Automating Flyway Development Chores using Database Diagrams
If you can produce a quick Entity-Relationship diagram for any version of a database, you'll have a simple way to 'sanity check' it for unreferenced tables, missing keys and other design flaws. This article shows how to auto-generate these diagrams when running a migration, using Flyway Teams and PowerShell.
You might think that the only purpose of Flyway is to apply migration scripts to a database, in the right order, to create whatever version of the database you wish. In fact, Flyway lends itself to being the centre of a development and deployment system and can help you automate many other development chores.
Developing databases is different to developing procedural code. Developers need more information and need to automate far more of the routine ‘chore’ work. Luckily Flyway, with its architecture of placeholders, callbacks and configuration files, is designed to make automation easy.
Catering for ad-hoc reports
Whenever Flyway does a migration run, it inspects the ‘locations’ that you’ve specified in the locations configuration parameter for any callback script that it must execute. If you’re using the community version of Flyway, you can use either SQL or Java callbacks. With Flyway Teams, you can also use PowerShell.
The sort of task that you’d generally want to script out at this point would be creating a build script, doing a backup of the new version or creating a database model. These are all-or-nothing tasks that don’t require input from you. You would never want a light backup, a well-grilled backup or a single-source backup: just a backup.
There are of course many other routine tasks to be done during a Flyway development, such as bug fixing, database code reviews, performance tuning, investigating potential data issues (e.g., causing problems or inconsistencies in business reports) or doing a security check. I like to call these the ‘canteen’ tasks because they feed on the results of the all-or-nothing tasks.
For each canteen task, you need a particular report to answer specific questions. For example, when performing a database code review, you’ll want to answer questions such as:
- What tables aren’t referenced by any other table?
- Are there any duplicate or near-duplicate indexes?
- Have you a table without any candidate keys?
- Are there any tables with columns incorrectly allowing NULLs?
You can extract the answers from the database model, for the version of database you’re investigating. It is all about making it easier to maintain database quality standards and, with this approach, you don’t even need access to the database itself. That is neat, because you then don’t need to learn the metadata calls for that particular RDBMS.
The FlywayTeamwork PowerShell framework that I use generates these models if you request them, for any of the more common RDBMSs (SQL Server, PostgreSQL, MariaDB, MySQL and SQLite). My article, Simple Reporting with Flyway and Database Models, shows how to generate the model, produced by a script called by Flyway, and then use it for simple reporting. In this article we’ll take it to a more advanced level.
Producing the code for a very simple Entity-Relationship diagram
Mapping and documenting the Foreign Key relationships between tables is one of those many rather tedious routine tasks that tend to be neglected when a team gets under pressure, which is a shame because it is so easy to spot mistakes in a diagram, whereas errors tend to get lost in lists or code. Far more time is wasted tracking down foreign key problems than are saved by abandoning diagramming. It is part of the greater task of working out the dependencies of a table and the consequences of making a change. So why not automate the process?
Databases are easier to develop if you have Entity-Relationship diagrams covering the tables within the domain of your work. I usually create the UML diagrams for designing databases and processes from PlantUML. You can design a database change, and communicate it to the team, by generating a diagram. These diagrams are scripts, so they can easily be placed in source control, and a change can automatically update the graphic.
Here is a small sample of the sort of thing you can produce:
PlantUML will create Entity-Relationship diagrams as well as classes, states, deployment, or Gantt charts. I’ve already demonstrated how it can produce a Gantt chart from the contents of the Flyway Schema History table, to track the progress of a Flyway project.
Although it will produce Entity Relationship diagrams, you generally wouldn’t want a diagram for an entire database: no paper-size is big enough for a typical corporate database. You’d be more interested in groups of inter-related tables but even then, you’d probably want to exclude certain relationships from the diagram.
Generate the PUML code for the E-R diagram from the database model
Your first task is to locate the model for the version of the database for which you want to generate the E-R diagram.
I’ll refer you to the Simple Reporting with Flyway and Database Models article for details of how to generate the model using Flyway and my PowerShell framework. If you are already using the project directory as your working directory, and have set up all your working parameters, you can read it in like this…
|
1 2 3 4 |
<# We can easily get hold of the JSON model of the database and convert it into a PowerShell object.#> $Model = ConvertFrom-json ( [IO.File]::ReadAllText("$($dbDetails.ReportLocation)\current\Reports\DatabaseModel.JSON") ) |
Alternatively, I’ve provided some sample models for various RDBMSs, so you’ve something to play with. You can read in any of these models, like this:
|
1 2 3 |
$Model = ConvertFrom-json ( [IO.File]::ReadAllText("<pathToModel>\<MyModelName>.JSON") ) |
Having done that, we can create the code for the diagram. Here is the script that will generate the PUML code from the model that we just read in:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
$PumlCode = @" @startuml ' hide the spot hide circle ' avoid problems with angled crows feet skinparam linetype ortho "@ $PumlCode += $model | Display-object -depth 3 | where { $_.Path -match '\$\..+?\.Table' } | foreach{ $bits = $_.Path.split('.'); [pscustomobject]@{ 'TableName' = "$($Bits[1]).$($bits[3])" } } | foreach { "`r`nentity $($_.TableName) " } $PumlCode += $model | Display-object -depth 10 | where{ $_.path -like '$.*.*.*.foreign key.*.Foreign Table' } | foreach{ $bits = $_.Path.split('.'); [pscustomobject]@{ 'TableSchema' = "$($Bits[1])"; 'TableName' = "$($bits[3])"; 'Key' = "$($bits[5])"; 'ReferenceSchema' = "$($_.Value)".Split('.')[0]; 'ReferenceTable' = "$($_.Value)".Split('.')[1] } } | foreach { "`r`n$($_.TableSchema).$($_.TableName) }|..|| $($_.ReferenceSchema).$($_.ReferenceTable) " } $pumlCode +=@" @enduml "@ $PumlCode |
This will produce the following PUML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
@startuml ' hide the spot hide circle ' avoid problems with angled crows feet skinparam linetype ortho entity dbo.authors entity dbo.discounts entity dbo.editions entity dbo.employee entity dbo.jobs entity dbo.prices entity dbo.publications entity dbo.publishers entity dbo.pub_info entity dbo.roysched entity dbo.sales entity dbo.stores entity dbo.tagname entity dbo.tagtitle entity dbo.titleauthor dbo.discounts }|..|| dbo.stores dbo.employee }|..|| dbo.jobs dbo.employee }|..|| dbo.publishers dbo.employee }|..|| dbo.jobs dbo.pub_info }|..|| dbo.publishers dbo.roysched }|..|| dbo.publications dbo.sales }|..|| dbo.stores dbo.sales }|..|| dbo.publications dbo.tagtitle }|..|| dbo.tagname dbo.tagtitle }|..|| dbo.publications dbo.titleauthor }|..|| dbo.authors dbo.titleauthor }|..|| dbo.publications @enduml |
Viewing and editing the E-R diagram
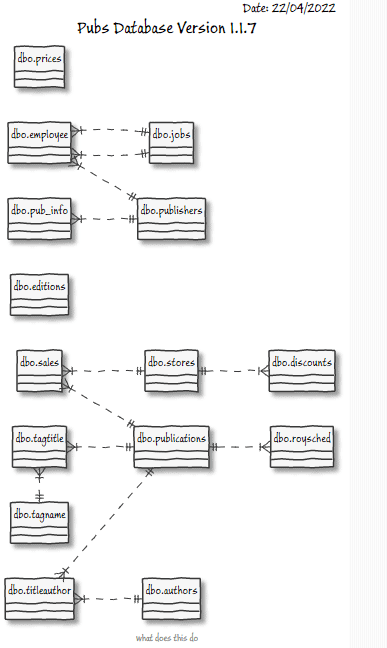
We can start very simply with PUML. All you need is the web-based PlantUML editor to render the above PUML code into an E-R diagram. Simply paste in the code and hit “Submit“, which gives our initial diagram (we have to shrink even this database to view it):

We can do a bit better than that, though. Firstly, we can make it a lot prettier by editing the PlantUML code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
@startuml ' hide the spot hide circle ' avoid problems with angled crows feet skinparam wrapWidth 150 skinparam handwritten true skinparam monochrome true skinparam packageStyle rect skinparam defaultFontName Buxton Sketch skinparam shadowing true skinparam MessageAlign left skinparam header{ FontColor black FontSize 14 } left to right direction Title Pubs Database Version 1.1.7 header Date: 22/04/2022 footer what does this do entity dbo.authors entity dbo.discounts entity dbo.editions entity dbo.employee entity dbo.jobs entity dbo.prices entity dbo.publications entity dbo.publishers entity dbo.pub_info entity dbo.roysched entity dbo.sales entity dbo.stores entity dbo.tagname entity dbo.tagtitle entity dbo.titleauthor dbo.discounts }|.up.|| dbo.stores dbo.employee }|..|| dbo.jobs dbo.employee }|..|| dbo.publishers dbo.employee }|..|| dbo.jobs dbo.pub_info }|..|| dbo.publishers dbo.roysched }|.up.|| dbo.publications dbo.sales }|..|| dbo.stores dbo.sales }|..|| dbo.publications dbo.tagtitle }|.right.|| dbo.tagname dbo.tagtitle }|..|| dbo.publications dbo.titleauthor }|..|| dbo.authors dbo.titleauthor }|..|| dbo.publications @enduml |
My additions give the code hints on displaying the diagram. This has to be done by hand. The use of a special ‘handwriting’ font and ‘hand-drawn’ lines is handy for people who are struggling with process and don’t realize that this is a ‘working’ diagram rather than a splendid design proposition. It must be done on a PC because it uses a font that isn’t available to online diagram generators.
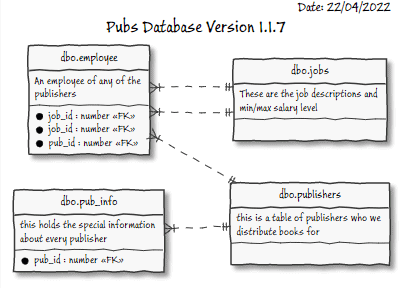
Here is the resulting “prettified” E-R diagram:
This will immediately flag up missing relationships between tables, of course, but we could really do more, and we will…
Which keys are being used?
We’d like to know which keys are being used to reference other tables, and which keys are being referenced. In the model, we already pick up these details for the comments or documentation that are applied to a table, so we can add them to our diagram. We could do with a title and date too, so let’s add those as well.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
<# we find every table reference from the model simply by examining the Foreign keys #> $title="Pubs Database Version 1.1.7" $date="$((Get-date).Date.ToString().Replace('00:00:00', ''))" $footer='Produced by PlantUML' $Reference = $model | Display-object -depth 10 | where{ $_.path -like '$.*.*.*.foreign key.*.Foreign Table' } | foreach{ $bits = $_.Path.split('.'); [pscustomobject]@{ 'TableSchema' = "$($Bits[1])"; 'TableName' = "$($bits[3])"; 'Key' = "$($bits[5])"; 'ReferenceSchema' = "$($_.Value)".Split('.')[0]; 'ReferenceTable' = "$($_.Value)".Split('.')[1] } } # now we can <a id="post-6917917-_Hlk103852679"></a>get all the tables that are either referencing or referenced # in any real database, the resulting diagram would be too big but we will # deal with that problem $Tables = $Reference | Select TableSchema, Tablename # We add in the referenced tables $Tables += $Reference | foreach{ [pscustomobject]@{ 'TableSchema' = $_.ReferenceSchema; 'Tablename' = $_.ReferenceTable } } <# we boil this down to a list of all the participating tables and for each of them we produce a simple PUML code that defines each entity. We can read any additional information we need from the table, in this case the comment#> $EntitiyCode = $Tables | sort -Unique tableSchema, Tablename | Foreach{ $TableSchema = $_.tableSchema; #remember the table schema $TableName = $_.tablename; #and the table name #now we can get the value of the comment for that table. #Lucky you did comments eh? $comment = $model.$TableSchema.table.$TableName.comment #we reference the foreign keys. one after another to get a list of keys $keys = $model.$TableSchema.table.$TableName.'foreign key' | foreach{ $_.psobject.Properties.Value } | select -ExpandProperty Cols #We can now create the data within the table entity of the foreign #keys accesses. If you don't have table documentation, you might need #some columns too $TheLisOfKeys = ($keys | foreach{ "* $($_) : number <<FK>>" }) -join "`r`n " @" entity "$TableSchema.$TableName" { $comment -- $TheLisOfKeys } "@ } $EntityRelations = $reference | foreach{@" $($_.TableSchema).$($_.TableName) ||..|| $($_.ReferenceSchema).$($_.ReferenceTable) "@ } $pumlCode = @" @startuml ' hide the spot hide circle ' avoid problems with angled crows feet skinparam linetype ortho skinparam wrapWidth 150 skinparam MessageAlign left skinparam header{ FontColor black FontSize 14 } Title $title header Date: $date footer $footer $($EntitiyCode -join "`r`n") $($EntityRelations -join "`r`n ") @enduml "@ $PumlCode |
This script will produce the following PUML code. You can prettify it quite a lot more, but I am trying to keep this relatively simple.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
@startuml ' hide the spot hide circle ' avoid problems with angled crows feet skinparam linetype ortho skinparam wrapWidth 150 skinparam MessageAlign left skinparam header{ FontColor black FontSize 14 } Title Pubs Database Version 1.1.7 header Date: 22/04/2022 footer Produced by PlantUML entity "dbo.authors" { The authors of the publications. a publication can have one or more author -- } entity "dbo.discounts" { These are the discounts offered by the sales people for bulk orders -- * stor_id : number <<FK>> } entity "dbo.employee" { An employee of any of the publishers -- * job_id : number <<FK>> * job_id : number <<FK>> * pub_id : number <<FK>> } entity "dbo.jobs" { These are the job descriptions and min/max salary level -- } entity "dbo.pub_info" { this holds the special information about every publisher -- * pub_id : number <<FK>> } entity "dbo.publications" { This lists every publication marketed by the distributor -- } entity "dbo.publishers" { this is a table of publishers who we distribute books for -- } entity "dbo.roysched" { this is a table of the authors royalty scheduleable -- * title_id : number <<FK>> } entity "dbo.sales" { these are the sales of every edition of every publication -- * title_id : number <<FK>> * stor_id : number <<FK>> } entity "dbo.stores" { these are all the stores who are our customers -- } entity "dbo.tagname" { All the categories of publications -- } entity "dbo.tagtitle" { This relates tags to publications so that publications can have more than one -- * title_id : number <<FK>> * TagName_ID : number <<FK>> } entity "dbo.titleauthor" { this is a table that relates authors to publications, and gives their order of listing and royalty% -- * title_id : number <<FK>> * au_id : number <<FK>> } dbo.discounts }|..|| dbo.stores dbo.employee }|..|| dbo.jobs dbo.employee }|..|| dbo.publishers dbo.employee }|..|| dbo.jobs dbo.pub_info }|..|| dbo.publishers dbo.roysched }|..|| dbo.publications dbo.sales }|..|| dbo.stores dbo.sales }|..|| dbo.publications dbo.tagtitle }|..|| dbo.tagname dbo.tagtitle }|..|| dbo.publications dbo.titleauthor }|..|| dbo.authors dbo.titleauthor }|..|| dbo.publications @enduml |
In my case, for the pubs the sample database I’ve provided, you get this diagram:
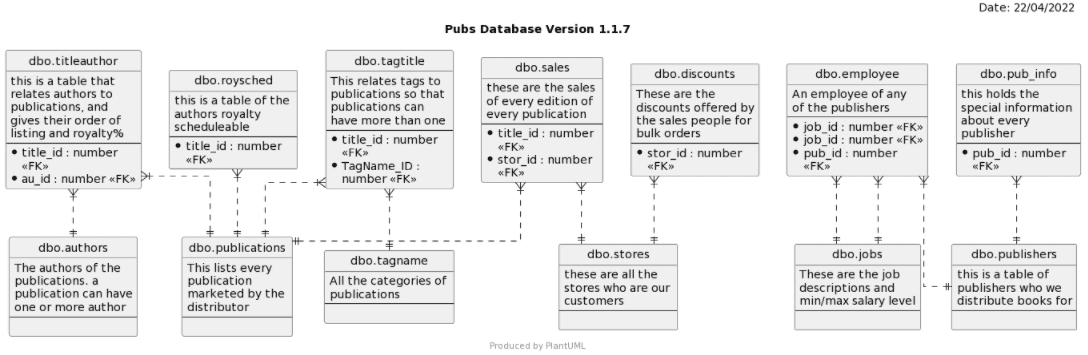
Investigating relationships for a subset of tables
Well, this is fine, but it still doesn’t go quite far enough. Even with our small, sample database the diagram starts to get cramped. We can do help a bit by altering the direction of the relations but, actually, we probably don’t even want the entire database plotted out, just those tables that are directly involved in our investigation.
This leads us to a central theme of this article, and more generally of what’s required to support a DevOps approach to team-based development: you cannot predict all the requirements that the team will have for information. You’ll never provide everything necessary in advance. It is much better to provide the ingredients (the model and the code to extract information from it) than the eventual meal. If you just served up an ER diagram of the entire database on every revision, it would make anyone’s eyeballs swivel even if they had the necessary eyesight. It is much better just to provide the basic information you need, by automation, and at that point allow you to find out just what you need.
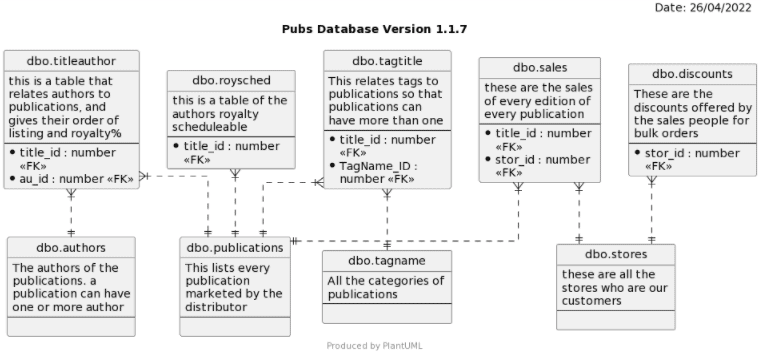
In this case, we’ll improve the code so you can specify a group of tables for which you need to investigate the relationships. We’ll do it just by passing the name of a member of the group of tables that you need to examine. In this case, we just specify a member of the group such as ‘publications’ to get just a collection of linked tables.
I can’t show in the article all the code to allow you to do this, so I’ve prepared it as a Cmdlet on Github called Create-PUMLEntityDiagram.ps1. However, it really is just a slightly more complex version of the code I’ve shown here.
Either you can generate the model for the whole database or, to get the list of tables, you choose one the tables from the group that you wish to investigate:
|
1 2 3 |
Create-PUMLEntityDiagram '*' '*' $model # do them all. It is a small database. Create-PUMLEntityDiagram 'dbo' 'TagTitle' $model Create-PUMLEntityDiagram 'dbo' ' TagTitle ' $model 'Publications from PubsMySQL 1.1.7' 'Phil Factor Enterprises' |
In this case, I chose TagTitle, but it could be any of the main group.
Summary
Once you have a model of a database, you have the opportunity for gaining a lot more information about the database you are developing. A model is merely a handy way of taking a snapshot of the main features of a database. It in turn facilitates a lot of reports, quality checks, diagrams and programming aids.
It isn’t always possible to extract all the information you need just from the model. With performance work, for example, you need the live database. However, for a lot of the time, information derived from a model can give you many insights into things that aren’t quite right with a database.
Fortunately, Flyway evolved with the advice and input of teams who wanted to automate as many of the processes around database development as possible. It makes all this much more convenient: you can generate a model from a callback and then kick off whatever further actions and reporting from that model that you need.
Tools in this post
You may also like
-

FoRG Hangout
FoRG Hangout Nov 16 2021: Flyway Desktop with Stephanie Herr
Watch this FoRG session on demand to learn about Flyway Desktop and Flyway Hub (and read more about both on the forum!). If you have any questions, just get in touch with friends@red-gate.com
-

Article
What is Flyway Enterprise?
How Flyway Enterprise will help you ensure that databases and applications can grow and develop in step, and to implement a workflow for delivery of database changes that is resilient, repeatable, fast and visible.
-
Article
Adding Test Data to Databases During Flyway Migrations
How to generate "realistic but fake" SQL Server test data, using SQL Data Generator, and then use SQL Data Compare to produce an INSERT script that Flyway can run to load the data into the database. The technique is useful for managing small volumes of test data or for "topping up" existing data when you create new entities.
-
Article
Reporting on the Progress of a Flyway Database Development Project
This article demos a novel way to report on the progress of your Flyway development project. It provides both SQL and PowerShell versions of code that extracts information for each database version from the Flyway schema history table and then plots it in a Gantt chart.
-
Article
Running SQL Code Analysis during Flyway Migrations
A set of PowerShell automation script tasks for running database build and migrations tasks. This article describes the SQL code analysis task, which will check the syntax of the SQL code in your databases and your migration scripts for 'code smells'.
-

Article
Why Would You Pay for Flyway?
Flyway is an open-source database deployment tool that also includes a paid tier called Teams. Since it’s open-source, you can just download Flyway and run it for free. You’ll get a robust DevOps tool to assist you in deploying your databases just like you deploy your code. It just works. So, why would you even