Sicherheit und Compliance
Gewährleisten Sie Datensicherheit und Compliance mit Datenmaskierung, Monitoring und Änderungsnachverfolgung
Gewährleisten Sie Datensicherheit und Compliance mit Datenmaskierung, Monitoring und Änderungsnachverfolgung
Überwachen und verstehen Sie Ihre Datenbanken mit vollständiger Transparenz über Leistung und Änderungen
Datenbankänderungen sicher erstellen, testen und bereitstellen
Datenbankentwicklungsprozesse vereinfachen und beschleunigen
Zuverlässige Datengrundlagen für KI-Initiativen vorbereiten
Plattformübergreifende Modernisierung von Datenbanken vereinfachen und absichern
Kosten steuern und Effizienz im Datenbankbetrieb erhöhen
Transformation von Cloud-Datenbanken vereinfachen und beschleunigen
„Wow, alles läuft plötzlich viel schneller. Was habt ihr gemacht?“
Ganz ehrlich: Solche Anrufe erwarte ich als DBA nicht oft. Aber es sind genau die Anrufe, die wir uns eigentlich wünschen - und ab und zu kommen sie tatsächlich vor.
In diesem Fall hatten wir im Betriebsteam gemeinsam mit den Entwicklern an einer Runde von Datenbankänderungen gearbeitet. Der Grund: Wir hatten festgestellt, dass die Performance einer unserer Datenbanken über die Zeit nachgelassen hatte. Also machten wir Vorschläge, wie wir die Leistung verbessern und gleichzeitig das Deployment der Änderungen einfacher gestalten könnten.
Das Entscheidende dabei: Schon Wochen vor der Umsetzung hatten wir **Baseline-Daten** für mehrere wichtige SQL Server-Kennzahlen gesammelt. Dadurch wussten wir genau, wie die Ressourcennutzung vor den Änderungen aussah. Nach der Umsetzung konnten wir dieselben Messungen erneut durchführen - und so schwarz auf weiß sehen, welchen Effekt unsere Arbeit auf die Auslastung des Servers hatte.
Das Ergebnis: Wir hatten nicht nur den Anruf eines zufriedenen Users als Bestätigung, sondern auch konkrete Zahlen, die wir unserem Manager zeigen konnten. Und damit bekamen wir als Team die Anerkennung für die Verbesserung.
Erin Stellato beschreibt eine Baseline treffend als *„einen Bezugspunkt, von dem aus Veränderungen gemessen werden können“*. Stellen wir uns vor, ein User meldet, dass seine Anwendung oder ein Bericht heute Morgen ungewöhnlich langsam war. Stimmt das? Und falls ja: Warum? Hatten wir plötzlich mehr User-Verbindungen? Gab es auffällige Muster bei CPU-, I/O- oder Speichernutzung? Oder hat jemand im Betrieb eine Servereinstellung geändert? Ohne **Baselines** ist das kaum seriös zu beantworten. Um beurteilen zu können, ob zum Beispiel die CPU-Auslastung wirklich ungewöhnlich hoch war, müssen wir wissen, was für unseren Server „normal“ ist - sprich: wir brauchen eine Vergleichsmessung aus einem typischen Zeitraum unter normaler Last.
Wir können Baselines für viele verschiedene Performance-Kennzahlen und Rahmenbedingungen anlegen. Typische Beispiele wären regelmäßige Messungen für:
Um das Ganze greifbarer zu machen, schauen wir uns zwei „Snapshots“ der Wait Statistics einer SQL Server-Instanz an. Sie stammen jeweils aus einer Abfrage der DMV sys.dm_os_wait_stats. Die Statistiken wurden am Ende jedes Tages zurückgesetzt.
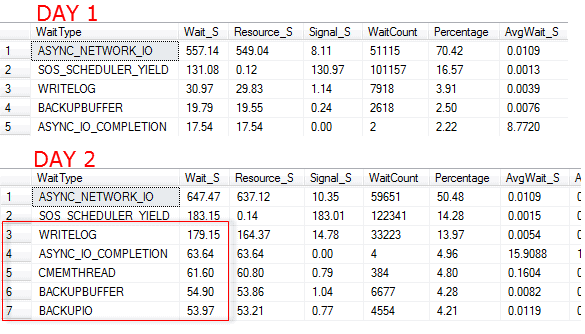
Abbildung 1 - Ergebnisse einer Abfrage von `sys.dm_os_wait_stats`
Sieht man sich nur einen dieser Snapshots an, wirken manche Wait Types vielleicht beunruhigend. Aber ohne Vergleich wissen wir nicht, ob das für diesen Server ungewöhnlich ist. Erst wenn wir beide Tage nebeneinanderlegen, wird klar: An Tag 2 gab es ungewöhnliche Aktivität. Viele Wait Types sind zwar an beiden Tagen vorhanden, aber ihre Werte sind am zweiten Tag deutlich höher - vor allem I/O-bezogene Wartezeiten wie `WRITELOG`, `ASYNC_IO_COMPLETION` und die Wartezeiten im Zusammenhang mit Backups.
Als DBA sollte man die geplanten Backup-Jobs prüfen und herausfinden, welches Backup in diesem Zeitraum lief - und warum es länger dauerte als üblich. Ebenso lohnt sich ein Blick auf die I/O-Performance des Backup-Speicherorts. In unserem Fall war ein reguläres Backup wegen eines umfangreichen Datenimports plötzlich deutlich größer als sonst.
Genau das ist der Kern von Baselines: Wenn wir regelmäßig Performance- und andere Messwerte erfassen, können wir im Laufe der Zeit Trends erkennen und auffällige Muster schneller identifizieren. So lassen sich auch plötzliche Veränderungen sichtbar machen - etwa nach einem neuen Code-Release oder einer geänderten Hardwarekonfiguration.
Der eingangs erwähnte Anruf unseres überraschten Users bezog sich auf die bessere Performance einer ERP-Anwendung eines Drittanbieters, für die unsere SQL Server-Instanz als Backend diente. Der Anbieter ließ nur begrenzte Änderungen zu, aber im Laufe der Zeit hatten die Entwickler dennoch zusätzliche Objekte ins Backend eingebaut. Das Betriebsteam konnte darauf kaum Einfluss nehmen, und mit jeder neuen Version wurde die Datenbank ein Stück langsamer. Über Monate hinweg beschwerten sich User über Batch-Prozesse, die ewig brauchten. Uns war klar: Wir mussten etwas ändern.
Unser erster Schritt war, regelmäßig die wichtigsten Performance-Kennzahlen zu erfassen. Damit hatten wir Baselines, um die Ressourcennutzung des Servers genauer zu beobachten und rechtzeitig Spitzen oder kritische Trends zu erkennen.
Auf dieser Grundlage planten wir, beim nächsten Deployment enger mit der Entwicklung zusammenzuarbeiten und gezielt Verbesserungen einzubauen.
Theoretisch ist das Sammeln von Baseline-Daten recht einfach: Wir schreiben eine Abfrage, lassen sie regelmäßig laufen und speichern die Ergebnisse in einer Tabelle zur späteren Analyse. So lässt sich zum Beispiel der **full scans/sec** PerfMon-Counter mit einer simplen Abfrage erfassen. Erin Stellato hat dazu auf SQLServerCentral eine Reihe von Artikeln, die zeigen, wie man das für PerfMon-Daten, Konfigurationseigenschaften, Wait Statistics und Speicherplatz umsetzt.
In der Praxis bedeutet das allerdings einiges an Verwaltungsaufwand: Wir müssen entscheiden, wie oft welche Metriken erfasst werden, wie lange wir die Daten aufbewahren und welche Jobs alte Daten automatisch löschen. Gerade bei DMVs mit aggregierten Werten ist es sinnvoll, regelmäßig zu löschen - so vergleichen wir immer Messwerte über denselben Zeitraum, etwa einen Tag, wenn wir die DMV-Daten für Wait Statistics jede Nacht zurücksetzen.
Außerdem brauchen wir Abfragen und Auswertungen, die aus den Rohdaten verständliche Berichte machen. So können wir Werte über Tage, Wochen oder Monate vergleichen und erkennen, ob es langfristige Trends oder plötzliche Ausreißer im Verhalten des Systems gibt.
Ein großer Vorteil von Redgate Monitor ist, dass es automatisch viele nützliche Leistungsdaten aufzeichnet. Dazu gehört zum Beispiel die CPU-Auslastung. In der Produktionsdatenbank zeigte sich dabei eine Reihe von CPU-Spitzen - eine davon sehen Sie in Abbildung 2.
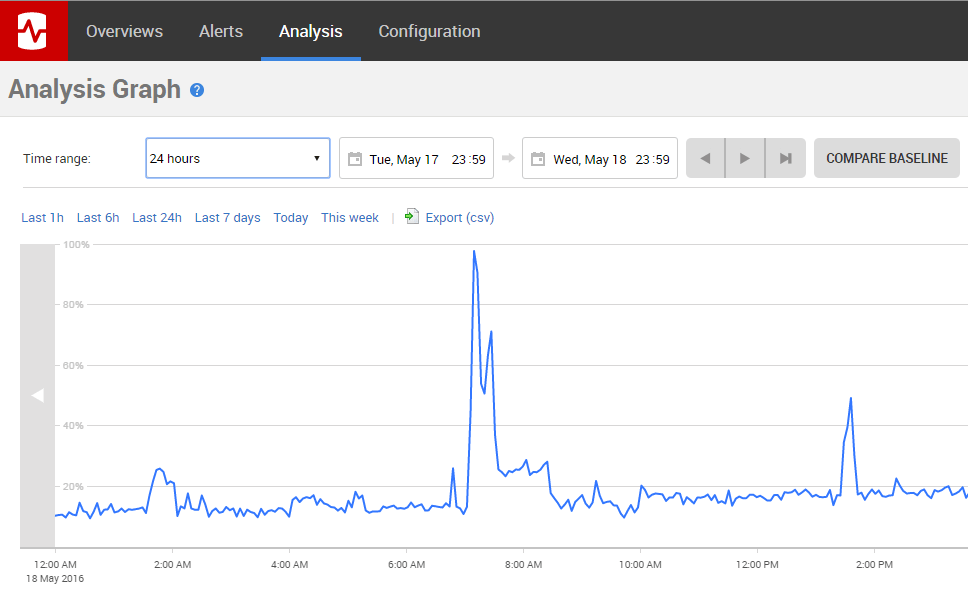
Abbildung 2 - Anstieg der CPU-Auslastung
Bei der Analyse der Abfragen rund um diese CPU-Spitze stellte sich heraus, dass sie von einem geplanten Job ausgelöst wurde. Dieser Job erzeugte einen Kundenverkaufsbericht, in dem eine skalare Funktion namens `dbo.udfProperCase` aufgerufen wurde, um Kundennamen korrekt zu formatieren. Das Problem: Diese UDF wurde nicht nur beim geplanten Job, sondern auch jedes Mal ausgeführt, wenn ein Vertriebsmitarbeiter den Bericht ad hoc startete.
Um das Verhalten mit früheren Ausführungen zu vergleichen, haben wir die Funktion **Baseline vergleichen** genutzt. Damit lässt sich dem Diagramm ein zweiter Datensatz hinzufügen, etwa für die CPU-Auslastung der letzten 24 Stunden. So erhält man eine Baseline, die als Vergleich dient. Anschließend haben wir die Baseline auf mehrere Zeiträume erweitert. Ausgehend von einem 24-Stunden-Vergleich haben wir sieben weitere Zeiträume hinzugefügt, sodass im Diagramm die Werte der letzten sieben Tage nebeneinander sichtbar wurden.
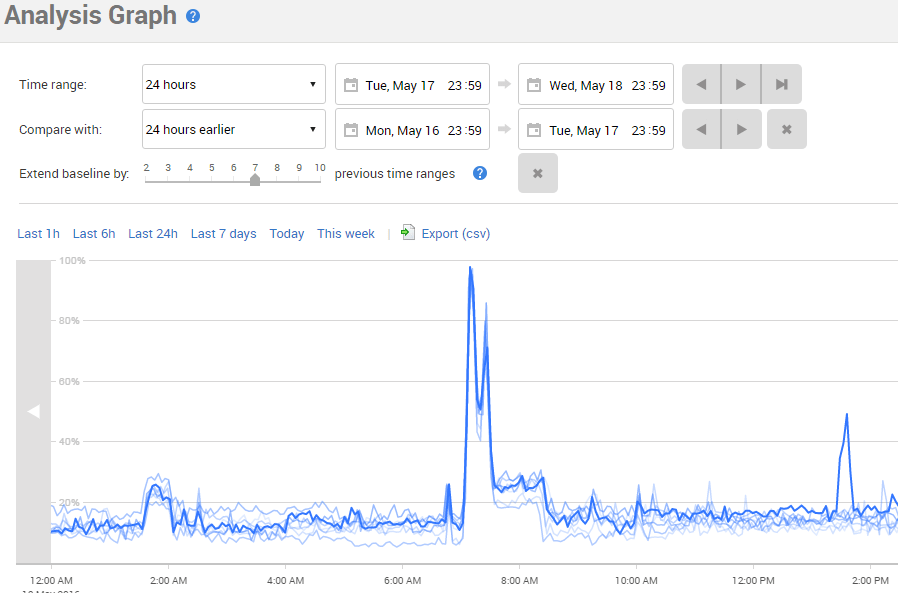
Abbildung 3 - CPU-Spitzen im Vergleich mit einer Baseline
Um das Ganze noch klarer darzustellen, können wir auch gemittelte Bereiche der Baselines einblenden. Dafür genügt ein Klick auf die Schaltfläche **Regionen** oben im Diagramm. Redgate Monitor zeigt die aktuellen Daten weiterhin als Linie, während die übrigen Daten geglättet und nach Quartilen farblich hervorgehoben werden. Der Bereich zwischen dem 1. und 3. Quartil wird dunkelblau dargestellt, die äußeren Bereiche heller blau.
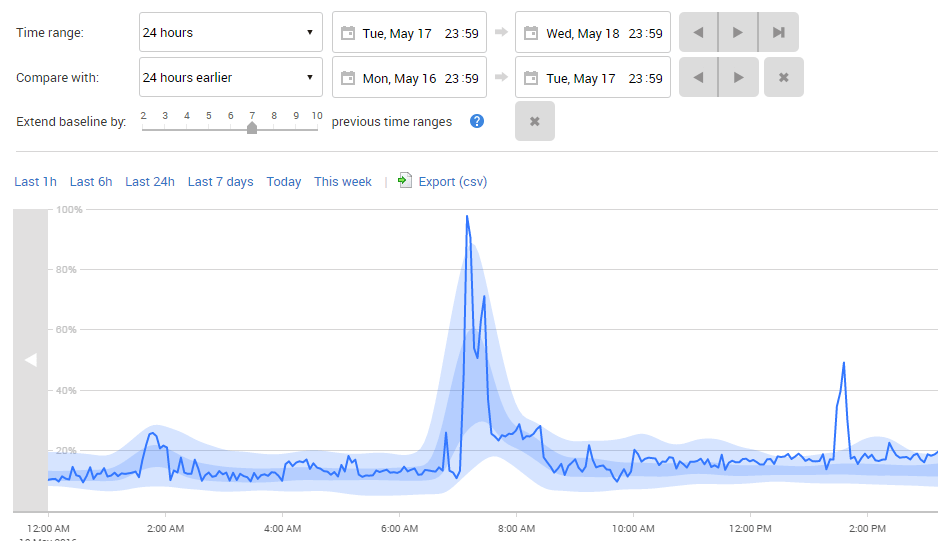
Abbildung 4 - CPU-Spitzen im Baseline-Bereich
Daran sehen wir gut, dass die CPU-Spitze um 7 Uhr morgens völlig normal ist - sie tritt jedes Mal auf, wenn der Bericht läuft. Allerdings ist bekannt, dass skalare Funktionen oft für Performance-Probleme sorgen. Genau das schien hier ebenfalls der Fall zu sein.
Doch das war nicht das einzige Problem: Auch bei der Metrik **full scans/sec** tauchten immer wieder Spitzen auf.
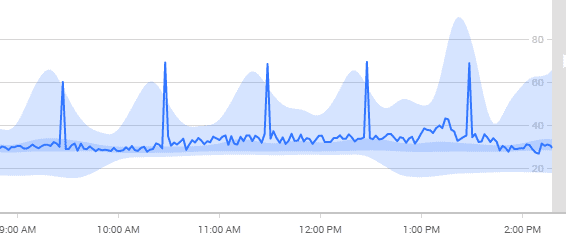
Abbildung 5 - Spitzen und Baselines bei Full Scans/Sek.
Bei der weiteren Analyse stellten die DBAs fest, dass diese Performance-Daten mit mehreren Warnmeldungen niedriger Priorität zusammenfielen, die wegen lang laufender Queries ausgelöst wurden. Diese Alarme sprangen jedes Mal an, wenn eine Abfrage länger als eine Minute dauerte. Die genauere Untersuchung zeigte, dass viele dieser Queries komplette Tabellenscans über Millionen von Zeilen durchführten - obwohl das Endergebnis oft nur ein paar Dutzend Zeilen umfasste.
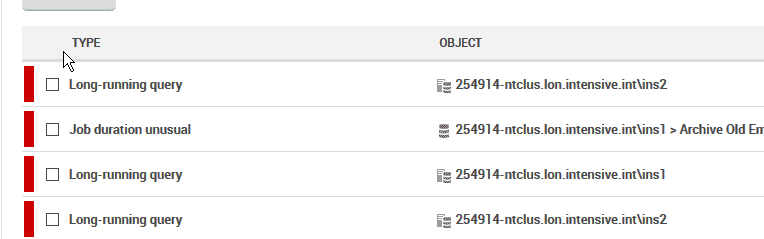
Abbildung 6 - Mehrere Warnungen zu langlaufenden Queries
Wir stellten fest, dass viele dieser Queries Datumsparameter verwendeten, um die Ergebnisse einzuschränken - allerdings waren die entsprechenden Datumsspalten in den Tabellen gar nicht indiziert.
Unser Vorschlag an das Entwicklungsteam war, dass das Betriebsteam bei der nächsten Runde geplanter Datenbankänderungen enger mitarbeitet - und dass wir gemeinsam unser erstes Deployment nach DevOps-Prinzipien ausprobieren.
Auf Basis der Monitoring-Daten und Baselines empfahlen wir außerdem, die UDF aus dem Verkaufsbericht zu entfernen. Da nur die ERP-Anwendung diese Funktion benötigte, schlugen wir vor, sie in C# neu zu implementieren und direkt in die Anwendung zu verschieben. Die Anpassung betraf zwar viele verschiedene Klassen, war aber technisch gut machbar. Erste Tests zeigten schnell, dass die Umsatzberichte mit der neuen C#-Funktion 200 bis 400 % schneller liefen als mit der alten T-SQL-UDF.
Nach mehreren Gesprächen mit dem Third-Level-Support des Herstellers erhielten die Operations-DBAs die Freigabe, nicht-geclusterte Indizes auf die Datumsspalten anzulegen, um die Queries besser abzudecken - mit der Bedingung, dass diese Indizes im Supportfall wieder leicht entfernt werden können.
Die Änderungen wurden dem Entwicklungsteam übergeben, getestet und zusammen mit der Anpassung zur Entfernung der UDF ausgerollt. Das Ergebnis: spürbar bessere Performance für die Kunden. Genau das führte zu dem positiven Anruf, mit dem unsere Geschichte begann - und auch die Server zeigten klar verbesserte Nutzungsmuster.
Nach dem Gespräch und weiteren Auswertungen erstellten wir einen Bericht, der die Auswirkungen der täglichen Verkaufsberichte dokumentierte. Für die Kunden änderte sich die Workload kaum - Abbildung 7 macht aber deutlich, wie stark die CPU-Last gesunken ist.
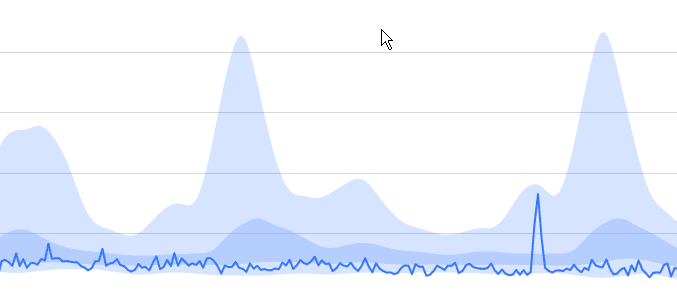
Abbildung 7 - Deutlich reduzierte CPU-Nutzung mit Baselines
Dank der neuen Indizes sank auch die Zahl der Tabellenscans in dieser Datenbank erheblich.
Das gesamte DevOps-Team war zufrieden: die Kunden waren glücklicher, und die Zahl der Tickets wegen Performance-Problemen ging zurück. Inzwischen laufen bereits weitere Projekte nach demselben Muster - mit dem Ziel, Änderungen schnell und kontrolliert bereitzustellen und ihre Auswirkungen auf die Nutzer systematisch zu messen. Ein Teil davon ist sehr menschlich: echte Nutzerzitate werden gesammelt, und einige Kommentare liest man in gemeinsamen Dev-/Ops-Meetings vor.
Der andere Teil ist wissenschaftlicher: Redgate Monitor liefert sowohl Entwicklern als auch DBAs belastbare Daten über die Systemauswirkungen. Neben klassischen Performance-Kennzahlen lassen sich auch benutzerdefinierte Business-Counter verfolgen, sodass sich objektiv feststellen lässt, ob eine Änderung die Performance verbessert oder verschlechtert. Subjektive Eindrücke wie „fühlt sich langsam an“ gehören damit der Vergangenheit an.
Zusätzlich erstellt Redgate Monitor Deployment-Reports, die die Performance vor und nach einem Release vergleichen. Diese Berichte werden an alle Entwickler und DBAs verteilt und dienen auch bei den halbjährlichen Reviews als Grundlage. Denn nichts untermauert eine Gehaltserhöhung besser als harte Fakten - schwarz auf weiß in einem Redgate Monitor Report.
Für weitere Informationen über Redgate Monitor, eine Demo oder Best Practices nehmen Sie gern Kontakt mit uns auf.

Seit mehr als 25 Jahren entwickelt Redgate spezialisierte Software für Datenbanken. 92 % der Fortune-100-Unternehmen setzen auf unsere Lösungen. Insgesamt vertrauen uns über 200.000 Kunden weltweit.

Redgate bietet eine umfassende Dokumentation und ein kompetentes, engagiertes Support-Team. Im Schnitt bewerten 87 % unserer Kundinnen und Kunden unseren Support mit „Ausgezeichnet“.




