Sicherheit und Compliance
Gewährleisten Sie Datensicherheit und Compliance mit Datenmaskierung, Monitoring und Änderungsnachverfolgung
Gewährleisten Sie Datensicherheit und Compliance mit Datenmaskierung, Monitoring und Änderungsnachverfolgung
Überwachen und verstehen Sie Ihre Datenbanken mit vollständiger Transparenz über Leistung und Änderungen
Datenbankänderungen sicher erstellen, testen und bereitstellen
Datenbankentwicklungsprozesse vereinfachen und beschleunigen
Zuverlässige Datengrundlagen für KI-Initiativen vorbereiten
Plattformübergreifende Modernisierung von Datenbanken vereinfachen und absichern
Kosten steuern und Effizienz im Datenbankbetrieb erhöhen
Transformation von Cloud-Datenbanken vereinfachen und beschleunigen
Von Tony Davis
Bei der Suche nach den Ursachen für schlechte Performance in SQL Server ist es ein häufiger Fehler, sich nur auf einzelne Messwerte wie CPU-Auslastung oder I/O-Kapazität zu verlassen. Wer nur eine Kennzahl betrachtet, läuft Gefahr, die Ursache falsch zu deuten.
CPU, I/O und Speicher hängen eng zusammen - und genau dieses Zusammenspiel müssen wir verstehen. Erst wenn wir das Gesamtbild sehen, können wir sinnvolle Maßnahmen ergreifen. Einfach mehr Speicher hinzufügen, den Plattendurchsatz erhöhen oder Konfigurationen anpassen, ohne die Hintergründe zu kennen, führt oft am eigentlichen Problem vorbei.
„Prozess X läuft langsam. Können Sie das beheben?“
Als DBA starten Sie den Windows-Ressourcenmonitor und entdecken sofort ein auffälliges Muster in den Festplattenaktivitäten.
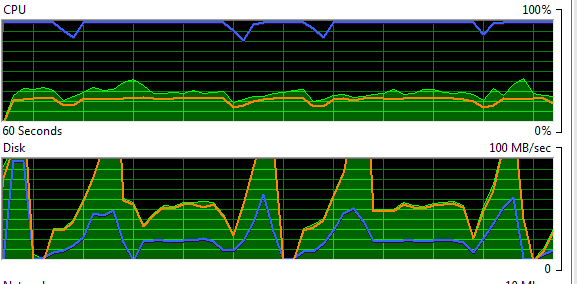
Abbildung 1 - Der Windows-Ressourcenmonitor zeigt ein ungewöhnliches Muster von Festplattenaktivitäten
Ihr erster Gedanke: Das Festplattensubsystem ist ausgelastet. Um das zu prüfen, erfassen Sie einige Disk Counter im Windows Performance Monitor (PerfMon).
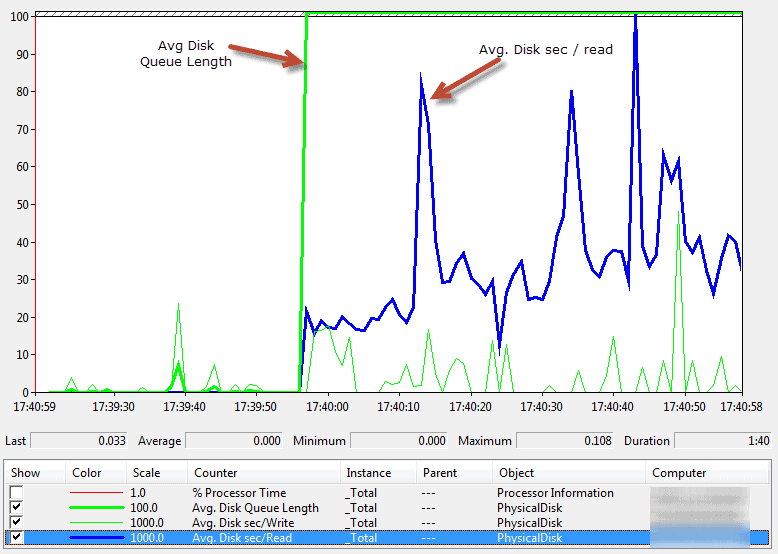
Abbildung 2 - Durchschnittliche Festplattenwarteschlange und Sekunden pro Lesevorgang im Performance Monitor
Die Werte zeigen: Es gibt Phasen mit hoher Latenz beim Lesen von der Festplatte, verbunden mit einer stark wachsenden Warteschlange. Das Subsystem scheint ein Engpass zu sein - die I/O-Performance von SQL Server sinkt, und Anfragen stauen sich.
Wie geht man jetzt vor? Bevor Sie den Systemadministrator fragen, ob mehr Kapazität nötig ist, sollten Sie genauer hinschauen.
Wer sich zu früh auf eine einzelne Kennzahl stützt, riskiert eine Fehldiagnose. Zwar deuten die Daten auf ein I/O-Problem hin, doch das heißt nicht zwingend, dass die Festplatten zu schwach oder falsch konfiguriert sind. Die Ursache für langsame Zugriffe kann ganz woanders liegen. Es braucht mehr Daten, um das wirkliche Problem zu finden. Aber wo anfangen?
Ein sinnvoller Startpunkt sind die SQL Server Wait Statistics. Sie zeigen, warum Sessions warten mussten, bevor sie auf benötigte Ressourcen zugreifen konnten. Die Analyse dieser Wartezeiten macht deutlich, welche Ressourcen die größten Engpässe verursachen und wo es zu Konflikten kommt.

Das kostenlose eBook von Jonathan Kehayias und Erin Stellato gibt einen hervorragenden Überblick über Wait Statistics und erklärt viele der gängigsten Wait Types - auch die, die wir hier im Artikel betrachten.
Die DMV `sys.dm_os_waiting_tasks` zeigt alle gerade laufenden Anfragen, die auf Ressourcen warten. Verknüpft man sie mit anderen DMVs, erhält man Details zu den zugehörigen Sessions und Queries. Pinal Dave hat das sehr anschaulich demonstriert. In unserem Beispiel sehen wir zwei Wait Types zusammen mit den Query-Texten und Ausführungsplänen.

Abbildung 3 - Die Waits `ASYNC_NETWORK_IO` und `PAGEIOLATCH`
Oft untersuchen wir Probleme allerdings im Nachhinein - dann ist diese DMV weniger hilfreich. In solchen Fällen greifen wir besser auf `sys.dm_os_wait_stats` zurück. Sie liefert kumulierte Werte („laufende Summen“) für alle Wait Types seit dem letzten Serverneustart oder seit einem manuellen Reset mit `DBCC SQLPERF`. Paul Randal stellt eine praktische Abfrage bereit, die viele unkritische Wait Types ausblendet. Abbildung 4 zeigt die Ausgabe in unserem Beispiel.
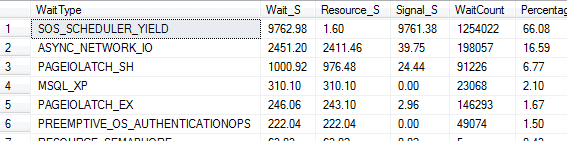
Abbildung 4 - Liste der Wait Types, gesammelt seit dem letzten Reset des Servers
Die beiden Wait Types aus unseren aktuellen Queries - `ASYNC_NETWORK_IO` und `PAGEIOLATCH_SH` (siehe Abbildung 3) - tauchen auch in dieser historischen Liste weit oben auf. Doch Vorsicht: Wenn das Problem einmalig oder selten ist, können solche Wait Types in den Gesamtdaten leicht untergehen. Deshalb ist es wichtig, Basiswerte (Baselines) für die Wait Statistics zu erfassen, wie im eBook beschrieben.
`ASYNC_NETWORK_IO` weist auf Wartezeiten im Netzwerk hin. Häufig bedeutet das, dass der Client die gelieferten Daten nicht schnell genug verarbeiten kann. In unserem Beispiel laufen Queries mehrfach und schicken große Datenmengen an SSMS. Achten Sie generell auf diesen Wait Type - er kann ein Hinweis auf langsame oder ineffiziente Client-Verarbeitung sein.
Spannender ist hier der Wait Type `PAGEIOLATCH_SH`. Er zeigt an, dass Leseanforderungen warten mussten, um einen Latch zu bekommen, damit Seiten von der Festplatte gelesen werden konnten, die nicht im Buffer Cache lagen. Das stützt unsere erste Vermutung: Das Festplatten-Subsystem ist überlastet oder falsch konfiguriert. Wenn es die Seiten nicht schnell genug liefert, stauen sich Anfragen und konkurrieren um Latches.
Vermutet man einen I/O-Engpass, stellt sich die nächste Frage: Was ist die eigentliche Ursache? Ein guter nächster Schritt ist die Analyse der I/O-Workload. Gibt es bestimmte Datenbanken oder Dateien, die besonders viele I/O-Zugriffe erzeugen?
Hier hilft die DMV `sys.dm_io_virtual_file_stats`. Damit lassen sich Dateistatistiken abfragen, zum Beispiel mit der Abfrage von Glenn Berry (Query #31). Abbildung 5 zeigt die Ausgabe im Beispiel.
Damit bekommen wir einen guten Einblick in die I/O-Aktivitäten einer SQL Server-Instanz. Besonders hilfreich ist das, um zu sehen, wie sich die I/O-Last auf die verschiedenen Datenbanken verteilt.
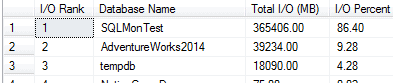
Abbildung 5 - Ergebnisse der `sys.dm_io_virtual_file_stats` DMV
Hier sehen wir, dass die Datenbank `SQLMonTest` ein klarer I/O-Hotspot ist. Diese Statistiken werden, genau wie die Wait Statistics, seit dem letzten Neustart gesammelt. Anders als bei den Wait Statistics lassen sie sich jedoch nicht manuell zurücksetzen. Weitere Abfragen (z. B. Listing 6 aus dem oben erwähnten eBook) können uns helfen, gezielt hohe Lese- oder Schreiblatenzen einzelnen Datenbanken zuzuordnen. In diesem Beispiel stehen `AdventureWorks2014` und `SQLMonTest` ganz oben auf der Liste.

Abbildung 6 - Die beiden Datenbanken mit den meisten I/O-Hotspots
Wenn wir das Problem auf eine oder zwei Datenbanken eingegrenzt haben, stellt sich die nächste Frage: Welche Queries verursachen eigentlich diese hohe I/O-Last? Dafür können wir uns die in `sys.dm_exec_query_stats` gespeicherten Ausführungsstatistiken ansehen. So finden wir etwa die Queries mit den meisten physischen Lesezugriffen zusammen mit ihren Plan Handles (einige Spalten wurden in der Ausgabe weggelassen) für eine bestimmte Datenbank.
SELECT TOP 10 t.text , execution_count , statement_start_offset AS stmt_start_offset ,sql_handle , plan_handle , total_logical_reads / execution_count AS avg_logical_reads , total_logical_writes / execution_count AS avg_logical_writes , total_physical_reads / execution_count AS avg_physical_readsFROM sys.dm_exec_query_stats AS sCROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS tWHERE DB_NAME(t.dbid) = 'SQLMonTest'ORDER BY avg_physical_reads DESC;

Listing 1 - Beispielabfrage zum Abrufen von Ausführungsstatistiken aus `sys.dm_exec_query_stats`
Mit den Plan Handles aus Listing 1 können wir anschließend `sys.dm_exec_query_plan` abfragen, um die Ausführungspläne dieser Queries einzusehen und zu prüfen, ob es Optimierungspotenzial gibt.
Bisher haben wir einzelne Tools, Views und Abfragen genutzt, um uns Schritt für Schritt ein Bild der Serveraktivität zu machen und die Ursache des Performance-Problems einzugrenzen.
Ein Tool wie Redgate Monitor bringt diese Informationen an einem zentralen Ort zusammen. Es löst Warnungen bei auffälligen Situationen aus, etwa bei einer „Long-Running Query“, und liefert dazu Snapshots, Übersichten und Metriken zu Ressourcennutzung und Query-Aktivität. So können wir sehr schnell erkennen, was genau im Problemzeitraum passiert ist.
In unserem Beispiel meldet Redgate Monitor ebenfalls eine erhöhte Lese-Latenz - genau das, was wir zuvor schon mit PerfMon gesehen haben. Zusätzlich zeigt es aber auch eine Vielzahl anderer Metriken im gleichen Diagramm. So lassen sich unterschiedliche Ressourcenbelastungen direkt miteinander vergleichen und mit den Queries in Verbindung bringen, die zu diesem Zeitpunkt liefen.
Spannend ist dabei, dass genau in dem Moment, in dem die I/O-Latenz nach oben schnellt, gleichzeitig die „Page life expectancy“ deutlich sinkt. Das kann auf Speicherdruck hindeuten - SQL Server musste Seiten aus dem Cache werfen, um Platz für neu angeforderte Seiten zu schaffen.
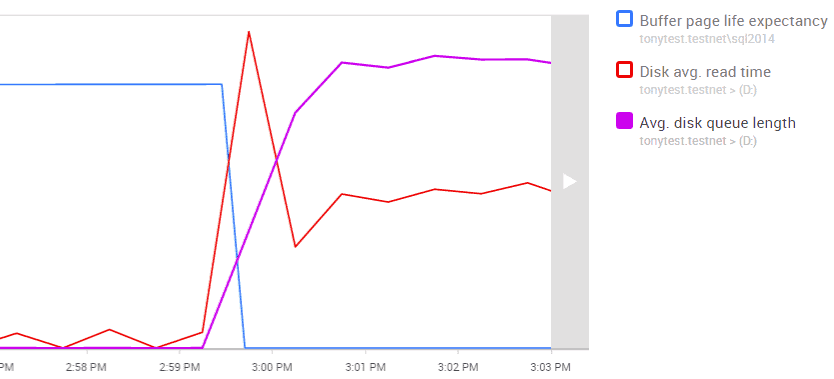
Abbildung 7 - Diagramm in Redgate Monitor: durchschnittliche Länge der Festplatten-Warteschlange, Lesezeit & Seitenlebensdauer
Vielleicht liegt die Ursache also gar nicht beim Platten-Subsystem, sondern schlicht an einem zu kleinen Buffer Pool oder ineffizienten Queries, die ständig Seiten nachladen, die nicht im Cache liegen?
Zusätzlich zeigt Redgate Monitor die wichtigsten Waits im gewählten Zeitraum - darunter die bereits erwähnten `PAGEIOLATCH_SH`- und `ASYNC_NETWORK_IO`-Waits.
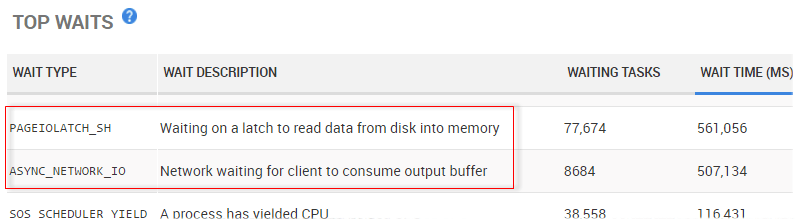
Abbildung 8 - Redgate Monitors Top-Waits-Liste mit `PAGEIOLATCH_SH` und `ASYNC_NETWORK_IO`
Klicken wir auf einen Wait Type, zeigt uns Redgate Monitor sofort die relevanten Queries dazu. Mit den manuellen Methoden, die wir weiter oben im Artikel besprochen haben, ist es oft mühsam und manchmal sogar Rätselraten herauszufinden, welche Query für welche Waits verantwortlich ist. Redgate Monitor nimmt uns diese Detektivarbeit ab: Wir können direkt in einen Wait Type hineinschauen und sehen sofort, welche Queries die Hauptursache sind. Praktisch ist auch, dass die Statistiken hier unabhängig von Server-Neustarts oder manuellen Resets bestehen bleiben - die typische Einschränkung „seit dem letzten Zurücksetzen“ fällt also weg.
In Abbildung 9 sehen wir eine Query, die für `PAGEIOLATCH`-Wartezeiten in der Datenbank `SQLMonTest` sorgt.
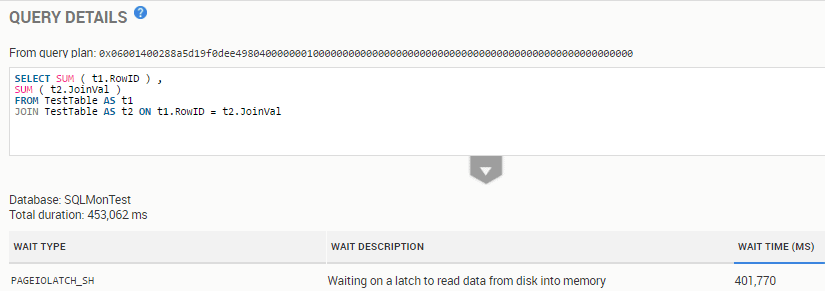
Abbildung 9 - Eine ineffiziente Query, die `PAGEIOLATCH_SH`-Wartezeiten verursacht
Wir können uns auch die Top-Queries pro Datenbank anschauen - inklusive Query-Text, Plan Handles und den jeweiligen Wartezeiten.
Werfen wir einen Blick auf den Ausführungsplan der Query in Abbildung 9: Wir finden dort ungefilterte Joins, große Table Scans und teure Join-Operationen.
Eine gute Strategie entsteht erst, wenn wir alle Performance-Daten im Zusammenhang betrachten. In diesem Beispiel ist klar: Wir sollten zuerst an der Query-Optimierung und an der Indexstrategie arbeiten. Ohne `WHERE`-Filter zwingt die Query SQL Server zu kompletten Table Joins. Das führt zu unnötig vielen Seitenlesungen und sorgt für ständiges Hin- und Herschieben im Cache. Am Ende muss SQL Server Pufferseiten auslagern, um Platz für neue zu schaffen - und genau das erzeugt den „Festplatten-Engpass“: Sessions warten darauf, dass Seiten von der Festplatte geladen werden, um ein Latch im Buffer Cache zu bekommen.
Für weitere Informationen über Redgate Monitor, eine Demo oder Best Practices nehmen Sie gern Kontakt mit uns auf.

Seit mehr als 25 Jahren entwickelt Redgate spezialisierte Software für Datenbanken. 92 % der Fortune-100-Unternehmen setzen auf unsere Lösungen. Insgesamt vertrauen uns über 200.000 Kunden weltweit.

Redgate bietet eine umfassende Dokumentation und ein kompetentes, engagiertes Support-Team. Im Schnitt bewerten 87 % unserer Kundinnen und Kunden unseren Support mit „Ausgezeichnet“.




