Greg Low in SQL Server What’s missing in T-SQL? My wish list of features that developers actually need in SQL Server A veteran SQL Server expert's wish list for T-SQL: true constants, enumerations, extensibility, better naming consistency, and more. See what's... 08 July 2026 12 min read 11
Edward Pollack in SQL Server 5 T-SQL features that should already exist (2026 SQL Server wish list) 2026 T-SQL wish list covering native Parquet imports, arrays, OVERLAPS, simpler licensing, and cloud storage — features SQL Server still... 26 June 2026 14 min read 31
Lukas Vileikis in Career Why you should still become SQL-certified in 2026 (and how to achieve it) Is SQL certification still worth it in 2026? Learn how it boosts credibility, career opportunities, and helps you stay competitive... 18 June 2026 10 min read 2
Edward Pollack in T-SQL Programming Demystifying PIVOT and UNPIVOT in T-SQL Learn how to use T-SQL PIVOT and UNPIVOT operators with clear examples — from basic row-to-column transforms to dynamic SQL... 20 May 2026 12 min read 4
Lukas Vileikis in Databases Why COALESCE might be the most useful SQL function you’re not using right Learn how the SQL COALESCE function works, with practical examples for handling NULL values, setting defaults, and writing cleaner, more... 07 May 2026 7 min read 31
Ben Johnston in SQL Server SQL Server Regular Expression Performance and Guidelines SQL Server 2025 introduces regular expression (regex) functions to the TSQL language. You could do this in previous versions with... 02 January 2026 15 min read 111
Joe Celko in Theory and design State Transition Constraints in SQL: Temporal Rules & Validation Implement state transition constraints in SQL Server using FOREIGN KEY references, temporal attributes, CTE path validation, and stored procedure wrappers.... 24 June 2025 14 min read 32
Louis Davidson in T-SQL Programming DISTINCT and UNION: What happens when you use them together? When I was perusing my LinkedIn feed the other day, I came across this thread about using SELECT *. In... 26 May 2025 11 min read 4
Dennes Torres in T-SQL Programming Azure SQL Native JSON Data Type: Query Techniques Explore Azure SQL's native JSON data type with CHECK constraints, JSON_ARRAYAGG, JSON_OBJECTAGG, and JSON_OBJECT functions. These features are coming to... 07 May 2025 16 min read 2
Matt Gantz in T-SQL Programming Purging Data from a Large Table in SQL Server Purging data from a table is a common database maintenance task to prevent it from growing too large or to... 01 May 2025 8 min read 421
Louis Davidson in T-SQL Programming SQL Server CHOOSE Function: Syntax, Examples & Limits Learn how to use the SQL Server CHOOSE function to select values by position. Covers syntax, practical ETL examples, random... 21 April 2025 40 min read 11
Louis Davidson in T-SQL Programming Crazy number of Parameters… and a challenge The other day, my lovable coworker and frequent Simple Talk writer: Grant Fritchey, sent this post on X: So I... 24 February 2025 35 min read 1
Rodrigo Ribeiro Gomes in T-SQL Programming SQL Server 2025 Embeddings: AI Vector Search Explained Understand embeddings and vector search in SQL Server 2025. Learn how to convert text to numerical vectors, calculate similarity with... 18 February 2025 48 min read 1252
Edward Pollack in T-SQL Programming Exploring Scalar Solutions to Complex Data Math There are many functions and tools available to database professionals that can solve data math challenges, regardless of complexity. A... 12 February 2025 17 min read 11
Louis Davidson in T-SQL Programming SQL Server BIT_COUNT and an Alternative I was editing an article the other day that uses the BIT_COUNT function that was added to SQL Server 2022.... 08 February 2025 11 min read 3
Aaron Bertrand in T-SQL Programming Five SQL Server changes I’d love to see (DROP_EXISTING, ALTER TABLE, STRING_SPLIT fixes) Aaron Bertrand on five SQL Server behaviours he'd like Microsoft to fix: DROP_EXISTING needing an existing index, ALTER TABLE DROP... 01 January 2025 5 min read 65
Edward Pollack in T-SQL Programming Store & Parse JSON in SQL Server: Strategy Guide Learn how to store, validate, index, and compress JSON in SQL Server. Covers ISJSON, OPENJSON, JSON_VALUE, computed columns, the Azure... 23 August 2024 27 min read 311
Aaron Bertrand in SQL Server Storing Weekday Sets in SQL Server Using Bitwise Flags: Schedules and Recurring Jobs Store and query sets of weekdays in SQL Server using bitwise flags - each day encoded as a power of... 02 August 2024 7 min read 1
Aaron Bertrand in T-SQL Programming Index cleanup : Harder than it looks I’m not the first person to write about cleaning up unused or redundant indexes. You can read many articles about... 22 July 2024 7 min read
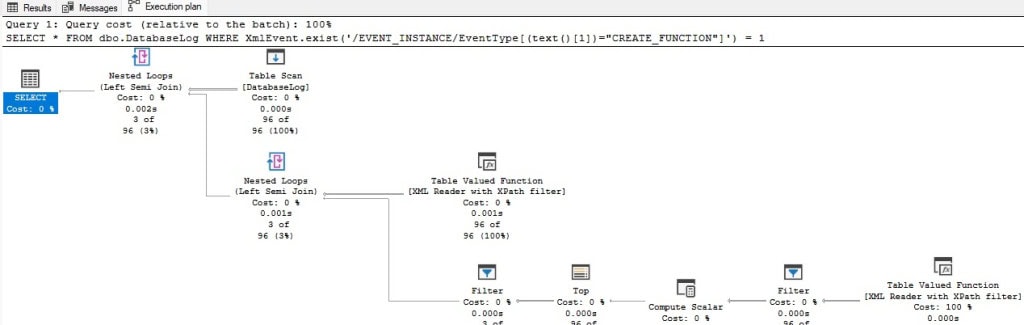
Edward Pollack in T-SQL Programming XML Performance Tuning and Added Options SQL Server provides a variety of ways to tune XML so that it provides consistent performance, consumes less space, all... 21 June 2024 12 min read
 3
3 1
1 1
1