
In my previous post, I showed how to borrow a snake draft concept from fantasy football, or a packing technique from the shipping industry, to distribute different portions of a workload to run in parallel. In the previous example, we determined a distribution order for databases based on size – though you can rank by literally any attribute (or combination of attributes). Once we’ve determined how to build out this order, we may want to store that data somewhere because, sometimes, the source of that data is not directly accessible. Using the database and view from part 1:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE dbo.DatabaseThreads ( ThreadID tinyint NOT NULL, DatabaseName sysname, RowNum int, CONSTRAINT UQ_DatabaseName UNIQUE(DatabaseName), CONSTRAINT PK_DatabaseThreads PRIMARY KEY(ThreadID, RowNum) ); |
Now, we need to bring the data over. In my case, I was able to use a linked server; if you’re on the same instance, just remove [SourceServer].:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DECLARE @ThreadCount tinyint = 4; INSERT dbo.DatabaseThreads ( DatabaseName, RowNum, ThreadID ) SELECT name, RowNum, RANK() OVER ( PARTITION BY GroupNo ORDER BY CASE Odd WHEN 1 THEN -RowNum ELSE RowNum END, name ) FROM ( SELECT name, size, RowNum, GroupNo = (RowNum-1)/@ThreadCount, Odd = (RowNum-1)/@ThreadCount % 2 FROM [SourceServer].Utility.dbo.DatabasesBySize ) AS sq; |
You may have to move the data in more creative ways if the servers are not adjacent.
Note that if you have a stable set of databases that don’t grow abnormally, you might not need to change this list very often. But if the list (or growth) is more volatile, you can create a job that re-populates the table from the source system at whatever frequency makes sense.
Next, you can create a procedure that simply returns the list of databases based on the requested ThreadID (or all), in either order, for consumers to process:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE PROCEDURE dbo.DatabaseThreads_List @ThreadID int = NULL, /* NULL means return all */ @Order varchar(4) = 'ASC' /* or 'DESC' */ AS BEGIN SET NOCOUNT ON; SELECT ThreadID, RowNum, DatabaseName FROM dbo.DatabaseThreads WHERE ThreadID = COALESCE(@ThreadID, ThreadID) ORDER BY CASE @Order WHEN 'ASC' THEN RowNum END, RowNum DESC; END |
This can be handy if you have PowerShell jobs, for example, that need to perform some operation on each database, and you want each job to handle only one of the threads.
When calling the procedure, you might have to think about it a little bit backwards. Since RowNum is based on largest size first, if you want smallest first, you want to apply DESC to RowNum. Some sample calls:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT query = 'all threads, largest first'; EXEC dbo.DatabaseThreads_List; SELECT query = 'just thread 1, largest first'; EXEC dbo.DatabaseThreads_List @ThreadID = 1, @Order = 'ASC'; SELECT query = 'just thread 1, smallest first'; EXEC dbo.DatabaseThreads_List @ThreadID = 1, @Order = 'DESC'; SELECT query = 'just thread 2, largest first'; EXEC dbo.DatabaseThreads_List @ThreadID = 2; |
Results:
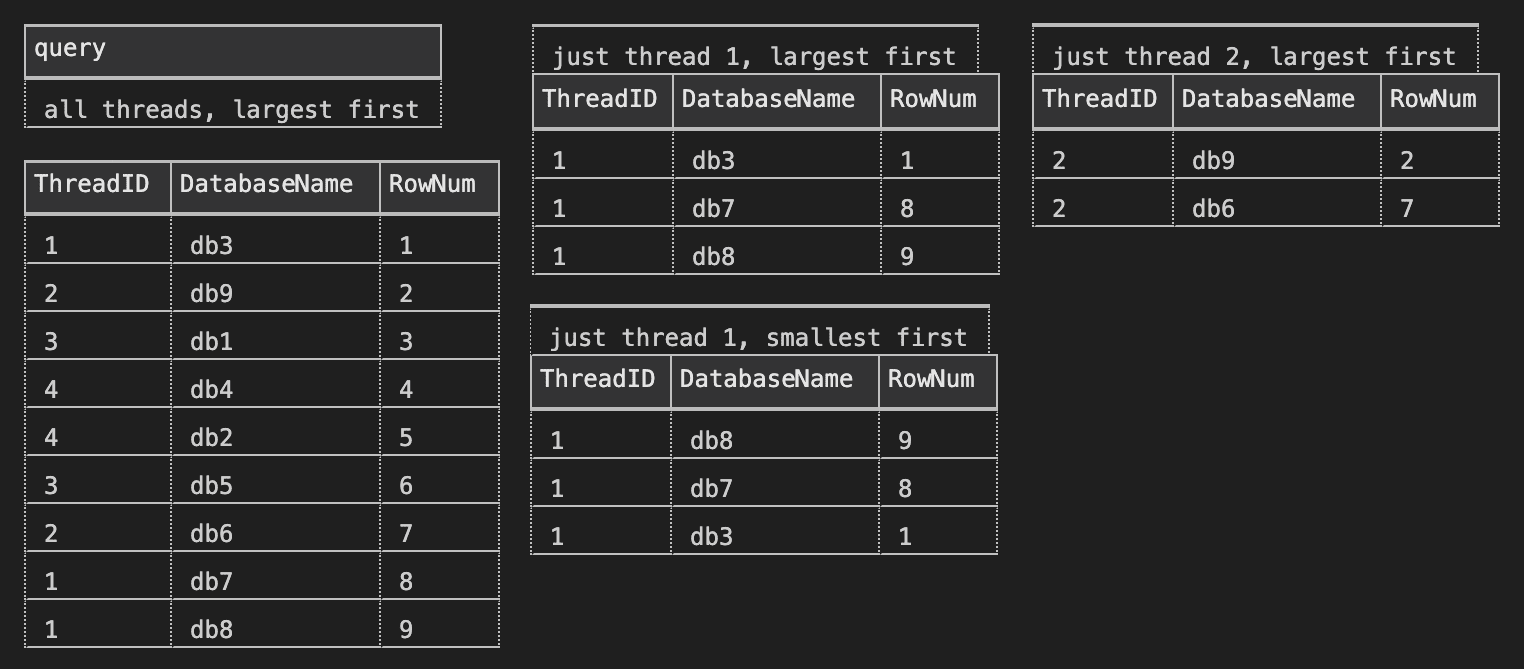
For my scenario, I wanted to start with the biggest databases first, in each thread, in the first round – if I am troubleshooting this thing late at night, especially if the issue is space-related, I want to get to the one most likely to cause a failure before waiting for 399 other databases to succeed. You might want to do the reverse; if your biggest database is the one that’s most likely to be problematic, you may want to put off dealing with it until morning, after all the rest succeed. You could even change it up a bit where you process the smallest <@ThreadCount> databases in the first round, as a sanity check, then – once you’re sure the process itself works – move on to the biggest and then go down.
Procedures called from jobs
One thing I can do with this is create a procedure to do my bidding against all of the databases in a given thread. For example, if I have a procedure called RestoreTestDatabase that takes a parameter @DatabaseName, I can use a cursor to loop through the databases in that thread only, and call that procedure for each one:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE PROCEDURE dbo.RestoreTestDatabases_ByThread @ThreadID tinyint AS BEGIN SET NOCOUNT ON; DECLARE @db nvarchar(128), @c cursor; SET @c = CURSOR FORWARD_ONLY STATIC READ_ONLY FOR SELECT DatabaseName FROM dbo.DatabaseThreads WHERE ThreadID = @ThreadID ORDER BY RowNum; OPEN @c; FETCH NEXT FROM @c INTO @db; WHILE @@FETCH_STATUS <> -1 BEGIN EXEC dbo.RestoreTestDatabase @DatabaseName = @db; FETCH NEXT FROM @c INTO @db; END END |
Then create four separate jobs, all specifying their own specific thread:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/* job 1 */ EXEC dbo.RestoreTestDatabases_ByThread @ThreadID = 1; /* job 2 */ EXEC dbo.RestoreTestDatabases_ByThread @ThreadID = 2; /* job 3 */ EXEC dbo.RestoreTestDatabases_ByThread @ThreadID = 3; /* job 4 */ EXEC dbo.RestoreTestDatabases_ByThread @ThreadID = 4; |
If I ever find that this overwhelms the system, I can return to something more like the previous behavior by staggering start times, combining the steps into a single job, or chaining them by making the last step of job 1 call sp_start_job for job 2, and so on. I can also reduce the impact by half by combining jobs 1 & 2 into a single job, and jobs 3 & 4 into a different job. The one thing I don’t want to do is try to estimate the buffer I’d need between jobs so they never overlap – I’ll either be wrong one way, and they will overlap; or, wrong the other way, and have precious time wasted in between jobs.
Another use case
I also used this technique for some work that had to be done outside of the database – think all kinds of RegEx, writing to files, zipping, and so on. I wrote these tasks in PowerShell, and was able to use threads to have four scripts running simultaneously, each processing their own chunk of databases. The concept is similar to the above, except I stuff the databases and other attributes into a DataTable, and iterate through that:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# PowerShell $ThreadID = 1; # or 2, or 3, or 4 $connString = "< nice try >"; $conn = New-Object System.Data.SqlClient.SqlConnection($connString); $conn.Open(); $cmd = $conn.CreateCommand(); $cmd.CommandType = [System.Data.CommandType]::StoredProcedure; $cmd.CommandText = "dbo.DatabaseThreads_List"; $p1 = New-Object System.Data.SqlClient.Sqlparameter("@ThreadID", $ThreadID); $cmd.Parameters.Add($p1) | Out-Null; $DBs = New-Object System.Data.DataTable; $da = New-Object System.Data.SqlClient.SqlDataAdapter($cmd); $da.Fill($DBs) | Out-Null; foreach ($db in $DBs) { Write-Host "Processing $($db["DatabaseName"])."; <# fun processing here for each database ... #> } |
(I actually wrote a proper module and passed some of these parameters in, but simplified for this example. I also am not a PowerShell expert, I just use it occasionally to get stuff done. I haven’t worked out how to migrate to Microsoft.Data.SqlClient in this environment, and still use some syntax conventions I remember from Classic ASP. Please don’t judge. 😊)
How did it work?
Well, in both cases, so far, so good. The serial process I described first used to took over 9 hours; the first few times under the new strategy, the slowest job finished in under 4 hours, without excessive strain on the system. Similarly, the PowerShell processing that used to handle one database at a time, now finished in less than half the time when spread across four scripts.
This shows, though, that you can’t always expect that <current runtime> will become <current runtime> / @ThreadCount – your economies of scale won’t always be linear.
My next experiments will be increasing threads to 8. I could also do some further math to make manual adjustments to the snake draft based on average historical restore times, to balance the duration a little better, since we don’t strictly need each thread to have the same number of databases. For now, I’m pretty happy to cut 5 hours off of every run, a reduction of more than 50%.
Up next
In the next installment in this series, I’ll talk about how I added more granularity to deal with disproportionate skew (basically, one database that grows 10X faster than all the others). After that, I’ll describe a simple method to handle coordination of all of these asynchronous processes.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments