Getting Started with Flyway SQL Code Analysis Rules
Before you apply pending SQL migration scripts, Flyway can automatically check them for a range of code smells. The check -code command can perform a static code analysis on these scripts to check that they comply with a set of rules designed to encourage good coding practices. You can opt to use SQL Fluff, provide your own Regex rules, or use both. This article explains how Flyway's regex-based code checks work and how to start running checks on Flyway-managed databases.
Assessing SQL style, SQL habits, and code quality
Development teams generally aim to adopt a consistent SQL style that meets common standards for coding practices, formatting, and usage. However, it is not straightforward to define what we mean by “good SQL”. Coding standards vary depending on the database system, the team’s preferences, and the performance and maintainability requirements of the application.
In addition, while static code analysis helps enforce good practices, developers tend to resist rigid, one-size-fits-all rules. SQL offers plenty of flexibility in how queries can be structured, and what works well for one team or database system might not suit another.
In my commercial programming experience, two broad types of SQL code checks are useful in development (in addition to usual functional and performance tests):
- Dynamic code analysis – examines a live database, querying the system catalog views, functions, tables, and properties to uncover potential issues such as missing indexes, disabled constraints, or inefficient queries. This type of analysis is typically done using a monitoring tool or by running targeted checks manually.
- Static code analysis – uses either a parser or regex strings to inspect the code rather than the live database. We can run static analysis on build scripts, migration scripts, the code within functions or even the code being used by applications to query the database
Both static and dynamic analysis are required. Static analysis will alert teams to faults in the code, before they get into the ‘main’ or ‘develop’ branches of the database. However, there is only so much you can check with static rules and if you rely on these alone, you will miss many of the issues that creep into a live database, such as disabled constraints and indexes. See Running Dynamic Code Quality Checks on Flyway Databases: Table Smells for more details.
Parser or Regex-based static code analysis
There are two main ways to perform static code analysis. The first, and most reliable, method is to use a SQL parser or tokenizer, which analyzes the structure of the SQL and enforces predefined rules. However, this approach is relatively inflexible: you can enable or disable rules, but it is difficult to modify them to match team conventions.
The second approach, regex-based code analysis, offers greater flexibility. It allows you to define custom rules without relying on external tools, making it easy to enforce team-specific SQL conventions. For example, you may have a team rule that GROUP BY statements either must, or should never, have numbers, depending on the RDBMS. However, regex analysis is less accurate. Unlike a SQL parser, regex treats SQL as plain text rather than a structured language. This means it cannot distinguish between keywords, identifiers, literals, and comments, so there’s a greater risk of false positives. Despite its limitations, regex-based code checks are useful for basic SQL hygiene, and for catching patterns that would be difficult to detect with a parser, such as:
- The use of
SELECT*instead of explicit column selection - A missing
WHEREclause inDELETEorUPDATEstatements. - Deprecated SQL syntax, even when buried inside comments or string literals.
- Debug and test artifacts, such as
TODOcomments or leftover print/debug statements.
Running Flyway code analysis checks
Flyway integrates with a SQL linter called SQL Fluff for a parser-based approach. I’ve previously explained how to run its checks through PowerShell in Reviewing SQL Migration Files Before a Flyway Migration. However, it is now fully integrated with Flyway, and once installed and configured, Flyway’s check -code command will run its rules automatically on any pending migrations.
The check -code command will also analyze the text of SQL migration files, executing both built-in and custom regex rules. It works much like a traditional GREP tool (e.g., PowerGREP), but with the added advantage that Flyway only analyzes those scripts that haven’t been applied. This makes it particularly useful for enforcing consistent SQL practices across a team.
The Regex rule format in Flyway
Each of Flyway’s regex rules are kept in a separate TOML file within a folder within your project. Each file can have several regexes per rule. If you don’t specify the location using the Check.rulesLocation configuration item, then Flyway looks in the ‘rules’ subdirectory in the Flyway installation for the built-in rules.
The filenames are in the format: A__B.toml (that’s two underscores) Where A is the rule identifier (e.g. MyRule01) and B is a short rule description. In the ‘code smell report’ B will be replaced by the more detailed description field in the TOML file, if supplied.
Here is an example built-in TOML rule file, to catch any use of SELECT *:
|
1 2 3 4 |
dialects = ["TSQL"] # Specifies which SQL dialect this rule applies to rules = ["(?i)SELECT\\s+\\*"] # Regex pattern to detect 'SELECT *' passOnRegexMatch = "false" # If the regex matches, trigger a violation description = "Avoid using 'SELECT *'. Specify column names explicitly." |
The rule file contains four main fields:
- Name – a unique identifier for the rule. This is embedded in the filename.
- Dialects – a list of applicable SQL dialects (e.g., TSQL, PostgreSQL, MySQL). If it is useful for all, you need to write
TEXTrather thanALL. - Rules – a list of the regex pattern(s) used to detect violations.
- passOnRegexMatch – this is set to
falseby default. It determines whether a rule is considered broken when a regex matches (false) or when it does not match (true). - Description – an explanation of the rule and why it may be important.
Flyway’s default regex rules
Flyway stores the default rules in the Flyway installation, within the ‘rules’ directory. This is a collection of TOML files with sample rules in them. You can find the full list in the documentation, but broadly they include rules that seek to:
- Prevent destructive commands with a risk of data loss – such as dropping or truncating a table, or dropping a column
- Guard against security misconfigurations – detecting commands that grant excessive privileges or make unauthorized changes to roles, users or passwords
- Encourage best practices – finding tables with no Primary key or that lack documentation.
These built-in rules are useful for learning, but if you wish to improve them, it is best to copy them over to your project’s ‘rules’ directory and use the copy, along with any new rules you add to them. Otherwise, all your projects must share the same default rules, and you lose any improvements you make to the built-in rules the next time you update Flyway.
Adding custom regex rules
Fyway’s built-in regex rules focus mostly on security and data protection. It’s a good starting point, but you’ll soon want to add more rules to enforce or encourage SQL best practices and code hygiene standards. Redgate maintains a small library of custom rules on GitHub, which you can copy over to your project’s rules folder, but you’ll also want to create your own custom rules.
I demonstrate how to create, test and maintain custom regex rules in the second article in this series, and provide a small regex library for seeking out code smells that could at some point cause performance problems and unpredictable behavior. These smells are selected from my SQL Code Smells booklet, which documents what I consider the worst offenders. There is also a GitHub site, and a GitHub version of the book. At the time of writing, if you’re working on Windows or using PowerShell, then all new rules had to be written explicitly in the Windows-1252 file format, or else UTF-8 without BOM, to avoid an inscrutable Java error. This problem is fixed in Flyway 11.4.1 and later.
For this article, however, we’ll get started using just the default rules.
Running the regex rules
The check -code command runs static code analysis over the pending SQL migrations, running all the rules defined in filesystem:rulesLocation. You need to provide an environment so that Flyway can determine what dialect of SQL you are using, and you can specify the dialects for which the regex can be used in the rules file.
You can provide parameters to alter the way that the check runs
- check.rulesLocation – where Flyway looks for rules. If you specify a location as a parameter, that is used instead of the ‘rules’ directory of the Flyway installation
- check.majorRules – list of rules considered to be major
- check.majorTolerance – the number of major rules violations to be tolerated before throwing an error.
- check.minorRules – list of rules considered to be minor
- check.minorTolerance – the number of minor rules violations to be tolerated before throwing an error
- reportFilename – the output path of the generated report.
- workingDirectory – the directory to consider the current working directory. All paths will be considered relative to this.
Make sure that there are no files in your rulesLocation other than your TOML files. Flyway will try to read any file, whatever its filetype and then ‘error-out’. A simple check -code command might look like this:
|
1 2 |
flyway -environment=main check -code -rulesLocation="<MyPathTo…>\Pubs\rules" -outputType=json |
The best and most useful output of check -code is the JSON output:
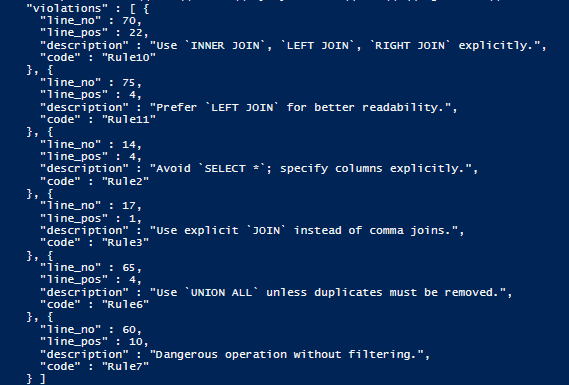
There are HTML reports for users of Flyway Desktop, but these aren’t useful within an automated pipeline.
Testing the regex rules
I’ve provided a SQL style assault course, geared for SQL Server, to test out the collection of built-in Regex rules and any custom rules you add subsequently (more on this in the next article). This test script should be saved into one of the project’s locations as a pending migration. It is also useful for developing Regex expressions. Just add to the pending script an example of a SQL Code smell that you are keen to discover.
You can run your regex code checks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
cd <MyPathToFlywayProjectDirectory> $SQLSmells = flyway check -code -rulesLocation='.\rules' -outputType=json | ConvertFrom-Json $SQLSmells.individualResults|where {$_.operation -eq 'code'} | foreach{$_.results}| foreach{ #code operation $file = ($_.filepath -split '\\') | select -Last 1; #get the filename $_.violations #get each violation } | foreach{ [pscustomobject]@{ 'File' = $file; 'Line' = $_.line_no; 'Col' = $_.line_pos; ; #'Code' = $_.code; 'SQL Smell' = "$($_.code) ($($_.description))" } } | Sort-Object -Property @{Expression={$_.file}}, @{Expression={$_.line}}, @{Expression={$_.col}} |
You’ll get a report like this:
File Line Col SQL Smell - ---- --- --------- V1.2__SecondRelease1-1-3to1-1-11.sql 9674 1 RX001 (DROP TABLE statement) V1.3__ThirdRelease1-1-11to1-1-15.sql 1468 9 RX001 (DROP TABLE statement) V99__DummySQLSmells.sql 2 1 RX014 (A table has been created but has no MS_Description property added) V99__DummySQLSmells.sql 50 1 RX001 (DROP TABLE statement) V99__DummySQLSmells.sql 52 1 RX003 (TRUNCATE statement) V99__DummySQLSmells.sql 55 1 RX004 (DROP COLUMN statement) V99__DummySQLSmells.sql 59 1 RX006 (GRANT WITH GRANT OPTION statement) V99__DummySQLSmells.sql 101 1 RX002 (Attempt to change password) V99__DummySQLSmells.sql 109 1 RX005 (GRANT TO PUBLIC statement) V99__DummySQLSmells.sql 113 1 RX007 (GRANT WITH ADMIN OPTION statement) V99__DummySQLSmells.sql 115 1 RX008 (ALTER USER statement) V99__DummySQLSmells.sql 117 1 RX009 (GRANT ALL statement) V99__DummySQLSmells.sql 119 1 RX010 (CREATE ROLE statement) V99__DummySQLSmells.sql 121 1 RX011 (ALTER ROLE statement) V99__DummySQLSmells.sql 123 1 RX012 (DROP PARTITION statement) V99__DummySQLSmells.sql 125 1 RX013 (CREATE TABLE statement without a PRIMARY KEY)
The test script
In case you don’t have access to GitHub, or the script gets moved or lost at some point, here it is in full:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
-- Deprecated Data Types Violation (TEXT, NTEXT, IMAGE) CREATE TABLE authors ( au_id CHAR(11) PRIMARY KEY, au_lname TEXT, -- Violation: Should be VARCHAR(MAX) au_fname TEXT, -- Violation: Should be VARCHAR(MAX) phone CHAR(12), address NVARCHAR(100), city NTEXT, -- Violation: Should be NVARCHAR(MAX) state CHAR(2), zip CHAR(5), contract BIT ); --Detecting Unqualified Column Names in Joins --Good SQL: SELECT Orders.OrderID, Customers.CustomerName FROM Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerID; -- Bad SQL (Flyway should flag OrderID, CustomerName as ambiguous): SELECT OrderID, CustomerName FROM Orders INNER JOIN Customers ON CustomerID = CustomerID; -- SELECT OrderID, CustomerName FROM Orders JOIN Customers ON CustomerID = CustomerID; -- -- a join Select * FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID; -- but this is fine (another rule (No Star) can be used for this) Select * from orders -- and so is this SELECT Orders.OrderID, Customers.CustomerName FROM Orders -- SELECT * Violation SELECT * FROM authors; Select au_fname+' '+au_lname, title from authors,TitleAuthor,publications where authors.au_id=TitleAuthor.au_id and publications.Publication_id =TitleAuthor.title_id -- SET IDENTITY_INSERT ON Violation SET IDENTITY_INSERT authors ON; -- GO inside stored procedure violation CREATE PROCEDURE sp_get_authors AS BEGIN SELECT * FROM authors; GO -- Violation: GO should not be inside a stored procedure END; -- Missing SET NOCOUNT ON in Stored Procedure CREATE PROCEDURE sp_get_titles AS BEGIN SELECT * FROM titles; END; -- Naming Conventions Violations (PK_, FK_, IX_ Prefixes Missing) CREATE TABLE titles ( title_id CHAR(6) CONSTRAINT title_pk PRIMARY KEY, -- Violation: Should be 'PK_titles' title TEXT, type CHAR(12), pub_id CHAR(4) CONSTRAINT pub_fk REFERENCES publishers(pub_id), -- Violation: Should be 'FK_publishers_pub_id' price MONEY, notes TEXT, pubdate DATETIME ); Drop table theNaughtyTable Truncate table theNaughtyTable ALTER TABLE theNaughtyTable DROP COLUMN TableName; -- Todo - Run the Flyway error check Grant select on Naughtyyable to maria,public; GRANT SELECT, UPDATE ON items TO mary WITH GRANT OPTION; -- Index Naming Violation CREATE INDEX title_index ON titles(title); -- Violation: Should be 'IX_titles_title' -- UNION instead of UNION ALL Violation SELECT title FROM titles UNION SELECT title FROM titles; -- Violation: Prefer UNION ALL unless explicitly removing duplicates -- Be explicit about JOIN type Violation SELECT a.au_id, t.title FROM authors a JOIN titles t ON a.au_id = t.pub_id; -- Violation: Should be INNER JOIN -- Right Join instead of Left Join Violation SELECT t.title, p.pub_name FROM titles t RIGHT JOIN publishers p ON t.pub_id = p.pub_id; -- Violation: Prefer LEFT JOIN for readability -- Short Table Alias Violation SELECT c.au_id, c.au_lname FROM authors c; -- Violation: Use 'authors' instead of 'c' for clarity -- Right Join instead of Left Join Violation SELECT t.title, p.pub_name FROM titles,publishers p ON t.pub_id = p.pub_id; -- Use explicit `JOIN` instead of comma joins. -- Dummy Data Insertion INSERT INTO authors (au_id, au_lname, au_fname, phone, address, city, state, zip, contract) VALUES ('172-32-1176', 'White', 'Johnson', '408 496-7223', '10932 Bigge Rd.', 'Menlo Park', 'CA', '94025', 1); --CREATE TABLE statement without a PRIMARY KEY constraint: CREATE TABLE ExampleTable ( ID INT, Name NVARCHAR(50) ); --A table created but has no MS_Description property added: CREATE TABLE ExampleTable ( ID INT primary key, Name NVARCHAR(50) ); --A DROP TABLE statement: DROP TABLE ExampleTable; --An attempt to change password: ALTER LOGIN [username] WITH PASSWORD = 'newpassword'; --TRUNCATE statement: TRUNCATE TABLE ExampleTable; --A DROP COLUMN statement: ALTER TABLE ExampleTable DROP COLUMN ColumnName; --A GRANT TO PUBLIC statement: GRANT SELECT ON ExampleTable TO PUBLIC; --GRANT WITH GRANT OPTION: GRANT SELECT ON ExampleTable TO [username] WITH GRANT OPTION; --GRANT WITH ADMIN OPTION: GRANT ALTER ANY LOGIN TO [username] WITH ADMIN OPTION; --ALTER USER statement: ALTER USER [username] WITH DEFAULT_SCHEMA = [schema_name]; --GRANT ALL: GRANT ALL ON ExampleTable TO [username]; --CREATE ROLE: CREATE ROLE ExampleRole; --ALTER ROLE: ALTER ROLE ExampleRole ADD MEMBER [username]; --DROP PARTITION: DROP PARTITION SCHEME PartitionName; --CREATE TABLE statement without a PRIMARY KEY constraint: CREATE TABLE ExampleTable ( ID INT, Name NVARCHAR(50) ); -- table created that has no MS_Description property added: CREATE TABLE ExampleTable ( ID INT, Name NVARCHAR(50) ); |
Conclusion
Flyway’s regex rules provide a configurable, lightweight approach to SQL code analysis. While not as powerful as the checks that use full SQL parsers, they catch many common mistakes and enforce some best practices. Their great advantage is that they are configurable.
A static code analysis is always useful because it checks what is in the SQL Script rather than the resulting metadata. As such, it provides a quick, lightweight safety net to prevent bad practices in migration scripts, or to ensure that code inserted only for testing or debugging is removed before the script gets into the migration chain.
This article gets you started with Flyway’s built-in rules but very soon you’ll want to start adding your own. In the next article, I describe how I develop and test new rules using a tool such as Regex Buddy and point out a few unique ‘gotchas’ around the Java regex syntax. I’ll also explain what I think is a more maintainable way of managing the rules, as your library grows, using a single JSON rules file and then auto-extracting from it the individual rule definition (.toml) files.
Tools in this post
You may also like
-

Article
Using ODBC in PowerShell Scripts and Callbacks
Flyway connects to database using JDBC, but when we're automating Flyway with PowerShell, we can't use JDBC directly to get access to the metadata we need to add useful reports and other functionality to Flyway's build and migration processes. This article demonstrates how to get what we need using ODBC from our PowerShell scripts, via a DSN.
-

Live training session
What’s new in Flyway
As a Redgate customer, you are invited to attend this exclusive training session to discover the what's new in Flyway.
-
Live training session
What’s new in Flyway: Introducing MongoDB
As a Redgate customer, you are invited to attend this exclusive customer training session to discover what's new in Flyway. In this 30-minute training session, our product team will demonstrate how you can integrate MongoDB into your Database DevOps pipeline and guide you through the process of introducing a new database into Flyway.
-

Article
Flyway 7.3.0 Released
Flyway 7.3.0 is out! This release contains new features and improvements over Flyway 7.2.0. Highlights You can find a detailed list of the changes in the release notes. Migration filename placeholder It can be useful to know the full name of a migration file at the time it’s executed, for auditing purposes. The migration description is of
-

Article
Flyway Desktop in Database Development Work: An Overview
For those new to Flyway Desktop, this article takes a strategic overview of the components of a Flyway Desktop project, how to set up a project for team-based development work, and how we can use the tool in conjunction with a version control system and CI servers to manage a database development and release process.
-
Article
A Flyway Teams Callback Script for Auditing SQL Migrations
Demonstrates a cross-database PowerShell callback script for reporting on and auditing Flyway migrations, telling you which scripts were used to create each version, when they were run, who ran them and more.





