





Using Data Scanning to Identify and Classify Sensitive Columns
When classifying SQL server databases, the most important thing is knowing what kind of data is contained in every column. For some databases, this is not a problem as that information can be inferred easily from the column names and their datatypes. Sometimes, though, column names give no hint of the data they contain, or the data contained doesn't match the name of the column. In the image below, for example, you can see there's a view (vVendorswithContacts) column called "Contact type" that contains job titles.
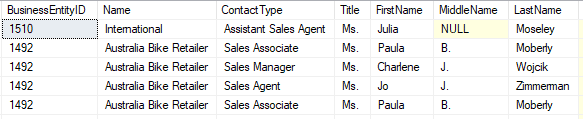
At this point a user must query those columns and look at the data or ask people who created those columns about their purpose. This is where data scanning comes in.
How data catalog identifies and classifies sensitive data
SQL Data Catalog has an extensive rule system allowing users to automatically identify and classify columns in their databases that store personal or sensitive information.
To get you started, it provides a built-in set of data classification rules. These use string-matching filters on the column names to make Information Type and Information Classification suggestions for columns that store character data. For example, if the built-in Zip Code rule detects the strings %postal% or %zip% in a column name it will suggest an Information Type tag of "Zip Code" and an Information Classification tag of "Confidential". You can apply these suggested classification tags manually or automatically.
In addition, you can define your own rules to give you suggestions or auto-applied tags. Previously, you could create these custom rules using only metadata filters, such as on the name of the column, its datatype, or its location (table or schema). Now, in v1.12 and later, you can also create custom rules based on the predicted information type of a column, obtained from data scanning.
With data scanning enabled, the built-in rules work just as before (based only on metadata analysis) but data catalog now has a second way to identify the type of information contained in a column, by peeking at the data itself. The information type determined by scanning is stored separately, as a "Predicted information type":

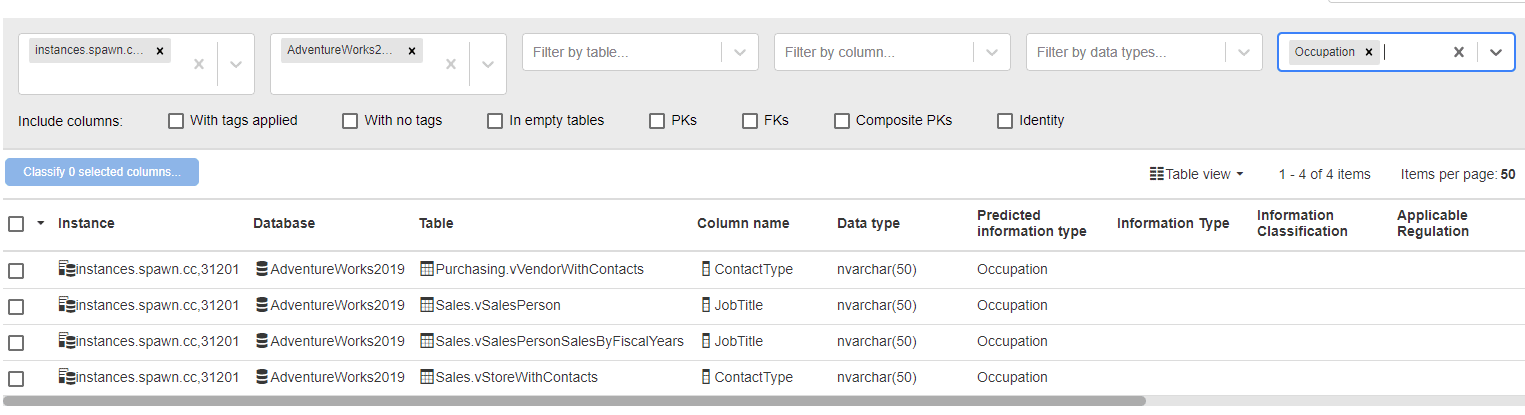
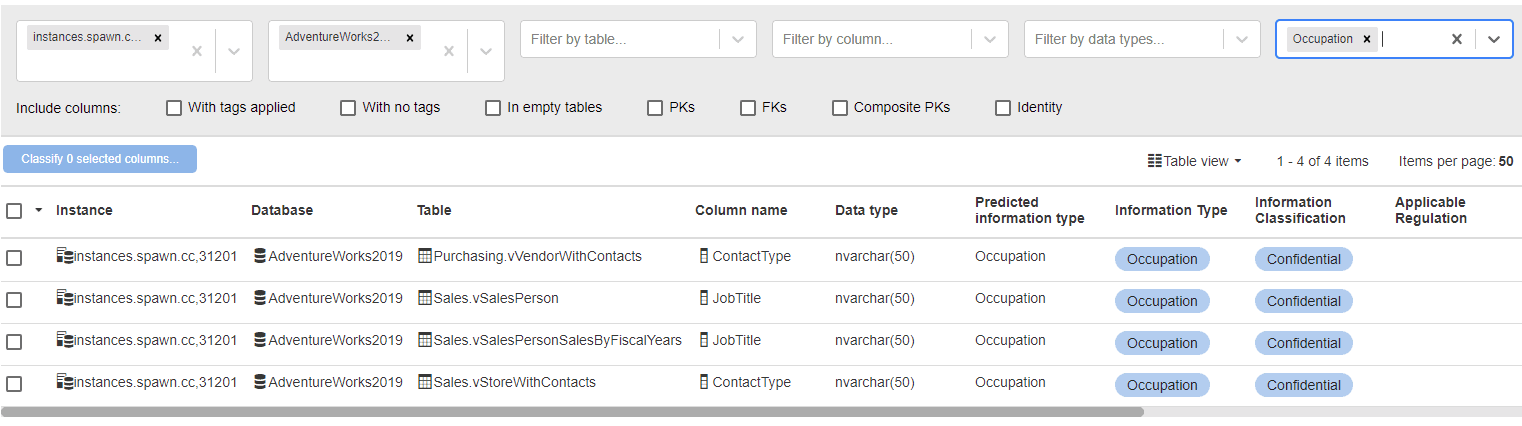
If I filter by a predicted information type of "Occupation", you can see that data scanning correctly identifies that the ContactType column in the vVendorswithContacts view contains job titles:
How data scanning works
While scanning, data catalog runs a select statement to retrieve up to 100 random samples from each column that contains strings of characters. To ensure the performance impact is minimal each query is run in sequence so there is only one query retrieving samples at any given time. As samples come in, the system uses a mix of dictionaries and regular expressions to determine their information type.
Data scanning uses regular expressions to identify information types with well-defined format, like emails or bank account numbers. Data dictionaries on the other hand are used for freeform types like given names and family names. They're lists containing a variety of examples for those data types. For example, the given name data dictionary contains common names like John or David but also less-common ones and names from different cultures like Aditya or Munir.
This means that data catalog is more likely to find columns containing personally identifying information such as names, addresses, titles and so on, as well as sensitive information such as bank account details and credit card numbers, regardless of what the column is called. It will also identify a broader range of potentially sensitive or personal data, such as the country details, or a person's title.
Enabling data scanning
By default, data scanning is disabled. It can be enabled per-instance either when you register it or by editing an already registered instance. Be aware that for this feature to work the account used to register the instance needs to have data reader permissions.
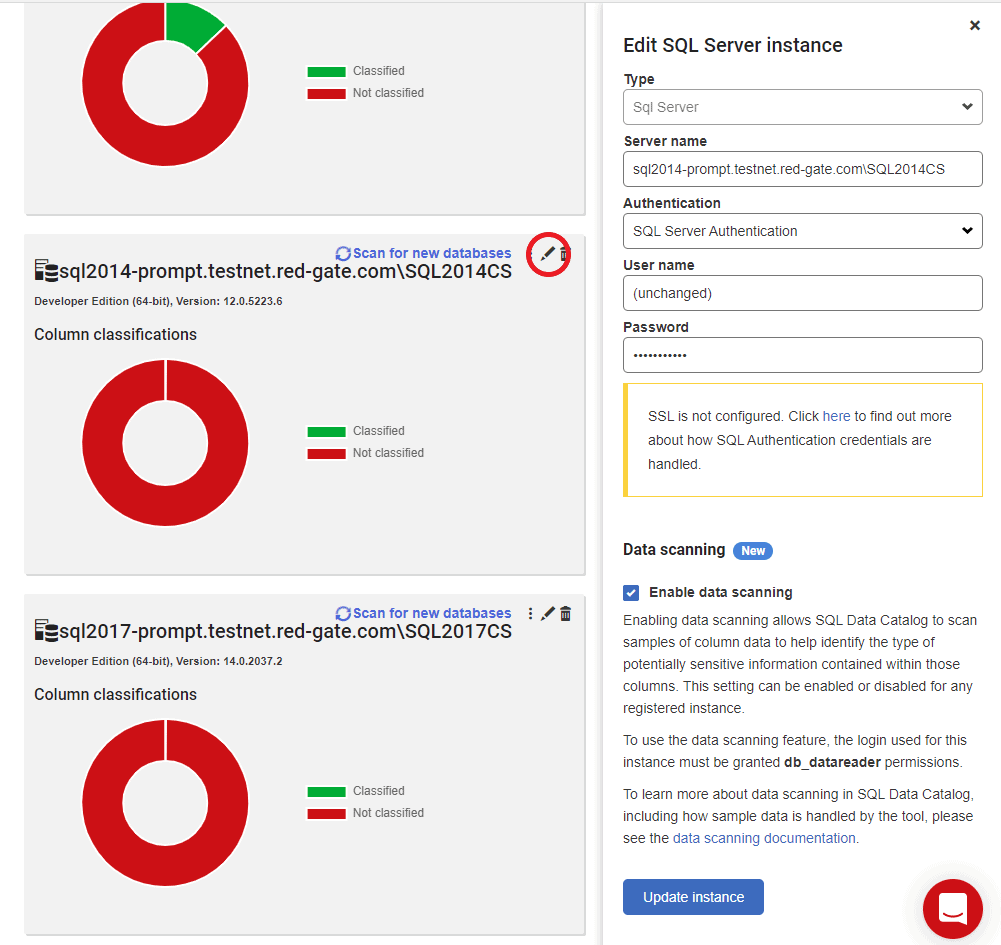
If you add new columns to a database, you can trigger a scan manually by navigating to Overview >Your instance and clicking on "Scan for updated schema" button. The scan will also run automatically once a day if new columns are found.
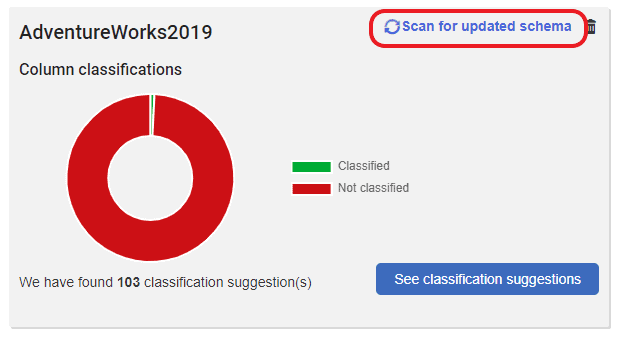
Once data scanning is enabled for an instance the system will identify all columns that contain text for all databases on that instance. If it determines a predicted information type, data catalog stores the information and won't scan those columns on subsequent runs.
Adding classifications based on predicted information type
The data scanning process does not apply tags to any columns, but you can set up additional rules based on the predicted information type, to generate suggestions or apply classifications automatically.
When creating a new rule from the Rules tab or editing an existing rule, simply use the Predicted information type filter as a criterion. For example you can create an automatically applied rule to assign "Occupation" and "Confidential" tags to all columns which have "Occupation" as predicted information type.
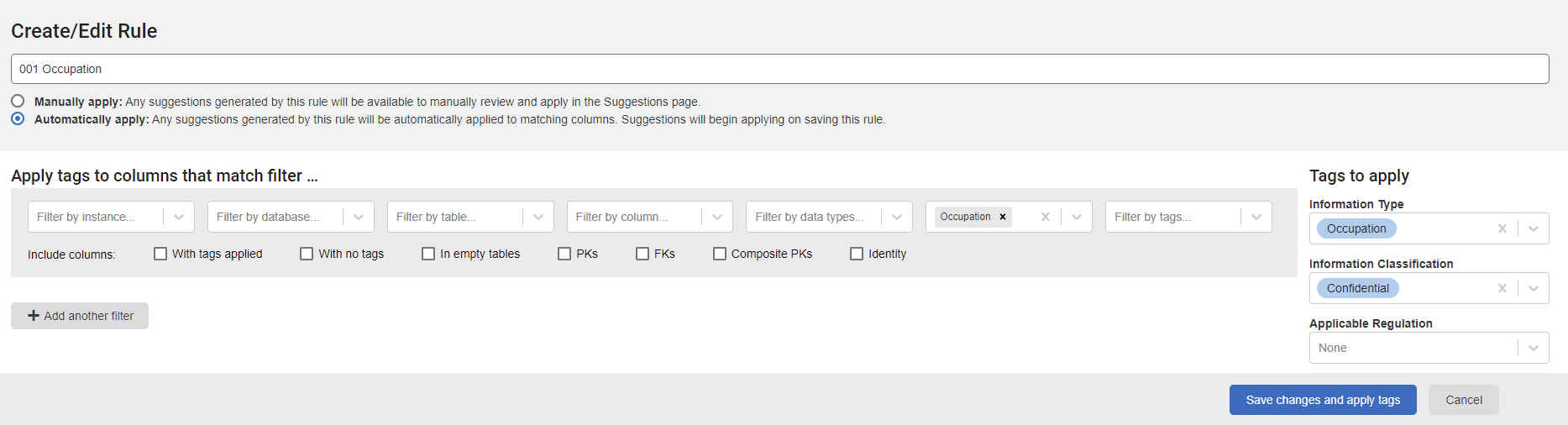
This can speed up the classification of your estate, reducing the time spent on manual classification, on your side. As you can see, having correctly predicted that the ContactType column contains 'occupation' information, it's now used our custom rule to suggest the correct type and classification for this column and any others that store this information.
You can also use rules based on the predicted information type to bulk classify data using PowerShell. For example, if your database contains a lot of system-generated columns you might start by bulk tagging these as "Out of scope – System" (or similar), as described in Data Categorization for AdventureWorks using SQL Data Catalog, and then use rules based on the predicted information types to auto-classify the remaining untagged columns.
Summary
Data scanning means that SQL Data Catalog can identify and classify personal or sensitive data in your SQL Server databases, regardless of the naming convention used for tables and columns. With data scanning enabled, SQL Data Catalog will automatically predict the "information type" of a column based on analysis of the data, using regular expressions and data dictionaries. You can use these predictions to apply a taxonomy of tags to describe all the different types of sensitive and personal data stored in your SQL Server databases.
No auto-discovery system is flawless, of course, and you'll still need to perform some manual review for occasional misclassifications. For example, in AdventureWorks, the Persontype is a 2-letter code some which match country codes so it can go wrong, depending on the rows that data scanning samples.
However, we'll use your experiences with data scanning to continuously refine and improve the data scanning algorithms, so please let us know of any feedback you have. You can now give feedback directly from within SQL Data Catalog, using the 'Intercom' message button, which you'll find at the bottom-right area of any screen.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
How to Classify and Protect your Development Data Automatically using SQL Data Catalog and Data Masker Command Line
Chris Unwin describes a classification-driven static data masking process, using SQL Data Catalog to classify all the different types of data, its purpose and sensitivity, and then command line automation to generate the masking set that Data Masker for SQL Server can use to protect this data.
Article
The Need for a Data Catalog
In the event of a breach of personal data, any organization must produce proof that they understand what data they hold and where, and how it is being used, and that they have enforced the required standards for access control and security. To make all this possible, it is essential to build a complete model of the data and its lineage, and a data catalog is the first step in this process.
Article
Using Data Scanning to Identify and Classify Sensitive Columns
SQL Data Catalog's new data scanning feature uses regular expressions and data dictionaries to identify where sensitive and personal data is stored in your databases.
Article
Improving the Quality of Data Governance: Where to Start?
How do we set about improving the quality of data governance within an organization? What are the priorities? Data Governance is generally considered to mean providing clear roles, responsibilities, policies, principles, and organizational structures that can ensure that data is managed well, in a way that benefits the whole organization. Where do you start?

Article
Data cataloging: A giraffe’s eye view
In the latest DBAle podcast episode our hosts, Chris and Chris, tackled what they really mean by cataloging a database and how taking a ‘giraffe’s eye view’ approach to compliance is not enough. That’s because the most common data concerns for managers and execs center around where your sensitive data is, the risk it poses and, if you’re migrating to the cloud, how much sensitive data is being stored on that database or that instance. To answer these concerns, a lot of people take a giraffe’s eye view where you’re way, way, way up, and you’re looking down and the

Live training session
Loading Existing Classifications into SQL Data Catalog
Classification is nothing new to companies – many have tried (and in some cases failed) to get columns tagged across their data estate. Much of this work is still usable, however. Join Chris Unwin, a Redgate Solution Engineer, as they take you through some of the best ways to persist your existing classifications into SQL Data Catalog (using the native functionality and PowerShell module), and use this for your data masking strategy, so no effort is wasted! Chris will also take you through our brand new data scanning feature, and how to enable it to automatically predict the type of
Loading comments...