





Tracking Development Changes using Flyway and Database Models
Flyway provides both a consistent way of developing databases across different RDBMSs, from SQLite to SQL Server, and a way of assigning a version number to a database. A version of a database is useful because it is then easier to manage releases and to integrate with source control systems.
However, knowing the Flyway version of a database becomes even more useful if we also have, saved in source control, a model describing what the metadata for each version looks like, so we know the design and structure of the tables, columns, indexes and views. If we have a version number and a model, and a way to compare two models, then we have a way to find out what changed, between any two versions of a Flyway-managed database.
Models are particularly useful in team-based development work because they offer a way to increase the visibility of changes. If we have a model for two different versions of a database, we can compare them to generate a report of which objects changed between versions, and how. This sort of report, in turn, is useful for other tasks, such as verifying that a database at a given version is still in the expected 'state', or for constructing a consolidated migration script, retrospectively, from database changes.
This article focuses on comparing models to examine any differences. For other practical uses of models in managing Flyway migrations, see Using Database Models and Flyway for Automating Routine Development tasks.
Why do I need a database model?
A database object model is a hierarchical representation of a database that is detailed enough to recreate the database. It is best stored in JSON, YAML or XML. They are reasonably easy to create by reading and collating information from the metadata views provided for each RDBMS. A database model is a cross-RDBMS way of representing the current 'state' of a database. In my GitHub repo, I've provided a sample model for the Pubs database, which is in JSON format.
Once you have the model for a database version, saved in a simple, structured text document like a JSON file, you can get all sorts of useful information out of it just with simple queries and searches, no parser required. This provides us with an RDBMS-independent way to find out about the structure and relationships of the objects in the database, and their dependencies, and to get basic details about the tables, constraints, and indexes that it contains.
Once we have a model saved for each successive Flyway version then it also becomes possible to compare models and see what changed between versions.
Can't I get the same information from build scripts?
In a sense, a database build script is a 'model' of a database, in that it defines, in SQL, the structure and interrelationships of database objects such as tables. In a previous article, I describe how to generate a build script for each new Flyway version, so that you can then use a simple 'Diff' tool to inspect the two files, side by side, for differences.
However, if you're using a SQL build script as your model, then your automated processes will need to use a parser to read it. Within a scripted process, you can't easily get information from SQL code, even just to get a list of tables or the column names of a table, unless you have a SQL tokenizer and a parser. And, of course, it has to be the right parser for the relational database system (RDBMS).
Surely I can just use Redgate's schema comparison tools?
Redgate's schema comparison tools can generate and compare SQL DDL 'models', referred to as schema models. Here, the schema model is a directory of SQL DDL files, organized by object type, where each script builds an object in the database. These files contain SQL DDL expressions that, when executed in the right order, will create the database. If a schema comparison engine is available for your RDBMS then it can automatically create and maintain these schema models, and it can compare them to produce visual reports of which objects changed and how, between Flyway versions.
For Flyway development, if you're using Flyway Teams edition, then it will generate a schema model for the associated development database and update it in response to database changes. In Enterprise edition of Flyway, you can then retrospectively capture those changes into a Flyway migration script.
However, if a 'compare engine' is not available for your RDBMS, or if you're using Flyway Community edition, then you'll need a different approach. A model for each version is still needed because the Flyway migration scripts, alone, don't tell you very much at all about the database. However, you'll need the models in a different format. Instead of a SQL DDL model, you need a standard format that is easily readable without a parser, so that automated processes can still extract details about the structure or compare two models to find out how the structure has changed. In short, you need the model in a JSON document.
What about using my ODBC driver?
You can, but it has limitations. The ODBC driver will only record changes in the metadata of the tables, views, procedures and functions, and it can't record changes in constraints. I've demonstrated what can be achieved by creating generic models of the database from ODBC metadata in Discovering What's Changed by Flyway Migrations, but it's only sufficient to give developers a 'high level' understanding of what changed.
Can't I just use the Information Schema views?
We can also create a model simply by reading the metadata of the live database, from the information schema provided for that RDBMS. So, why not just use that? Firstly, the information schema isn't supported as widely as it should be and varies greatly between implementations. Secondly, it means that each time you want to investigate what's in a particular version of a database, you need access to a live database, at that version.
Instead, a JSON model will give you useful, accessible information about what was in a database that isn't live, such as an old version stored in source control. It can provide this information for a range of RDBMSs. If the model is comprehensive, and the database has the version discipline that Flyway manages, then it quicky becomes the dominant source of information about the structure and history of a database.
Creating the database models
In order to compare a database between two versions, you need a database model of both versions. Flyway Teamwork, my PowerShell scripting framework for Flyway, has a task called $SaveDatabaseModelIfNecessary that will automatically save a database model for each new version that Flyway creates. It is designed for use with Flyway Teams edition, in particular, but you can also use it with the free Community edition.
The models it produces are merely an object representation of the hierarchy of tables, views, columns, keys, indexes and so on, saved in a standardized, RDBMS-independent format (a JSON hierarchy). The task creates these models by extracting the information about each object from the metadata views provided for the particular RDBMS, combining it, and then saving it to a JSON file. For each new version, it generates object-level JSON files, grouped by object type, and saves them in the model subfolder for each version:
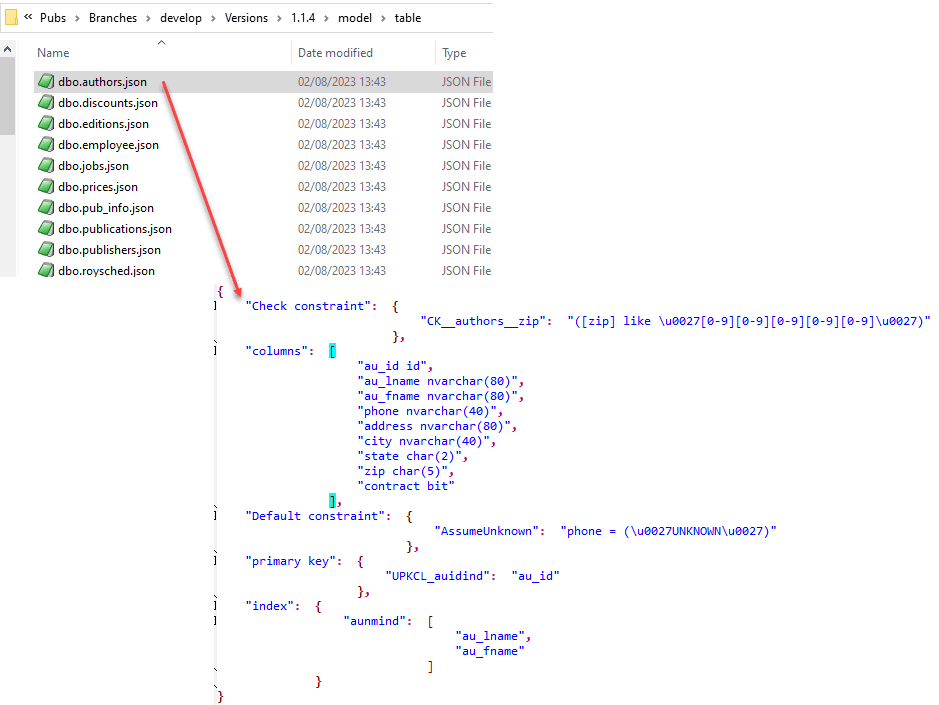
In the reports subfolder, for each version, you'll find the file for the combined, database-level model.
My previous article, Simple Reporting with Flyway and Database Models, shows both how to generate the models in PowerShell and then perform simple searches on them to explore the structure of the database. Here is the start of the model for the Pubs database, represented in YAML to make it easier to follow:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
---
dbo:
table:
roysched:
foreign key constraint:
- FK__roysched__title___15502E78
Columns:
- title_id tid
- lorange int
- hirange int
- royalty int
Indexes:
- titleidind (title_id)
publishers:
check constraint:
- CK__publisher__pub_i__0425A276
default constraint:
- DF__publisher__count__0519C6AF
Columns:
- pub_id char(4)
- pub_name varchar(40)
- city varchar(20)
- state char(2)
- country varchar(30)
primary key constraint:
- UPKCL_pubind (pub_id)
|
Using database models
As you can tell, these models are immediately useful for understanding the structure and relationships of each of the objects in these databases. You can see how they would come in handy for several tasks such as working out dependencies or checking for missing indexes. I even went so far as to show how to autogenerate a quick Entity-Relationship diagram from a model, so that the team could sanity check any Flyway version for unreferenced tables, missing keys or indexes, and other design flaws.
Furthermore, once we have models for every version, we can then compare the models to see what has changed between those two versions.
Comparing models to work out what changed
To compare two database models, I've provided a PowerShell cmdlet called Diff-Objects, which you'll find in the Resources folder of the Flyway Teamwork framework. It is designed to compare PowerShell objects, so we read in the JSON models from file and convert them.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
$PreviousVersionReportPath='<Path To>PubsPG\Branches\Develop\Versions\1.1.6\Reports\'
$currentVersionReportPath='<Path To>PubsPG\Branches\Develop\Versions\1.1.16\Reports\'
$pathToSource="$PreviousVersionReportPath\DatabaseModel.JSON"
$pathToTarget="$currentVersionReportPath\DatabaseModel.JSON"
#see what is changed by comparing the models before and after the migration
$Comparison = Diff-Objects -Parent $Details.Database -depth 10 <#get the previous model from file#>`
([IO.File]::ReadAllText($pathToTarget) |
ConvertFrom-JSON)<#and get the current model from file#> `
([IO.File]::ReadAllText($pathToSource) |
ConvertFrom-JSON) |
where { $_.match -ne '==' }
$Comparison |foreach -begin{$Schema='';$ObjectType='';$ObjectName='' } {
$current = $_;
$objectList=$current.Ref.split('.')
$SchemaChanged=($Schema -ne $objectList[1])
$Schema=$objectList[1]
$ObjectTypeChanged=($ObjectType -ne $objectList[2])
$ObjectType=$objectList[2]
$ObjectNameChanged=($ObjectName -ne $objectList[3])
$ObjectName=$objectList[3]
$TheMatch=$current.Match
if ($SchemaChanged) {"$Schema"}
if ($ObjectType -ne $null -and $ObjectTypeChanged) {"`t$ObjectType ($TheMatch)"}
if ($ObjectName -ne $null -and $ObjectNameChanged) {"`t`t$ObjectName ($TheMatch)"}
}
|
I've used the symbols <- to mean added, <> to mean changed, and -> to mean deleted. This produces the following database change report:
accounting
table (<-)
bills (<-)
bill_lines (<-)
bill_payments (<-)
chart_of_accounts (<-)
customer (<-)
invoices (<-)
invoice_lines (<-)
invoice_payments (<-)
received_moneys (<-)
received_money_lines (<-)
spent_moneys (<-)
spent_money_lines (<-)
suppliers (<-)
view (<-)
bill_trans (<-)
invoice_trans (<-)
received_money_trans (<-)
spent_money_trans (<-)
trial_balance (<-)
dbo
function (<-)
calculate_monthly_sales (<-)
splitstringtowords (<-)
theyear (<-)
table (<>)
discounts (<>)
editions (<-)
employee (<-)
prices (<-)
publications (<-)
publication_types (<-)
sales (<>)
tagtitle (<-)
view (<-)
salesbymonthandyear (<-)
titlesandeditionsbypublisher (<-)
titlestopicsauthorsandeditions (<-)
people
table (<-)
abode (<-)
address (<-)
addresstype (<-)
creditcard (<-)
emailaddress (<-)
location (<-)
note (<-)
noteperson (<-)
organisation (<-)
person (<-)
phone (<-)
phonetype (<-)
view (<-)
authors (<-)
publishers (<-)
This tells you whether any table, function or view has appeared, changed, or vanished. At the next level, it tells you which of each type of object has changed. Finally, it tells you which attributes, such as columns, constraints or indexes, have changed and how.
I've provided a $CreateVersionNarrativeIfNecessary task in my Teamwork PowerShell framework, which uses the Diff-Object cmdlet to compare the current version, produced by the latest successful Flyway migration, to the previous version and produce a high-level report of what changed. My article Recording What’s Changed when Running Oracle Migrations with Flyway gives a demo.
Verifying a database version
I've already explained elsewhere how we can use these model comparisons to verify a Flyway version, to check for accidental or surreptitious changes to the current database version. Flyway will do its best to ensure that you can't retrospectively change the contents of any migration script that has already been applied to a database. However, in order to check that a database hasn't 'drifted' from its assigned version, due to subsequent external or 'uncontrolled' changes, we need to compare its current 'state' to a model of what should be in the database at that version. We can do this easily if, for every version of a database produced by Flyway, we save in source control a corresponding model, defining the structure or 'state' of the database at that version.
We can also use these version checks to verify that:
- an undo script returns a database to exactly the right state
- a test teardown removes all remnants of test objects
- a consolidated migration script for a version (such as a baseline migration) produces exactly the same result as the existing run of migration scripts.
Again, if you have a schema comparison tool available for your RDBMS then it can do all of these tasks for you, automatically, but if not then the ability to generate and compare simple JSON models will give you a good start.
Creating a consolidated migration script to merge branch changes
If you're working on an isolated branch database, at some point you'll need a migration script to merge the changes into the parent branch. This script will need to contain all the changes made to the branch, which may involve consolidating a lot of the branch's migration files and will need to be assigned the right version number for the parent branch.
To get a first-cut migration script for the merge operation, you'll need to find out what actually changed within the branch. You do that by finding the differences between the 'state' of the database at the beginning and end of the work. I've demonstrated the process in full in Database Branching and Merging without the Tears, although using SQL Compare to do the comparison and generate the script. If your RDBMS has equivalent schema comparison technology, and you have a license, then this is the best way to do it. However, if you don't have access to such a tool, or it doesn't exist for your RDBMS, then you can get a good overview of the differences you need to capture by comparing two JSON models, one for the starting version and one for the current version of the branch database.
As you saw in the previous example, we can use the Diff-Objects routine to determine which objects need to be created (<-), altered (<>), or dropped (->), in dependency order. You can either create or alter/replace each object or drop the object if it exists and create a new version.
When altering tables, a lot of care is required. There was a time that one would import the fake development data at the end of the build, which meant that you could drop the old versions of tables and re-create them from the new version. This was wonderful for developers but caused chaos at deployment time because a production database could only be updated with a generated script that made those same changes as your development code, but in a way that preserved the data. This would never have been tested and it could therefore take time to ensure that the script could alter the tables while preserving the existing production data.
With Flyway, the same files that you use to develop the database will be used to migrate the production database to a new version. This removes a lot of the anxiety from deployment, but it makes development harder because you have to make changes to tables in a way that ensures the preservation of the data, even though you're using fake test data. The extra pain is worthwhile because it means that you can ensure, during development, that your changes don't corrupt any existing data.
You can use ALTER statements for those changes such as column renames that preserve the data, and various software devices for table splits or data re-engineering. At the worst, you would need to insert the data from the old tables into the new.
Our previous Diff-Object example simply gave a list of objects that had created, altered or dropped between two versions (1.1.6 and 1.1.16). Most of the changes were simply new object creations, but two tables (discounts and sales) were present in both versions but different. If we simply request to see just get the entries where an object from the older version was changed in the newer version, we get more detail about exactly what changes need to be done:
$Comparison |where {$_.match-eq '<>'}|convertTo-json
[
{
"Ref": ".dbo.table.discounts.columns[5]",
"Source": "discount_id integer GENERATED BY DEFAULT AS IDENTITY",
"Target": "discount_id integer GENERATED ALWAYS AS IDENTITY",
"Match": "\u003c\u003e"
},
{
"Ref": ".dbo.table.sales.columns[2]",
"Source": "ord_date date NOT NULL ",
"Target": "ord_date character varying (50) NOT NULL ",
"Match": "\u003c\u003e"
}
]
We can see that in the discount_id column was originally defined with an identity attribute of GENERATED ALWAYS AS IDENTITY but was then subsequently changed to GENERATED BY DEFAULT AS IDENTITY. It turns out that a PostgreSQL table's identity attribute, once defined, cannot be altered or modified directly, so we'd need migration code that creates a new table with the desired identity attribute using the GENERATED BY DEFAULT AS IDENTITY syntax.
For example, the migration could copy the data from the existing dbo.discounts table to a new table (e.g., dbo.newDiscounts) with the correct definition, drop the existing dbo.discounts table and rename the new table from dbo.newDiscounts back to dbo.discounts.
The change to the sales table can be done by an ALTER TABLE statement, if you can prove that the original text version of the ord_date column can be entirely implicitly converted to valid dates. Otherwise, you'd need to add a new nullable column of type DATE to the table, update the new column with the converted values from the existing column, using the to_Date() function, drop the old character-based column, and then rename the new column to ord_date.
Naturally, you'll want the migration file to alter the tables in a way that avoids errors. The same $SaveDatabaseModelIfNecessary task, in the Teamwork framework, that generates the JSON models also generates a table manifest to give you the right order. I describe the table manifest in more detail in Managing Datasets for Database Development Work using Flyway.
Summary
I've shown how, if you save the model of the database on every migration, you can compare any two versions of a flyway-managed database to see the differences. Although in SQL Server, you can use SSDT BACPACs to do this, there is nothing equivalent in other RDBMSs, and we need to do this as a routine check no matter what RDBMS we use.
Although the best representation of a database uses relational views, there are certain advantages in having a model of a database that is independent of the actual RDBMS being used. Unfortunately, there is no current standard for the metadata views, but even if there was, there must be a standard way of reading the information from those tables into a script or application. Instead, I'd suggest that, with a standard way of representing a database in JSON, it then becomes possible to perform all sorts of routine RDBMS-independent tasks such as porting a database from one RDBMS to another or producing a 'fluff-check' for a lot of table smells, missing indexes, naming problems and so on. If you're wondering; yes, I'm working on it.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Using SQL Compare with Row Level Security
As you test your row-level security in various environments, you can use SQL Compare to script out and deploy those changes to other databases.

Article
Insert Statement Without Column List (BP004)
Many production databases have failed embarrassingly as a result of
INSERTcode that omits a column list, usually in mysterious ways and often without generating errors. Phil Factor demonstrates the problem, and advocates a 'defense-in-depth' approach to writing SQL, in order to avoid it.
Article
Self-service and Delegation with SQL Clone 4 Teams
SQL Clone 4 introduces a new access control feature called Teams, allowing granular control over the SQL Server instances, images and clones to which each group of users has access. I’ll explain how Teams makes it easier to manage the safe distribution of database copies throughout the organization, to the various teams that need them for development, testing, training or analysis. By ensuring that no SQL Clone team has access to data or to SQL Server instances to which they do not have permission, or that are simply irrelevant to them, SQL Clone delivers a “canteen-style” of database provisioning, where

Article
A Flyway Teams Callback Script for Auditing SQL Migrations
Demonstrates a cross-database PowerShell callback script for reporting on and auditing Flyway migrations, telling you which scripts were used to create each version, when they were run, who ran them and more.
Article
Pseudonymizing your data with SQL Data Generator
Starting from a database view, as the basis for a typical sales reports, Phil factor shows how to generate a data-masked version of this report, which the Tax Men can safely pore over.
Article
Misuse of the scalar user-defined function as a constant (PE017)
The incorrect use of a scalar UDF as a global database constant is a major performance problem and should be investigated whenever SQL Prompt spots this in any production code. Unless you need to use these global constants in computed columns or constraints, it is generally safer and more convenient to store the value in an inline table-valued function, or to use a view.
Loading comments...