
SQL Server provides a native XML data type with built-in support for XQuery, OPENXML, XML indexes, and schema validation. Store XML in XML-typed columns (not VARCHAR) to get type checking, XML-specific indexing, and native XQuery support. Parse XML values using the .value(), .query(), .nodes(), and .modify() methods, or use OPENXML for rowset-based shredding.
Convert between XML and string types with CAST(xml_column AS NVARCHAR(MAX)) or CAST(string_column AS XML). For performance, create primary and secondary XML indexes on columns that are frequently queried. This guide covers the full lifecycle of XML in SQL Server – from storage and parsing to indexing, validation, and conversion.
Introduction
XML is a common storage format for data, metadata, parameters, or other semi-structured data. Because of this, it often finds its way into SQL Server databases and needs to be managed alongside other data types.
Even though a relational database is not the optimal place to store and manage XML data, it is often needed due to application requirements, convenience, or a need to maintain this information in close proximity to other app data.
This article dives into a variety of common XML challenges and the functionality included in SQL Server to help make managing them as simple as possible.
Store XML as XML. Store non-XML as non-XML.
XML will enter our data lives in one of two ways:
- Data stored in an XML-typed column.
- Data stored in some other format.
Before diving into managing XML, it is important to note that not all XML requires a data engineer to know advanced (or any) knowledge about how to index, filter, update, or use XML.
Sometimes, XML is stored in a database for convenience and is simply written or read by the application directly. In these scenarios, there is little architectural work involved aside from the need to have an XML-typed column available to store the data.
In many ways, this is an ideal situation. The purpose of a database is to store and retrieve data, and not needing to index, filter, or shred XML allows a database to do what it is best at while not introducing complexity into database or application code to manage it. If XML is stored in SQL Server, it will often need to be directly queried, even if filtering, aggregating, or other more advanced functionality is not needed.
If possible, store XML data in an XML typed column. Developers sometimes choose to store XML in string columns instead, such as VARCHAR(MAX). While strings are more familiar to us and easier to work with, they do not provide the many XML-related benefits that an XML-typed column does. Oftentimes, when XML functionality is later needed against a string column, the result is the awkward need to convert from VARCHAR to XML and then back again, as needed. This is inefficient and creates additional opportunities for mistakes to occur as data is being frequently converted, in addition to written, read, filtered, etc…
Similarly: do not store data as XML unless needed. Data or metadata that will be routinely consumed by SQL Server ideally should be stored in a format that is quick and easy to read/write. Whether in a configuration table, metadata table, temporal table, or some other convenient data structure, consider the ideal candidate for storing data before finalizing the decision.
Data types are database design decisions that have long lives ahead of them. Choosing the wrong data type for an important data element can result in poor performance, wasted time and effort, and technical debt that remains for years to come. Therefore, be sure to store XML in XML-typed columns and non-XML in non-XML data types.
Parsing XML
The most common need with XML is to read it, either in its entirety or by pulling out specific details from a document. For the demos in this article, the dbo.DatabaseLog table will be used, which can be found in the AdventureWorksDW database. (You can download a backup to restore here from the Microsoft site. I am using the 2022 version of the database.)
This table contains logs of SQL commands used to create or modify database objects. For example, the following query retrieves a single row from the table:
|
1 2 3 4 |
SELECT * FROM dbo.DatabaseLog WHERE DatabaseLog.PostTime = '2017-10-27 14:36:32.110'; |
The results show a column called XmlEvent:

The simplest way to read data from an XML column is by using an XQuery against it. In the following example, several elements are returned, each as a separate column:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT DatabaseLog.XMLEvent.value('(EVENT_INSTANCE/EventType)[1]', 'VARCHAR(MAX)') AS EventType, DatabaseLog.XMLEvent.value('(EVENT_INSTANCE/ServerName)[1]', 'VARCHAR(MAX)') AS ServerName, DatabaseLog.XMLEvent.value('(EVENT_INSTANCE/LoginName)[1]', 'VARCHAR(MAX)') AS LoginName, DatabaseLog.XMLEvent.value ('(EVENT_INSTANCE/TSQLCommand/CommandText)[1]' , 'VARCHAR(MAX)') AS SetOptions FROM dbo.DatabaseLog WHERE DatabaseLog.PostTime = '2017-10-27 14:36:32.110'; |
Each column specifically retrieves the first element for the various tags provided. The results look like this:

The data type provided alongside the tag detail is the data type that the result will be returned as. Using VARCHAR(MAX) is overkill for EventType, ServerName, and LoginName, as these columns will not exceed 128 characters. It is a fairly typical process to start with a large datatype as you are interrogating the data in XML. Moving forward in this article, data types will be chosen that are more fitting for the data elements provided.
This syntax is perfect when you know exactly what data elements are needed, what they are called, and where to find them. This is an easy way to parse XML when it is served to you nicely on a platter. If only life were always so easy!
OPENXML may also be used to parse an XML document. This is ideally used on a scalar variable or XML that is read into a single variable/parameter. An extra step is needed to prepare the XML document, which converts it into a format that SQL Server can easily consume:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @XMLDoc INT; DECLARE @XMLEvent XML = ' <EVENT_INSTANCE> <EventType>ALTER_TABLE</EventType> <PostTime>2017-10-27T14:36:32.113</PostTime> <SPID>62</SPID> <ServerName>BARBKESS24\MSSQL2017RTM</ServerName> <LoginName>REDMOND\barbkess</LoginName> <UserName>dbo</UserName> <DatabaseName>AdventureWorksDW2017</DatabaseName> <SchemaName>dbo</SchemaName> <ObjectName>DimPromotion</ObjectName> <ObjectType>TABLE</ObjectType> <AlterTableActionList> <Create> <Constraints> <Name>PK_DimPromotion_PromotionKey</Name> </Constraints> </Create> </AlterTableActionList> <TSQLCommand> <SetOptions ANSI_NULLS="ON" ANSI_NULL_DEFAULT="ON" ANSI_PADDING="ON" QUOTED_IDENTIFIER="ON" ENCRYPTED="FALSE" /> <CommandText>ALTER TABLE [dbo].[DimPromotion] WITH CHECK ADD CONSTRAINT [PK_DimPromotion_PromotionKey] PRIMARY KEY CLUSTERED ( [PromotionKey] ) ON [PRIMARY]</CommandText> </TSQLCommand> </EVENT_INSTANCE> '; EXEC sys.sp_xml_preparedocument @XMLDoc OUTPUT, @XMLEvent; |
The script above takes the same XML from the previous example, stores it in a scalar XML variable, and then converts it using sp_xml_preparedocument, placing the result into @XMLDoc. (Note that as this is a variable, you will need to execute the following SELECT statement in the same batch of code for it to execute.)
From here, there are a handful of options available. The first allows for specific elements to be retrieved from the XML document, like this:
|
1 2 3 4 5 6 7 |
SELECT * FROM OPENXML (@XMLDoc, '/EVENT_INSTANCE', 2) WITH (EventType VARCHAR(50), ServerName VARCHAR(128), LoginName VARCHAR(128), TSQLCommand VARCHAR(MAX)); |
This syntax will explicitly return the same four elements that were previously parsed out of the XML document. The second parameter (2) indicates that the XML is element centric. If an XML document is attribute-centric, then set this to 1.
Ensure that data types are correct, or an error will be returned. For example, if EventType were declared as an INT, then the following error would be thrown.
Msg 245, Level 16, State 1, Line 61
Conversion failed when converting the nvarchar value 'ALTER_TABLE' to data type int.
If there is a need to return everything from an XML document, then consider the following syntax, instead:
|
1 2 3 4 5 |
SELECT * FROM OPENXML (@XMLDoc, '/EVENT_INSTANCE'); -- No value for XML flag: All elements returned --in an edge table. |
The result will be a hierarchical table that looks like this:
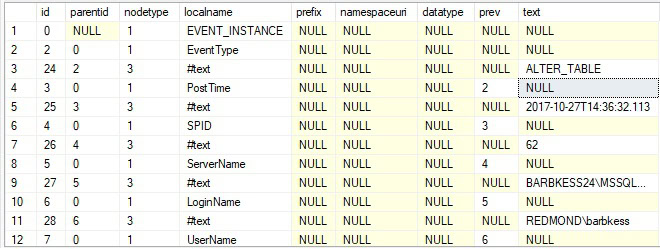
Note that while the column headers will the same no matter what sort of XML document is parsed, the content of the rows will vary greatly. There are many ways to use this data, such as:
- Return all details for a given attribute.
- Search for specific values.
- Validate the existence (or lack thereof) for an attribute or value.
Because XML documents can be large, be sure that you are prepared for the size of the output. If testing, a TOP or COUNT(*) may be used with the SELECT statement that returns the table. This can help with understanding the size of the output before diving into it.
The results use a pairing of id and parentid to create a hierarchy to understand each level of XML within the document. Nodetype indicates the type of XML node that the row references, which can be one of three values:
- Element node
- Attribute node
- Text node
localname is the tag name. If it references an XML text value, then it will contain the string, “#text”.
The column prev indicates the id of the previous element tag. If that element contains many levels of detail, then there can be a long gap of NULLs between each value in this column.
Finally, the column text contains the element text detail, if applicable. It will be NULL for XML metadata and contain values for XML data.
If XML document manipulation is a part of a larger script\batch, then it is a best practice to remove the document when it is no longer needed. This can be accomplished with sys.sp_xml_removedocument, like this:
|
1 |
EXEC sys.sp_xml_removedocument @XMLDoc; |
Creating XML
Sometimes there is a need to create XML documents for use elsewhere in SQL Server, or by an application. There are a variety of ways to do this, which will be outlined here.
The simplest way to generate XML quickly is by using FOR XML AUTO. This mindless syntax can convert the contents of a SQL query into XML. One nice aspect of this syntax is that the query can include any of the standard T-SQL syntax, such as WHERE, GROUP BY, and ORDER BY, for example. The following query generates XML that converts the contents of four columns in dbo.DatabaseLog into elements within an XML document.
|
1 2 3 4 5 6 7 8 9 |
SELECT DatabaseLogID, PostTime, [Schema], [Object] FROM dbo.DatabaseLog WHERE PostTime >= '10/27/2017 14:36:34.000' ORDER BY PostTime ASC FOR XML AUTO; |
Here is the XML output:

Note that table name is included as the tag for each set of attributes and the attribute names are simply the column name. Each row is its own addition to the XML file, as it is attribute centric.
Element-centric XML may be generated by adding ELEMENTS to the FOR XML AUTO clause:
|
1 2 3 4 5 6 7 8 9 |
SELECT DatabaseLogID, PostTime, [Schema], [Object] FROM dbo.DatabaseLog WHERE PostTime >= '10/27/2017 14:36:34.000' ORDER BY PostTime ASC FOR XML AUTO, ELEMENTS; |
This addition to the query greatly changes the shape of the XML output. The following is a sample of how it looks:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<dbo.DatabaseLog> <DatabaseLogID>89</DatabaseLogID> <PostTime>2017-10-27T14:36:34.113</PostTime> <Schema>dbo</Schema> <Object>FactResellerSales</Object> </dbo.DatabaseLog> <dbo.DatabaseLog> <DatabaseLogID>90</DatabaseLogID> <PostTime>2017-10-27T14:36:34.120</PostTime> <Schema>dbo</Schema> <Object>FactSalesQuota</Object> </dbo.DatabaseLog> |
In this scenario, each row has been converted into its own element. Within each element are the detailed gleaned from the columns that were selected in the query. The choice to use attribute-centric or element-centric XML will depend on the application or process that is consuming the document.
There is no need to accept the table name as the root node name. This can be easily adjusted like this:
|
1 2 3 4 5 6 7 8 9 |
SELECT DatabaseLogID, PostTime, [Schema], [Object] FROM dbo.DatabaseLog WHERE PostTime >= '10/27/2017 14:36:34.000' ORDER BY PostTime ASC FOR XML PATH ('Log'); |
In this example, the root node will be named “Log” instead of “dbo.DatabaseLog”. Here is a sample of the output:
|
1 2 3 4 5 6 |
<Log> <DatabaseLogID>89</DatabaseLogID> <PostTime>2017-10-27T14:36:34.113</PostTime> <Schema>dbo</Schema> <Object>FactResellerSales</Object> </Log> |
Since the XML is being generated directly from the query output, columns may be renamed, converted to other data types, or formatted as part of the query. Basically, any of the usual tactics that may be used to adjust how column output looks can be used here as well.
If XML column values are included in the creation of an XML document, they will be added and nested accordingly. For example, the following query includes the column XmlEvent, which itself contains XML data:
|
1 2 3 4 5 6 7 |
SELECT DatabaseLogID, XmlEvent FROM dbo.DatabaseLog WHERE PostTime >= '10/27/2017 14:36:34.000' ORDER BY PostTime ASC FOR XML AUTO; |
The output will include nested attributes based on the contents of each XmlEvent value, like this partial output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<dbo.DatabaseLog DatabaseLogID="89"> <XmlEvent> <EVENT_INSTANCE> <EventType>ALTER_TABLE</EventType> <PostTime>2017-10-27T14:36:34.113</PostTime> <SPID>62</SPID> <ServerName>BARBKESS24\MSSQL2017RTM</ServerName> <LoginName>REDMOND\barbkess</LoginName> <UserName>dbo</UserName> <DatabaseName>AdventureWorksDW2017</DatabaseName> <SchemaName>dbo</SchemaName> <ObjectName>FactResellerSales</ObjectName> <ObjectType>TABLE</ObjectType> <AlterTableActionList> <Create> <Constraints> <Name>FK_FactResellerSales_DimCurrency</Name> |
This can be a handy way to combine XML and non-XML data quickly and easily, if needed.
One final way to create XML data in SQL Server is somewhat obvious, but often overlooked, and is to do so directly:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
UPDATE DatabaseLog SET XmlEvent = ' <EVENT_INSTANCE> <EventType>ALTER_TABLE</EventType> <PostTime>2017-10-27T14:36:34.120</PostTime> <SPID>62</SPID> <ServerName>BARBKESS24\MSSQL2017RTM</ServerName> <LoginName>REDMOND\barbkess</LoginName> <UserName>dbo</UserName> <DatabaseName>AdventureWorksDW2017</DatabaseName> <SchemaName>dbo</SchemaName> <ObjectName>FactSalesQuota</ObjectName> <ObjectType>TABLE</ObjectType> <AlterTableActionList> <Create> <Constraints> <Name>FK_FactSalesQuota_DimEmployee</Name> <Name>FK_FactSalesQuota_DimDate</Name> </Constraints> </Create> </AlterTableActionList> <TSQLCommand> <SetOptions ANSI_NULLS="ON" ANSI_NULL_DEFAULT="ON" ANSI_PADDING="ON" QUOTED_IDENTIFIER="ON" ENCRYPTED="FALSE" /> <CommandText>ALTER TABLE [dbo].[FactSalesQuota] ADD CONSTRAINT [FK_FactSalesQuota_DimEmployee] FOREIGN KEY([EmployeeKey]) REFERENCES [dbo].[DimEmployee] ([EmployeeKey]), CONSTRAINT [FK_FactSalesQuota_DimDate] FOREIGN KEY([DateKey]) REFERENCES [dbo].[DimDate] ([DateKey])</CommandText> </TSQLCommand> </EVENT_INSTANCE>' FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
If XML data already exists outside of a table, variable, or parameter, its value can be updated in the same way as if it were any other SQL Server data type.
Updating XML
There are a variety of ways to update XML using standard XML methods. The following are a handful of ways to make inline changes to XML using the XQuery method modify(), without the need to rewrite the entire document.
modify() may be used to insert, delete, and update values within an XML document. This is very much a scalpel that can meticulously adjust XML values without creating change throughout an entire document.
Note that SQL Server expects values to be modified inline as part of the syntax. An attempt to update XML like this will result in an error message:
|
1 2 3 4 |
UPDATE DatabaseLog SET XmlEvent = XmlEvent.modify('insert <color>Orange</color> after (/EVENT_INSTANCE/EventType)[1]') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
This will throw a confusing error:
Msg 8137, Level 16, State 1, Line 168Incorrect use of the XML data type method 'modify'. A non-mutator method is expected in this context.
Could that be any more confusing?! If attempts to use modify() are failing with an error like this, be sure to check the syntax being used and verify it is exactly as demonstrated. Once working, it is easy enough to adjust, but getting it right the first time can be a bit awkward.
It is a bit counter-intuitive to what we are used to, but when updating XML with an UPDATE…SET statement, there is no equals operator. Simply use SET with the column and modify to get the desired results.
Consider the following XML sample:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @XMLSample XML = ' <Log> <DatabaseLogID>89</DatabaseLogID> <PostTime>2017-10-27T14:36:34.113</PostTime> <Schema>dbo</Schema> <Object>FactResellerSales</Object> </Log> <Log> <DatabaseLogID>90</DatabaseLogID> <PostTime>2017-10-27T14:36:34.120</PostTime> <Schema>dbo</Schema> <Object>FactSalesQuota</Object> </Log>'; |
What if there was a need to add a username to only the second log entry? This can be done using modify() and the insert…into… syntax:
|
1 2 |
SET @XMLSample.modify('insert <username>EdPollack</username> into (/Log)[2]'); SELECT @XMLSample; |
This query will add the username attribute to the end of the Log tag. Specifying [2] tells the query to insert the tag (username) and its associated value (EdPollack) to only the second Log entry in the XML document. The result is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<Log> <DatabaseLogID>89</DatabaseLogID> <PostTime>2017-10-27T14:36:34.113</PostTime> <Schema>dbo</Schema> <Object>FactResellerSales</Object> </Log> <Log> <DatabaseLogID>90</DatabaseLogID> <PostTime>2017-10-27T14:36:34.120</PostTime> <Schema>dbo</Schema> <Object>FactSalesQuota</Object> <username>EdPollack</username> </Log> |
If the numeric index provided does not correspond to a value in the XML document, the query will still succeed without an error, but no changes will be made. This can be handy when there is a need to conditionally add a tag, but only if a list is of a certain length.
A variable or parameter may also be passed into modify(), using a slightly different syntax:
|
1 2 |
DECLARE @UserName VARCHAR(100) = 'EdPollack'; SET @XMLSample.modify('insert <username>{sql:variable("@UserName")}</username> into (/Log)[2]'); |
Instead of providing an explicit value, the variable @UserName is used instead. This allows parameters and other scalar data to be added to an XML document without the need for dynamic SQL or some other messier solution. The result for this query is identical to the previous example.
This syntax may also be used as part of an UPDATE statement against a table, allowing one or many values to be updated in a single batch. Note that the query does not have an equals operator in it:
|
1 2 3 4 |
UPDATE DatabaseLog SET XmlEvent.modify('insert <color>Orange</color> after (/EVENT_INSTANCE/EventType)[1]') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
This example used after instead of into, allowing the query to add the new element directly after the first instance of EventType within EVENT_INSTANCE. The results look like this:
|
1 2 3 4 5 |
<EVENT_INSTANCE> <EventType>ALTER_TABLE</EventType> <color>Orange</color> <PostTime>2017-10-27T14:36:34.120</PostTime> <SPID>62</SPID> |
Conditionals may be embedded into a modify() call, allowing for changes to be made based on column data or variable values. An example of this would be to check if the color “Orange” from the prior example is in the XML document in the expected location. Based on that condition, different values could be inserted. Alternatively, a change could be made under one condition, but not another.
The following example checks to see if the color “Orange” is found in EVENT_INSTANCE. If so, then create a new element with the flavor “spicy”, otherwise add the flavor “sweet”:
|
1 2 3 4 5 6 7 8 |
UPDATE DatabaseLog SET XmlEvent.modify('insert if (/EVENT_INSTANCE/color = "Orange") then element flavor {"spicy"} else element flavor {"sweet"} as first into (/EVENT_INSTANCE)[1]') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
I intentionally used some silly examples here as they are very easy to spot in the resulting XML. The results look like this:
|
1 2 3 4 5 6 |
<EVENT_INSTANCE> <flavor>spicy</flavor> <EventType>ALTER_TABLE</EventType> <color>Orange</color> <PostTime>2017-10-27T14:36:34.120</PostTime> <SPID>62</SPID> |
Note that the text used within the conditional statement is case-sensitive by default and does not follow the object collation that is defined within a database. Even if the database collation is case insensitive, the conditional text will validate an exact match, including case.
Note that if you execute this multiple times, you will get multiple flavor tags in the XML.
Values can be updated within XML using modify() in a similar fashion by using the replace option. This example changes the color from its previous value to “Purple”:
|
1 2 3 4 |
UPDATE DatabaseLog SET XmlEvent.modify('replace value of (/EVENT_INSTANCE/color/text())[1] with "Purple"') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
In the event that there are multiple elements with the same name, an index may be added to specify which to update:
|
1 2 3 4 |
UPDATE DatabaseLog SET XmlEvent.modify('replace value of (/EVENT_INSTANCE/color[1]/text())[1] with "Purple"') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
Since only a single element exists for color in this example, the results of both queries are the same.
modify() can delete from XML documents, as well. The following queries show how the data previously added to XmlEvent can be carefully removed.
|
1 2 3 4 5 6 7 8 |
UPDATE DatabaseLog SET XmlEvent.modify('delete /EVENT_INSTANCE/flavor') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; UPDATE DatabaseLog SET XmlEvent.modify('delete /EVENT_INSTANCE/color') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
The first UPDATE statement deletes the element “flavor” and the second query removes the element “color” from the XML document. Once executed, the resulting XML looks like it did before any changes had been made to it in this article:
|
1 2 3 4 5 6 |
<EVENT_INSTANCE> <EventType>ALTER_TABLE</EventType> <PostTime>2017-10-27T14:36:34.120</PostTime> <SPID>62</SPID> <ServerName>BARBKESS24\MSSQL2017RTM</ServerName> <LoginName>REDMOND\barbkess</LoginName> |
If needed, an entire hierarchy of XML elements can be deleted at one time. For example, if the TSQL commands stored in these XML documents were rarely used and were consuming significant space, then they could be deleted using modify(). This script removes TSQLCommand for one specific row:
|
1 2 3 4 |
UPDATE DatabaseLog SET XmlEvent.modify('delete /EVENT_INSTANCE/TSQLCommand/*') FROM dbo.DatabaseLog WHERE DatabaseLogID = 90; |
Removing the WHERE clause would allow this deletion to occur for all XmlEvent XML documents in the table, if needed.
The XQuery method modify() has quite a bit of functionality associated with. Full details for how it can be used in SQL Server can be found here:
modify() Method (xml Data Type) – SQL Server | Microsoft Learn
That article has subsections for various use-cases and method parameters/details.
Conclusion
In part one of this series on XML in SQL Server, we covered the basics of how to parse and query XML, as well as how to modify the data in the XML data.
XML is a bit of a double-edged sword in SQL Server. On the one hand, XML is a commonly used tool for storing and moving data between applications. It is an easy-to-use open standard that has an extensive amount of functionality built-in for querying and updating it. SQL Server provides many ways to read and write XML data, as well as optimizations to improve search speeds and reduce its storage footprint.
On the other edge, despite its convenience, XML is not a relational data format and is not naturally compatible with a transactional database engine such as SQL Server. While storing and retrieving XML is not computationally expensive, searching and updating XML can be slow, arduous processes. The ideal use of XML in SQL Server is as a pass-through to allow data to be written, stored, and retrieved when needed by an application.
If filtering or heavy data manipulation is needed, consider normalizing commonly used XML elements into table columns, allowing for SQL Server to do what SQL Server is best at: managing transactional data. Alternatively, if XML can be stored outside of a transactional database, then doing so may be beneficial.
Fast, reliable and consistent SQL Server development…
FAQs: How to store and parse XML in SQL Server
1. How do you convert XML to a string in SQL Server?
Use CAST or CONVERT to transform an XML-typed value to a string: SELECT CAST(XmlColumn AS NVARCHAR(MAX)) FROM YourTable. For the reverse (string to XML), use CAST(StringColumn AS XML). Note that CAST to NVARCHAR(MAX) preserves the full XML content, while NVARCHAR(4000) may truncate large documents. You can also use the .value() method with a specific XPath to extract individual text values directly.
2. What is the fastest way to parse XML in SQL Server?
For querying individual values from XML, the .value() XQuery method is generally fastest. For shredding XML into rows, the .nodes() method outperforms OPENXML for most use cases. OPENXML with sp_xml_preparedocument is better suited for very large documents processed once. For repeated queries against the same XML column, create a primary XML index followed by secondary indexes (PATH, VALUE, or PROPERTY) matching your query patterns. Avoid repeated CAST operations between XML and string types.
3. Should you store XML in an XML column or VARCHAR in SQL Server?
Always prefer the native XML data type over VARCHAR. XML-typed columns provide automatic validation (ensuring only well-formed XML is stored), support for XQuery methods (.value, .query, .nodes, .modify), XML-specific indexing, and schema collection binding. Storing XML as VARCHAR loses all these benefits and forces frequent CAST operations. The only exception is when XML content will never be queried by SQL Server and is purely written/read by the application.
4. For JSON handling in SQL Server, what are the equivalent approaches?
SQL Server stores JSON in NVARCHAR columns (or the native JSON type in Azure SQL). The equivalents are: OPENJSON (like OPENXML), JSON_VALUE (like .value()), JSON_QUERY (like .query()), JSON_MODIFY (like .modify()), and FOR JSON (like FOR XML). For a detailed guide, see the companion article on storing and parsing JSON in SQL Server.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments