Getting Started with Data Masker for SQL Server: I Want to Mask A Database
Grant Fritchey explains what's involved in masking a SQL Server database. It can seem a daunting task, but it all becomes a lot more logical if you start from a plan, based on agreed data classifications, and then use a tool like Data Masker to implement the masking, and track progress.
My previous article in this series explored some of the masking rules and features of Data Masker, and how to use them to mask columns in a table, in order to meet specific business requirements. This article extends that process to masking a database. To a large degree, this just means masking hundreds of columns, so performing the same tasks in the last article, but hundreds of times. However, when we need to mask an entire database, in compliance with regulations, we need to work to a plan that tells us exactly what data we need to mask. We must also consider the database’s overall structure, as this affects choices made in the tool, from the order of operations to the specific rules used and how you use them.
Compliance and data classification
From the General Data Protection Regulation (GDPR) to the California Citizen’s Privacy Act (CPPA), more and more, we have compliance driving a lot of our decisions within IT. I’m going to assume that prior to starting this project of masking the database, you’ve already examined your database and defined what needs to be masked and what doesn’t.
One mechanism for doing this would be to use the data classification functionality built into SQL Server Management Studio (SSMS). This tool uses column names to automate part of the data classification process. I’m not going to go into the details here; I’ll just outline part of what it can do. First, you can let it scan your database to suggest data classifications. You can also add them yourself, manually. The output from the tool looks something like this:
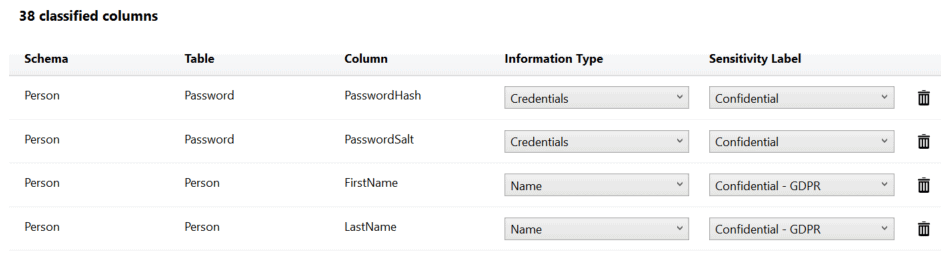
The classification information is stored with your tables as extended properties. These can then be added to source control along with the rest of your database to ensure that your classification documentation is deployed to production. You can also generate a report showing the distribution of the sensitive and personal data across your database:
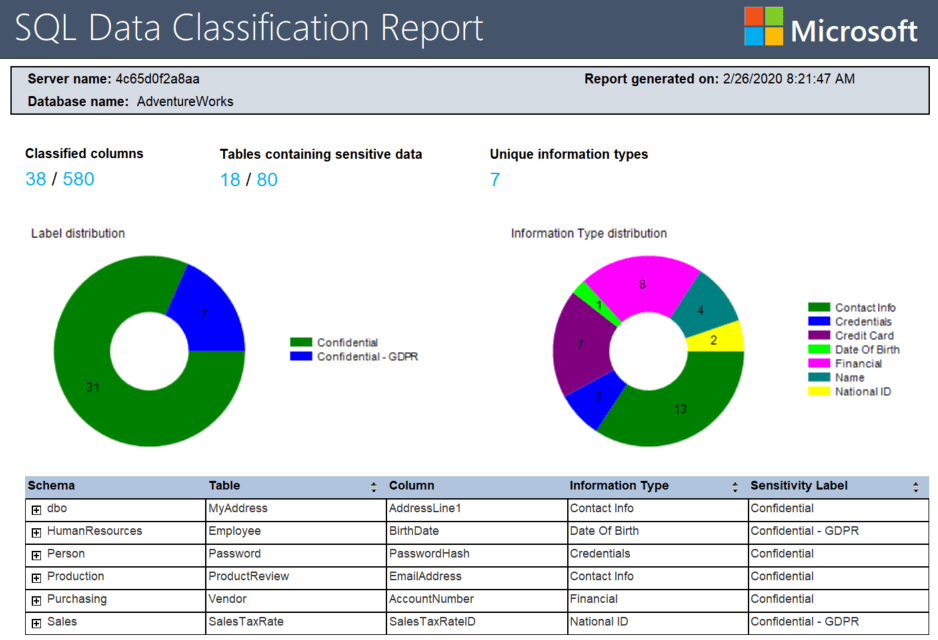
Redgate also has a data classification tool called SQL Data Catalog. It works with the SSMS classification system, and can import those classifications, but offers a lot more. It supports an open taxonomy, so you can add and edit your own classification categories and tags. It also makes it easy to use the classifications as the basis for data masking, as part of an automated database provisioning process.
Whichever way you do it, even if it means just putting pen to paper and writing down the classifications, it is an important step because it helps to provide a checklist of “columns to be masked” within the database.
Database structure considerations
Obviously, the data types within the columns are going to matter. However, concerns around the data structure goes beyond that. First, our database may have, really, should have, foreign key constraints that ensure referential integrity across our tables. Depending on the choices we make for masking, and the columns being masked, we may have to account for those foreign keys, for example, if a given column is both being masked and is part of a primary key. Luckily, SQL Data Masker provides rules for disabling and re-enabling foreign keys, as well as rules for dealing with triggers and indexes. You may need to plan for use of these rules, depending on the structures of your database.
Another common complicating factor, which I’ll cover in more detail in a later article, is the need to mask column values consistently when you’re dealing with linked servers or cross-database dependencies. It shouldn’t affect how you load the tables locally unless you’re retrieving that data from an external source and need to maintain that coupling for certain functionalities within your system. So, you may need to plan to mask more than one database, in whole or in part.
Masking a database: schemas and controllers
To get started setting up a data masking set for an entire database, the first thing you need to think about are schemas. In Data Masker, we use controllers to manage our schemas, and the tables they contain, so if we need to mask data in multiple schemas, we must set up multiple controllers. We create a controller and database connection for each schema.
Cloning controllers
Occasionally, you need more than one controller for a given schema, and you want them to run differently and manipulate different tables. In these cases, you have the options to clone a controller and then edit it to change the associated schema. This second method is more complex and is for more specialized requirements, so I will cover it in a separate article.
Create a controller and database connection for each schema
The easy way to add a series of controllers is to add a controller for each schema, one by one, through the database connection. Here I’m adding the last of my schemas, Sales, to my masking set:
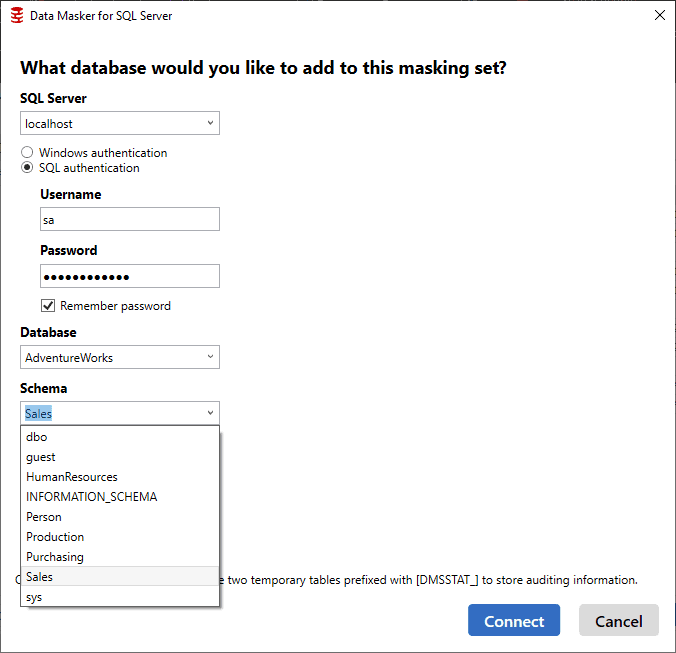
You must add the connection each time because, if needed, you could set up a masking set that crosses databases, masking data from one database in one controller and then another database from another controller, all within a single masking set. This would ensure that any cross-database dependency could be covered, if necessary.
Editing controller descriptions for clarity
After creating controllers for each of the schemas in the AdventureWorks database, my masking set looks like this:
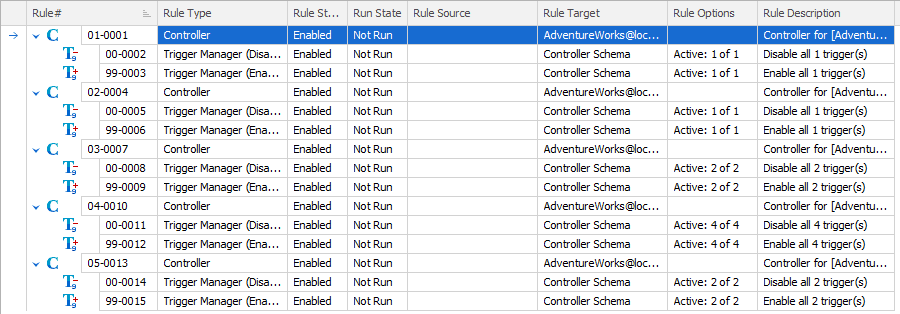
I would suggest that you edit these controllers, immediately, providing each one with a description that makes its purpose clear. In my case, each one is managing a schema in a single database. So, I’m going to edit each controller description to reflect that, in this case supplying a customized description of ‘Purchasing’, making it clear that the purpose of this controller within my masking set is to mask data in the Purchasing schema.
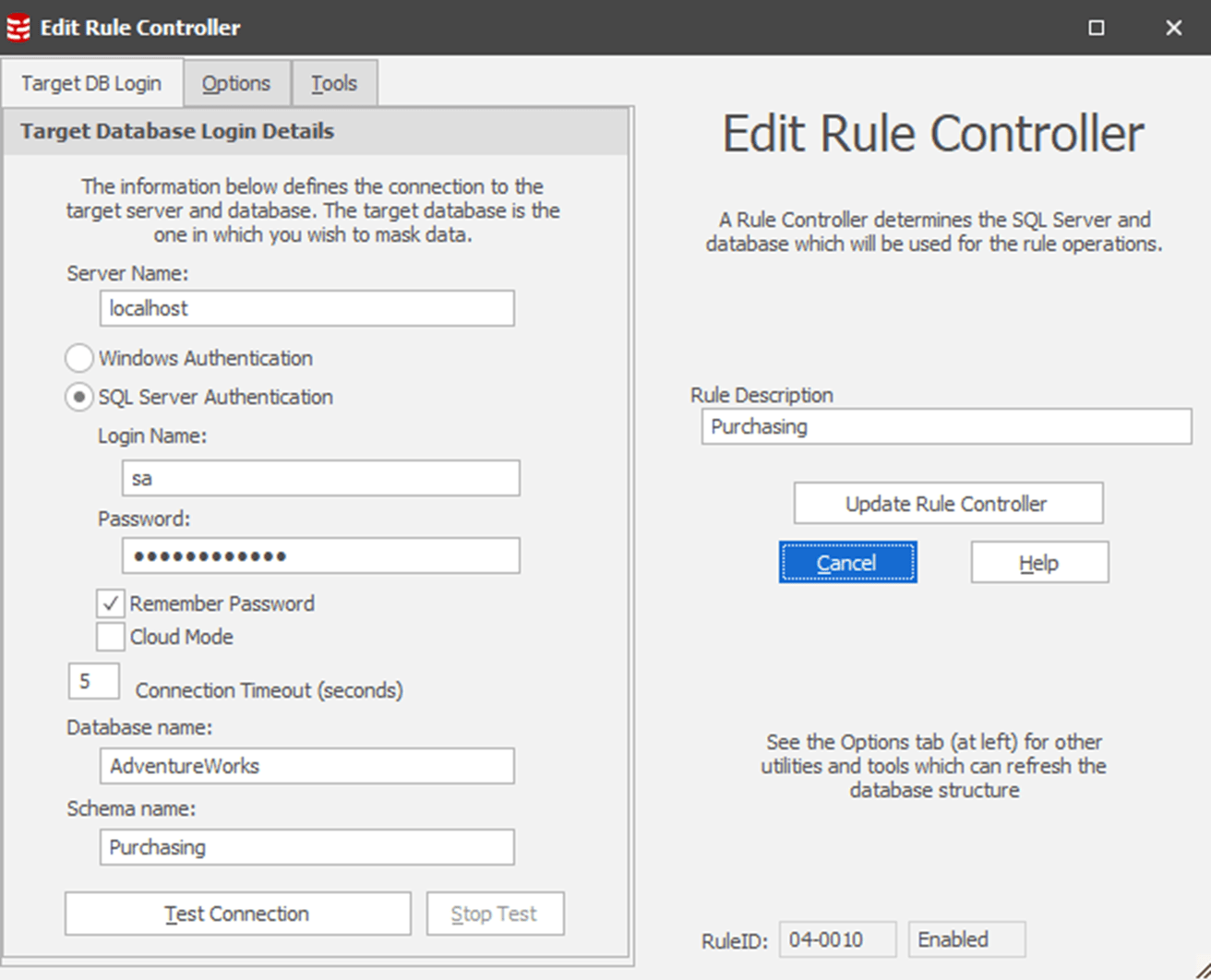
If I were masking more than one database within a masking set, I’d probably expand the description along the lines of ‘AdventureWorks.Purchasing’. You can also type directly into the edit the Rule Description column directly, within the masking set.
After completing this, you can see a much clearer picture of what each part of the masking set is going to do:
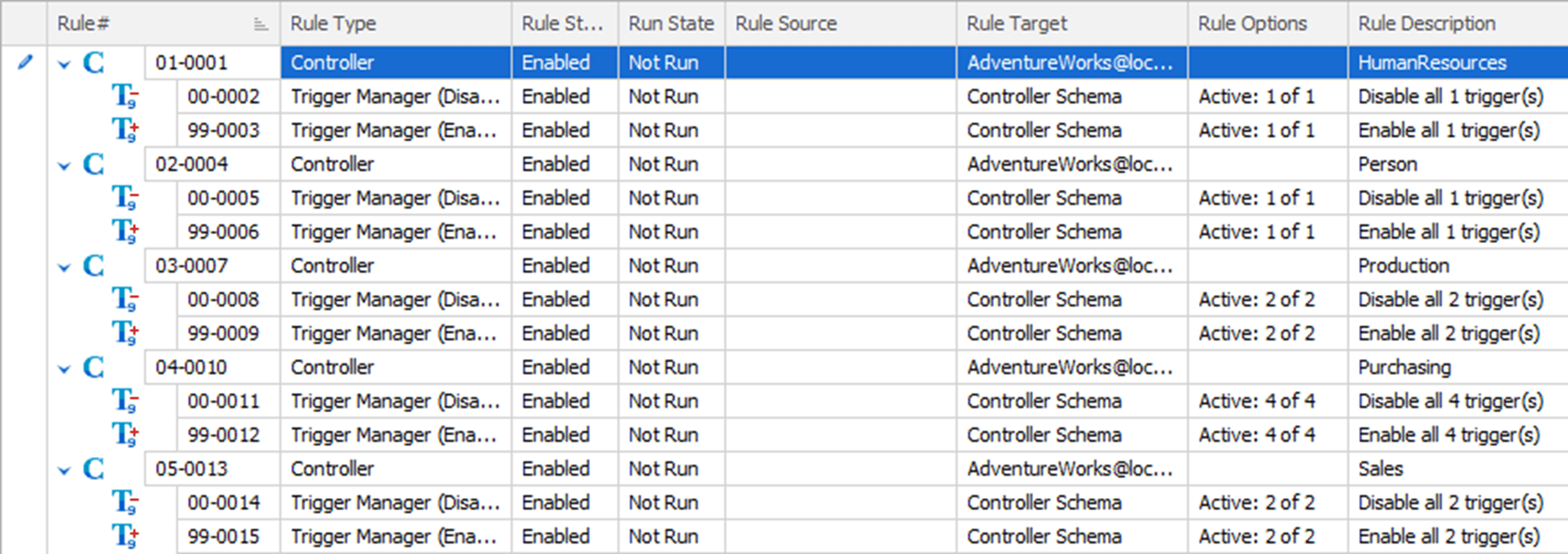
I could now simply start to build out my masking sets by walking through all the necessary columns, one by one, and applying rules to mask them. However, I want to take advantage of the checklist that our data classification tool is going to provide.
The Tables tab: a data classification checklist
A lot of our time, when working in SQL Data Masker, will be spent on the Rules tab which is where we define and manipulate the controllers and the rules within them. However, this time, we’re switching over to the Tables tab:
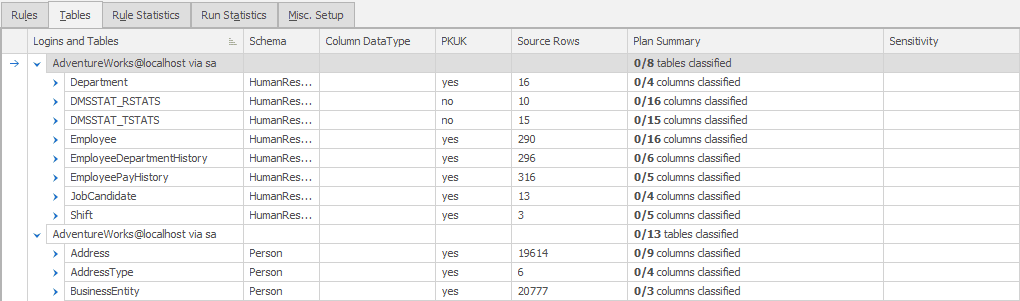
Whether or not you’re using data classification to track which columns need to be masked, this view on to the tables, as opposed to the rules, provides a way to track your progress (which tables and which columns have already been masked and which haven’t).
By default, this screen shows you the controller for each schema, and the list of tables within that schema, and you can expand each table to its columns, and you’ll see which of the columns have been masked by any rule or rules (and yes, you can apply more than one rule to a column). If nothing else, this is a simple masking checklist. However, we can expand the functionality and use the data classifications so that our masking process becomes a way of documenting compliance.
Importing classifications
At the bottom of the screen, you can see a series of buttons:

The first four are for controlling the display on the screen (Options, Schemas, Tables, Columns). You can also decide to remove tables from here. However, the “Export/Import Plan” button is the one we’re interested in now, as this lets us export the existing masking plan, or to import a plan on which to base the masking strategy. The plan can be imported either as a comma delimited file, or, directly from the existing SQL Server classifications, or from SQL Data Catalog:
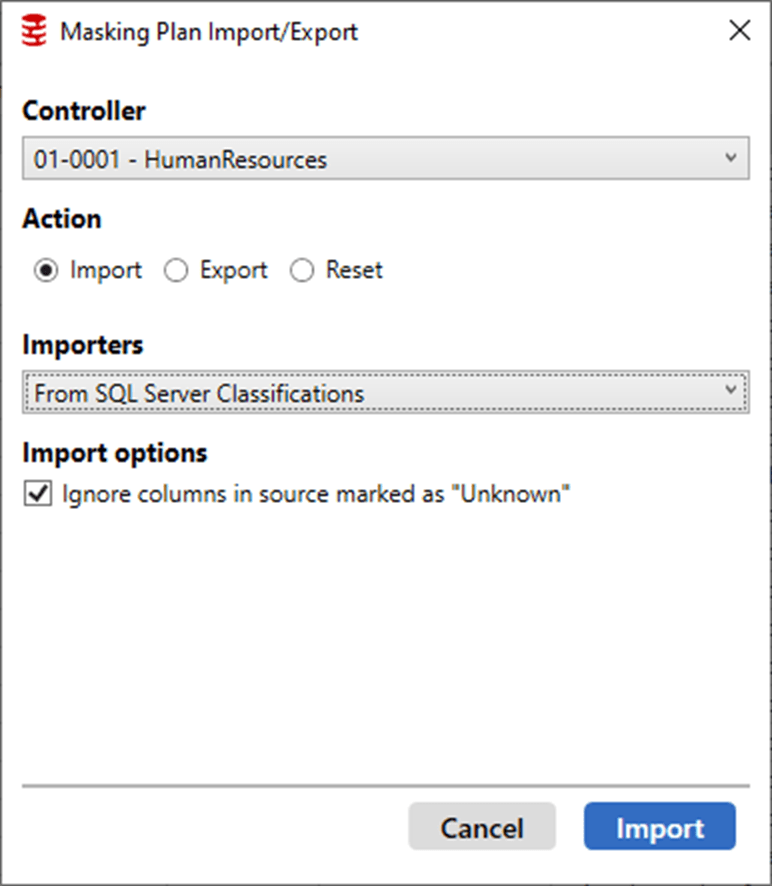
As you can see, you first select the controller for which you wish to import a plan, in my case the controller for the HumanResources schema. Clicking on the Import button will import the data classifications for that schema, and you’ll see this reflected in the Plan Summary and Sensitivity columns of the Tables tab:
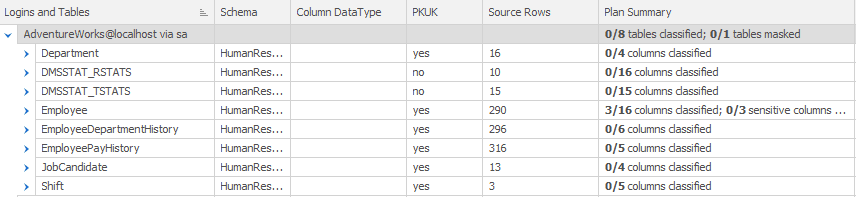
Only the Employee table was classified with sensitive data in SQL Server. However, you can see that now 3 out of 16 columns in the table have been classified. We can expand the list to see the detail:
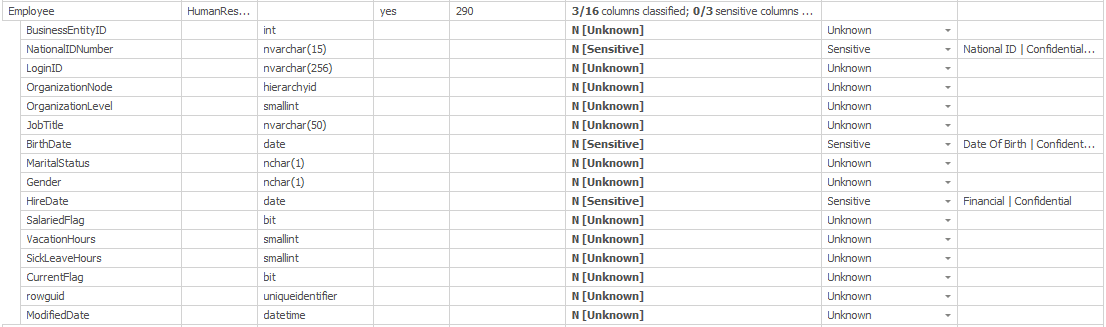
Now we know that the three columns that were classified are NationalIDNumber, BirthDate and HireDate. We also get the explanation for the classification in the final column.
This lets us use the existing classifications as a foundation for how we’re going to implement the masking strategy for each of our tables.
Adding classifications within Data Masker
If you don’t have classifications in a form that you can easily import, or your classification tool did not correctly infer the sensitivity of certain columns, then you can also assign classifications and sensitivities directly within the tool. Here, I’m setting the Sensitivity of the BusinessEntityID column:
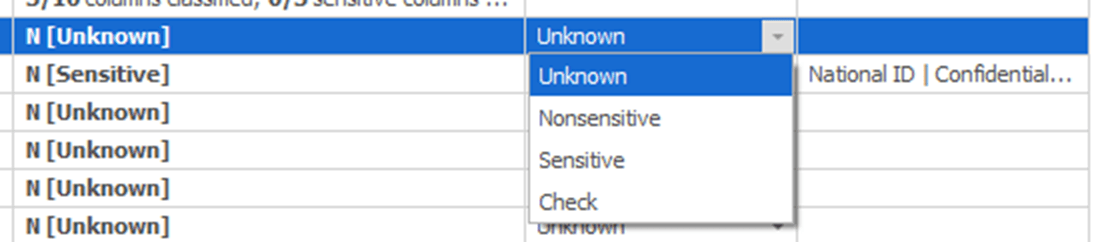
This is very much a business process. If you’re unsure if a column is classified as sensitive, you’ll need to verify this with the business, using the Check selection. Once you have completed the checklist with the business, you go through all the columns and mark them appropriately.
Just to give a sense of how it works, I went through and marked as Nonsensitive all the columns in the Employees table, other than the three columns classified as sensitive, per the SQL Server classifications. As a result, the Plan Summary column looks like this:
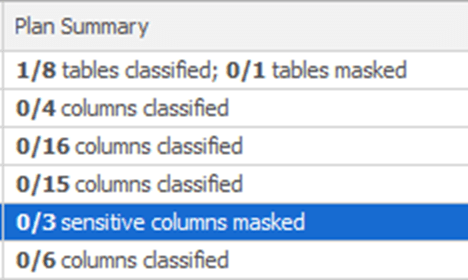
We can see that there are now no unclassified columns, and that 3 sensitive columns have not yet been masked. You would have to repeat this process for each schema, each table, and the columns on the tables. Once you have your checklist configured, you would start to create rules to mask the appropriate columns.
Creating masking rules for sensitive data
We’re not going to go into the details of creating specific rules for specific columns. You can read that kind of detail in the Data Masker documentation as well as in other articles in the Masking Data for Development and Testing series.
When you’re masking a whole database, there are going to be rules that have dependencies between tables. That means that you are going to have to worry about the order in which you do the masking, not simply of the tables themselves, but also the order in which you are masking the schemas. Data Masker doesn’t know the dependencies that you may have in your system other than through foreign keys. This is especially true when we start considering cross-schema dependencies that are further complicated by a lack of normalization or enforced normalization. In those cases, you will have to rearrange the order of operations yourself.
Masking a whole database is a lot of work; there is no real shortcut. However, by using a masking plan based on data classifications, as discussed earlier, you can at least eliminate all the columns that you already know aren’t sensitive and so don’t need masking. For each remaining sensitive column, you’ll need to decide the best way to mask it, and then repeat the process for all the sensitive columns in all the tables in your entire database across all the schemas. Further, you may have to also ensure that you’re still preserving referential integrity and consistency.
Let’s take the Employee table as an initial example. From our simple, initial classifications, it contains three columns that must be masked. If we do the work of masking that data, then check back with the Tables tab, we’ll see something like this:
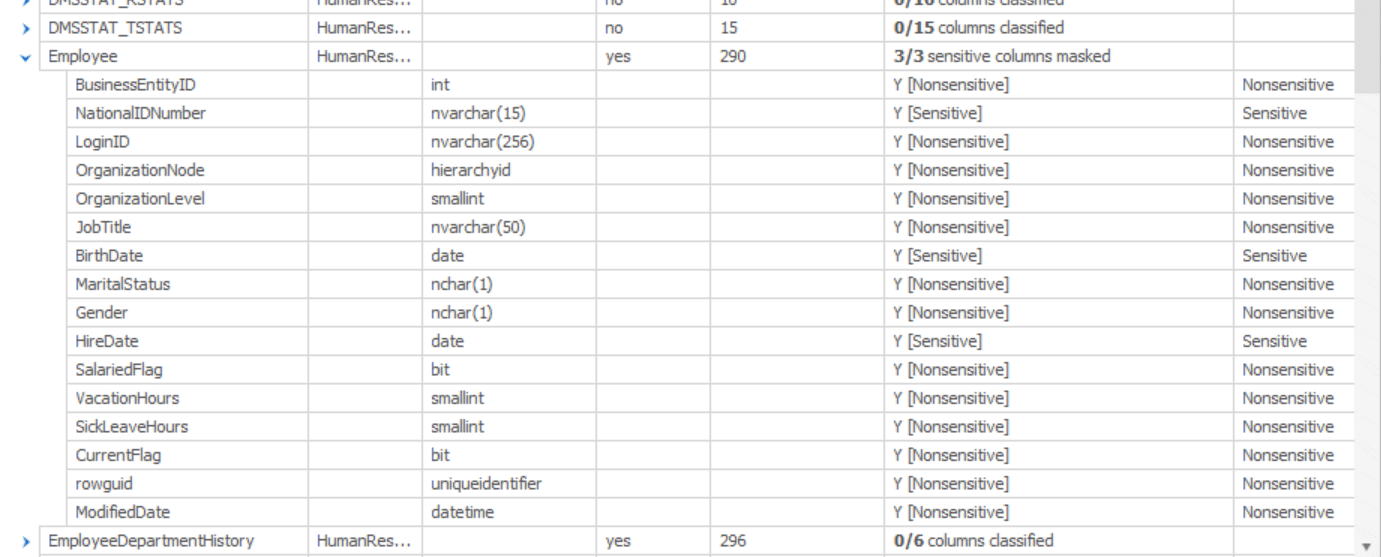
Since I’m building my masking based on a plan, which in turn is based on agreed data classifications, then I can be assured that every column in the Employee table is marked either Sensitive or Nonsensitive and that I’ve already masked all the Sensitive columns, since the tool reports “3/3 sensitive columns masked”
Now I must step through all the other tables, for all the schemas, doing the same thing. For a table where there are no sensitive columns, you can right click on the table in the Tables tab and mark all the columns at once by changing the table to Nonsensitive. As you work through the tables, you may find columns that were missed in the initial assessment. For example, the Address table has several sensitive data columns that were caught by the SSMS classification tool. However, the SpatialLocation column, which is going to be just as sensitive as the Address lines, was missed. You can then mark such columns manually, so that they become a part of the checklist.
Another way to use the Tables tab is to find a column you want to mask and then create a rule from right there. Right clicking on the column brings up a context menu where you can pick a rule like this:
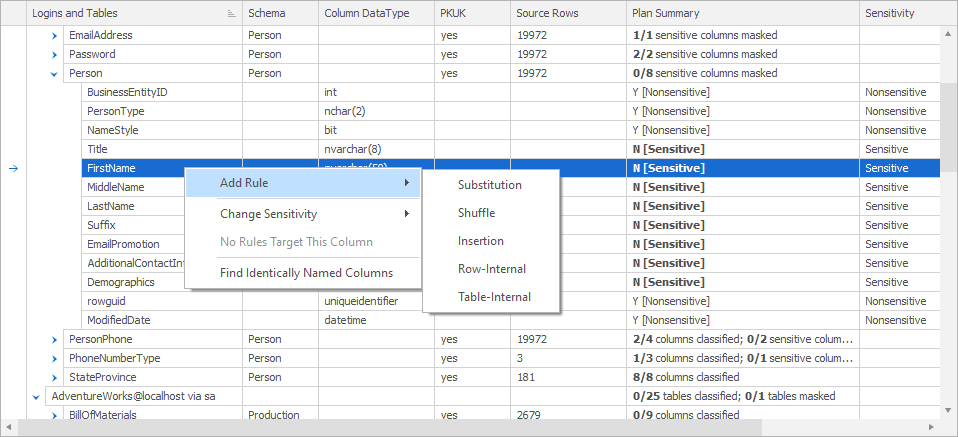
Selecting a rule here will open the appropriate rules window and allow you to start setting up what you need. Notice though, that this is the short list of most common rules. For example, if you want to add an XML Masker rule, you’ll need to switch back to the Rules tab.
Then you simply go back and forth between the Tables and the Rules tabs to arrive at this:
It’s a good practice to get in the habit of running small pieces of the masking set as you build it. This way you can identify errors as you go, rather than trying to find all the errors as you finally try to run the whole masking set. You’ll frequently find that you may have to rearrange the order of the controllers, or the order of the rules within each controller (covered in the next section).
I’ve rolled up my Controllers so you can see the report on which tables and columns have been masked:

Moving and nesting rules
It’s entirely possible to have dependencies between rules, meaning that you’ll need to run the rules in the right order. You may need to control which rule completes first. Data Masker can help you with these situations. By default, the rules will be started in the order you see them in on the Rules tab. If you have multiple workers, you can run more than one rule at the same time. For most rules this is probably not an issue. However, for some rules, there may be dependencies on the specific order of operations, meaning that running multiple rules simultaneously can result in data that is not masked in the way you anticipated.
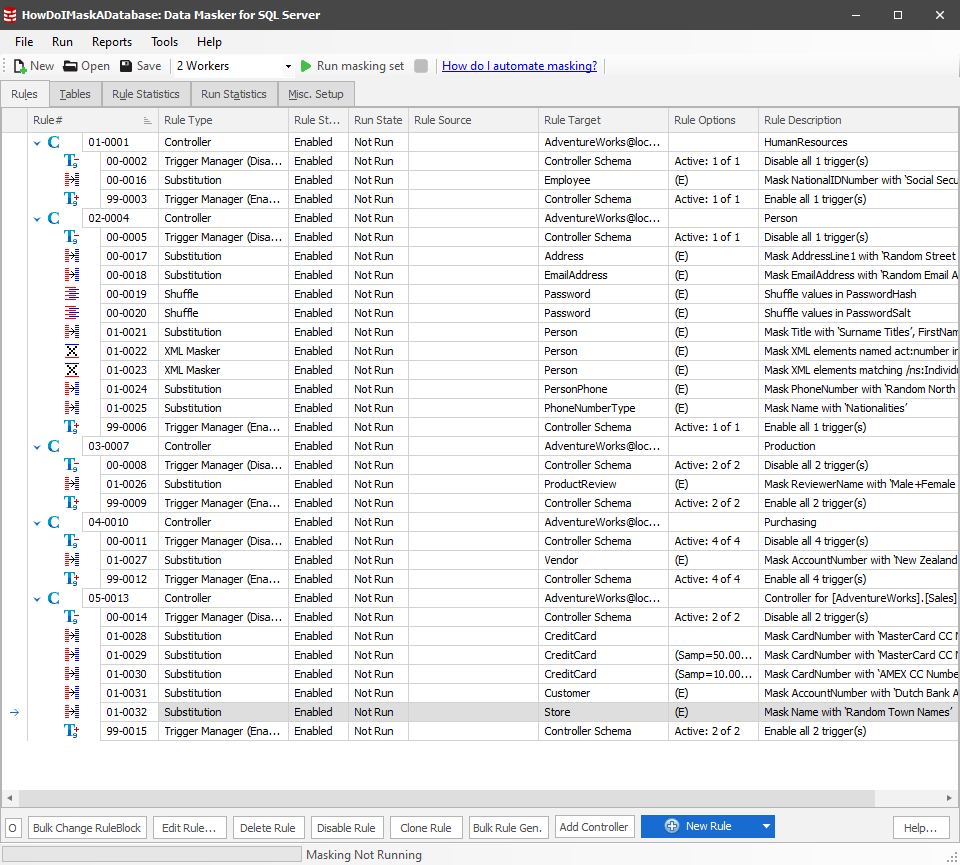
In my example, I have three rules for dealing with credit card data:

The first rule masks 100% of the data as MasterCard data. This ensures that all data is masked. Then, another rule masks 50% of the data as Visa. This is a random distribution across the data. Finally, the last rule masks 10% of the data as Amex. The goal here is to get more realistic data (see Spoofing Realistic Credit Card Data for your Test Systems using Data Masker for more details).
To achieve this, I need to be sure that this data runs in this specific order, and only in this order. To make this happen, I’m going to grab the second rule, and drag it onto the first rule. You’ll see a green arrow appear, letting you know that the rule you’re moving is being inserted into the other rule as a dependency. The rules window changes like this:

This means that the first rule, 01-0028, which masks the data as MasterCard will be run to completion before the next rule starts. I’m going to do the same thing to the third rule:

Now, I don’t have to worry about the masking occurring out of order.
Conclusion
While masking an entire database can be a daunting task, it becomes much more logical if you work to a plan. First, you define which tables and columns need to be masked, across your database. Then, you use Data Masker to work your way through the columns, one at a time, to arrive at a masked database. You can use the Tables tab to document what needs to be masked and to track progress. Masking an entire database will never be an easy task, but it can be done by simply taking one step at a time.
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality