How to Classify and Protect your Development Data Automatically using SQL Data Catalog and Data Masker Command Line
Chris Unwin describes a classification-driven static data masking process, using SQL Data Catalog to classify all the different types of data, its purpose and sensitivity, and then command line automation to generate the masking set that Data Masker for SQL Server can use to protect this data.
The challenges of masking data
Static data masking is the process of removing or replacing sensitive information, such that the original data subject cannot be identified, making it safe to make certain parts of that data available for their own development work and testing, or for training, research.
The fundamental challenge though, is both in identifying all the data that needs to be masked, and then in working how to mask certain data values so that this data is always fully protected, and still remains fit for its proposed use within the non-production workflow.
This data classification and masking process is often difficult, especially in large enterprises that maintain several large, complex data systems and collect data from many sources (see Masking Data in Practice). As such, it can quickly become a drawn out task, one that is hard to get right the first time, and impossible, without automation, to get right every time we need to create or refresh data in a non-production system.
The State of Database DevOps Report 2020
This survey of 2000 respondents found that 62% of companies were using at least one copy of a Production database for development and testing purposes, and of those 42% reported that at least some personal information was not masked.
This article outlines a classification and masking process that encourages iteration and collaboration. It uses automation wherever possible, but remains easily customizable to each organization’s requirements. It ensures that all sensitive and personal data is correctly and consistently masked, every time, but retains the ‘look-and-feel’ of the real data. It has been proven in some organizations to shorten the whole process dramatically, by weeks or even months.
So, where do we start? The first step is to identify and classify all the different types of data, where it is stored, its business owners, and its purpose and sensitivity. For this we need SQL Data Catalog.
SQL Data Catalog: data identification, before de-identification
Any organization that collects personal, private, or sensitive data now has a legal obligation to prove that it is done so securely. Before making this data available for use within their organization, they must first either remove any Personally Identifiable Information (PII), Protected Health Information (PHI), and any other confidential information, or ‘obfuscate’ it such that it cannot possibly reveal the original data subject.
Before an organization can do this, it must first have a complete catalog of what types of data it stores where, and why. Like all good security practices, data cataloging should be built into the underlying data protection process to achieve “Data Protection by Design and Default“, a phrase that, in a variety of forms, is built into many pieces of global data protection legislation.
Redgate SQL Data Catalog creates the data classification metadata that describes the data that your organization uses. It will allow you to define, apply and retain a taxonomy of tags to describe all the different types of data stored in your SQL Server databases. This taxonomy will likely be based on a conceptual business model of the enterprise, agreed at the organizational level.
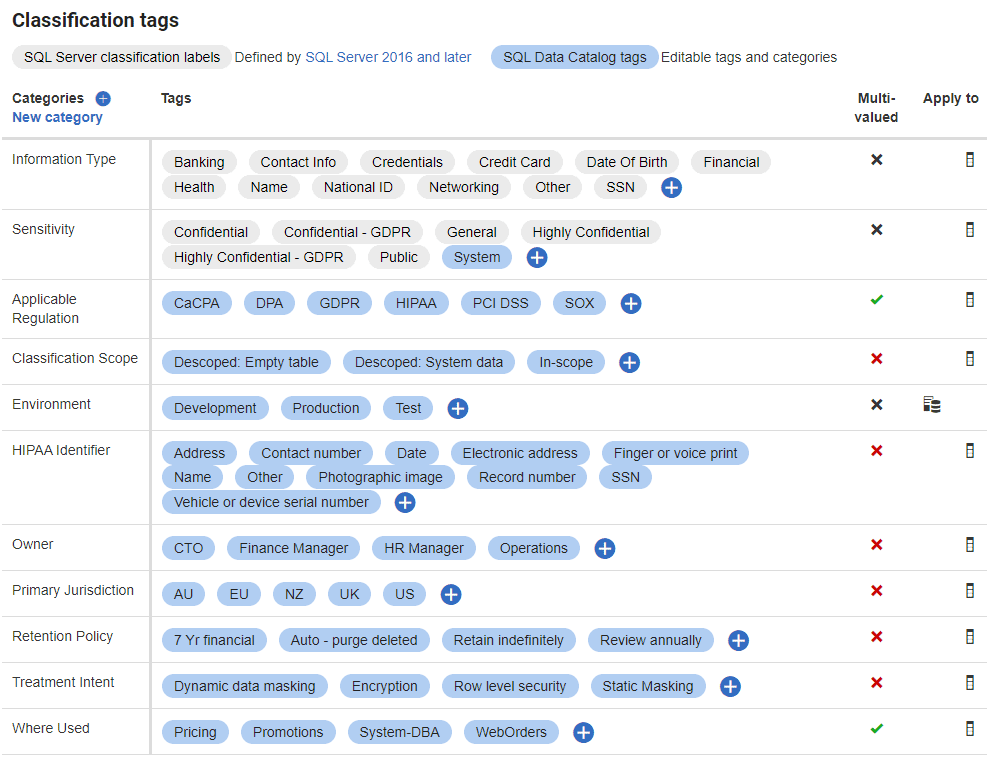
SQL Data Catalog then provides analytical filters, a customizable suggestions engine and automation through PowerShell, to allow you to classify all the data in a database quickly, thoroughly, and consistently.
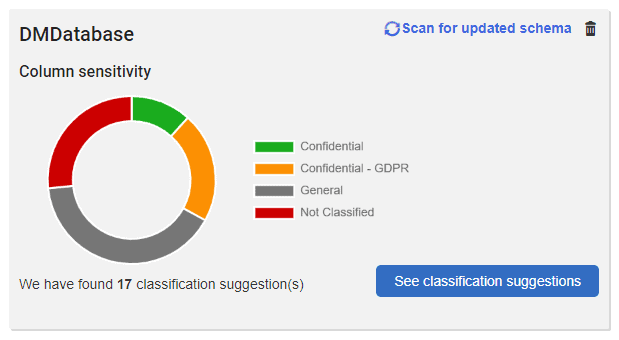
The classification process has often been regarded as a monolithic effort, proceeding field by field, marking each one as sensitive or otherwise, rather like playing a protracted game of ‘battleships’. However, with SQL Data Catalog, it becomes more like a team-based game of Minesweeper, making successive ‘sweeps’ through the data, using filters to drill down to, and classify, specific data types, in line with the agreed policy, or business model, to “de-scope” unimportant or irrelevant fields and then auto-catalogue them using PowerShell, and so on.
Once you have achieved this initial data classification, you will have the basis from which to ensure data is kept secure and is masked every single time. However, much like the challenges of outdated Excel spreadsheets, if the data catalog is not built into the underlying database change management process, and frequently refreshed to account for the changing nature of the data, then it can quickly go out of date and lose all relevance.
Acting on classification to protect your data
With the catalog in place, the organization can use it to begin the process of data masking, sometimes referred to as data de-identification or data pseudonymization. It encompasses a range of practices, including substituting sensitive data with realistic non-sensitive values, shuffling data, truncating data, and others. While each one is well understood, masking an entire database can, nevertheless, be a complex task.
One approach is to import the data classifications into Data masker, as a masking plan, and then work through each column, building out a set of masking rules that will ensure that each bit of personal and sensitive data we’ve identified is always masked and protected. We can so this either using SQL scripts, or from within Data Masker, as described here: Getting Started with Data Masker for SQL Server: I Want to Mask A Database.
However, with the latest improvements to Data Masker’s command line, we can use the data classifications in SQL Data Catalog to auto-generate a prepared data masking set to cover each of the different types of columns that are classed as sensitive. This is achieved by selecting templates that will map each data classification to a substitution rule that that Data Masker will use to “de-identify” values.
For well-designed databases, and straightforward masking needs, we may not require more than this. However, Data Masker also allows us to build out and customize the rules it generates, so that we can fine tune exactly how our masked data will appear in non-Production environments.
We only need 3 steps to achieve this, or 4 is you require the extra customization.
1. Map masking data sets to columns
To generate the masking data sets automatically, Data Masker needs a JSON mapping file that will indicate to it which “templates”, should be used for which columns. SQL Data Catalog provides a range of pre-existing mapping ‘templates’ that cover a wide variety of sensitive information. Each template defines an automatic masking set that will ensure that the resulting information will be masked thoroughly, but still be realistic and useful.
There are two ways to do this:
- Let SQL Data Catalog pick a suitable template, and therefore masking set, for each column, and use these mappings to generate the mapping file – in which case, skip to step 2
- Specify which of the pre-existing template mappings it ought to use for which columns.
To specify the templates, you will need to provide a category of tags within SQL Data Catalog’s taxonomy that can be used for this mapping. The category can be called whatever you prefer (I have used “Masking Data Set” for this article) and it will need to be populated with tags that match the names of existing templates exactly (see the documentation for the full list).
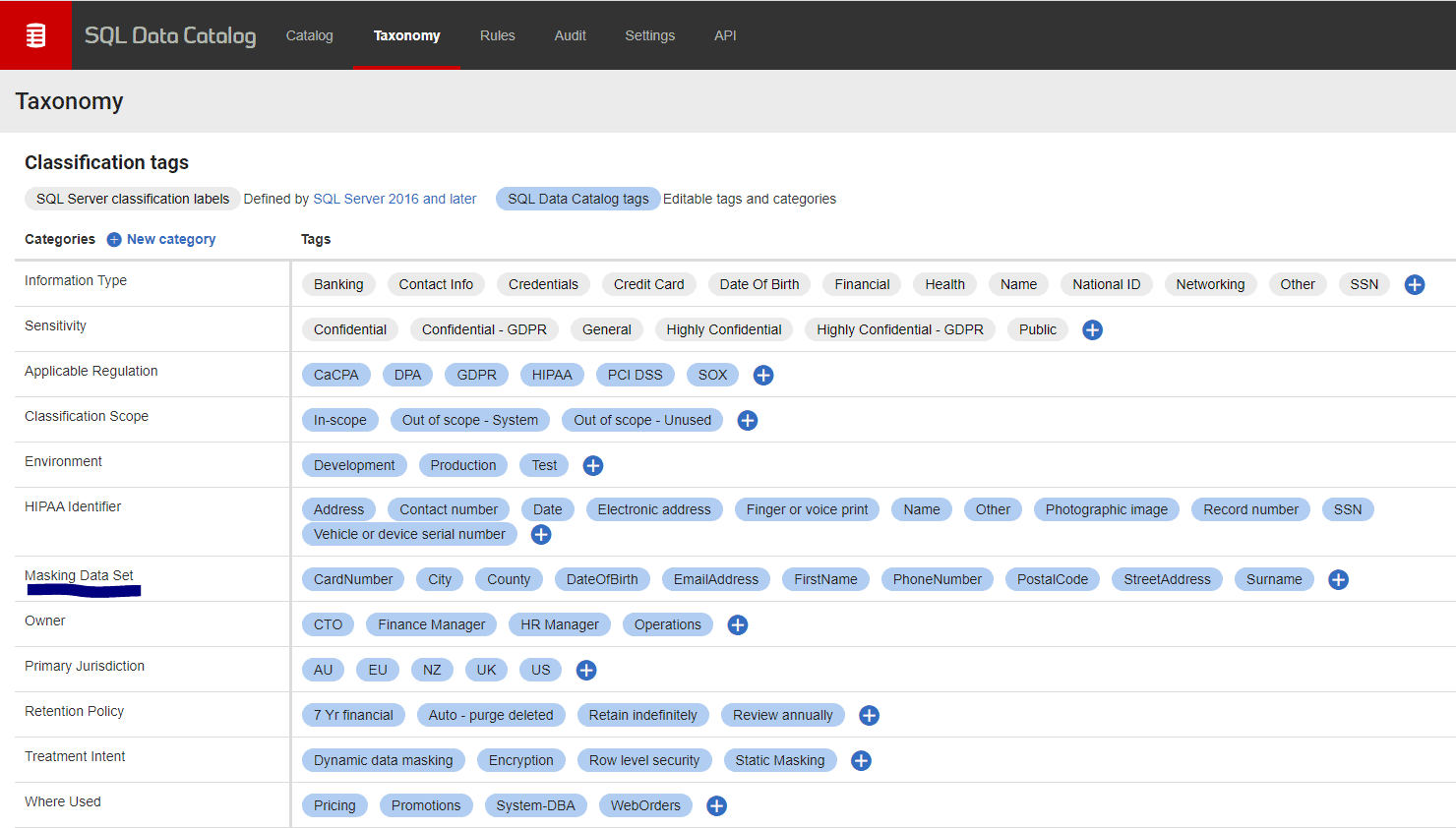
Then simply apply these tags to columns as part of your classification workflow. In the following example, I’m applying the masking data set tag called EmailAddress template to the customer_email column of the dm_customers table:
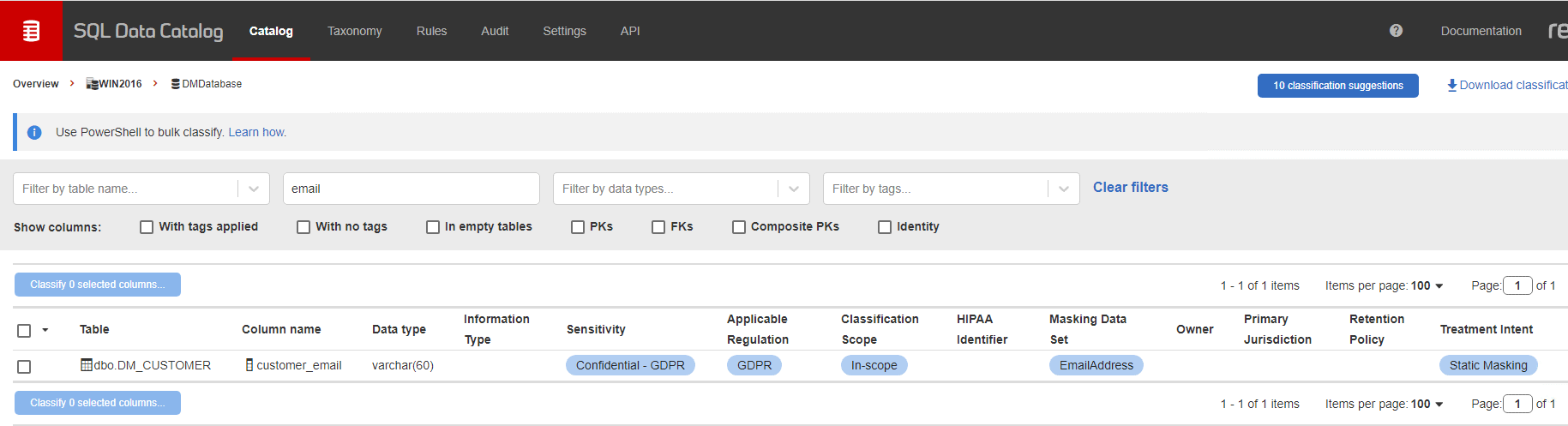
2. Generate the mapping file
We can now invoke Data Masker’s command line to create the mapping file. All of the command line switches can be found in the documentation. We will need to specify the column-template-build-mapping-file command which will require 3 specific switches to identify and generate an accurate column mapping file:
--sensitivity-category– the category exactly as it appears in SQL Data Catalog that you have used to describe how a sensitive column should be masked. In the above screenshot, this would be ‘Treatment Intent’.--sensitivity-tag– the exact tag within thesensitivity-categorythat is used to denote the columns that will require masking with Data Masker. In this example, ‘Static Masking’.--information-type-category– the category applied to the column that indicates what type of masking data set we would like applied, in this case ‘Masking Data Set‘.
Only columns marked with the –sensitivity-tag that you choose, in the above example, the ‘Static Masking’ tag, will be included in the masking set. Even if another category highlights that a column is sensitive, nothing will be generated if it does not have a tag matching the one selected for automation.
Although none of these switches are required by this command, and it will build a mapping file regardless, they allow us to generate rules for only the sensitive columns we have identified as needing static data masking. Every column that has the --sensitivity-tag that we identified in the mapping file will be masked, even if we did not give it a tag from the “Masking Data Set” category.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Location and Key for SQL Data Catalog $catalogUri = "http://[YourCatalogServer]:15156" $apikey = "[YourAPIKey]” # Target database $server = "[YourTargetServer]" $database = "[YourTargetDatabase]" # Files needed by Masker $logDirectory = "C:\DataMaskerFiles\Logs" $mappingFile = "C:\ DataMaskerFiles \mapping.json" $parfile = "C:\ DataMaskerFiles \PARFILE.txt" $maskingSet = "C:\ DataMaskerFiles \$database.DMSMaskSet" # Invoke Data Masker to create set & ‘C:\Program Files\Red Gate\Data Masker for SQL Server 7\DataMaskerCmdLine.exe’ column-template build-mapping-file ` --catalog-uri $catalogUri ` --api-key $apikey ` --instance $server ` --database $database ` --log-directory $logDirectory ` --mapping-file $mappingFile ` --sensitivity-category "Treatment Intent" ` --sensitivity-tag "Static Masking" ` --information-type-category "Masking Data Set" |
Running this command produces the JSON mapping file needed to mask this copy of the database:
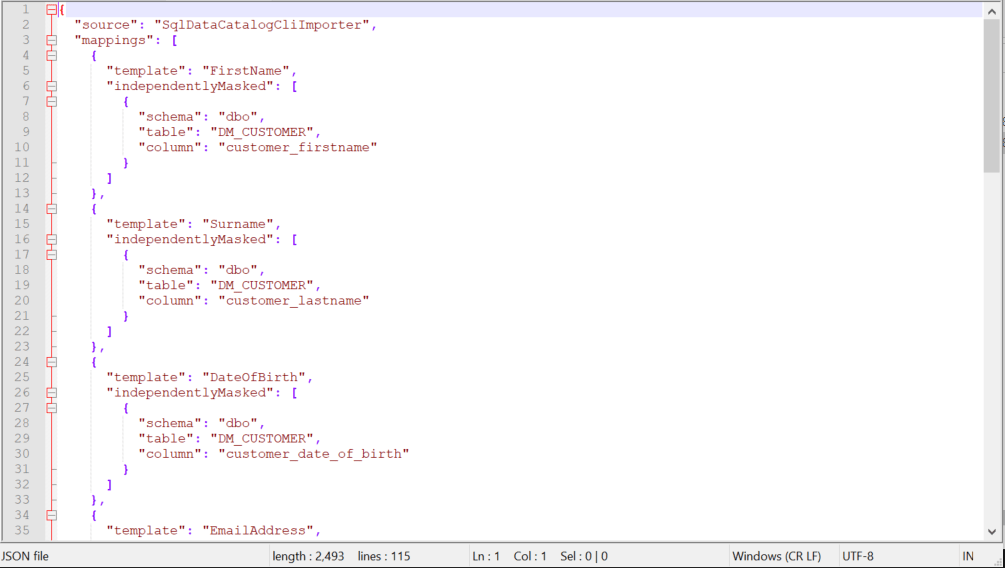
Notice that I did not provide a “Masking Data Set” tag for customer_company_name:

However, because this column is tagged as “Treatment Intent”: “Static Masking”, SQL Data catalog has examined it, and assigned it a ‘catch all’ masking data set of ShortString, since it has a datatype of varchar(60).

The outcome of this process is a JSON mapping file that lets Data Masker know what templates we would like to be applied to which columns, when creating the substitution rules for masking. This means that although we are generating it automatically, we can still have more granular control over what data gets generated into which columns, to add realism.
3. Generate the Data Masker ‘Masking Set’
Once you have your mapping file, you can follow the above PowerShell with one further command, the build command, which will instruct Data Masker to use the mapping file to build the necessary ‘masking set’. It will also try to connect to the database to which the masking set will be applied, to refresh its understanding of the schema, so it may be desirable to use a non-production copy for this exercise.
For the build command, we can specify either Windows or SQL authentication, and then the switches with the same locations as in the previous script, but with the inclusion of the mapping file:
|
1 2 3 4 5 6 7 |
& ‘C:\Program Files\Red Gate\Data Masker for SQL Server 7\DataMaskerCmdLine.exe’ build using-windows-auth ` --mapping-file $mappingFile ` --log-directory $logDirectory ` --instance $server ` --database $database ` --masking-set-file $maskingSet ` --parfile $parfile |
Data Masker will then get to work, first by connecting to and getting an understanding of the structure of the database: keys, indexes, tables and so on and then using the mapping JSON file to build substitution rules for all the sensitive columns that have been selected for static masking.
Templates will be applied to the mapping of column to data set or the catch all will be applied, and where certain templates like Names or Credit Card Numbers are required Data Masker will split these values across several dependant substitution rules with different samples to automatically provide a more realistic distributed set of values. The following screenshot show the files generated by the build command, including the auto-generated masking set (.DMSMaskSet):

We can open the auto-generated masking set and we can see that dependent rules are generated to create more meaningful sample values, but are serialized to prevent concurrent running

Now that we have generated the Masking Set we can either choose to run it automatically, either by passing it to SQL Clone as part of our provisioning workflow, or via the Data Masker command line, using the Run command.
However, as mentioned earlier, for more complex databases, it is difficult to get data masking correct every single time with automation, so at this point there may be some changes we may wish to make to the masking set, according to our requirements.
4. (Optional) Customize the Data Masker masking set
In addition to the imperative of protecting data, the masking process must ensure that the masked data remains fit for purpose. To be useful for development or test work, for example, the masking process must try to retain the same distribution and characteristics as the original data. Sometimes this can be a little more complicated. For example, sensitive data might be included in Primary or Foreign keys, as well as other constraints, rules, and triggers, making it more difficult to mask data while retaining relational integrity and data consistency.
This means that we may need to use the auto-generated masking set as the starting point, and then adapt it to ensure the data remains realistic. To the auto-generated set above, for example, I added table-to-table synchronization rules to restore the relationship between DM_Customer and DM_Customer_Notes, and also removed the column masking “Email” from the substitution rule, instead adding a Row-Internal Synchronization rule to create a realistic email address from the now-masked first and last names:

If you’re unsure where to start with making changes to a masking set or which types of rules you may wish to use for certain tasks, you can learn more about building a masking set in the Redgate University course.
Conclusion
Together, SQL Data Catalog and Data Masker provide us with a best-practice, flexible, and automated process for data protection during database provisioning, much like global data community organisation PASS were able to implement.
With the enhanced command line integration in Data Masker for SQL Server we can remove the bottleneck of having to create individual masking rules manually from scratch, by generating masking sets automatically, from our data classifications.
This gives us confidences that all the PII we hold is identified, classified, and then sanitized, before it’s made available for reuse elsewhere in the organization. Also, by preserving the characteristics of the original data, in the masking process, data masker ensures that the masked data remains useful to the organization. For example, it will allow developers and testers to work rapidly and effectively, test and re-work changes, and so perform some of hardest testing as early as possible. This is one of the most obvious and achievable methods of ensuring our testing is done right and that we deliver value to end users, without putting their data at risk.
Keen to learn more? Check out the following resources:
- Tactics for classification using SQL Data Catalog (Webinar)
- Evaluating SQL Data Catalog using Docker Containers (Product Learning)
- 5 reasons why SQL Server teams should take ownership of cataloging their data (Whitepaper)
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
You may also like
-

Article
The Database DevOps Challenges SQL Provision Solves
SQL Provision helps to accelerate the delivery of database changes, by enabling an organization to provide database copies, and the right data, to all parts of the deployment pipeline that need it, with a light footprint, and securely. Tony Davis explains how.
-

Article
Meeting your CCPA needs with Data Classification and Masking
This article will explain how to import the data classification metadata for a SQL Server database into Data Masker, providing a masking plan that you can use to ensure the protection of all this data. By applying the data masking operation as part of an automated database provisioning process, you make it fast, repeatable and auditable.
-
Article
Approaches to masking email addresses
Chris Unwin explains the basic approaches to anonymizing email addresses, and shows how Data Masker can generate realistic email addresses, based on faked names, and even retain the correct distribution of email providers.
-

Article
A quick guide to the New Zealand Privacy Act 2020 for DBAs
December 1 saw the introduction in New Zealand of the Privacy Act 2020 which not only brings increased protection for individuals but also has some new implications for businesses, including increased fines for non-compliance and the reporting of serious privacy breaches. However, the changes and impact may be less than organizations fear because the act
-

Article
The Need for a Data Catalog
In the event of a breach of personal data, any organization must produce proof that they understand what data they hold and where, and how it is being used, and that they have enforced the required standards for access control and security. To make all this possible, it is essential to build a complete model of the data and its lineage, and a data catalog is the first step in this process.
-
Article
A Basic Technique for Masking Address Data using Data Masker
Grant Fritchey provides a simple way to create fake address information that still looks real. The compromise is that it uses random data distributions and doesn't maintain any correlation between postal codes, states and cities, so won’t accurately reflect the real address data.