Security and compliance
Ensure data security and compliance with data masking, monitoring, and change traceability
Ensure data security and compliance with data masking, monitoring, and change traceability
Monitor and understand your databases with full visibility into performance and change
Build, test, and deploy database changes with confidence
Simplify and speed up database development workflows
Prepare reliable data foundations for AI initiatives
Simplify and secure database modernization across platforms
Control costs and boost efficiency in database operations
Simplify and speed up cloud database transformation
This is often called a 'none-chatty' design, where a single larger call is preferred over multiple smaller calls. Each call involves a degree of negotiation and overhead and the more calls you make, the more overhead is incurred. A single larger call reduces the overhead.
While Entity Framework can be a fantastic ORM tool, it can also be a major pain when you are executing a number of calls that are constantly hitting the database.
For simple database activities (SELECT, INSERT, UPDATE, or DELETE), use Entity Framework's standard Add, SaveChanges, and Delete methods. To improve SQL Server query performance for complex result sets, it can sometimes be more efficient to place them in a stored procedure and leave the heavy lifting to the database.
If you are calling the database using Entity Framework, you may write this command:
return context.Products.ToList().FirstOrDefault();
While this essentially returns one record, it retrieves the entire Products table from the database and then returns you one record. A better command would be:
return context.Products.FirstOrDefault();
This will produce a SQL command equivalent to grabbing the TOP 1 record instead of the entire contents of the table.
If your Model exposes an IQueryable object, your View may actually run a query multiple times when it tries to read the object's data.
List properties in the Model should be of type IList to force the query to be executed once and only once.
It's easy to spot these additional queries with .NET performance analysis tools like ANTS Performance Profiler, which shows you what queries are being run by your application.
Entity Framework greatly simplifies database access for the developer, but it can also introduce problems when you are writing more complex LINQ to SQL queries.
This may generate poorly-performing SQL, so to improve SQL Server query performance, try troubleshooting the generated SQL with tools like SQL Server Profiler or a SQL and .NET performance analysis tool like ANTS Performance Profiler.
Instructing Entity Framework to use the right kind of string when generating queries can resolve datatype conversion issues. A simple solution is to introduce Column Annotation:
public class MyTable
{
[Column(TypeName="varchar")]
public string Property1 { get; set; }
}
This is particularly valid for string datatypes where .NET Strings are Unicode by default and are not the same in SQL Server.
For more information, see: http://www.simple-talk.com/dotnet/.net-tools/catching-performance-issues-in-development/
WHERE IN style LINQ to SQL queriesEntity Framework is smart enough to convert the Contains() operator on LINQ queries to WHERE IN (…) in SQL. But there is a hidden problem: Giving a data set length of greater than around 10,000 records in a WHERE IN (…) clause will significantly degrade the performance of the query generation and query execution:
var ids = new int[]{0,1, 2,3,4,5,6,7,8,9,10........99995, 99996,99997,99998,99999};
var matches = ( from person in people
where ids.Contains(person.Id)
select person).ToArray();
The above statement generates the following fat SQL query:
SELECT * FROM PERSON WHERE ID IN (0,1,2,3,4,5,6,7,8,9,10.....,99995,99996,99997,99998,999 99)
It is advisable therefore to send data in batches. 500 records per batch, for example, would yield a significant improvement in performance, but you should do benchmarking to see what works for you.
If you're using an ORM like Entity Framework, when you declare an object mapped to another table with foreign keys, you automatically get references of those related entities. Unfortunately, there is a significant hidden cost when accessing the related entities, as separate queries can be run to retrieve details of each referenced row. This is commonly called the n+1 select problem.
For example, consider the following code where we fetch a list of schools from a database then filter that list. On line 1, a query is run to retrieve a list of n schools. On line 2, for every item in the schools list, a query is run to retrieve the number of pupils at that school, so in total n+1 queries are run.
Listschools = context.Schools.ToList(); List filteredSchools = schools.Where(s => s.Pupils.Count > 1000).ToList();
Consider using Eager Loading to avoid this scenario if you need to access properties of Pupils later:
Listschools = context.Schools.Include(s => s.Pupils).ToList();
Or in this scenario, simply replace line 1 with:
Listschools = context.Schools.Where(s => s.Pupils.Count > 1000).ToList();
Projecting a row into an object with a nested object has a big impact on the generated SQL. For example, here is an original query:
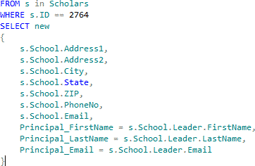
from s in Scholars
where s.ID == 2764
select new
{
s.School.Address1,
s.School.Address2,
s.School.City,
s.School.State,
s.School.ZIP,
s.School.PhoneNo,
s.School.Email,
Principal_FirstName = s.School.Leader.FirstName,
Principal_LastName = s.School.Leader.LastName,
Principal_Email = s.School.Leader.Email
}
This generates the following SQL:
SELECT 1 AS [C1], [Extent2].[Address1] AS [Address1], [Extent2].[Address2] AS [Address2], [Extent2].[City] AS [City], [Extent2].[State] AS [State], [Extent2].[ZIP] AS [ZIP], [Extent2].[PhoneNo] AS [PhoneNo], [Extent2].[Email] AS [Email], [Join2].[FirstName] AS [FirstName], [Join4].[LastName] AS [LastName], [Join6].[Email] AS [Email1] FROM [dbo].[Scholar] AS [Extent1] LEFT OUTER JOIN [dbo].[School] AS [Extent2] ON [Extent1]. [SchoolID] = [Extent2].[ID] LEFT OUTER JOIN (SELECT [Extent3].[ID] AS [ID1], [Extent4].[FirstName] AS [FirstName] FROM [dbo].[Staff] AS [Extent3] INNER JOIN [dbo].[Person] AS [Extent4] ON [Extent3]. [ID] = [Extent4].[ID] ) AS [Join2] ON [Extent2]. [LeaderStaffID] = [Join2].[ID1] LEFT OUTER JOIN (SELECT [Extent5].[ID] AS [ID2], [Extent6].[LastName] AS [LastName] FROM [dbo].[Staff] AS [Extent5] INNER JOIN [dbo].[Person] AS [Extent6] ON [Extent5]. [ID] = [Extent6].[ID] ) AS [Join4] ON [Extent2]. [LeaderStaffID] = [Join4].[ID2] LEFT OUTER JOIN (SELECT [Extent7].[ID] AS [ID3], [Extent8].[Email] AS [Email] FROM [dbo].[Staff] AS [Extent7] INNER JOIN [dbo].[Person] AS [Extent8] ON [Extent7]. [ID] = [Extent8].[ID] ) AS [Join6] ON [Extent2]. [LeaderStaffID] = [Join6].[ID3] WHERE 2764 = [Extent1].[ID]
Using the 'let' keyword allows us to define the navigation as an alias:
from s in Scholars
where s.ID == 2764
let leader = s.School.Leader
select new
{
s.School.Address1,
s.School.Address2,
s.School.City,
s.School.State,
s.School.ZIP,
s.School.PhoneNo,
s.School.Email,
Principal = new {
leader.FirstName,
leader.LastName,
leader.Email
}
}
This results in a much smaller query:
SELECT 1 AS [C1], [Extent2].[Address1] AS [Address1], [Extent2].[Address2] AS [Address2], [Extent2].[City] AS [City], [Extent2].[State] AS [State], [Extent2].[ZIP] AS [ZIP], [Extent2].[PhoneNo] AS [PhoneNo], [Extent2].[Email] AS [Email], [Join2].[FirstName] AS [FirstName], [Join2].[LastName] AS [LastName], [Join2].[Email] AS [Email1] FROM [dbo].[Scholar] AS [Extent1] LEFT OUTER JOIN [dbo].[School] AS [Extent2] ON [Extent1]. [SchoolID] = [Extent2].[ID] LEFT OUTER JOIN (SELECT [Extent3].[ID] AS [ID1], [Extent4].[FirstName] AS [FirstName], [Extent4]. [LastName] AS [LastName], [Extent4].[Email] AS [Email] FROM [dbo].[Staff] AS [Extent3] INNER JOIN [dbo].[Person] AS [Extent4] ON [Extent3]. [ID] = [Extent4].[ID] ) AS [Join2] ON [Extent2]. [LeaderStaffID] = [Join2].[ID1] WHERE 2764 = [Extent1].[ID]
Looking at the query execution plan in SSMS, the first query is roughly twice as expensive as the second, so not only is the query cleaner, but it performs and scales better as well.
SQL and .NET performance analysis tools like ANTS Performance Profiler can be used here to discover the performance improvement because it lets you see the generated SQL from a LINQ to SQL/EF query.
Using SQLBulkCopy can dramatically decrease the time it takes to load data into SQL Server. A test using SQL Server 2012 on a local machine loading a 100,000 row file had the following results:
Let's say you need to load a webserver log into SQL Server. You would still need to load a file, read the file, parse the file, and load the data into objects. Then you would create a DataTable (you could also use the DataReader or an array of DataRow too):
DataTable table = new DataTable();
table.TableName = "LogBulkLoad";
table.Columns.Add("IpAddress", typeof(string));
table.Columns.Add("Identd", typeof(string));
table.Columns.Add("RemoteUser", typeof(string));
table.Columns.Add("LogDateTime", typeof(System. DateTimeOffset));
table.Columns.Add("Method", typeof(string));
table.Columns.Add("Resource", typeof(string));
table.Columns.Add("Protocol", typeof(string));
table.Columns.Add("QueryString", typeof(string));
table.Columns.Add("StatusCode", typeof(int));
table.Columns.Add("Size", typeof(long));
table.Columns.Add("Referer", typeof(string));
table.Columns.Add("UserAgent", typeof(string));
Next step would be to load the DataTable with data that you've parsed:
foreach (var log in logData)
{
DataRow row = table.NewRow();
row["IpAddress"] = log.IpAddress;
row["Identd"] = log.Identd;
row["RemoteUser"] = log.RemoteUser;
row["LogDateTime"] = log.LogDateTime;
row["Method"] = log.Method;
row["Resource"] = log.Resource;
row["Protocol"] = log.Protocol;
row["QueryString"] = log.QueryString;
row["StatusCode"] = log.StatusCode;
row["Size"] = log.Size;
row["Referer"] = log.Referer;
row["UserAgent"] = log.UserAgent;
table.Rows.Add(row);
}
Now you're ready to use the SqlBulkCopy class. You will need an open SqlConnection object (this example pulls the connection string from the config file). Once you've created the SqlBulkCopy object you need to do two things: set the destination table name (the name of the table you will be loading); and call the WriteToServer function passing the DataTable.
This example also provides the column mappings from the DataTable to the table in SQL Server. If your DataTable columns and SQL server columns are in the same positions, then there will be no need to provide the mapping, but in this case the SQL Server table has an ID column and the DataTable does not need to explicitly map them:
using (SqlConnection conn = new SqlConnection(Configu rationManager.ConnectionStrings["LogParserContext"]. ConnectionString))
{
conn.Open();
using (SqlBulkCopy s = new SqlBulkCopy(conn))
{
s.DestinationTableName = "LogBulkLoad";
s.ColumnMappings.Add("IpAddress", "IpAddress");
s.ColumnMappings.Add("Identd", "Identd");
s.ColumnMappings.Add("RemoteUser", "RemoteUser");
s.ColumnMappings.Add("LogDateTime", "LogDateTime");
s.ColumnMappings.Add("Method", "Method");
s.ColumnMappings.Add("Resource", "Resource");
s.ColumnMappings.Add("Protocol", "Protocol");
s.ColumnMappings.Add("QueryString", "QueryString");
s.ColumnMappings.Add("StatusCode", "StatusCode");
s.ColumnMappings.Add("Size", "Size");
s.ColumnMappings.Add("Referer", "Referer");
s.ColumnMappings.Add("UserAgent", "UserAgent");
s.WriteToServer((DataTable)table);
}
}
There are other features of the SqlBulkCopy class that are useful. The BatchSize property can control the number of rows in each batch sent to the server, and the NotifyAfter property allows an event to be fired after a specified number of rows, which is useful for updating the user on the progress of the load.
In a lot of cases, data retrieved by the Entity Framework will not be modified within the scope of the same DBContext. Typical examples of this are ASP.NET MVC or ASP.NET MVC API action methods that just answer a get request. However, if you're using the default way of retrieving data, Entity Framework will prepare everything to be able to detect changes on your retrieved entities in order to persist those changes later in the database. This doesn't only add a performance penalty, but costs some memory, too.
A typical method of retrieving data is:
var products = db.Products.Where(p => p.InStock).ToList();
A better way uses the extension method AsNoTracking from the System.Data.Entity Namespace:
var products = db.Products.Where(p => p.InStock). AsNoTracking().ToList();
Indexing tables requires some trial and error combined with lots of testing to get things right. Even then, performance metrics change over time as more and more data is added or becomes aged.
When you're using SQL Server, it's a good idea to regularly run and analyze the standard reports SQL Server provides that show index usage (such as top queries by total IO, top queries by average IO, etc). This can highlight unused indexes, and can also show queries that are using excessive IO which may require further indexing.

For a deeper analysis of queries, you can also use SQL and .NET performance analysis tools like ANTS Performance Profiler.
Accessing the database is often the slowest aspect of an application due to the physical nature of accessing the data from disk (database query caching not withstanding). Developing your application with an efficient caching mechanism in mind can relieve the need for your database to perform requests and let it devote its time where required.
Simple things like caching reference data or data that changes very infrequently can make easy gains and reduce load on your database. As you cache more and more, it's important to ensure you invalidate cached data when it is updated using a common key, and this needs to be factored into the design.
For a headstart on caching and supporting multiple cache engines easily, try this library: https://bitbucket.org/glav/cacheadapter. This allows you to support ASP.NET web cache, memcached, Redis and the now defunct AppFabric on the same codebase via configuration only.
Entity Framework is a great productivity booster for developers. Instead of writing tedious SQL statements, you just write code like this:
var products = db.Products.ToList();
A line like this is great if you only have a few columns in your products table or if you don't care much about performance or memory consumption. With this code, Entity Framework selects all the columns of the products table, but if your product table has 25 columns and you only need two of them, your database, network, and PC all run slower.
Do your users a favor and retrieve only the columns you need. If, for example, you just need the 'Id' and 'Name' fields, you could rewrite your statement like this:
var db.Products.Select(p => new {p.Id, p.Name}).ToList();