masked to protect sensitive or personal data, to each machine in an Azure-based test cell.
-

Article
SQL Clone on your Laptop
Phil Factor provides a PowerShell script to disconnect your laptop without risking error 21, if you're working with SQL Clone and need to go offline. The same script will then bring the clone database back online smoothly, once you're reconnected.
-

Webinar
Can Continuous Compliance Automation transform data protection in your organization?
Continuous Compliance Automation introduces a proactive, always on approach to data protection. This one hour webinar will feature a panel of industry peers as they discuss this mindset change and the impact it can have on your organization.
-

Live training session
How to create and maintain masking sets with Data Masker
In this 30-minute training session, Redgate Solution Engineer, Chris Hawkins, will show how you can translate a business need of “I have some sensitive data I need to protect” into a data masking protection plan. First you need to know where your sensitive data is, then you can add the necessary protection and masking in