





SQL Prompt Code Analysis: Table does not have clustered index (BP021)
With a few exceptions, every table should have a clustered index. However, they are not always essential for performance. The value of a clustered index depends on the way a table is used, the typical pattern of queries, and how it the table is updated. More important for a table is that it should have an appropriate primary key. If you cannot explain a good reason for avoiding a clustered index on a table, it is far safer to have one. Good reasons are hard to come by unless you know exactly how the table will be used.
Heaps and SQL Server
Heaps, which are tables without clustered indexes, are treated in SQL Server as the naughty sister of tables and they have, in the past, generally lived up to their reputation. In previous SQL Server versions it was, for example, impossible to rebuild the indexes. The query response times increased as inserts and deletes happened to the table, because of forwarding pointers.
When you create a heap, the individual records are not in any logical ordering. To find a particular record, therefore, SQL Server would need either a reference to the row (physical RID) or else a full table scan to find it. To get that RID, the query must use a non-clustered index. The non-clustered index stores the physical RID of every record in the heap.
With repeated updates, you can get performance loss due to fragmentation. If the heap requires defragmentation, this is a good indication that it should be converted to a table by adding a clustered index.
Clustered Indexes in SQL Server
There isn't such a thing as a clustered index in relational theory. However, any major RDBMS, such as SQL Server or Oracle, will have them. A clustered index has a special importance in SQL Server. A table without a clustered index is technically not a table but a 'heap'. An unindexed heap is only effective for logs from which we hardly ever need to read. A skillfully-indexed heap can perform as well as a table.
For a well-used OLTP database system that is seeing lots of changes, and many fast, simple queries, then clustered indexes become the obvious choice. Clustered indexes are used to organize the table, while non-clustering indexes are used to support queries. Clustered index keys should be Narrow, Unique, Static and Ever Increasing (NUSE). By this, we mean that individual rows of the columns selected should take as little storage space as possible because the clustered index is also used in non-clustered index lookups. Each row needs to be unique or as near to it as possible. The values in the columns shouldn't be expected to change. It helps a lot if the clustered index is ever-increasing, so that the rows are arranged in ascending sort-order of the clustered index. If new rows always have a higher value in the clustered index key then no insertions of rows into the sequence are required, only additions at the end. Inserts occur in logical order on storage, and page splits will be avoided.
Although the incrementing IDENTITY column is key is often chosen as the key, it's not always the best choice. For example, so much of trading data is based on the date and time, that the date column becomes a more natural choice, especially as the date is often used for filtering the data. However, the choice of the clustering index is very much dependent on the patterns of use and the occurrence of 'hotspots', where rapid inserts are required.
Don't confuse primary keys and clustered indexes
A primary key is a logical construct and a clustered index is a special way of physically storing data. A clustered index is usually chosen to embody a Primary key. By specifying a clustered index for a key, you determine the way that the key is then implemented. A primary key may well be most effectively implemented with a clustered index key, but not necessarily.
Clustered indexes work well for primary keys when you are generally selecting rows based upon the primary key where the indexed value is unique, such as when selecting a row based upon a value. It also works well for a range of values of the primary key, because the table rows will be adjacent to each other in storage. The rows that is likely to be queried together are stored together
A table can have only one clustered index, so you need to make your choice carefully. The candidate key that makes logical sense as a primary key does not necessarily have the characteristics that are required for a well-performing clustered index.
Comparing heaps and tables for static data
A clustered index works best with queries that are likely to select predominately single values, or queries that need to return the data from columns that aren't part of the primary key. They work well for queries that typically select either unsorted or sorted ranges, within a category, if the category column has the clustered index.
Sometimes it is better to avoid using a clustered index if the data is always accessed through nonclustered indexes. This is generally because the reference to the actual row in a heap (the RID or row identifier) is likely to be smaller than a clustered index key. Heaps are often chosen for log tables that are almost never read from, must be written to quickly, and are never updated.
Another obvious use of an indexed heap is with data in a table that has incremental changes very infrequently, such as a directory. Tables that have no 'natural' order and are frequently updated can sometimes also work better as heaps.
To illustrate the point, I created a four-million row table containing a business directory and store it in a heap and a table. If you want to reproduce the tests, I've provided the build script for the bigdirectory table, and a SQL Data Generator project XML file to fill it with 4 million rows (you can lower this if you prefer). It is actually .sqlgen file type but renamed to have a .xml extension. You'll need to edit the DataSource XML project file to provide the right connection and database details and then save it as a .sqlgen file.
|
1
2
3
4
5
6
7
8
9
10
|
<DataSource version="4" type="LiveDatabaseSource">
<ServerName>MyServerName</ServerName>
<DatabaseName>MyDatabase</DatabaseName>
<Username />
<SavePassword>False</SavePassword>
<Password />
<ScriptFolderLocation />
<MigrationsFolderLocation />
<IntegratedSecurity>True</IntegratedSecurity>
</DataSource>
|
Both tables are given a suitable covering index:
|
1
2
3
4
5
|
CREATE NONCLUSTERED INDEX CountyBusinessTypeCovering
ON dbo.BigDirectory (county, BusinessType)
INCLUDE
(Name, Address1, Address2, town, city, Postcode, Region,
Leads, Phone, Fax, Website );
|
We want to extract from this 4 million row table, BigDirectory, and its evil Heap twin HeapBigDirectory, all the columns of all the rows from the county of Essex whose line of business begins with 'R'.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
DECLARE @bucket INT
SELECT --count of filtered result from heap
@bucket = Count(*)
FROM Heapbigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --count of filtered result from table
@bucket = Count(*)
FROM bigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --heap, get all columns
*
INTO #sometempTable
FROM Heapbigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --table, get all columns
*
INTO #othertempTable
FROM bigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
DROP TABLE #sometempTable
DROP TABLE #othertempTable
|
We put this in the test harness, using the SQL Prompt chk snippet that I described in another article.
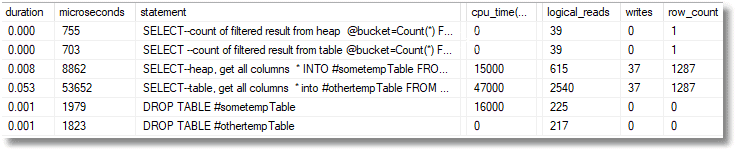
The heap outperforms the table when it manages to write the data to the temporary table in a seventh of the time, though the actual identification of the rows takes the same time. Of course, in this example, the query should, in theory, not need to go out to the table to fetch the data because the result can be obtained from the index.
So, let's delete the nonclustered index from the table and heap create a new one on each that no longer covers.
|
1
2
3
4
|
CREATE NONCLUSTERED INDEX CountyBusinessType ON dbo.BigDirectory
(county, BusinessType);
CREATE NONCLUSTERED INDEX CountyBusinessType ON dbo.HeapBigDirectory
(county, BusinessType);
|
We use queries that only support the filter and leaves the gathering of the data to be done via the RID or the clustered index
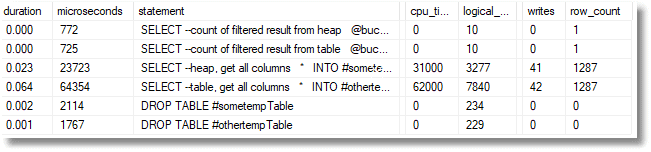
Now that the heap is having to fetch the data from the rows via a RID lookup, its advantage has been reduced but it is still around three times faster than the table.
Conclusion
The real code smell is not so much the lack of a clustered index, as the lack of any index at all on the columns that are referenced in queries. If you can have a nice clustered index with a Narrow, Unique, Static and Ever-Increasing key, then you can be reasonably confident that the table will cope with any query that uses the nonclustered index columns for filtering, especially if the index is covering.
For a heap to be superior in performance for any particular query, the non-clustered index must cover all the columns used in either the JOIN or the WHERE filter clause and the table must essentially be static.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
How to Test SQL Server Functions and Procedures using SQL Prompt
Phil Factor shows how to create a table of input values versus expected results, and then use it to unit test your SQL stored procedures and functions and verify that they always produce the correct results. He uses SQL Prompt to make this task much simpler.
Article
SQL Prompt Hidden Gem: Auto-fill the GROUP BY clause
Writing
GROUPBYclauses is a very common, but tedious, activity for a SQL programmer. SQL Prompt will fill it in for you, with all non-aggregated columns returned by the query.Article
Never Create Columns with ANSI_PADDING set to OFF
There is no good reason for having ANSI_PADDING set to OFF when you create tables in SQL Server. It was provided purely for legacy databases that had code that assumed the old CHAR behavior for dealing with padding, and its use has now been deprecated.

Live training session
New features added to SQL Prompt
Our development team have been busy adding new features and functionality to make SQL Prompt even more awesome. In this 30-minute training session Redgate Solutions Engineer, David Ong, will be joined by Terry Malone and Owen Standage from our SQL Prompt Dev Team to look at each of the new features and how they work, including a few exclusives for SQL Toolbelt Essentials’ subscription users. Command Palette: Find and execute SQL Prompt and SSMS functionality, and search for database objects, via a single keyboard shortcut. Redgate Platform: Share formatting styles and snippets with your team. Bulk actions: Apply bulk formatting,
Article
Exploring Auto-fix in SQL Code Analysis
Phil Factor presents a useful but slightly flawed 'table report' script as an adventure playground for exploring SQL Code analysis issues. He demonstrates use of the auto-fix feature, to arrive at a pristine script free from wavy green underlines.
Article
Why your Development team needs SQL Prompt
While everyone knows SQL Prompt for its code completion and IntelliSense features, a lot of its extra value comes from features that allow the development team to standardize coding practices and drive up code quality.
Loading comments...