







Data Categorization for AdventureWorks using SQL Data Catalog
Josh Smith shows how to use SQL Data Catalog to perform a 'first cut' data classification for one your SQL Server databases, identifying all columns that are likely to hold personal or otherwise sensitive data.
SQL Data Catalog will identify those columns and tables in your SQL Server databases that seem to have sensitive data of some sort, and categorize them. Having helped to identify the nature of the data, this provides a basis on which an organization can build, by adding the business context and developing a complete taxonomy for data classification. It is also the starting point for understanding data lineage; where the data comes from and how it is used (in views and table-valued functions and so on).
I’ll show how to use the tool’s UI to identify the columns that are candidates for holding sensitive data. I’ll also demonstrate how to use PowerShell to categorize those columns that clearly don’t contain any sensitive or personal data, quickly finding and eliminating a lot of the ‘low-hanging fruit’ in a cataloging process.
Why is a Data Catalog necessary?
A data catalog is necessary in order to be able to understand the data within an organization, where it is held and how the organization uses it. You are obliged to create a data catalog in order to be able to prove legally that your organization is sufficiently competent to undertake the responsible curation of personal data. It is also part of the process of ensuring that you have the right security, in the right places, to be able to assure the leaders of the organization that the data is safe from breaches.
A Data Catalog is a collection of data classification metadata that describes the data that your organization uses. It will apply classification and labeling to any personal or sensitive data in each data source, revealing where, throughout the organization or elsewhere, this sort of data is stored and used. The types of data, the business owners, the purpose and the sensitivity of the data will come naturally from any competent data cataloging.
Once the catalog can map the data in terms that the organization can understand, it can then be passed to the security and data governance teams to contribute to a document that conforms to the legislative framework in force. In Europe and the UK, this would be a ‘Data Protection Impact Assessment‘ (DPIA).
Classifying data with SQL Data Catalog
Once you’ve installed SQL Data Catalog and pointed it at a SQL Server instance, it inspects all the databases on that instance and will present a donut chart for each one, showing the proportion of columns that fall into each sensitivity classification. Of course, initially, you’ll see that all the data is marked in red as “Not Classified”.
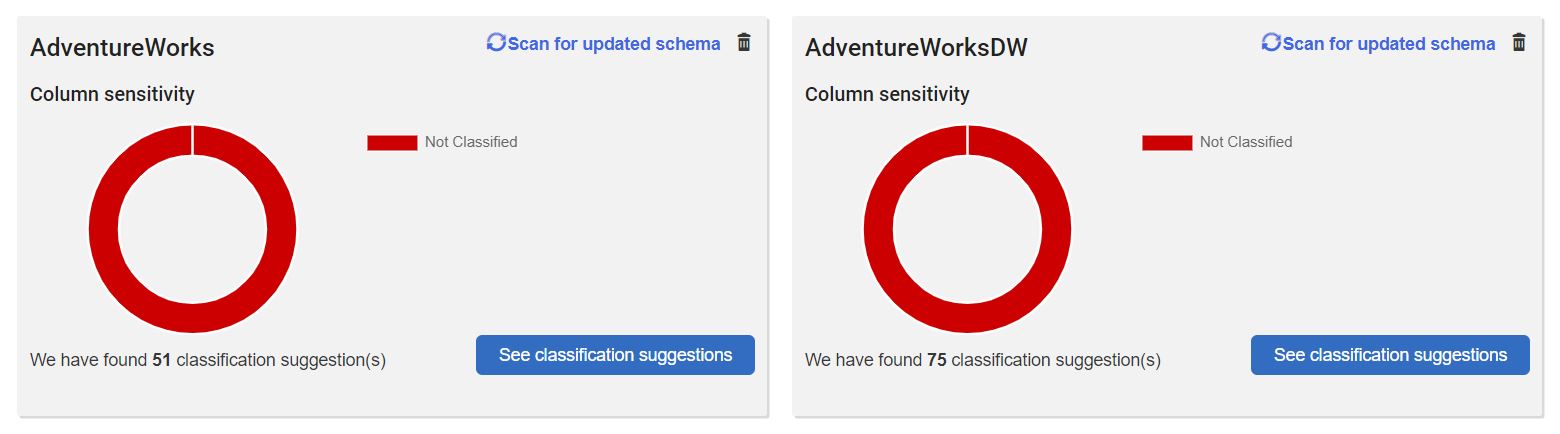 Figure 1 : All that red is unsettling to any good data governance team.
Figure 1 : All that red is unsettling to any good data governance team.
If you click on the AdventureWorks database, you’ll see that SQL Data Catalog has identified 486 columns that require classification. Even for a small database like this, it can seem an overwhelming task. More often, you’ll likely be presented with thousands of unclassified columns. So, where do you start?
SQL Data Catalog tries to give you a start, by automatically examining each database and trying to identify those columns that probably contain personal or sensitive data. For each of those columns, it suggests an Information Type tag and a Sensitivity label.
The pre-defined Information Type tags are the same as those used natively in SQL Server 2016 and later. The sensitivity labels include “Confidential – GDPR” for columns containing personally identifying data, as defined by the GDPR regulations, and “Confidential” for data that is likely confidential but not personally identifying.
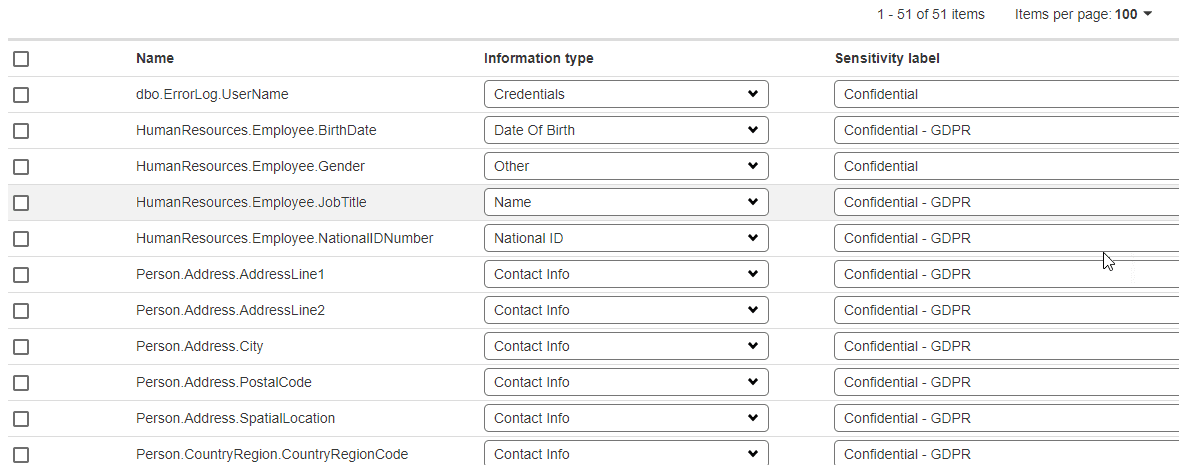
Figure 2: SQL Catalog automatically tries to detect columns that hold personal data, and suggest categorizations
Although SQL Data Catalog provides this default categorization or taxonomy, Redgate encourages you to add and edit your own categories for classification, and tags which can be used within them.
Using the Taxonomy page, you can define your own tag categories in the Classification tags section. Each category should contain several tags, which you can define according to your needs. Categories can be defined as ‘multi-valued’, meaning that more than one tag can be applied at the same time to the same item in the Data Catalog. SQL Data Catalog also allows you to add Free-text attributes, which do not have tags but instead allow free text to be applied to an item in the Data Catalog.
By creating a custom taxonomy that is appropriate to your organization (see ‘Further advice on defining a taxonomy‘), you are likely to be able to make much better use of the tool. This is essential in order to provide a classification that is meaningful to business owners, and to prevent you being overwhelmed with classification suggestions.
A first cut classification using SQL Data Catalog
Of course, personal data, as defined by GDPR, is precisely the data that an organization is most keen to identify and protect. Every organization must document the risks to this data and report to the board, and to do that they have to know where at least the personal data is held. If a breach occurs and they can’t produce this signed-off document for the DPIA (in Europe), they are liable to a large fine. You need to be sure that you catch and classify correctly every piece of this data in every data source.
Therefore, I like to tackle the problem from the other side. Many columns in a database will not store any personal or sensitive data. These columns will often support application functionality and the data in them will have no meaning outside the context of the database. Therefore, a useful first task is to identify and “bulk classify” all those columns that definitively do not contain sensitive or personal data.
We can then turn our attention to the trickier task of classifying a smaller volume of remaining data that might be of concern to our Data Governance or Information Security teams. In this case, I’m aiming simply at a first-cut classification, enough to pass onto one of these teams for further assessment and then a deeper classification, using a business-specific taxonomy. Once finalized, it will need to be implemented using SQL Data Catalog’s open taxonomy and then applied to the database by subject matter experts.
With some simple initial investigation and scripting, you can often automate much of this initial categorization, as I’ll demonstrate.
The first-cut taxonomy
While implementing a full, custom taxonomy is out of scope, I do need to make some minor changes to the various categories and tags that SQL Data Catalog provides out of the box.
Within the Taxonomy tab, you’ll see that it provides a category of tags called “Classification Scope“. A column can be In-Scope (it contains data that needs classification) or Out-of-Scope (it contains internal system data or is unused).
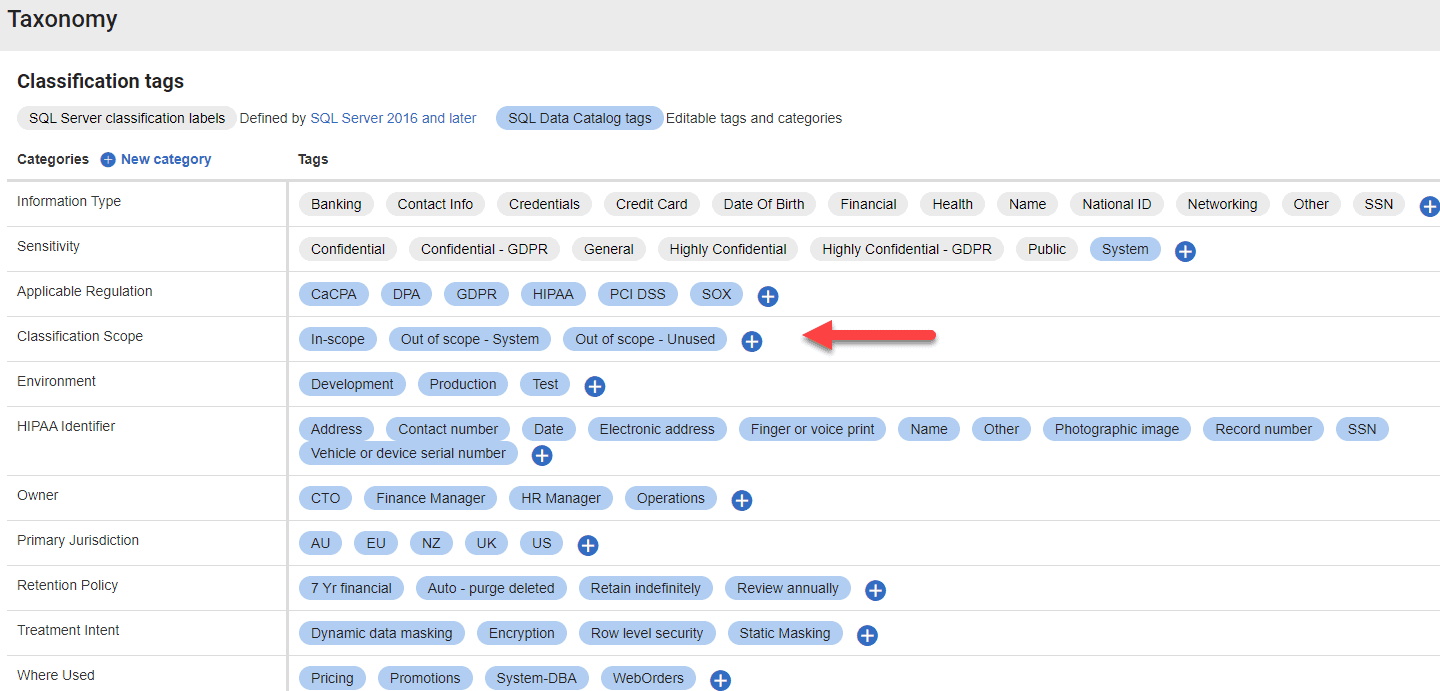
Figure 3: SQL Data Catalog taxonomy
In my case, the data governance team has decided I can “descope” any empty or system tables in the initial phase. I’ve modified the Classification Scope metadata tags to reflect this, Descoped: Empty table; Descoped: System data; and In-Scope, and also added a new sensitivity type: System
In this broad, initial categorization I’ll use tags as follows:
Classification Scope
- In-Scope – user data, or system-generated data that needs further assessment
- Descoped: System data – system data that needs no further classification
- Descoped: Empty table – no data!
Sensitivity
- System – columns containing internal data
- General – empty columns
- Confidential – business-sensitive or personal data
- Highly Confidential – highly sensitive category of personal data (e.g. medical data, national IDs, and so on.)
Information Type
- Other – for any non-personal data columns. Any columns that I bulk categorize with PowerShell scripting will get this tag. Again, this can be refined later.
- As appropriate –any personal data columns will get the appropriate pre-defined information type.
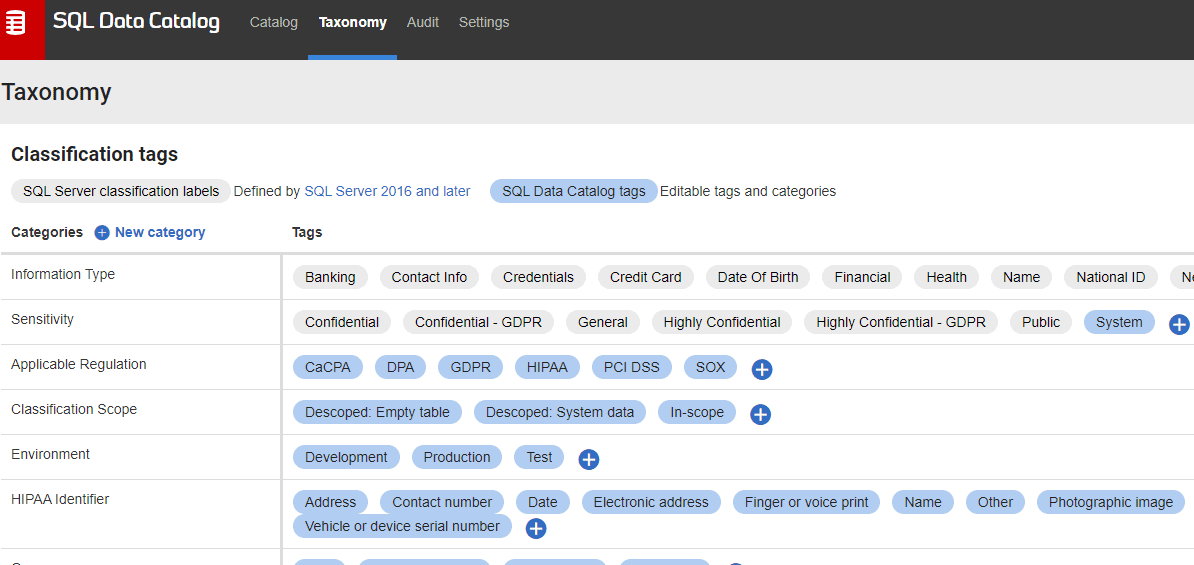
Figure 4: Ensuring we have defined the metadata we need.
Exploring non-personal and non-sensitive data in the UI
Now I’m ready to start poking around to find any tables and columns that are unlikely to have information regarding end users, so that I can auto-catalogue them, applying one of my Descoped classification tags.
In our databases, Primary Keys, Foreign Keys, and any columns storing datatypes like bits, all have a very high probability of containing only system data, especially when coupled with column names that contain terms like ID, key, flag or status. These are candidates to be assigned the Descoped: System data tag. Of course, if your database uses any natural key, such as SSN or NI numbers, rather than surrogate keys, then it’s likely they will contain personal or sensitive data.
Before I start auto-cataloging, I verify my hypothesis by checking the box for “With no tags” and then applying further filters, either checking the PKs or FKs check boxes or drilling down to specific data types in the dropdown.
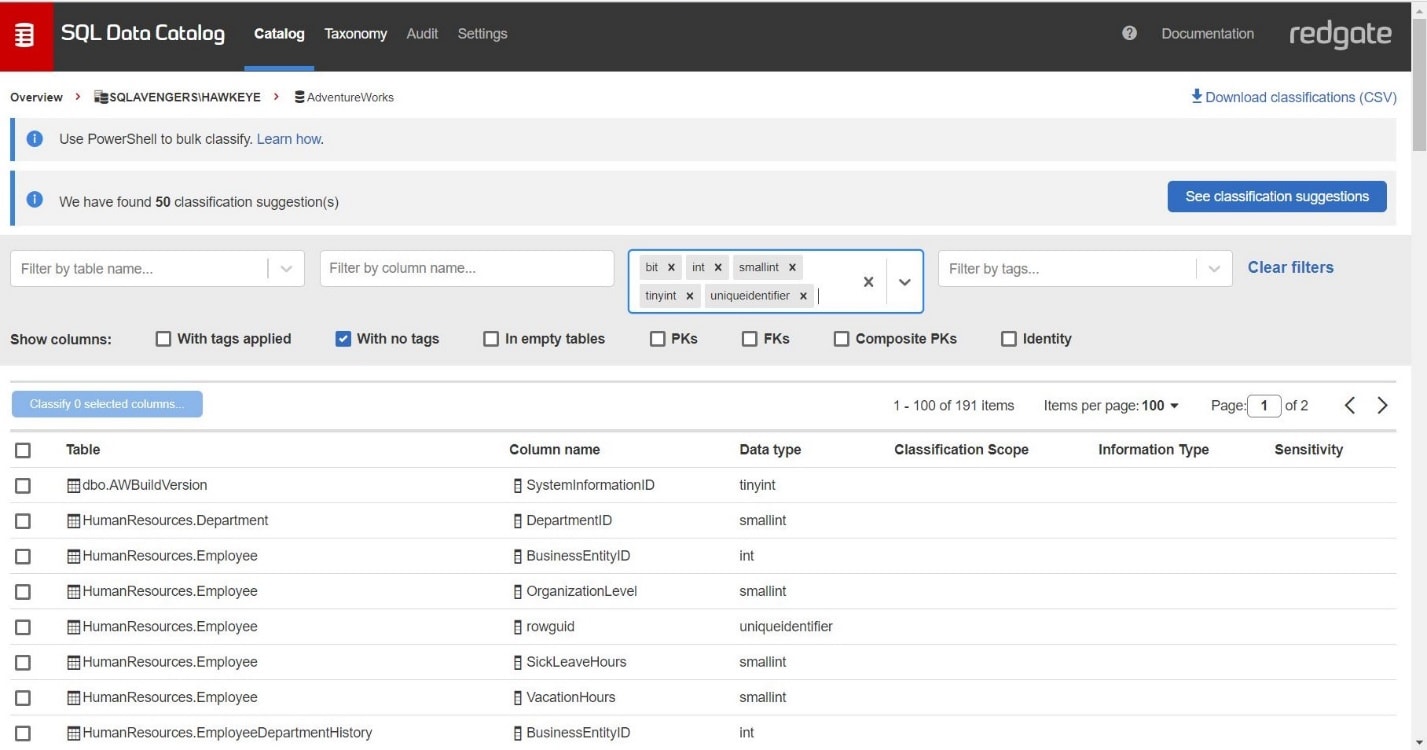
Figure 5: We’ve already found columns we can descope in just a couple of clicks.
Scanning through the filtered results, I decide that I will exclude from my initial auto-cataloging any columns that are within schemas likely to contain personal data (Person, HumanResources) or financial information (Purchasing, Sales). Some of these integer columns might contain only internal data, but not all. For example, some of the integer fields in the Sales schema contain credit card details. I want to take a closer look at all this data before I apply any classification tags.
Any of the various types of integer and bit columns that are in user tables outside these schemas, I’ll tag as In-Scope data with a sensitivity of System.
I can safely tag as Descoped: System data any IDENTITY columns and Primary Keys that are integers and have ID in the name, regardless of the schema. Finally, if a table is empty, I’ll apply the Descoped: Empty table tag.
Auto-cataloging non-personal and non-sensitive data using PowerShell
That’s a fair number of filters, so I’m ready to implement those as part of a PowerShell script. Via PowerShell I’ll pull in the database columns and sort them into three filtered groups that I’ll apply specific metadata to: descoped empty tables, descoped system tables, and in scope system columns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
<# script auth token generated from the data catalog - see <a href="https://documentation.red-gate.com/sql-data-catalog/automation/generating-authorization-token">docs</a> #> $AuthToken = 'MyAuthTokenValue==' $dataCatalog = 'http://MyDataCatalogServer:15156' Invoke-WebRequest -Uri "$dataCatalog/powershell" -OutFile 'data-catalog.psm1' -Headers @{"Authorization" = "Bearer $AuthToken" } Import-Module .\data-catalog.psm1 -Force <# make our initial connection to the data catalog and authenticate #> Connect-SqlDataCatalog -ServerUrl $dataCatalog -ClassificationAuthToken $AuthToken $dbColumns = Get-ClassificationColumn -instanceName 'MyServer\MyInstance' -database "AdventureWorks" <# category info for empty tables #> $descopeEmpty = @{ "Sensitivity" = @("General") "Information Type" = @("Other") "Classification Scope" = @("Descoped: Empty table") } <# all system tables will marked as system tables #> $descopeSystem = @{ "Sensitivity" = @("System") "Information Type" = @("Other") "Classification Scope" = @("Descoped: System data") } <# any application columns #> $inscopeSystem = @{ "Sensitivity" = @("System") "Information Type" = @("Other") "Classification Scope" = @("In-Scope") } <# all empty tables: #> $emptyCols = $dbColumns | Where-Object {$_.tableRowCount -eq 0} <# all tables starting with database in the dbo schema are system tables: #> $descopedSystemCols = $dbColumns | Where-Object {$_.tableName -like "database*" -and $_.schemaName -eq 'dbo'} <# system/application columns that are not in the person, human resources, purchasing or sales schemas #> $systemCols = $dbColumns | Where-Object {$_.schemaName -ne "Person" -and $_.schemaName -ne "Sales" ` -and $_.schemaName -ne "HumanResources" -and $_.schemaName -ne "Purchasing"} | Where-Object {$_.dataType -eq "int" ` -or $_.dataType -eq "smallint" -or $_.dataType -eq "tinyint" -or $_.dataType -eq "bit" -or $_.dataType -eq "uniqueidentifier" } <# primary key fields and identity columns for ID columns #> $idCols = $dbColumns | Where-Object {$_.columnName -like "*ID" -and ($_.dataType -eq "int" -or $_.dataType -eq "tinyint" -or $_.dataType -eq "smallint")} Set-Classification -columns $emptyCols -categories $descopeEmpty Set-Classification -columns $descopedSystemCols -categories $descopeSystem Set-Classification -columns $systemCols -categories $inscopeSystem Set-Classification -columns $idCols -categories $descopeSystem |
That done, I’ve already autocataloged about 30% of the data!
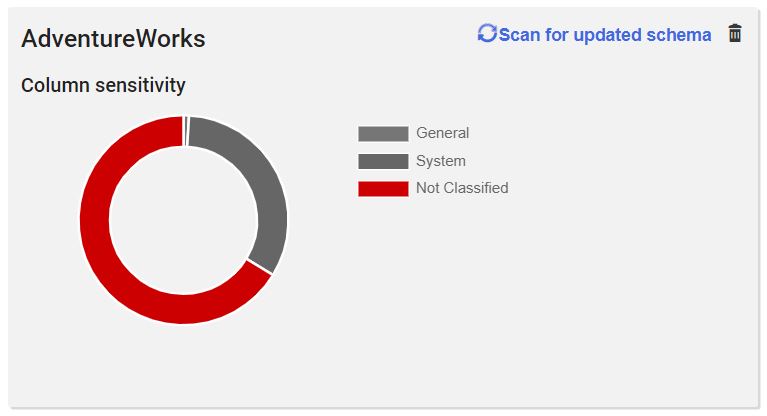
Figure 6: One PowerShell script later and we’re already around 30% complete!
Returning to the Data Catalog dashboard, and filtering by columns with no tags, I quickly discover some columns with *Flag in their name, and a data type of flag. Additionally, there are a series of columns just named rowguid with a uniqueidentifier data type. A closer look at some of the tables illustrates this GUID is not being used as a key to other tables and may not be used at all in the application. I can also find some other columns that start to fit similar “system use” patterns. For example, I’ve also identified multiple columns called ModifiedDate that seem to just capture when a row was last changed.
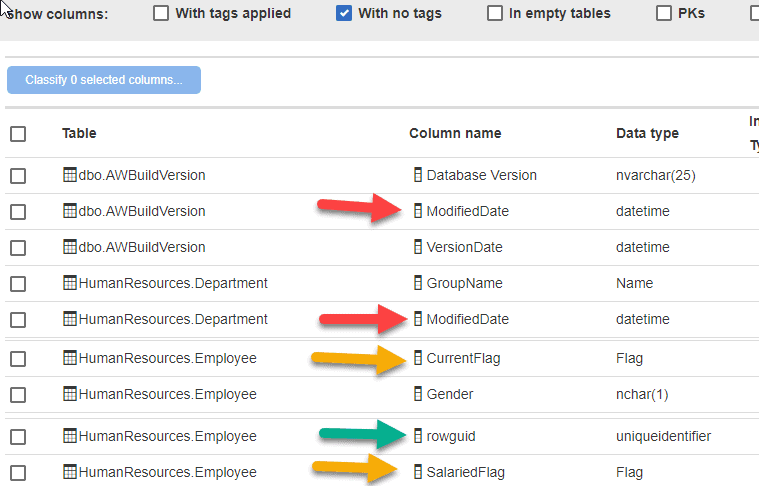
Figure 7: Identifying system-use columns
I can safely categorize these columns, in any schema, as In-Scope and System with a second pass of the data, using the following PowerShell.
|
1 2 3 4 5 6 7 |
<# Categorizing all our flag columns: #> <# get uncategorized db columns so we don't overwrite our previous work #> $dbColumns = Get-ClassificationColumn -instanceName 'MyServer\MyInstance' -database "AdventureWorks" | Where-Object {$_.tags.count -eq 0 ` -and $_.informationType.length -eq 0 -and $_.sensitivityLabel.length -eq 0} $secondPass = $dbColumns | Where-Object {$_.columnName -like "*Flag" -or $_.columnName -eq "ModifiedDate" -or $_.columnName -eq "rowguid"} Set-Classification -columns $secondPass -categories $inScopeSystem |
This done, I’ve classified more than half the data. Returning to the Data Catalog dashboard again, I filter the untagged columns by the Flag data type and discover two columns that my previous script missed, because they don’t have “Flag” in their names.
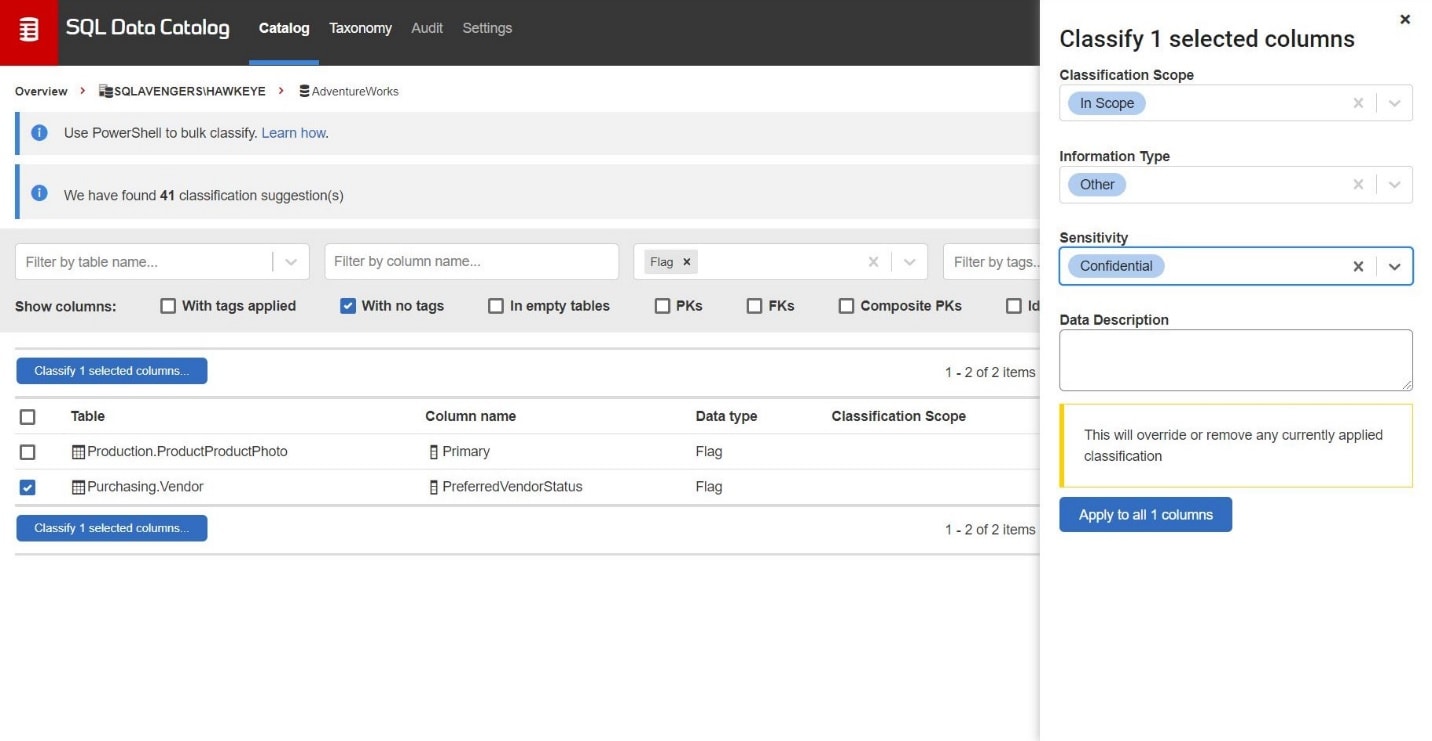
Figure 8: For one-off columns, cataloging through the dashboard is the most efficient.
These one-off classifications are best dealt with directly through the dashboard. The column called Primary is clearly system-use only and I tag it with In-Scope, System. The second one, PreferredVendorStatus, might easily be considered sensitive information about our business processes and I tag it as In-Scope, Confidential.
I now spend some time looking at other integer and bit data types and manually classify this data. Most of it is unremarkable System data and I can quickly tag them as such via the bulk classification interface.
However, I also find some sensitive employee information (sick and vacation hours), credit card data (expiration year), as well as some sales order details. Most of this is confidential information of one kind or another and I mark it as such via the dashboard (In-Scope and Confidential).
Manually and automatically classifying personal and sensitive data
While reviewing the remaining untagged columns in the dashboard, I find many columns related to our product line. I can filter the results to just the Production schema by typing “Production” into the table filter in Data Catalog.
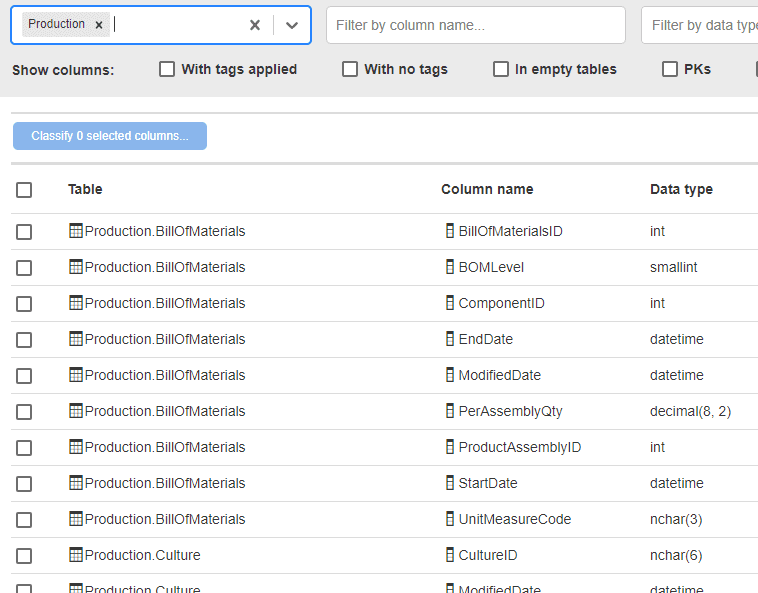
Figure 9: Filtering tables by schema
Mostly, this information is sensitive business data that includes product details and history and so I want to categorize it as Confidential. The only exceptions I can find are a couple of columns in the ProductReview table, which hold the names and contact information for individuals leaving reviews. I manually classify these through the dashboard as Confidential, Name and Confidential, Contact Info.
Having done that, I auto-classify the remaining business-sensitive data via PowerShell.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<# Categorizing data in the production schema: #> <# get uncategorized db columns so we don't overwrite our previous work #> $dbColumns = Get-ClassificationColumn -instanceName 'MyServer\MyInstance' -database "AdventureWorks" | Where-Object {$_.tags.count -eq 0 ` -and $_.informationType.length -eq 0 -and $_.sensitivityLabel.length -eq 0} $inScopeProduct = @{ "Sensitivity" = @("Confidential") "Information Type" = @("Other") "Classification Scope" = @("In-Scope") } $productColumns = $dbColumns | Where-Object {$_.schemaName -eq "Production" -and $_.columnName -ne "ReviewerName" ` -and $_.columnName -ne 'EmailAddress'} Set-Classification -columns $productColumns -categories $inScopeProduct |
A quick check shows I am already over two-thirds finished with the database!
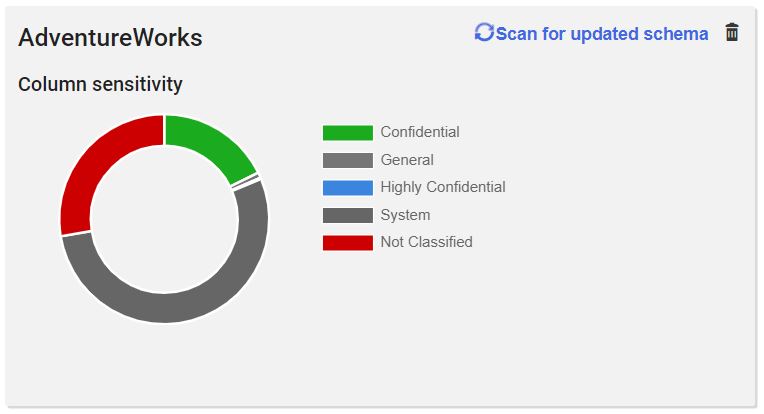
Figure 10: Two-third of AdventureWorks categorized
Time to make another pass through the dashboard! This time, there are a lot of individual categorizations to apply.
The Person.Person and HumanResources.Employee tables obviously have some personal data that we need to categorize through the dashboard, including resumes that could hold names and addresses as well as other contact information. All of these are at Confidential or Highly Confidential with information types assigned according to what’s in each (Date of Birth, Name, Contact Info and so on), although the resumes may contains lots of different information types, and the data governance team may want to review this closely and decide how to classify this and any other columns storing XML data types.
While reviewing the Person.Address table, I find that I accidentally categorized the StateProvinceID as In-Scope, System, but in this table it could potentially be used to identity the person so I update the column via the dashboard to show this is actually sensitive contact information, and then go on to categorize the rest of the address information in the table.
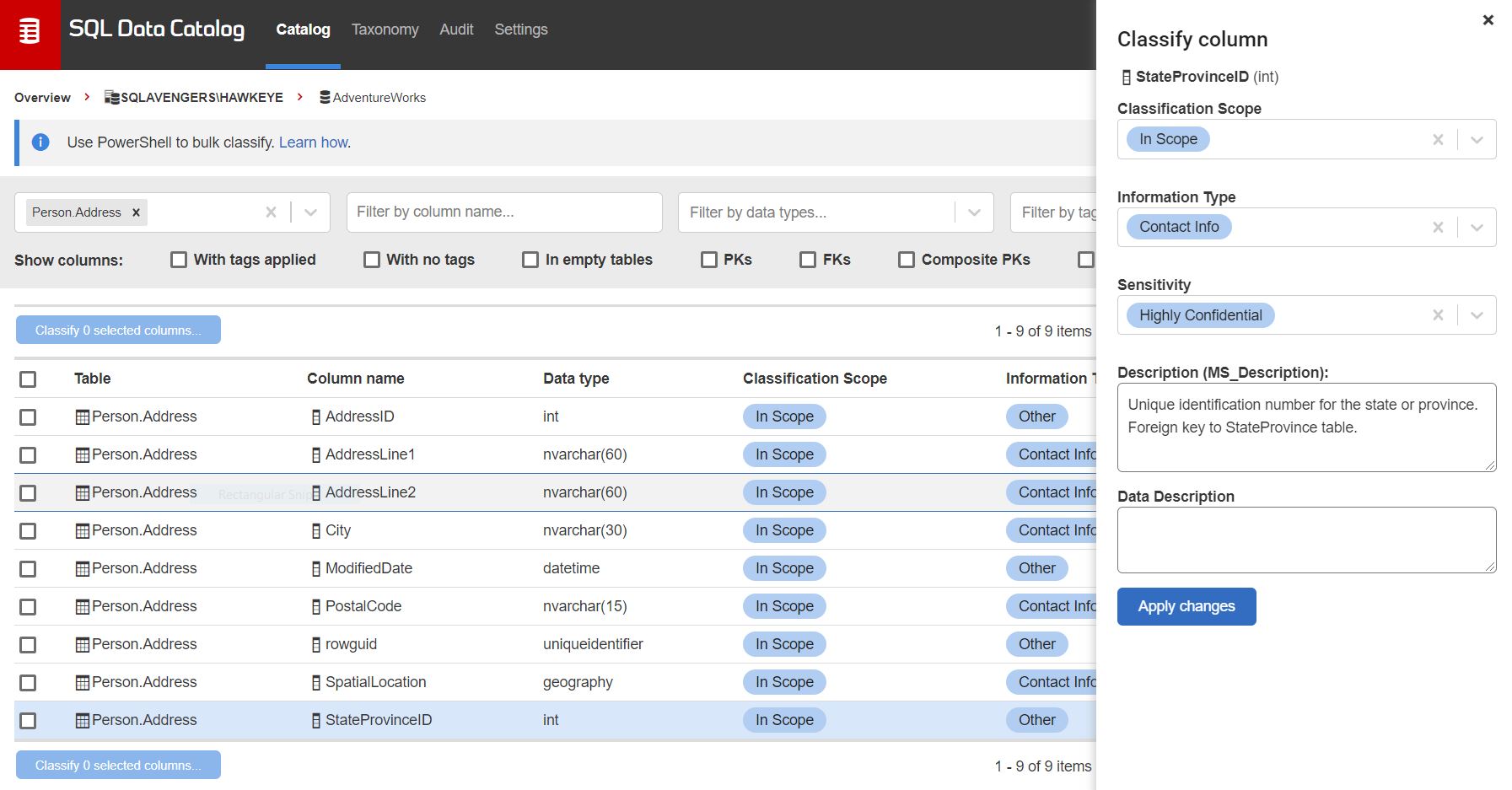
Figure 11: Categorizing address data
I spend some time working my way through one-off columns and tables with similar data categories. Eventually, I find that the remaining information is all in the Purchasing and Sales schemas and seems to all be of a type. I can more quickly script out and apply the metadata back PowerShell, using the same tags as for the sensitive product information.
|
1 2 3 4 5 6 7 8 9 10 11 |
<# get uncategorized db columns so we don't overwrite our previous work #> $dbColumns = Get-ClassificationColumn -instanceName 'MyServer\MyInstance' -database "AdventureWorks" | Where-Object {$_.tags.count -eq 0 ` -and $_.informationType.length -eq 0 -and $_.sensitivityLabel.length -eq 0} $inScopePurchasingSales = @{ "Sensitivity" = @("Confidential") "Information Type" = @("Other") "Classification Scope" = @("In-Scope") } $purchasingSalesCols = $dbColumns | Where-Object {$_.schemaName -eq "Purchasing" -or $_.schemaName -eq "Sales"} Set-Classification -columns $purchasingSalesCols -categories $inScopePurchasingSales |
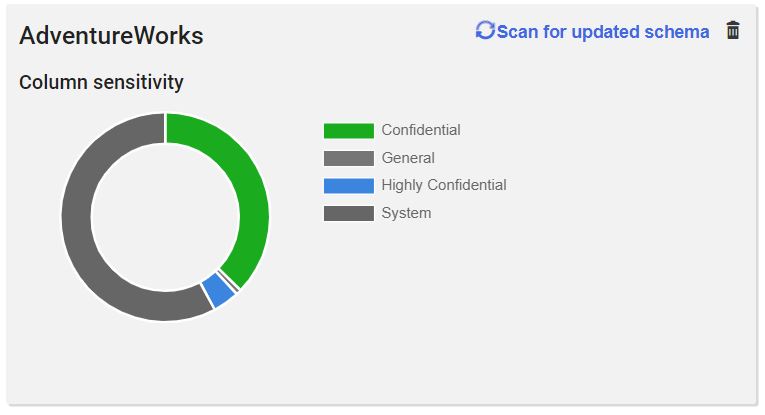
Figure 12: All columns categorized. Of course, this is just the end of the beginning.
Next Steps
Now that the data has been cataloged, it can be handed off to the data governance team for review or to information security to quantify the risk of the data, and to develop processes for masking that data outside of production. Additionally, the work of creating and applying a business-specific taxonomy is yet to be done. This will make the data even more valuable as data analysts or ETL developers will be able to find that data in the SQL estate no matter what the name of the column in the database.
I’ll also want to monitor the database to capture any new tables or columns that are added over time so they can be cataloged properly once they are identified. I have several other databases waiting for the same treatment but by working through cycles of data review, and applying custom scripts, the number of columns that need individual review can be discovered and addressed quickly and efficiently.
Tools in this post
You may also like
-

Article
The challenges – and rewards – of cataloging and masking data at Republic Bank
At Republic Bank, we’ve spent the last five years and more on a mission to be the most technically advanced community bank in the US. With 1,200 employees and around $5+ billion in assets, we might not be the biggest bank, but we like to see ourselves as one of the most innovative. It’s strategically
-

Webinar
POPIA - Set the scene and demo
-

Live training session
Cataloging and Masking AdventureWorks
AdventureWorks is a database we all know and love so there’s no place better to tackle one of the most challenging aspects of protecting data in non-Production environments. Join Chris Unwin in this session as they walk you step-by-step through getting AdventureWorks classified and masked for non-Production use in just 30 minutes. With the help
-
Live training session
Loading Existing Classifications into SQL Data Catalog
Classification is nothing new to companies – many have tried (and in some cases failed) to get columns tagged across their data estate. Much of this work is still usable, however. Join Chris Unwin, a Redgate Solution Engineer, as they take you through some of the best ways to persist your existing classifications into SQL
-
Webinar
POPIA - getting started
-
Article
Meeting your CCPA needs with Data Classification and Masking
This article will explain how to import the data classification metadata for a SQL Server database into Data Masker, providing a masking plan that you can use to ensure the protection of all this data. By applying the data masking operation as part of an automated database provisioning process, you make it fast, repeatable and auditable.





