
I recently had a restore job where I needed to split the work up into multiple parallel processes (which I’ll refer to here as “threads”). I wanted to balance the work so that the duration was something significantly less than the sum of the restore times.
Imagine a job that loops through and restores each database in sequence (let’s start with just four):

The restores are not finished (allowing the next step(s) to start) until the sum of the restore times for all four databases.
Instead of one job, imagine four jobs that all start at roughly the same time, each restoring one of those four databases (assuming the server can handle the extra work):

With this strategy, all of the restores are finished by the time it takes the longest restore to finish, instead of the sum of all four restore times. This allows subsequent tasks to start a lot sooner, and frees up the server for other work.
Well, duh
This concept is not overly clever or imaginative on my part – this has been the premise of parallel computing since computing was a thing and, more generally, division of labor has been a strategy throughout recorded history.
That said, the above was a simplistic example.
In reality, we have a lot more databases, in a periodic job where we restore a slew of backups on an internal server (and then perform further processing once they’re all finished). Since this is a supporting server and not production-facing, it is configured to restore and support all of the production databases, with no other workload, so it has generous headroom for additional work. While I didn’t want to overwhelm the server, I wanted the entire set of restores to happen faster in parallel than serially. But how could I split the work up? Alphabetical? Random? Those might lead to quite skewed work – all the biggest databases could be alphabetically together or just randomly placed on the same thread.
Borrowing from sports
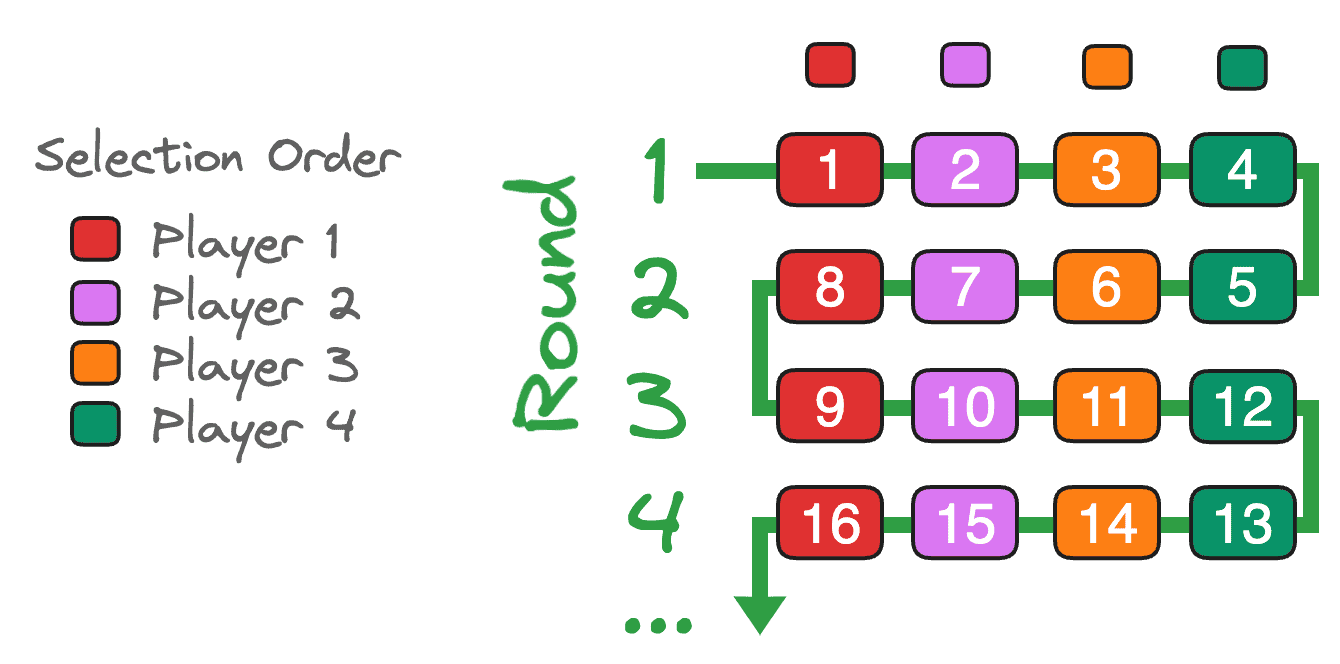
I play fantasy football. To start each season, there is a draft, where players are randomly assigned draft order. We’ve started some seasons with a “snake” draft, to make the selection of players most fair and balanced. A snake draft works like this (a simple example with four players):
- First pick in the first round picks last in the second round.
- Second pick in the first round picks third in the second round.
- Third pick in the first round picks second in the second round.
- Last pick in the first round picks first in the second round.
- Then, in the third round, it reverts to the original order: The first pick from the first round picks first again (giving them two picks back-to-back).
For that reason, it’s called a “snake.” To illustrate:
This is also slightly reminiscent of playoff brackets or draws in tennis, where the first round starts with the lowest seed playing the highest, the second lowest playing the second highest, and so on.
I borrowed from this technique to split up my restore jobs to make the “amount of work” most equitable. I based this by simply ranking by size of the source data files, but you could also use compressed backup size, historical backup times, random distribution (ORDER BY NEWID()), or even segment alphabetically (say, if you didn’t want the Aaron database to always finish first, or the Zorro database to always finish last). You might also think about whether there is, say, one database that is disproportionately larger or more resource-intensive than all the others, and manually put that database on a thread all its own.
Again, I didn’t want to overwhelm the server, perhaps causing all the parallel work to slow things down and defeat the purpose. I landed on 4 “threads,” knowing that I might be able to increase that after testing, but I also conceded that it would probably be impossible to get the distribution so perfect that all 4 threads finished at exactly the same time. Maybe something for machine learning to figure out down the road?
Meanwhile, I thought, “I can rank databases by total data size descending, and put the biggest file on thread 1, the second biggest on thread 2, the third on thread 3, and the fourth on thread 4. Then, the 5th would go on thread 4, the 6th on thread 3, the 7th on thread 2, and the 8th on thread 1. Then start the cycle over.” This way, I could spread the work most fairly across the four threads, like my snake draft example above.
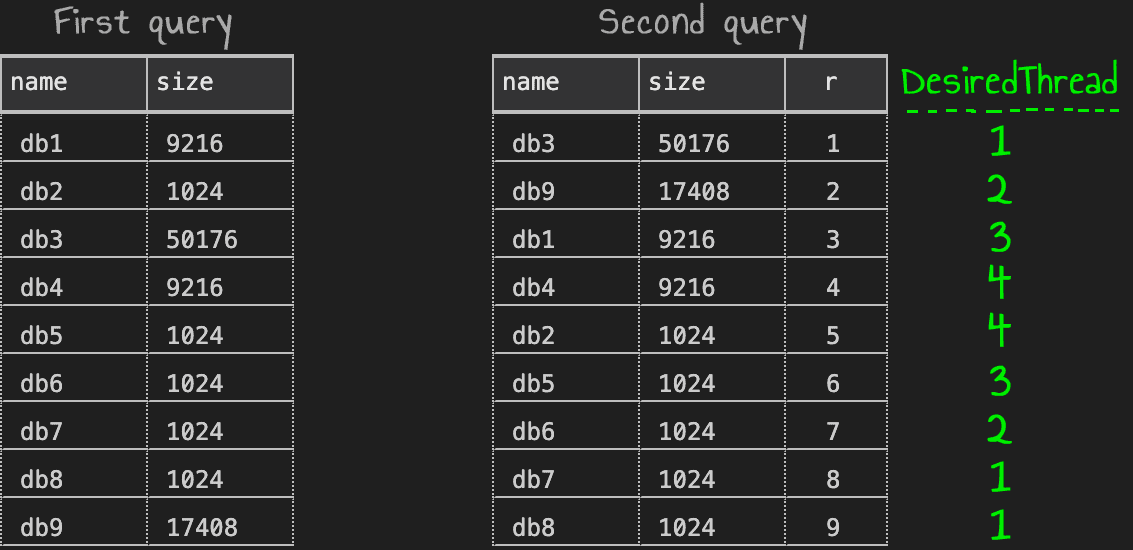
But I sure didn’t want to rank those databases by hand – or even name them, since there are nearly 400. So, I created my original list from sys.databases on the source server. On my test server, there are 9 databases, with some ties.
|
1 2 3 4 5 6 7 8 9 |
SELECT d.name, size = SUM(size) FROM sys.master_files AS f INNER JOIN sys.databases AS d ON f.database_id = d.database_id WHERE f.type_desc <> N'LOG' AND d.database_id > 4 GROUP BY d.name; |
Then I added the row number so I know the exact ordering by size descending:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT d.name, size = SUM(size), r = ROW_NUMBER() OVER (ORDER BY SUM(size) DESC, d.name) FROM sys.master_files AS f INNER JOIN sys.databases AS d ON f.database_id = d.database_id WHERE f.type_desc <> N'LOG' AND d.database_id > 4 GROUP BY d.name; |
I worked on this on my local instance. On the left, the results from the first query; on the right, the second query, showing the added row number (and scribbled with the desired thread I wanted for each row):
Next, to make further queries simpler, I created a view in my Utility database on the source system (and added a clause to exclude self):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE VIEW dbo.DatabasesBySize AS SELECT d.name, size = SUM(size), RowNum = ROW_NUMBER() OVER (ORDER BY SUM(size) DESC, d.name) FROM sys.master_files AS f INNER JOIN sys.databases AS d ON f.database_id = d.database_id WHERE f.type_desc <> N'LOG' AND d.database_id > 4 AND d.name <> DB_NAME() GROUP BY d.name; |
To get the desired outcome, we have to think of each group of 4 (or whatever ThreadCount you want) as independent. Within each group, depending on whether the group is odd or even, we can order within that group either descending (for odd) or ascending (for even). Visually:

This certainly sounds like a problem that window functions can solve. First, let’s take advantage of SQL Server’s integer division to assign groups of 4:
|
1 2 3 4 5 6 7 |
DECLARE @ThreadCount tinyint = 4; SELECT name, size, r = RowNum, GroupNo = RowNum/@ThreadCount FROM dbo.DatabasesBySize; |
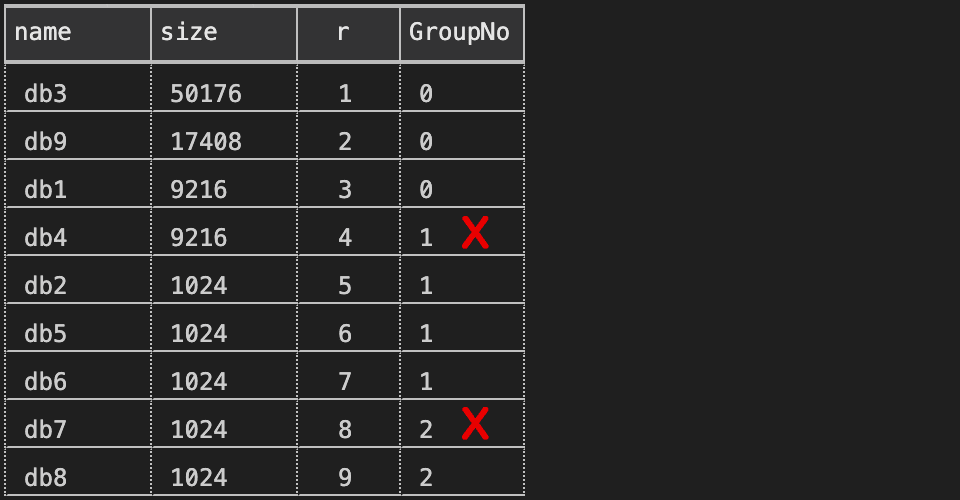
This produces an off-by-one error, though, because 1/4 = 0, 2/4 = 0, 3/4 = 0, and 4/4 = 1:
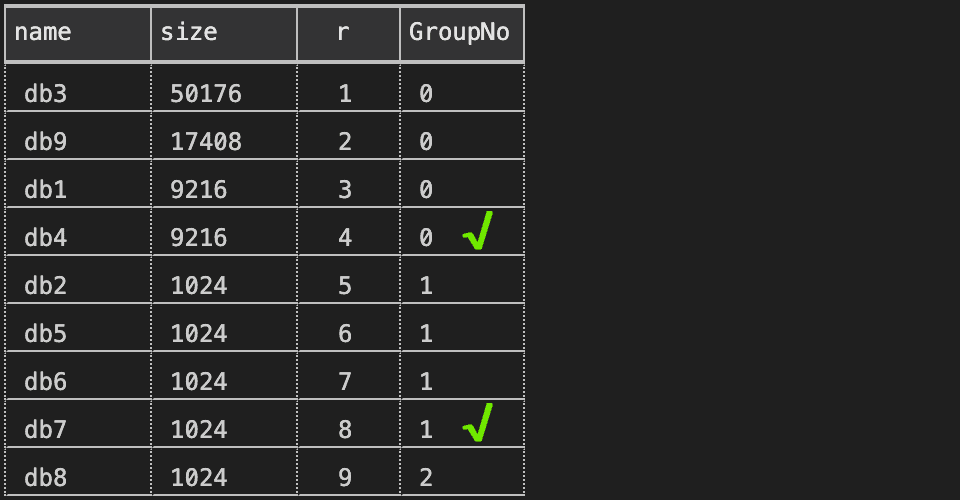
Thankfully, this is easy to fix. To get the first row in the first group, and the fourth row into the second group, we can just subtract one from the row number to force nicer alignment:
|
1 2 3 4 5 6 7 8 |
DECLARE @ThreadCount tinyint = 4; SELECT name, size, r = RowNum, GroupNo = (RowNum-1)/@ThreadCount -----------------^^^^^^^^^^ FROM dbo.DatabasesBySize; |
Results:
The trickier bit is to flip the order between descending and ascending within each group. Since we are limited to two options, we could make a decision on ORDER BY depending on whether the GroupNo is odd or even:
|
1 2 3 4 5 6 7 8 |
DECLARE @ThreadCount tinyint = 4; SELECT name, size, r = RowNum, GroupNo = (RowNum-1)/@ThreadCount, Odd = (RowNum-1)/@ThreadCount % 2 FROM dbo.DatabasesBySize; |
Results:
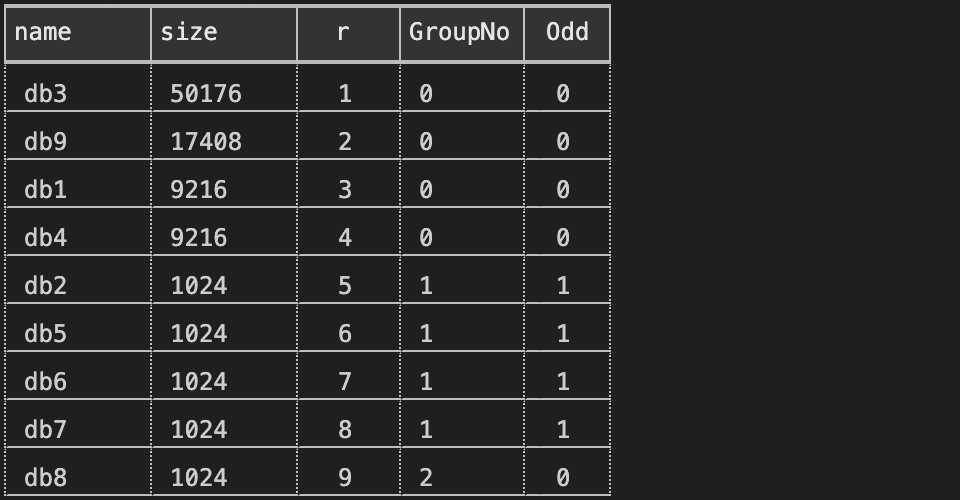
With that information, I can use a RANK(), partitioned by GroupNo, ordered by either the row number (RowNum) if the GroupNo is even, or the row number descending (-RowNum) if the GroupNo is odd (with name as a deterministic tie-breaker):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DECLARE @ThreadCount tinyint = 4; SELECT name, size, r = RowNum, GroupNo, Odd, GroupRank = RANK() OVER ( PARTITION BY GroupNo ORDER BY CASE Odd WHEN 1 THEN -RowNum ELSE RowNum END, name ) FROM ( SELECT name, size, RowNum, GroupNo = (RowNum-1)/@ThreadCount, Odd = (RowNum-1)/@ThreadCount % 2 FROM dbo.DatabasesBySize ) AS sq ORDER BY r; |
And we get the output we want:
![]()
You can also change the thread count; here is the result with a thread count of 3:
![]()
This general technique may sound similar to other solutions: companies like Amazon use a packing algorithm to minimize wasted space in a shipment, to reduce size and cost. Though, in my experience, it does not always work very well when your shipment has a small number of items, since they will often arrive in a comically oversized box. You might also remember playing Tetris, or may have even taken a break from playing Tetris to read this post.
Summary
In this post, I’ve shown how you can divide your heavy processing tasks up into relatively equal units of work. Stay tuned for my next post, where I’ll demonstrate a few ways to use this information.
FAQs: Snake draft sorting in SQL Server, part 1
1. What is snake draft sorting in SQL Server?
Snake draft sorting assigns rows or tasks to processing groups in a serpentine order – first group gets row 1, second gets row 2, and so on down the list, then the order reverses: the last group gets the next row, working back up. This ensures each group receives a balanced mix of early-listed and late-listed items rather than clustering all ‘top’ items into the first group. The name comes from fantasy sports drafts where picks alternate direction each round.
2. When should I use snake draft sorting in SQL Server?
Use snake draft sorting when you have a list of tasks ranked by some cost or weight – index rebuilds ranked by fragmentation, tables ranked by row count, jobs ranked by runtime – and you need to distribute them across multiple workers, maintenance windows, or parallel execution slots such that no single slot gets an overwhelming concentration of heavy work. It is a simple, effective alternative to random distribution when the cost ordering of tasks is known.
3. How do I implement snake draft distribution in T-SQL?
Assign a row number to each task ordered by cost descending. Then use modular arithmetic to determine which group each row belongs to: group = (row_number – 1) % number_of_groups. Reverse the within-group ordering for even-numbered rounds by using a CASE expression or by inverting the sort within each group assignment. The result is a table where each group contains a balanced distribution of high-cost, medium-cost, and low-cost tasks.
4. What is the difference between snake draft and round-robin distribution in SQL Server?
Round-robin distribution assigns tasks in strict rotation: task 1 → group 1, task 2 → group 2, etc. If tasks are sorted by cost, this gives group 1 all the most expensive tasks (positions 1, n+1, 2n+1…). Snake draft reverses direction each round, so the most expensive task goes to group 1 in round 1, but the most expensive remaining task in round 2 goes to the last group. This significantly improves balance when task costs are skewed.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments