
This is part 3 of a four-part series on snake-draft (serpentine) sorting to balance parallel work in SQL Server. Parts 1-2 established the technique at the database level: when running parallel jobs against many uneven databases, sort by size descending and assign to workers in a serpentine pattern (1→2→3→3→2→1→1→2→3…) to get markedly better load balance than round-robin.
Part 3 extends the technique down one level – balancing work across 7 unevenly-sized tables within a single database. The same serpentine logic applies, but the work-unit granularity changes from ‘database’ to ‘table’, and the worker coordination layer becomes more relevant (parts 1-2 could assume each worker owned its database exclusively; part 3 has workers operating against shared-database tables).
The article walks through the adjustment, measures the runtime reduction on a real workload, and sets up part 4’s thread-completion coordination problem.
In part 2 of this series, I showed an example implementation of distributing a long-running workload in parallel, in order to finish faster. In reality, though, this involves more than just restoring databases. And I have significant skew to deal with: one database that is many times larger than all the rest and has a higher growth rate. So, even though I had spread out my 9-hour job with 400 databases to run faster by having four threads with 100 databases each, one of the threads still took 5 hours, while the others all finished within 1.5 hours.
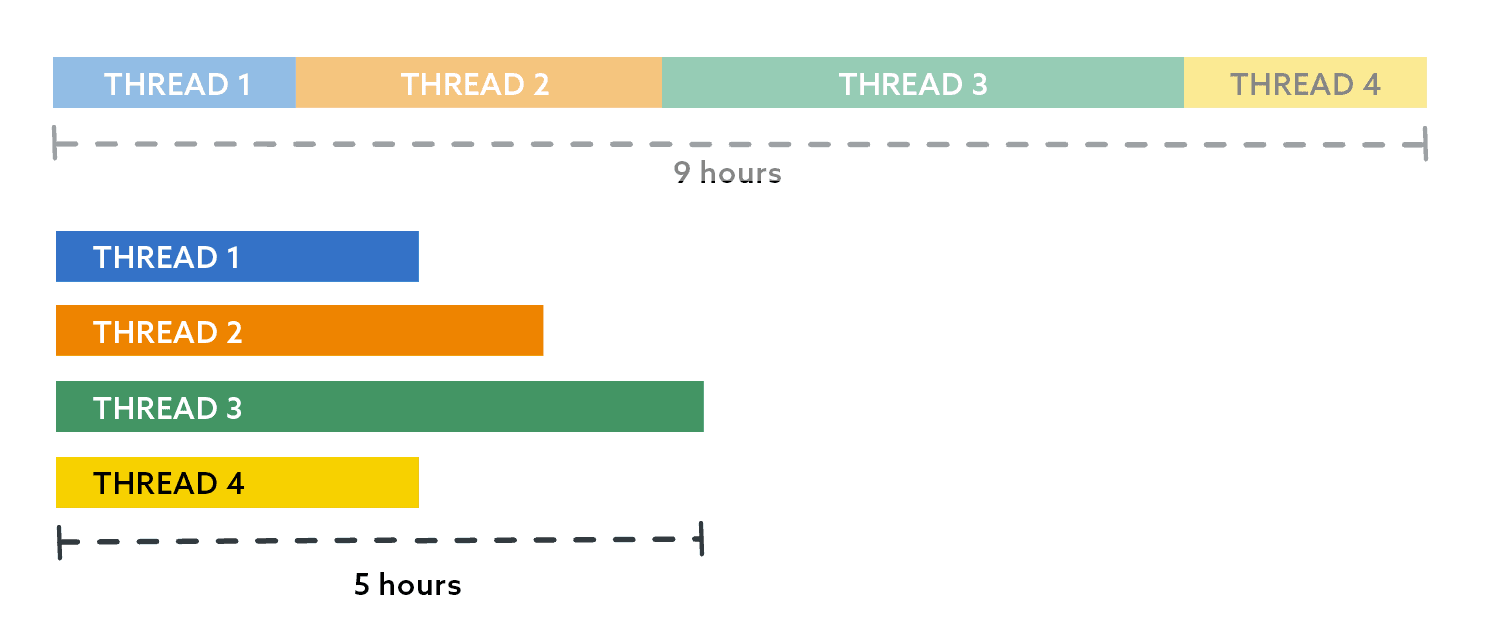
If we put little slices in there to represent the databases in each thread, it looks something like this:
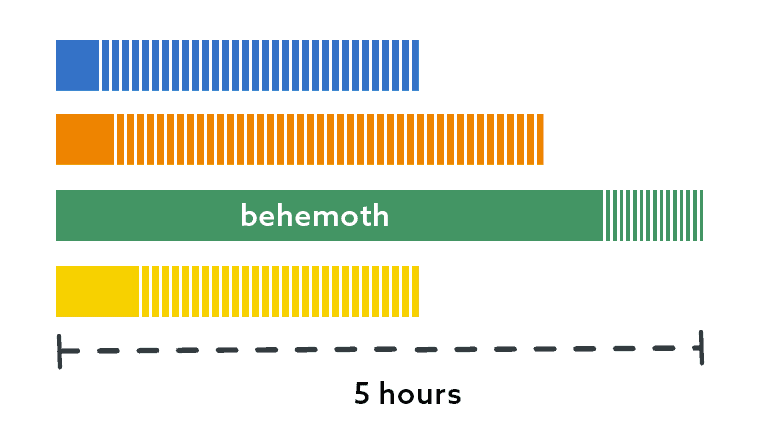
(Note: None of these graphs are precise.)
I did what I suggested previously: I put this behemoth on its own thread. I simply ran my script again with a ThreadCount of 3, without the behemoth database, and just assigned it thread 4 manually.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @ThreadCount tinyint = 3; SELECT name, size, r = RowNum, GroupNo, Odd, ThreadID = RANK() OVER ( PARTITION BY GroupNo ORDER BY CASE Odd WHEN 1 THEN -RowNum ELSE RowNum END, name ) FROM ( SELECT name, size, RowNum, GroupNo = (RowNum-1)/@ThreadCount, Odd = (RowNum-1)/@ThreadCount % 2 FROM dbo.DatabasesBySize WHERE name <> N'Behemoth' ) AS sq ORDER BY r; |
This made the other three threads absorb the databases that used to be in thread 4, which made them take a little bit longer, but this made the collective finish times a little more balanced. Now we were down to 4 hours for the biggest database:
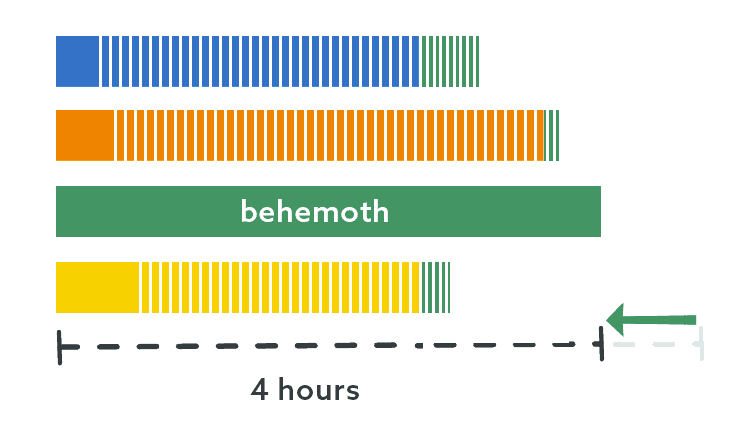
But I want more
The underlying task here processes data from 7 different tables. Like the databases, these tables aren’t evenly distributed, and this is most prominently the case in the behemoth database. It is the fastest growing table and many times larger than the others. When I analyzed the runtime for these processes, the thread this database was on still spent a majority of its time processing this one table, while the other tables had to wait:
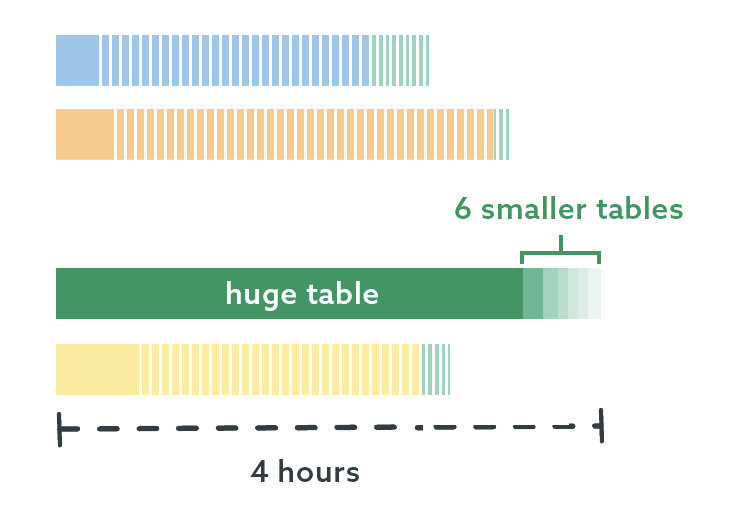
I determined that I could further parallelize the work by putting this one table on its own thread, and the other 6 tables could be processed in the meantime. And we’re down to a small enough number of objects that I no longer have to do this through code – I know which table is largest and I know the names of the other 6 tables. I don’t even have to use my toes! I made two sub-threads here, one with the biggest table, and one with the rest:
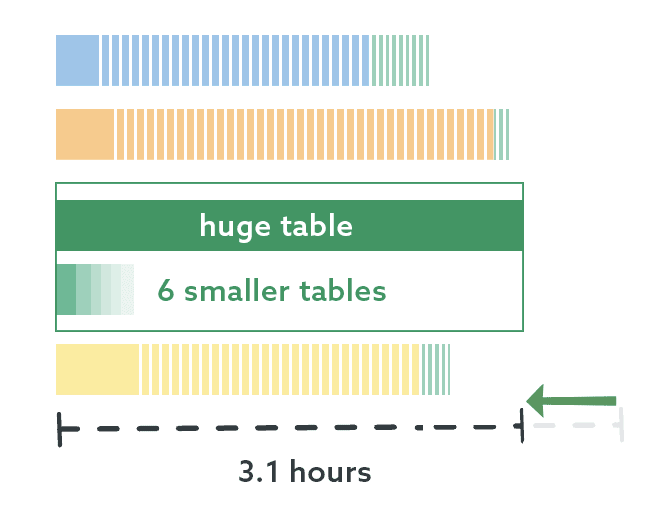
This is great progress! We’ve taken a job that used to take 9 hours and shrunk it down to just over 3 hours, with mostly negligible performance impact on the server (aside from slightly elevated CPU).
But I still want more
The work in this database is still unevenly distributed, and I knew that I could reduce the runtime even further by parallelizing this table on its own, using pagination. If I can have 4 threads processing this one table simultaneously then, at least in theory, I should be able to have an even bigger impact on runtime.
The table currently has about 161 million relatively wide rows, and a primary key on a column called ElephantID. I used the system metadata to tell me how to distribute those rows across 4 threads, but I also only wanted any one thread to process 250,000 rows at a time. This query told me everything I needed to know:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
DECLARE @TableName sysname = N'dbo.Elephant', @ThreadCount int = 4, @RowsPerPage int = 250000; ;WITH threads AS ( SELECT ThreadID = value FROM GENERATE_SERIES(1, @ThreadCount) ) SELECT [RowCount], PageCount, RowsPerThread, ThreadID, [FirstRow] = RowsPerThread * (ThreadID - 1) + 1, [LastRow] = RowsPerThread * ThreadID, FirstPage = ((ThreadID-1) * [PageCount] / @ThreadCount) + 1, LastPage = ((ThreadID) * [PageCount] / @ThreadCount) FROM threads CROSS JOIN ( SELECT [Rowcount], RowsPerThread = [Rowcount] / @ThreadCount, [PageCount] = [Rowcount] / @RowsPerPage FROM ( SELECT [Rowcount] = SUM([rows]) FROM sys.partitions WHERE [object_id] = OBJECT_ID(@TableName) AND index_id = 1 ) AS rowcounts ) AS breakdown; |
Output:

The jobs or scripts would run that query and pull the information only for their thread, calling the following procedure in a loop for each page in their bucket:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE PROCEDURE dbo.PagingTheElephant @PageNumber int, @PageSize int AS BEGIN SET NOCOUNT ON; ;WITH ThisPage AS ( SELECT ElephantId FROM dbo.Elephant ORDER BY Id OFFSET @PageSize*(@PageNumber-1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT e.ElephantId /* , e.OtherCols */ FROM dbo.Elephant AS e INNER JOIN ThisPage AS tp ON tp.ElephantId = e.ElephantID ORDER BY e.ElephantId; END |
Now we’re really getting somewhere! With four threads processing chunks of that table together, I cut the execution time almost in half:
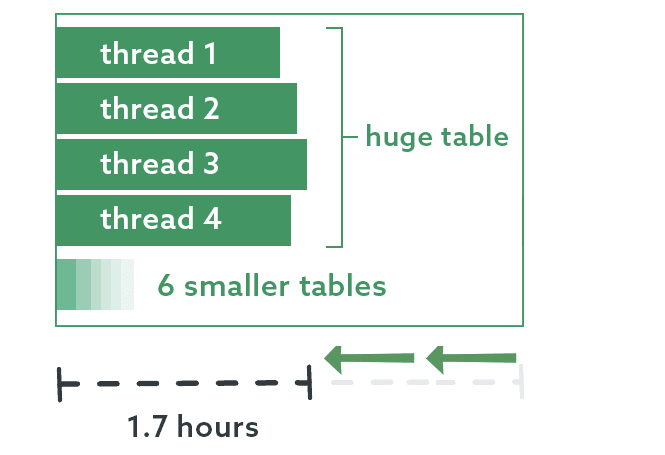
As I mentioned before, I could experiment with adding even more threads to process some of these simultaneously, and possibly bring the runtime down even further. For now, though, I am extremely happy with these improvements.
Next time
In my next post – my last in this series, I promise – I’ll show how I coordinate all of the threads finishing with starting the next task, avoiding conflicts or unnecessary delays.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments