Security and compliance
Ensure data security and compliance with data masking, monitoring, and change traceability
Ensure data security and compliance with data masking, monitoring, and change traceability
Monitor and understand your databases with full visibility into performance and change
Build, test, and deploy database changes with confidence
Simplify and speed up database development workflows
Prepare reliable data foundations for AI initiatives
Simplify and secure database modernization across platforms
Control costs and boost efficiency in database operations
Simplify and speed up cloud database transformation
Avoiding hidden allocations is a good way to improve performance but sometimes allocations have to be made. There are two major ways to optimize them:
a) Calculate on the stack and publish to the heap
Consider the following code:
public class Counter
{
public int Cnt;
}
...
Thread[] th = new Thread[8];
for (int i = 0; i < th.Length; i++) {
int n = i;
th[i] = new Thread(new ThreadStart(() => {
int cnt = 0;
for (int k = 0; k < 100000000; k++)
{
cnt = cnt + 1;
}
p.arrCounter[n] = new Counter();
p.arrCounter[n].Cnt = cnt;
}));}
We first increment the counter on the stack, after which we publish the results to the heap.
b) Off heap allocate
Consider the following code:
public static unsafe byte* global;
...
unsafe { global = Unsafe.Allocate(65536); } //this uses VirtualAllocEX
...
Thread[] th = new Thread[8];
for (int i = 0; i < th.Length; i++) {
int n = i;
th[i] = new Thread(new ThreadStart(() => {
unsafe {
int* ptr = (int*)(global);
ptr = ptr + (n * 16);
for (int k = 0; k < 100000000; k++) {
*ptr = *ptr + 1;
}}}));}
We allocate unmanaged memory pool and increment the counter and save it to that space.
False sharing is a performance degrading effect that happens when two or more hardware threads (meaning two cores or processors) use the same cache line in the following way:

Consider this simple program:
public static int[] arr = new int[1024];
...
Thread[] th = new Thread[4];
for (int i = 0; i < th.Length; i++)
{
int n = i
th[i] = new Thread(new ThreadStart(() => {
for (int k = 0; k < 100000000; k++) {
arr[n] = arr[n] + 1;
}
}));
}
We create four threads and assign each thread to a specific array index and then increment the counter. This program has false sharing because every thread will use the same cache line. In order to eliminate false sharing, we need to assign each thread its own cache line by offsetting the array index given to each:
public static int[] arr = new int[1024];
...
Thread[] th = new Thread[4];
for (int i = 0; i < th.Length; i++)
{
int n = i;
th[i] = new Thread(new ThreadStart(() => {
for (int k = 0; k < 100000000; k++) {
arr[n * 16] = arr[n * 16] + 1;
}
}));
}
The performance gain of such a simple change is usually two or three times faster, depending on core and processor numbers.
Hidden allocations are a problem because they often allocate a bunch of small stuff on the heap, which introduces memory pressure resulting in garbage collection. There are two major categories of hidden allocations.
a) Hidden boxing
Consider the following code:
public static void Sum(int a, int b)
{
Console.WriteLine("Sum of a {0} b {1} is", a, b, a + b);
}
This code will compile to void [mscorlib]System.Console::WriteLine(string, object, object, object) which means that it will be boxed to objects and allocated on the heap.
A simple .NET code optimization technique here is to call to string on the ints. This will do string allocation but is still better than boxing.
public static void Sum(int a, int b)
{
Console.WriteLine("Sum of a {0} b {1} is", a.ToString(), b.ToString(), (a + b).ToString());
}
b) Lambdas
Lambdas are problematic because they create lots of hidden allocations and can also box values.
Consider the following code:
public static Client FindClientByName(string name)
{
return clients.Where(x => x.Name == name). FirstOrDefault();
}
This simple lambda creates tons of allocations. First of all, it creates a new delegate in the Where clause, but that delegate uses the 'name' variable which is out of scope of the delegate so a helper (capture) class needs to be created to capture that variable.
There is also hidden boxing here because we're calling FirstOrDefault which operates on IEnumerable
The code for FirstOrDefault looks as follows:
public static TSource FirstOrDefault(IEnumerable source) { if (source == null) { throw Error.ArgumentNull("source"); } IList list = source as IList ; if (list != null) { if (list.Count > 0) { return list[0]; } } else { using (IEnumerator enumerator = source.GetEnumerator()) //We will box here! { if (enumerator.MoveNext()) { return enumerator.Current; } } } return default(TSource); }
The fix is simple:
public static Client FindClientByName(string name)
{
foreach(Client c in clients)
{
if (c.Name == name)
return c;
}
return null;
}
In .NET there are lots of hidden components doing things that could potentially lead to false sharing such as GC Compaction, Card Tables, Card Bundles, Brick Tables, and Intern Tables.
The previous code example that fixed false sharing still contains false sharing and it's related to .NET bounded check implementation. In order to check if we're not out of array bounds, the thread that writes (or reads) will need to check its metadata for size, the information for which is stored at the start of the array.

In our program, each thread actually uses not one but two cache lines and the first cache line is shared between all other threads. Since they only need to read from it, everything should be alright.
The sample code shows, however, that the first thread uses this line. There will therefore be one thread that will be writing while others are reading. In other words, false sharing.
To fix this, we need to guarantee that the cache line where metadata of the array is stored has its own cache line and there are no writes to it. We can satisfy this condition if we offset the first thread:
for (int i = 0; i < th.Length; i++)
{
int n = i + 1 // WE ADD ONE;
th[i] = new Thread(new ThreadStart(() => {
for (int k = 0; k < 100000000; k++) {
arr[n * 16] = arr[n * 16] + 1;
}
}));
}
The increase in performance is dependent on the number of threads but on average it will be 10-15%.
Cache prefetching can dramatically improve performance by taking advantage of the way modern processors read data. Consider this simple program:
int n = 10000;
int m = 10000;
int[,] tab = new int[n, m];
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
tab[j, i] = 1; //j instead of i
}
}
This program will execute (depending on the machine) in around 1500 ms. Now let's swap the indexes of the array such that we will start from 'I' and move to 'j'.
int n = 10000;
int m = 10000;
int[,] tab = new int[n, m];
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
tab[i, j] = 1; //i instead of j
}
}
Now this program will execute in around 700 ms, so on average it will run at least two times faster. In terms of pure memory access, array indexing should not make a change since virtual memory addressing makes the memory seam linear and its access times should be more or less the same.
It happens because modern processors read data in portions called lines (usually 64 bytes). Processors also detect memory access patterns so if our memory access is predictable then all of the data needed to execute our loop will be loaded ahead of time (cache prefetching).
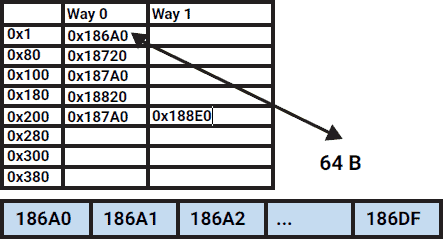
So the first example will load an entire line of continuous data, write to the first four bytes (the size of an int) then throw it into oblivion and load another one write and throw it away and so on. This is very inefficient and usually prevents cache prefetching since processors only prefetch data on linear data access patterns.
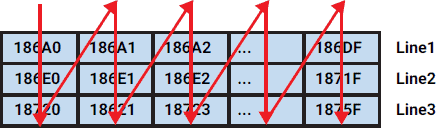
The second example loads a cache line, modifies all data cells in that line and then loads the next one and so on, which is much faster.

The given example was doing writes only, but if it read from an already populated array the performance impact would be much greater because writes are always volatile and some cycles are wasted writing to main memory.
The takeaway is that you should access your data structures and arrays in a sequential way rather than jumping through the memory.






