





Finding code smells using SQL Prompt: TOP without ORDER BY in a SELECT statement (BP006)
In a SELECT statement, you should always use an ORDER BY clause with the TOP clause, to specify which rows are affected by the TOP filter. If you need to implement a paging solution in an application widget, to send chunks or "pages" of data to the client so a user can scroll through data, it is better and easier to use the OFFSET-FETCH subclause in the ORDER BY clause, instead of the TOP clause.
A recommendation to avoid use TOP in a SELECT statement, without an ORDER BY, is included as a "Best Practice" code analysis rule in SQL Prompt (BP006).
Limiting rows with TOP
TOP isn't standard SQL, but it is intuitive. If you want just a few sample rows from a table source, then it is tempting to use the TOP keyword without the ORDER BY clause. A single table is likely to conform to the order of the clustered index but even that isn't guaranteed due to parallelism.
If we go beyond the query for a single table and do a few joins, the 'natural' order is less obvious. Maybe you are in AdventureWorks and want just five customers, any five customers, and their addresses. It is perfectly legal to do this, but it is slightly dangerous if you subsequently forget why you are doing it.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
SELECT TOP 5 Person.Title, Person.FirstName, Person.MiddleName,
Person.LastName, Address.AddressLine1, Address.AddressLine2, Address.City,
Address.PostalCode, AddressType.Name
FROM Sales.Customer
INNER JOIN Person.Person
ON Customer.PersonID = Person.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress
ON Person.BusinessEntityID = BusinessEntityAddress.BusinessEntityID
INNER JOIN Person.Address
ON BusinessEntityAddress.AddressID = Address.AddressID
INNER JOIN Person.AddressType
ON BusinessEntityAddress.AddressTypeID = AddressType.AddressTypeID;
|
Listing 1
You get what you expect, just the first five customers that are returned by the query. The order I get is that of the clustered index of the Sales.Customer table's PK_Customer_CustomerID, starting with the customer with the lowest customer_id that is a person rather than a store. A different execution strategy could well change that. You are not guaranteed a deterministic result. This may be fine if you just want a sample during development, but in production systems what you really want are the top five customers and addresses according to their rank order, as determined by some attribute such as how much they spend. You really need that ORDER BY.
In short, SQL tables have no guaranteed consistency in its intrinsic order. You may have set a PRIMARY KEY that gives your table values some fundamental ordering, but this isn't guaranteed to happen consistently. SQL Server reserves the right to introduce any optimisation it wants, in creating an execution plan that will return the results, even if it means delivering those results in a different order. In short, you can't guarantee that the results will be returned in the order you expect, unless you make it explicit with an ORDER BY statement.
So, we return to the perfectly reasonable requirement that the developer has of just being able to eyeball a representative sample of rows from the query. How should this be done?
SET ROWCOUNT and TABLESAMPLE: do they help?
There was a time when we had to use the SET ROWCOUNT statement to put a limit on the number of rows returned. One drawback to that was that the query optimiser couldn't create an effective plan in the light of the number of rows requested, because the ROWCOUNT is a session or procedure/trigger-wide setting that wasn't visible to the Query Optimiser within the query.
Also, it was possible to forget that you'd set the ROWCOUNT and neglected to 'unset' it. Another disadvantage was that you couldn't pass the value a variable. TOP is better, because it works at the statement level, and you can pass either a row value, or a percentage, as a variable or expression.
You might think that you can reliably get a limited number of rows from a table with the TABLESAMPLE clause. The only problem with it is that it doesn't work as advertised, and even if it did work as advertised it only works on tables, rather than the whole rich variety of table sources.
|
1
|
SELECT * FROM Sales.Customer TABLESAMPLE SYSTEM (5);
|
Listing 2
This is supposed to limit the number of rows returned from a table in the FROM clause to a sample number or PERCENT of rows. A quick test will show you why nobody uses it.
|
1
2
3
4
5
6
7
|
DROP TABLE IF EXISTS #Result;
CREATE TABLE #Result (TheOrder INT IDENTITY, TheRowsReturned INT);
GO
INSERT INTO #Result (TheRowsReturned)
SELECT Count(*) FROM Sales.Customer TABLESAMPLE(200 ROWS);
GO 30
SELECT #Result.TheOrder, #Result.TheRowsReturned FROM #Result;
|

Listing 3
Getting meaningful table samples with TOP…ORDER BY
So far, because TABLESAMPLE is broken, we are stuck with the slight awkwardness of this for getting a sample from a table.
|
1
|
SELECT TOP 5 * FROM Sales.Customer
|
Listing 4
Why is this awkward? Listing 4 will give you back five rows, but you cannot entirely rely on which rows are returned, though it is likely to be in the order of the PRIMARY KEY, as we are just accessing a single table. However, sales.customer is a bit of a 'trick' table in that it uses polymorphic association, and the first 700 of the 19820 rows represent stores, not people. So, Listing 4 is likely to give a very unrepresentative sample of this table because You could easily get the incorrect impression of the data in the table, thinking that customers are stores when the majority are people!
What most developers will want is to see a few rows of the table they are investigating, taken at random, but if you want the sample in random order, then you have to make that explicit.
|
1
|
SELECT TOP 5 * FROM Sales.Customer ORDER BY NewId()
|
Listing 5
This will return you five rows in a random order, but it takes more resources to return the result. If you aren't dealing with a 'trick' table and just don't care about order, and need to indicate that fact in the code, then SQL Server will accept any system function, such as @@version or host_name(), even ORDER BY (SELECT NULL). This trick is often seen where SQL Server refuses to accept code in a window function that requires an ORDER BY. It means 'I know, I know but I'm doing it deliberately'.
|
1
|
SELECT TOP 10 * FROM Sales.Customer ORDER BY @@identity
|
Listing 6
If you are happy with the records you get by using TOP without the ORDER BY, then it is best to be entirely explicit, and point out that you really do want it by the PRIMARY KEY field
|
1
2
3
|
SELECT TOP 5 *
FROM Sales.Customer
ORDER BY Customer.CustomerID;
|
Listing 7
Using TOP with ORDER BY for reporting queries
TOP comes into its own for reporting purposes. Managers love lists of top customers and top salesmen. At this point, the ORDER BY part becomes crucial.
|
1
2
3
4
5
6
7
8
|
SELECT TOP 10 Person.BusinessEntityID, Sum(SalesOrderHeader.TotalDue) AS expenditure
FROM Sales.SalesPerson
INNER JOIN Sales.SalesOrderHeader
ON SalesPerson.BusinessEntityID = SalesOrderHeader.SalesPersonID
INNER JOIN Person.Person
ON SalesPerson.BusinessEntityID = Person.BusinessEntityID
GROUP BY Person.BusinessEntityID
ORDER BY Sum(SalesOrderHeader.TotalDue) DESC;
|
Listing 8
This gives you the top ten performing salespeople.
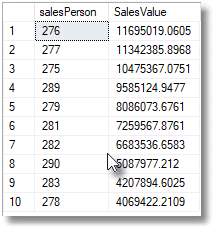
We might decide that this report doesn't really tell us who the salesperson was, so we'd tweak it.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
SELECT SalesPerformance.SalesValue,
Coalesce(Person.Title + ' ', '') + Person.FirstName
+ Coalesce(' ' + Person.MiddleName, '') + ' ' + Person.LastName
+ Coalesce(' ' + Person.Suffix, '') AS SalesPerson
FROM
(
SELECT TOP 10 SalesPerson.BusinessEntityID AS salesPerson,
Sum(SalesOrderHeader.TotalDue) AS SalesValue
FROM Sales.SalesPerson
INNER JOIN Sales.SalesOrderHeader
ON SalesPerson.BusinessEntityID = SalesOrderHeader.SalesPersonID
INNER JOIN Person.Person
ON SalesPerson.BusinessEntityID = Person.BusinessEntityID
GROUP BY SalesPerson.BusinessEntityID
ORDER BY Sum(SalesOrderHeader.TotalDue) DESC
) AS SalesPerformance(SalesPerson, SalesValue)
INNER JOIN Person.Person
ON SalesPerformance.SalesPerson = Person.BusinessEntityID
ORDER BY SalesPerformance.SalesValue DESC
|
Listing 9
Why would we need to do that second ORDER BY? The original SQL was an aggregate query and we needed the top 10 aggregate sales totals, so we had to impose an order on it. This was passed, with no fixed order, to the outer query that added the person's name. To be certain of the order of this outer query, it will need an explicit ORDER BY clause too. This is sometimes referred to as a 'presentation ORDER BY', or 'presentation ordering'.
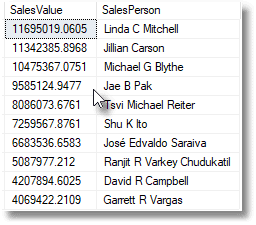
Using FETCH-OFFSET instead of TOP
The better way of doing this is, of course, to use the ORDER BY with the optional OFFSET-FETCH clause, available in SQL Server 2012 onwards, instead of TOP. It is much more versatile and is standard ANSII SQL too. Here are the twenty longest-serving employees of AdventureWorks.
|
1
2
3
4
5
6
7
8
9
|
SELECT Employee.JobTitle, Employee.HireDate,
Coalesce(Person.Title + ' ', '') + Person.FirstName
+ Coalesce(' ' + Person.MiddleName, '') + ' ' + Person.LastName
+ Coalesce(' ' + Person.Suffix, '') AS Name
FROM HumanResources.Employee
INNER JOIN Person.Person
ON Person.BusinessEntityID = Employee.BusinessEntityID
ORDER BY Employee.HireDate ASC
OFFSET 0 ROWS FETCH FIRST 20 ROWS ONLY;
|
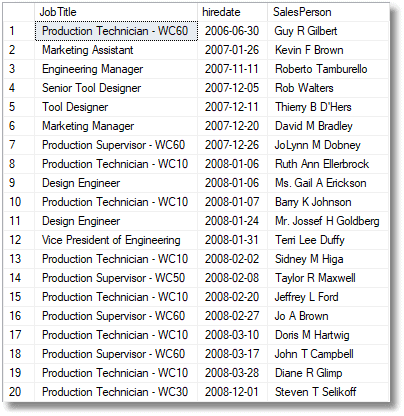
Listing 10
Now, with ORDER BY…OFFSET…ROWS FETCH FIRST…ROWS ONLY, you can provide a means of scrolling or paging through this hall of fame.
Using TOP with INSERT, UPDATE, MERGE, or DELETE
It seems odd that you are discouraged from using TOP without and ORDER BY, when in certain circumstances you are actively prevented from doing so. As well as the SELECT statement, the DELETE, INSERT, MERGE and UPDATE statements all have a TOP clause. In contrast to SELECT, you can't have an associated ORDER BY clause. Let's take this example.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
DROP TABLE IF EXISTS #tempCustomer; --in case it exists
SELECT Customer.CustomerID, Customer.PersonID, Customer.StoreID,
Customer.TerritoryID, Customer.AccountNumber, Customer.rowguid,
Customer.ModifiedDate
INTO #tempCustomer
FROM Sales.Customer --just for the test
UPDATE TOP (10) #tempCustomer
SET #tempCustomer.AccountNumber =
Replace(#tempCustomer.AccountNumber, 'AW', 'PF')
OUTPUT Deleted.CustomerID, Deleted.AccountNumber AS before,
Inserted.AccountNumber AS after
|
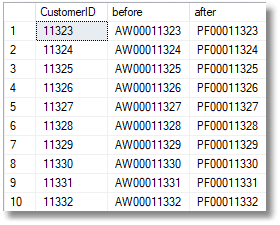
Listing 11
Now try putting in an ORDER BY clause! It won't allow it. As the documentation says:
"The rows referenced in the TOP expression used with INSERT, UPDATE, MERGE or DELETE are not arranged in any order".
No, you must do something like this.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
UPDATE #tempCustomer
SET #tempCustomer.AccountNumber = --
Replace(#tempCustomer.AccountNumber, 'AW', 'PF')
OUTPUT Deleted.CustomerID, Deleted.AccountNumber AS before,
Inserted.AccountNumber AS AFTER
FROM
(
SELECT TOP 10 CustomerID
FROM #tempCustomer
ORDER BY #tempCustomer.CustomerID DESC
) AS ordered
WHERE #tempCustomer.CustomerID = ordered.CustomerID
GO
|
Listing 12
Likewise, an INSERT statement. We can't use TOP to insert rows in a meaningful chronological order. As the book says:
"When TOP is used with INSERT the referenced rows are not arranged in any order and the ORDER BY clause cannot be directly specified in this statement."
If you need to do this, you must use TOP together with an ORDER BY clause that is specified in a sub-select statement.
DELETE has a TOP clause, but we can't use it either. What if you wanted to clean out old purchase order details? You'd want to be certain to clean out the oldest ones first. We can't put an ORDER BY in the delete statement, but then we don't have to.
Let's set up the test.
|
1
2
3
4
5
6
|
DROP TABLE IF EXISTS #tempPurchaseOrderDetail; --in case it exists
SELECT POD.PurchaseOrderID, POD.PurchaseOrderDetailID, POD.DueDate,
POD.OrderQty, POD.ProductID, POD.UnitPrice, POD.LineTotal, POD.ReceivedQty,
POD.RejectedQty, POD.StockedQty, POD.ModifiedDate
INTO #tempPurchaseOrderDetail
FROM Purchasing.PurchaseOrderDetail AS POD
|
Listing 13
We now delete the ten oldest purchase order details.
|
1
2
3
4
5
6
7
8
9
|
DELETE FROM #tempPurchaseOrderDetail
OUTPUT Deleted.DueDate, Deleted.LineTotal, Deleted.PurchaseOrderID
WHERE PurchaseOrderDetailID IN
(
SELECT TOP 10 PurchaseOrderDetailID
FROM #tempPurchaseOrderDetail
ORDER BY DueDate ASC
);
GO
|
Listing 14
So, what is the point of having that TOP filter if it can't be used to DELETE, INSERT, MERGE or UPDATE? Well, in fact, it can be used, in circumstances where a particular set of records don't need to be deleted in a specific order, as long as they eventually get deleted.
The use of the TOP filter without the ORDER BY is a life-saver if you need, for example, to delete lots of rows, regularly, from an operational production system. Deletes are logged, and can also result in escalating locks. I once had to design a system that regularly cleared out a million rows from a SQL Server database. The optimum method involved taking a lot of successive bites when eating the elephant rather than attempting it in a mouthful.
We can illustrate this very easily, though you wouldn't see the advantage until you have a working system, especially one that was needing to access the table while you were deleting, updating, inserting or merging. Again, we will illustrate the point with a temporary table so as not to interfere with the good working of AdventureWorks.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
DROP TABLE IF EXISTS #tempPurchaseOrderDetail; --in case it exists
SELECT POD.PurchaseOrderID, POD.PurchaseOrderDetailID, POD.DueDate,
POD.OrderQty, POD.ProductID, POD.UnitPrice, POD.LineTotal, POD.ReceivedQty,
POD.RejectedQty, POD.StockedQty, POD.ModifiedDate
INTO #tempPurchaseOrderDetail
FROM Purchasing.PurchaseOrderDetail AS POD
--we delete rows successively
DECLARE @rowcount INT = 1
WHILE @rowcount > 0
BEGIN
DELETE TOP (200) FROM #tempPurchaseOrderDetail
WHERE #tempPurchaseOrderDetail.DueDate < DateAdd(YEAR, -2, GetDate())
SELECT @rowcount = @@RowCount
END
|
Listing 15
I've found, in the past, that large-scale operations like this often benefit from being done in chunks, and the size of the chunk is a matter of fine-tuning with the operational system to get it right. For this sort of work, the TOP clause without the ORDER BY in a DELETE, INSERT or UPDATE can be very valuable for doing large-scale changes, a short step at a time, in a hard-working transactional system
Summary
SQL Server's TOP clause in a SELECT statement is very useful and intuitive, but it allows you to leave out the associated ORDER BY clause that clarifies what you had in mind: TOP by what aspect? After all, your TOP ten songs aren't the ten loudest, or the ten sung in the highest voice. They are the ten most popular in terms of the records sold. You may, fortuitously get the right result in development work, but in production, the workload, the server and the data size could result in the queries being optimised in very different ways, resulting in a different result.
For a more versatile way of dealing with such thing, I'd suggest using the ORDER BY … OFFSET…FETCH syntax introduced in SQL Server 2012 because it is more versatile and conformant. It isn't too much harder to remember than the TOP filter either.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Enhancing your database development using coding standards
Updated June 2020 Development and IT departments face increasing demands to deliver changes faster, often with increasing complexity and less tolerance for downtime, and without a corresponding growth in team size to handle the extra work. Standardizing database development practices by establishing coding standards can help achieve this by removing blockers to understanding code, easing the implementation of new code or processes, and improving code quality, so less time is spent on maintenance or fixing mistakes in the future. Improving the readability of code Setting standards for code writing, formatting, structure, and style means anyone, even those not immediately familiar
Article
A day in the life of a developer with SQL Prompt
Write, refine, format and test a reporting query before lunch then refactor a database, and retest the new design, afterwards. All in a day's work for a developer armed with SQL Prompt.

Article
SQL Prompt Product Updates – March 2026
SQL Prompt’s February releases focused on compatibility and stability, with a critical fix for SSMS 22.3 users and several features graduating from experimental to fully supported. SSMS 22.3 Compatibility Fix If you recently upgraded to SSMS 22.3 and experienced crashes with SQL Prompt installed, we’ve resolved this in v11.3.6. The issue caused SSMS to crash consistently on startup when SQL Prompt was present. If you were affected, updating to the latest version should resolve the problem — see our documentation for details. This compatibility issue also extended to our other SSMS tools so you will also need to upgrade those
Article
Bulk Formatting of the SQL Server SQL Files
How to apply SQL formatting styles as part of an automated process, using the SQL Prompt command line formatter, with examples of bulk applying styles from the command prompt, PowerShell or a DOS batch.
Article
How to Compare Two SQL Prompt Styles
A PowerShell function that will compare two SQL formatting styles, saved in JSON, and produce a report showing the differences between the options they use to lay out your SQL code.

Article
Tracking use of Deprecated SQL Server Features
Phil Factor explains how to use Dynamic Management Views and Extended Events to track use of deprecated SQL Server syntax on working SQL Server databases, as well as SQL Prompt and SQL Change Automation to detect its use during database development.
Loading comments...