

Embeddings in SQL Server 2025 let you convert text, images, or other data into numerical vectors that capture semantic meaning – enabling similarity search, recommendation engines, and AI-powered classification directly in your database. Instead of keyword matching, you can find conceptually similar records by calculating the distance between vectors using functions like cosine similarity.
SQL Server 2025 introduces native support for storing and querying these vectors, eliminating the need for a separate vector database. This guide walks through the concept of embeddings from scratch, shows how to generate them, and demonstrates vector similarity queries in T-SQL.
One of the cornerstones of AI is a concept called embeddings. Virtually every AI model, whether for text, video, or audio, uses something related to embeddings. Starting with SQL Server 2025, this is a term you’ll be hearing a lot, as its potential for applications is enormous!
In this post, I want to offer a more didactic explanation of embeddings, especially for those who haven’t had the opportunity to explore the world of AI or machine learning. My hope is that by the end of this post, you’ll finally understand what embeddings are and see the possibilities for use with SQL Server (or any other database with support).

The goal of this post is to move beyond this simple table to this script!
Starting without SQL and without AI
Let’s start with a simple exercise, and for now, we won’t involve AI or SQL. The goal is for you to understand the idea behind the concepts and operations involving embeddings.
Imagine a car… Now, a bus. In your mind, you probably identified standard elements and characteristics of these two words. You imagined some geometric shape, textures, internal and external elements, etc. A series of unique properties you’ve learned throughout your life that define these two concepts.
And both have common characteristics, but in different quantities. For example, you may have imagined a car as a small rectangular geometric shape, and a bus also as a rectangular geometric shape, but larger. And, most likely, when imagining one of these two concepts, you made little or no association with masculine or feminine, which would be very different if I asked you to imagine a queen, for example.
Notice that with each word or phrase we learn, we make some kind of association with other concepts, even unconsciously. That is, we learn to identify characteristics and how much of that characteristic is present.
To use this on a computer, we need a way to transform these relationships into numbers. Let’s try a very simple approach: we’ll take the phrases above and put each one on a line in a table. Then, we’ll map these two characteristics: Vehicle (indicates whether the phrase refers to a vehicle), Person (indicates whether it refers to a person)
|
Text |
Vehicle |
Person |
|
A car |
1 |
0 |
|
A bus |
1 |
0 |
|
A queen |
0 |
1 |
Congratulations! These are your first embeddings.
- For cars and bus, I put 1 in the Vehicle column because they are vehicles and 0 for people because they are not people. Simple as that.
- For the queen phrase, the opposite: 0 for vehicle, because it’s not a vehicle, and 1 for person, because a queen is a person.
Maybe you have a more elaborate criterion than mine. But, for now, I want to keep things simple, and that’s why I limited myself to identifying as 1 or 0. It’s already enough for our first objective: we managed to represent a phrase in numbers, even if few and simple numbers, but there it is.
Vectors
We can represent this table in a “more mathematical” way: using vectors (or, if you prefer, call them arrays). Each characteristic we have mapped (vehicle and person) is a position in our vector. We name each position a “dimension.” That is, if we have 2 characteristics, then, for each phrase, we need a 2-dimensional vector:
- A car = [1,0]
- A bus = [1,0]
- A queen = [0,1]
If there were 10 characteristics, there would be 10 dimensions, and so on… These are the embeddings: the vectors that represent each word, phrase, etc. Up to this point, we haven’t used any AI… Just a little human reasoning and mathematics! Let’s continue a little further, still without AI…

Comparing Vectors
Now, how can we compare this? This is where a mathematical concept comes in: Cosine Similarity. In other posts, we can go into detail about why this calculation helps to compare, but just understand that this operation can tell us how much two vectors are the same or not: you pass two vectors and it returns a value between 0 and 1.
The closer to 0 the comparison returns, the closer the compared vectors are. that is, equal, and the closer to 1, the further apart they are, that is, different. Besides this, there are other algorithms that also compare vectors (such as Euclidean distance), but for now, let’s only use cosine.

Again: I’m keeping things simple here, okay? If you’re a PhD in AI or mathematics, don’t get mad at me.
SQL Server joins the group…
So far, you’ve learned the main concepts: We have embeddings (which are these vectors that represent each phrase; it’s common to use the term “vectors” or “embeddings”—they refer to the same thing, okay?!), and we have a calculation to compare them. And this is where SQL Server and its new support for all this comes in!
Since I don’t yet have access to SQL Server 2025, I set up an Azure SQL Database, which already has minimal vector support and is sufficient to explain what I need. When 2025 is publicly released, we’ll do new tests there. So, here’s a very simple script that you can run on any Azure SQL Database:
|
1 2 3 4 5 6 7 8 |
DECLARE @car vector(2) = '[1,0]' ,@bus vector(2) = '[1,0]' ,@queen vector(2) = '[0,1]' SELECT [Car vs Bus] = VECTOR_DISTANCE('cosine',@car,@bus) ,[Car Vs Queen] = VECTOR_DISTANCE('cosine',@car,@queen) ,[Bus Vs Queen] = VECTOR_DISTANCE('cosine',@bus,@queen) |
The query creates a variable for each of our phrases, with the new vector type. This is the data type that Microsoft created to represent these arrays. The value passed in parentheses is the number of dimensions, which in our case is 2. I initialized each variable with its respective vector, according to our previous table. I could have created a table with a varchar column and a vector column, but I chose to use variables directly in the script to keep the code simpler.
Then, right after, we have a SELECT to compare these vectors, using the new function: VECTOR_DISTANCE. The first parameter is the mathematical comparison function. Here I specified ‘cosine’, because I want to use the cosine distance (‘euclidean’ would be for Euclidean distance). The other two parameters are the vectors to be compared, which in our case are in the variables (they could be columns, literals, etc.)
I generated a comparison between each of the phrases and the result was this:

What does this result tell me?
- The phrases “A car” and “A bus” have a distance of 0, that is, the embeddings are identical. This means that, in our context, with these 2 dimensions, they are two texts with the same meaning.
- “A car” vs “A queen” or “A bus” vs “A queen” have a distance of 1, that is, they are totally different (1 is the maximum value).
Of course a car and a bus are different, which is why the vectors are going to quite a bit more complicated as we continue.
Read more: New PRODUCT() function in SQL Server 2025
A slightly more realistic example
Our embeddings are very, very simple… I kept it simple on purpose, just so you understand the comparison. Now, let’s make something a little more elaborate. See the table below:
|
Text |
Vehicle |
Person |
Color |
Gender |
|---|---|---|---|---|
|
A blue car |
0.70 |
0.01 |
0.90 |
1.00 |
|
A white bus |
0.80 |
0.10 |
1.00 |
1.00 |
|
A white car |
0.70 |
0.01 |
1.00 |
1.00 |
|
The king entered the car |
0.70 |
1.00 |
0.00 |
1.00 |
|
The queen took a plane |
0.95 |
1.00 |
0.00 |
0.50 |
Now we have 4 dimensions: Vehicle, Person, Color, and Gender. I chose 4 characteristics, and the values represent how much each phrase possesses of each characteristic. Here are the rules I established to define the values:
- In vehicle, it indicates how much of the concept of vehicle is present in the phrase. And, to differentiate the type of vehicle, the larger the vehicle, the closer to 1 this value will be.
- In person, I also defined how much of the concept of person is present. For vehicles, I kept a lower value, but which represents the capacity to transport people (bus > car). And for phrases that actually refer to people, it has a value closer to 1.
- In color, it’s how much of some color is present. And, to differentiate shades of color, colors closer to white have a value closer to 1. The 0 means that there is nothing related to colors.
- In gender, the closer the phrase refers to masculine, I left it as 1. The closer to feminine, 0.5. 0 would be for phrases that do not have any distinction of gender.
If you disagree with these values, or think they are disproportionate, don’t worry. The objective now is not the values themselves, but only that you understand that something defines these dimensions and calculates these values for each of them. For now, that thing was me… But it could be, for example, an AI trained with a giant amount of data that teaches this relationship…
Now, let’s see how all this compares, using cosine distance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @BlueCar vector(4) = '[0.70,0.01,0.90,1.00]' ,@WhiteBus vector(4) = '[0.80,0.10,1.00,1.00]' ,@WhiteCar vector(4) = '[0.70,0.01,1.00,1.00]' ,@KingCar vector(4) = '[0.70,1.00,0.00,1.00]' ,@QueenPlane vector(4) = '[0.95,1.00,0.00,0.50]' SELECT Cars = VECTOR_DISTANCE('cosine',@BlueCar,@WhiteCar) ,WhiteVehicles = VECTOR_DISTANCE('cosine',@WhiteBus,@WhiteCar) ,BlueCarVsBus = VECTOR_DISTANCE('cosine',@BlueCar,@WhiteBus) ,KingVsQueen = VECTOR_DISTANCE('cosine',@QueenPlane,@KingCar) ,KingVsCar = VECTOR_DISTANCE('cosine',@BlueCar,@KingCar) ,QueenVsCar = VECTOR_DISTANCE('cosine',@QueenPlane,@BlueCar) |
Executing this results in:

Now, we have much more interesting results than before. Let’s explain each column of the result:
- The
Carscolumn is a comparison between the two cars, blue and white. Note that the result is almost 0, but it’s not 0. This shows how close these phrases are, but not exactly, after all, they are different colors. WhiteVehiclescompares white buses and cars. Also, they are very close to 0, but still, there is a difference. They are 2 vehicles of the same color, but vehicles with different characteristics. And, note that the value is slightly higher than the comparison of cars. While the 2 cars gave 0.0013, this one gave 0.0030, which makes some sense, since a car is quite different from a bus.BlueCarVsBuscompares a blue car with a white bus produces a slightly higher value than the previous one. 0.0031, and, again, it makes sense, because besides the different vehicles, the colors are different.KingVsQueencompares two people. Here we have a much larger value than the previous ones, 0.064, but still very close to zero, indicating how much these phrases have a similarity: Both talk about people and vehicles, but they are people of different sexes and different vehicles… That’s why the value is higher than the others!KingVsCarshows a comparison between two completely different phrases. 0.37, a much higher value than the others… After all, the only thing in common is the vehicle.QueenVsCarfollows the same line, showing even more difference, because while one has people and vehicles, the other focuses primarily on the vehicle and color.
Notice how mathematics does interesting magic in these results. Up to this point, we haven’t used absolutely anything from AI, just mathematics, and we only transformed concepts into numbers.
10 tools for every stage of SQL Server development
AI joins the group…
And where does AI fit into this whole story? As I mentioned above, it’s when it comes to generating embeddings. Most of language models can generate embeddings. In fact, in almost all cases, they need embeddings, because it is by using embeddings that they can understand the text, and thus can generate more text considering context.
So, basically, all this work I did of choosing dimensions and mapping the values is done by an AI that was trained with a lot of data (or with data from a specific area, which makes it generate the values of these embeddings much better than an AI that “knows a little bit of everything”).
And, in addition, you have much more than just 4 dimensions. Imagine how much we could compare if we added just one more dimension: Do the test yourself… use your creativity, choose a dimension and adjust it in the code above, and assign some values… You’ll see how this extra dimension can completely change the results. Now, consider the fact that AIs usually generates 768, 1536 dimensions…
To generate embeddings, you must have access to an AI model, input the desired text, and receive the embeddings as output. You can access AI models in many ways; most of them involve accessing a model via API using some programming language or a web UI. This table provides a summary of options, along with some of their pros and cons:
|
Method |
Complexity |
Pros |
Cons |
|
Python Script |
Very High |
Can automate for multiple texts |
Requires knowledge of Python and AI libraries; must understand the AI model; invoke an API like OpenAI, Ollama, etc. |
|
Invoking an API from a Provider |
High |
Easily automatable in any language with HTTP support |
Requires programming skills; must understand the AI model |
|
PowershAI Module |
Medium |
Easy automation |
Easy to use in Windows environment; requires basic PowerShell knowledge; must understand the models |
|
Directly from SQL Server |
Low |
Easy automation, integrated with tables |
No need to learn other languages; not yet available; requires knowledge of new SQL 2025 commands; must understand the models |
|
Using a Hugging Face Space |
Low |
No programming knowledge needed |
Poor for automations or generating multiple texts; depends on someone creating the space for you, otherwise as complex as Python |
Generating Real Embeddings
Now that you know the basic concept behind the scenes, let’s generate real embeddings using an AI, and not from my head anymore.
For this post, we will use a Hugging Face Space. Hugging Face, often referred to as the “GitHub of AI,” hosts open-source models and demos that showcase the functionalities of these models through a web UI. I’ve set up a demo (called a “Space” in Hugging Face terminology) where you can simply paste your text, and it will generate embeddings that you can easily copy and use in your SQL Server script.
The link to the Space is: Text Embeddings – a Hugging Face Space by rrg92
This Space utilizes an open-source AI model from a company called Nomic. The model generates embeddings with 768 dimensions, which are significantly more than the 2 or 4-dimensional embeddings we explored in previous tests.
But you can use any model you want. You can use OpenAI API, or your own local install with ollama, for example. If you want more details on another ways, just leave comments that I show in future post how do that.
Note: When SQL 2025 is publicly available, I plan new posts showing how generate embeddings directly from database using lot of providers.
Real embeddings contain more decimal places that those I showed as example here. And it can contains negative values. So don’t worry about this slight difference from our example, just remember: they are just a vector of numbers (of a floating point numbers to be more precise).
Here is an example of embeddings generated using link above:

Important info about that big monster value
Real embeddings are a lot of data. You might be wondering: “Is it really that much information for just three words? Where does the AI get all of this from? Where does all this data come from?” The answer is simple: embeddings are fixed representations created by the AI model.
To better explain that let’s revisit our small 4-dimensional embeddings: Vehicle, Person, Color, Gender. Take the phrase: “Hi!”
- Does it contain something related to a vehicle? No. Assign a value of 0.
- Something about a person? No. Assign 0 again.
- Color? 0
- Gender? No. Assign 0.
Even though my sentence has just one word, it still maps to 4 dimensions. In this case, the values of these dimensions indicate low relevance for that word.
Now, imagine scaling this process up to 768 dimensions. If just 4 dimensions can capture useful information, think how complex and complete can be 768. The model has been trained to map a wide range of features (or characteristics) of words and texts into this fixed vector space. Each model has its own unique way of determining these values, and which the dimensions will be used, and this process is often a “black box” to us. For features that don’t have a direct mapping, the model still assigns some value—this could be zero or even a small negative number.
To illustrate further, let’s compare the phrases “a blue fish” and “a blue car.” Both embeddings would likely share similarities in the dimensions associated with the color “blue,” but they would differ in dimensions related to context—fish versus car. There are a lot of dimensions for “fish” that will have different values for “car.”
For example, if an AI model has a dimension to represent how “aquatic” a word is, for “fish,” this would be something close to 1, while for “car,” this could be close to or less than 0. If the model contains a dimension to represent how “metallic” a word can be, for “car,” it will be close to 1, but for “fish,” it will be close to or less than 0. Values closer to 1 indicate a strong positive association, closer to 0 indicate little to no association, and closer to -1 represent a negative or inverse association. Note that the two dimensions I mentioned, Aquatic and Metallic, are just examples. I cannot say if a model uses it because it is part of model’s internal workings and architecture.
Another important thing about real embeddings is that AI models don’t directly apply embeddings to entire sentences as shown in the simplified examples earlier. That approach was used here to make the concept more didactic and easier to understand. In practice, AI models calculate embeddings for each word (technically for each token, but for now, imagine a token as being equivalent to a word).
For a sentence, there are several techniques to combine these token-level embeddings into a single representation. One common method is to take the embeddings of all tokens and calculate the average for each dimension. However, this can sometimes result in a loss of meaning, as averaging might dilute the impact of certain key words. This issue is often more noticeable in shorter texts, where each word carries more weight in the overall meaning, compared to longer texts where the effect is less perceptible. This can explain why, in some examples below, we observe large distances compared to our previous examples.
It’s worth noting that embeddings are not perfect. For example, not all embeddings account for word position, though some advanced models do. Each AI model has its own particularities, and better models produce embeddings that are more accurate for comparisons. However, these better models often come with higher costs—either in terms of API usage fees or computational resources like GPUs required to run them.
All the details mentioned earlier about AI model embeddings can be further explored in future posts, especially once SQL 2025 becomes available, allowing us to dive deeper into techniques and real-world scenarios.
So, here’s the code with the real embeddings I generated using the Hugging Face Place mentioned earlier for each text.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE -- Gemerated using Nomic, in this space: https://huggingface.co/spaces/rrg92/text-embeddings-enus @BlueCar vector(768) = '[-0.04458834230899811, -0.009829321876168251, -0.1071217805147171, 0.010725616477429867, 0.04995579272508621, 0.015441863797605038, -0.023975618183612823, 0.04064883291721344, -0.06193269044160843, -0.041421011090278625, 0.02388092130422592, 0.009038489311933517, 0.05676793307065964, 0.024577230215072632, 0.06226604804396629, -0.028421515598893166, -0.022054390981793404, -0.04445527121424675, -0.018383268266916275, -0.016402453184127808, 0.03631089627742767, -0.004198375158011913, -0.06958834826946259, 0.012117850594222546, 0.11983727663755417, 0.022704364731907845, 0.005344585981220007, -0.004786789417266846, -0.004828524775803089, 0.0031563241500407457, 0.03057517670094967, -0.01972569338977337, 0.023008687421679497, -0.06444232910871506, -0.03278486803174019, -0.06806060671806335, 0.054954931139945984, 0.03692738339304924, 0.024324459955096245, 0.019910648465156555, 0.03970235958695412, 0.04239603132009506, 0.020277298986911774, -0.038499604910612106, 0.045184530317783356, -0.04427910968661308, 0.013413416221737862, 0.008086941204965115, 0.0018591610714793205, 0.023727143183350563, -0.03441818058490753, 0.06187102198600769, -0.005788900423794985, -0.08753295987844467, 0.05097357928752899, 0.018424002453684807, 0.0642593577504158, -0.02466471865773201, -0.027755195274949074, -0.005679564084857702, 0.05021066963672638, 0.0684981420636177, 0.01535304170101881, 0.11579055339097977, 0.03215054050087929, -0.06288453191518784, -0.005609558429569006, 0.04544017091393471, 0.019825486466288567, -0.025379003956913948, 0.04727477580308914, -0.015504471957683563, 0.014745011925697327, 0.0002574832469690591, -0.01185810286551714, -0.01782406121492386, -0.05240254104137421, -0.01448904536664486, 0.07034696638584137, 0.015214410610496998, 0.021693026646971703, 0.042933158576488495, -0.008897911757230759, 0.028549902141094208, 0.06793371587991714, 0.04290949925780296, 0.018871232867240906, 0.023011019453406334, 0.009785083122551441, -0.004792643710970879, 0.04373989254236221, 0.003911094274371862, 0.030968867242336273, 0.0011366988765075803, -0.02094477228820324, -0.04180396348237991, -0.05376134812831879, 0.05762380734086037, -0.0791977271437645, -0.0017393478192389011, -0.05638999864459038, -0.013378458097577095, -0.03219909593462944, 0.02105892263352871, 0.08798985183238983, 0.05806451663374901, -0.025558721274137497, 0.02340591698884964, -0.033250775188207626, -0.05183858424425125, 0.007134871557354927, 0.021206513047218323, -0.00581371271982789, 0.007223502267152071, -0.02949046902358532, -0.013208393007516861, -0.00028520607156679034, -0.0410267673432827, 0.015350030735135078, 0.03721786290407181, 0.020713308826088905, 0.024941543117165565, 0.021492525935173035, -0.011716942302882671, 0.031691160053014755, 0.010888774879276752, -0.06948430091142654, 0.009628682397305965, -0.05074786767363548, -0.007150833494961262, -0.05531947687268257, -0.011956772767007351, 0.04409152269363403, -0.01744137890636921, 0.04083341732621193, 0.08218090236186981, 0.01675485074520111, -0.012431482784450054, 0.008827713318169117, 0.04506300762295723, 0.043751273304224014, 0.04307150840759277, 0.035565514117479324, 0.019312532618641853, -0.02739933505654335, -0.0674905925989151, -0.0014278371818363667, -0.010763842612504959, -0.04960747808218002, -0.04064032435417175, -0.02317170798778534, -0.02865341678261757, 0.021950285881757736, 0.04003581404685974, 0.02245517075061798, -0.03190750256180763, 0.03779936581850052, -0.0013709962368011475, 0.001240366604179144, 0.04703512787818909, 0.053498681634664536, -0.01866505853831768, -0.013270286843180656, -0.006980372592806816, -0.04191618040204048, -0.04824957996606827, -0.017657864838838577, 0.04011602699756622, 0.025559796020388603, 0.02767942100763321, -0.0718347504734993, -0.08276104927062988, -0.05908765643835068, -0.011533872224390507, 0.015494907274842262, -0.04670652747154236, 0.027652207762002945, 0.005854567978531122, 0.015494025312364101, -0.04215772822499275, 0.010043219663202763, -0.06292741745710373, 0.020513584837317467, 0.059602610766887665, -0.021126244217157364, 0.0009306254214607179, -0.01791425608098507, -0.030881397426128387, -0.07569355517625809, -0.013771002180874348, 0.0031389021314680576, 0.021203499287366867, -0.017458902671933174, -0.052497684955596924, -0.031171932816505432, -0.06560375541448593, 0.014586575329303741, 0.039773695170879364, 0.07964104413986206, -0.010418347083032131, 0.013054021634161472, -0.010862634517252445, -0.004336628597229719, 0.0034660515375435352, 0.012325860559940338, 0.0310186930000782, 0.02064221352338791, 0.03906438127160072, -0.0077979546040296555, -0.006689106114208698, 0.10142883658409119, 0.017406607046723366, -0.03187423571944237, -0.00280552776530385, 0.013753283768892288, -0.0024886459577828646, -0.029179152101278305, -0.00212482875213027, 0.01576637662947178, 0.045185357332229614, 0.05225301906466484, 0.026646187528967857, 0.034515004605054855, -0.06602824479341507, 0.0035212566144764423, 0.04593885317444801, -0.010273647494614124, -0.013297653757035732, 0.029531676322221756, 0.01459990069270134, -0.007203109562397003, -0.022152436897158623, 0.03449398651719093, -0.01600799709558487, 0.03527052700519562, 0.030825115740299225, 0.02414792962372303, 0.03218958154320717, -0.02445984072983265, 0.007938235998153687, -0.045423850417137146, 0.021618714556097984, -0.02194220758974552, -0.0017799666384235024, -0.045254215598106384, -0.004959322977811098, -0.044588856399059296, -0.008886345662176609, -0.007017726078629494, 0.02420138008892536, 0.01876715011894703, 0.013606566935777664, -0.0059608942829072475, -0.007155479863286018, 0.03559144213795662, -0.03662549704313278, -0.04128691554069519, -0.020289221778512, 0.008485700003802776, -0.01792328804731369, 0.01795504428446293, -0.053791407495737076, 0.05782441422343254, -0.056689273566007614, -0.034365542232990265, 0.030215471982955933, -0.034064363688230515, -0.05988907068967819, 0.05897688865661621, -0.07926946878433228, -0.013671633787453175, 0.02194714918732643, -0.04311457276344299, -0.004337904043495655, 0.05318035930395126, -0.017606036737561226, 0.008382213301956654, -0.03558102995157242, -0.03229406103491783, 0.034710466861724854, -0.016026755794882774, 0.01910104788839817, 0.0009287690045312047, -0.0013773366808891296, -0.010698087513446808, 0.008250868879258633, -0.001623785705305636, 0.04251360148191452, 0.03828693553805351, 0.024657947942614555, -0.020421013236045837, 0.03164256736636162, 0.02966219000518322, 0.07138805836439133, 0.005132843274623156, 0.05660286173224449, 0.045677538961172104, 0.014048275537788868, 0.03228544071316719, -0.0672767385840416, 0.026414306834340096, -0.049091946333646774, 0.03557564690709114, -0.01467729452997446, 0.04236193001270294, -0.0169052854180336, 0.03050827421247959, 0.05765344575047493, 0.04828033223748207, 0.02993435226380825, -0.03882436826825142, 0.003034873167052865, -0.006438660901039839, 0.03276243805885315, -0.08892108500003815, 0.05529256537556648, -0.009765543043613434, -0.01522672176361084, 0.04431522265076637, 0.025616057217121124, 0.04466290771961212, -0.05384442210197449, 0.035242948681116104, -0.010088742710649967, 0.029519852250814438, 0.0229637548327446, -0.006506725214421749, 0.01721988618373871, 0.0391397699713707, -0.05535484850406647, -0.023381533101201057, 0.04861003905534744, 0.01067870482802391, -0.023561011999845505, 0.009837557561695576, -0.026080848649144173, -0.027888892218470573, -0.017998553812503815, -0.03774026408791542, 0.035249508917331696, 0.10900387167930603, -0.04481406509876251, 0.06988035887479782, -0.08475394546985626, -0.008044935762882233, 0.0037447696086019278, 0.03613508120179176, 0.0038100893143564463, 0.0232907272875309, -0.018171973526477814, -0.011069288477301598, -0.012372579425573349, -0.0026245738845318556, 0.0159969050437212, -0.046687982976436615, -0.005576498806476593, -0.031446345150470734, -0.008139989338815212, -0.004630087874829769, 0.03800315037369728, -0.0076899453997612, -0.04177406430244446, -0.0011113722575828433, 0.02075171284377575, -0.007061907090246677, -0.00457674078643322, -0.018312174826860428, -0.015328168869018555, 0.03769223019480705, -0.025444528087973595, -0.014578772708773613, 0.0028800361324101686, 0.007001400459557772, 0.04080093652009964, 0.04084431752562523, 0.02959582954645157, 0.010196713730692863, -0.08240749686956406, -0.023550838232040405, -0.013527732342481613, -0.0046657840721309185, 0.01683313213288784, 0.018105538561940193, 0.04947469383478165, 0.009627943858504295, -0.00787968747317791, -0.03463498502969742, -0.00952286459505558, -0.027184920385479927, -0.00010891148122027516, -0.020475665107369423, -0.04363911226391792, -0.043618664145469666, -0.005125652998685837, 0.008717392571270466, -0.03713659942150116, 0.07424020022153854, -0.04220863804221153, -0.03437221422791481, -0.013623720034956932, -0.08492084592580795, 0.03012186847627163, -0.000183523865416646, 0.0016044233925640583, -0.01082699652761221, 0.04065268486738205, 0.0041084871627390385, -0.07984661310911179, 0.07615739852190018, 0.04354507476091385, 0.03144824877381325, 0.04032951593399048, -0.0006487745558843017, -0.08480391651391983, 0.05250420421361923, 0.006078385282307863, 0.017964694648981094, 0.021382901817560196, 0.016195058822631836, 0.034203752875328064, 0.04542602598667145, 0.03762105107307434, 0.023206880316138268, 0.02269216999411583, 0.011191658675670624, -0.03162073716521263, -0.004136469215154648, 0.050807420164346695, -0.007415789645165205, -0.08906275033950806, 0.0005250597605481744, -0.03927477076649666, -0.06583748757839203, 0.01227788906544447, -0.058591220527887344, 0.015749415382742882, -0.01901897042989731, 0.013352006673812866, 0.03541041910648346, 0.03136182948946953, 0.0011963006108999252, -0.058109257370233536, 0.0075218817219138145, -0.022862421348690987, 0.050932079553604126, 0.05321560800075531, 0.03908088058233261, -0.04156560078263283, -0.039304621517658234, 0.01888279803097248, -0.01838444173336029, 0.008581935428082943, 0.008577101863920689, 0.09941866248846054, 0.03172394633293152, -0.016049740836024284, -0.0630931630730629, -0.022660337388515472, 0.030857818201184273, 0.056882552802562714, 0.06405030936002731, -0.021415363997220993, -0.02394810877740383, 0.023284198716282845, -0.001377528766170144, -0.06713501363992691, 0.026300892233848572, -0.0029329725075513124, 0.02913600392639637, 0.059909041970968246, -0.04377346113324165, 0.018109086900949478, 0.05821564793586731, -0.028245529159903526, -0.028598768636584282, 0.03718763217329979, 9.1334200988058e-05, -0.01507672667503357, 0.041492391377687454, 0.034136053174734116, 0.019847366958856583, -0.004361756145954132, -0.018782196566462517, -0.05312579870223999, -0.012427203357219696, 0.05985007807612419, 0.024106523022055626, 0.005240618716925383, 0.027749046683311462, -0.00847015343606472, 0.039485834538936615, -0.011582993902266026, 0.005015389062464237, -0.017159758135676384, 0.009834924712777138, -0.02104646898806095, 0.000333851610776037, -0.018587281927466393, 0.02018999122083187, -0.01813613995909691, -0.00655454583466053, 0.036018501967191696, 0.012484434992074966, 0.009627913124859333, 0.004255648702383041, 0.01408689096570015, -0.0022100619971752167, -0.03803907334804535, -0.03450121358036995, 0.07098370790481567, 0.005612822249531746, -0.008791891857981682, 0.0763261616230011, -0.017805201932787895, -0.006088851951062679, -0.014006400480866432, -0.01839282177388668, 0.011536906473338604, -9.187000978272408e-05, 0.04383537545800209, 0.01657944731414318, 0.005993365775793791, -0.056950874626636505, -0.011222431436181068, -0.02558913826942444, 0.02300037257373333, 0.026649868115782738, -0.09589041769504547, 0.010007309727370739, -0.016294756904244423, 0.036312468349933624, 0.010488925501704216, -0.007384163327515125, -0.01630517654120922, -0.031917303800582886, 0.01985437236726284, -0.013202645815908909, 0.031113244593143463, 0.0007531677256338298, 0.0395992211997509, 0.01619206741452217, -0.03746408596634865, 0.0006403798470273614, 0.007145638111978769, 0.016966165974736214, 0.011510501615703106, -0.07173535972833633, -0.001270035281777382, 0.04151802882552147, -0.03872992843389511, 0.0054492163471877575, -0.06005703657865524, 0.015165703371167183, -0.0026355574373155832, 0.02812781184911728, -0.040573202073574066, -0.01786266453564167, -0.03182343393564224, -0.018672503530979156, -0.0076803481206297874, 0.002477959729731083, -0.03744545206427574, 0.07461670786142349, 0.015338209457695484, 0.04671023041009903, -0.03625244274735451, -0.019696548581123352, 0.0485449880361557, 0.04302943870425224, 0.03326919674873352, 0.05340471491217613, -0.014243046753108501, 0.0052040256559848785, -0.014084364287555218, 0.012719972059130669, -0.05518585070967674, 0.015577088110148907, 0.02665451541543007, -0.03588317334651947, -0.0031324599403887987, 0.02835208736360073, -0.0179744865745306, 0.0013478054897859693, 0.04923906922340393, -0.04796208068728447, 0.03368159383535385, -0.0170985646545887, -0.03967010974884033, 0.01676964946091175, -0.04562560096383095, -0.014340144582092762, -0.017994705587625504, -0.049109481275081635, -0.013166957534849644, 0.008508670143783092, -0.00793615821748972, -0.04516813904047012, -0.053426146507263184, -0.01563597284257412, -0.022686179727315903, 0.006693217903375626, -0.042636141180992126, -0.02670179307460785, -0.026644675061106682, -0.045979585498571396, 0.014035256579518318, 0.012620972469449043, -0.0004200899275019765, 0.009021283127367496, -0.045996714383363724, 0.025143921375274658, 0.0005889218300580978, -0.014238595962524414, 0.001405593124218285, 0.025856880471110344, 0.030948085710406303, 0.04509618133306503, -0.028244081884622574, 0.002345679560676217, -0.06277463585138321, 0.009890945628285408, -0.039629943668842316, 0.060927506536245346, -0.05436713248491287, 0.011711291037499905, -0.042613085359334946, -0.05946489796042442, -0.048017822206020355, 0.038083869963884354, 0.037365399301052094, -0.004685573745518923, 0.006939896382391453, -0.0446152463555336, -0.04937287047505379, -0.01914559118449688, -0.00998601969331503, -0.02829478494822979, 0.015269330702722073, 0.04307304695248604, 0.011615797877311707, -0.014019818045198917, -0.004207888152450323, -0.013406096026301384, 0.0260293111205101, 0.011236384510993958, -0.035698067396879196, 0.03529798239469528, 0.015200851485133171, 0.041870664805173874, -0.022969925776124, 0.028679613023996353, 0.03459436446428299, 0.004514069762080908, -0.034869126975536346, -0.010406107641756535, -0.009594103321433067, 0.002175095258280635, -0.0335761159658432, -0.01719016209244728, -0.02812047302722931, -0.01164099108427763, 0.029904399067163467, -0.0728212296962738, 0.006694641429930925, 0.05029255524277687, -0.008469502441585064, 0.0003439775318838656, -0.05687438324093819, -0.0631667897105217, 0.025388125330209732, -0.0533159039914608, 0.030535930767655373, -0.03837808966636658, -0.037061844021081924, -0.0005907514714635909, 0.018075140193104744, 0.0004641663399524987, 0.05778947472572327, 0.0779535248875618, -0.009621520526707172, 0.03850407525897026, -0.02038906142115593, -0.03411258012056351, -0.0030089705251157284, -0.007862337864935398, -0.038158249109983444, 0.011490199714899063, -0.028851917013525963, -0.009170010685920715, -0.1108689159154892, 0.002080589300021529, -0.06527896970510483, -0.04045668989419937, -0.039408981800079346, 0.015382892452180386, -0.01328832283616066, -0.022550228983163834, -0.009678739123046398, -0.02530931867659092, 0.034438736736774445, -0.026507239788770676, 0.015273204073309898, 0.03182642161846161, 0.06187283247709274, -0.03433910012245178, -0.03867434710264206, -0.0025324926245957613, -0.03466170281171799, -0.054944537580013275, 0.03976785019040108, -0.06810741126537323, 0.020119652152061462, -0.003124671522527933, 0.02616346813738346, -0.001620466005988419, 0.006080920342355967, 0.04139496013522148, -0.022103674709796906, -0.013027285225689411, 0.041742026805877686, 0.06539066880941391, -0.019183265045285225, 0.0072784931398928165, -0.05994619429111481, -0.025857316330075264, -0.06124955788254738, 0.02660318650305271, -0.06940257549285889, -0.028727496042847633, -0.03020239993929863, -0.009900989942252636, 0.044294003397226334, 0.013945786282420158, 0.042010899633169174, -0.03985859453678131, -0.07205677777528763, -0.03511785715818405, -0.008442526683211327, 0.0033362647518515587, -0.008233805187046528, -0.04114651307463646, -0.056525059044361115, 0.03839297220110893, 0.03941555321216583, 0.01640142686665058, 0.015072820708155632, -0.00801049917936325, 0.04846164956688881, 0.09000784903764725, 0.011643040925264359, 0.009907384403049946, 0.009495485574007034, -0.02457716502249241, -0.01612655259668827, -0.005796502809971571, 0.00931460689753294, -0.018077122047543526, 0.0036246587987989187, 0.03422935679554939, 0.008152666501700878, 0.01341637410223484, 0.04989401623606682, -0.00456588389351964, -0.022077040746808052, -0.014214788563549519, -0.0026837908662855625, -0.09649178385734558, -0.006170217413455248]' ,@WhiteBus vector(768) = '[-0.06753987073898315, 0.07278157770633698, -0.16209536790847778, -0.03427405282855034, 0.059884246438741684, 0.03777429834008217, 0.04805590957403183, 0.06330639123916626, 0.0013740735594183207, 0.037285130470991135, 0.034625161439180374, 0.02807888388633728, 0.005724778864532709, -0.015320872887969017, 0.0006015371182002127, -0.05546802282333374, 0.03255333751440048, -0.07278770953416824, -0.01803540252149105, 0.02775910310447216, 0.022438742220401764, 0.01651052013039589, -0.07111023366451263, 0.05056516453623772, 0.12490788847208023, 0.04730222746729851, -0.02558787725865841, 0.02021860145032406, 0.027999714016914368, 0.0016590554732829332, 0.020401258021593094, -0.046842802315950394, 0.03908110782504082, -0.021801725029945374, -0.01823713630437851, -0.049415700137615204, 0.013592363335192204, -0.05734631419181824, 0.034646037966012955, 0.05381272733211517, 0.023852409794926643, -0.007062137592583895, -0.012680746614933014, 0.01586841233074665, 0.030323611572384834, -0.020290547981858253, -0.030928965657949448, -0.025266055017709732, 0.022992825135588646, 0.07110389322042465, -0.008829225786030293, -0.020472854375839233, -0.03709211200475693, -0.027930958196520805, 0.037873607128858566, -0.06502632051706314, 0.05565175786614418, -0.00949242152273655, -0.0268830768764019, 0.07220879942178726, -0.007129456382244825, -0.016455309465527534, 0.01270582340657711, 0.05786964297294617, 0.01951593905687332, -0.06139933317899704, -0.025385914370417595, 0.11720259487628937, 0.003314809873700142, -0.01399045716971159, 0.042422592639923096, -0.0026398140471428633, 0.03154914826154709, 0.040785130113363266, 0.044427379965782166, 0.04090290516614914, 0.02223508432507515, -0.03245113044977188, 0.010845126584172249, -0.012934555299580097, 0.026572134345769882, 0.0243513286113739, 0.04298821836709976, 0.06295352429151535, 0.02148522064089775, 0.0251179039478302, 0.009442930109798908, -0.033573418855667114, -0.09622170776128769, -0.0033251119311898947, 0.005363987293094397, 0.010275479406118393, 0.041716620326042175, 0.004539657849818468, -0.0165326576679945, -0.06448474526405334, -0.03357795253396034, 0.0011327677639201283, -0.042509887367486954, -0.06874965876340866, 0.044723592698574066, 0.031449757516384125, 0.027130942791700363, -0.04718969017267227, 0.019093431532382965, -0.021139338612556458, -0.016892246901988983, -0.06022575870156288, -0.060594819486141205, -0.02801678515970707, 0.002128286985680461, -0.020585065707564354, 0.006462740711867809, -0.055388811975717545, 0.03148769214749336, 0.06857883185148239, 0.06219728663563728, -0.05486880987882614, 0.05562739819288254, 0.015620740130543709, -0.00640681991353631, -0.018847718834877014, -0.04233672097325325, 0.044789720326662064, 0.012020831927657127, 0.01032610796391964, 0.007643215823918581, 0.03582453355193138, -0.0034806784242391586, -0.011811125092208385, -0.02844700776040554, -0.028272517025470734, 0.001826923107728362, -0.010596401058137417, 0.027004648000001907, 0.0507185235619545, -0.04681149125099182, -0.012483175843954086, -0.05343441292643547, 0.03387528285384178, -0.010971411131322384, 0.04591359943151474, 0.007331435102969408, 0.013547238893806934, -0.004284666385501623, -0.010278704576194286, 0.0058721802197396755, -0.02742108516395092, 0.012341071851551533, 0.058024633675813675, -0.025083083659410477, 0.011608975008130074, 0.0026038535870611668, 0.023073816671967506, 0.02586543932557106, -0.052216071635484695, 0.03018985502421856, 0.005576753988862038, 0.0027047337498515844, -0.03885068744421005, 0.06071760132908821, -0.012369439005851746, -0.015294978395104408, 0.014733134768903255, -0.018253983929753304, -0.04611120745539665, 0.008534821681678295, 0.006546329706907272, 0.04615360498428345, 0.01581859588623047, -0.06257878988981247, -0.08920854330062866, -0.018853727728128433, 0.03649149462580681, 0.006270451005548239, -0.0609319694340229, -0.02108457311987877, -0.005191299598664045, 0.02025851048529148, 0.013186526484787464, 0.016135388985276222, -0.04393143206834793, 0.026144227012991905, 0.020026234909892082, 0.007963729090988636, -0.01081851776689291, -0.031052667647600174, -0.026542475447058678, -0.08690182864665985, 0.0006196757312864065, -0.04287133365869522, 0.0416436642408371, 0.0013381780590862036, -0.013389253057539463, -0.031561486423015594, -0.01870056986808777, 0.060468584299087524, 0.00133947329595685, 0.028163133189082146, -0.051322322338819504, -0.03908231109380722, 0.017875945195555687, -0.02971956692636013, -0.0007504074601456523, -0.050515543669462204, 0.000861346663441509, -0.0033522476442158222, -0.017696678638458252, 0.009080146439373493, 0.05820843204855919, 0.031717319041490555, -0.043661974370479584, 0.025903934612870216, -0.005628982093185186, 0.007039457559585571, -0.005992755759507418, -0.021218182519078255, -0.031268827617168427, -0.009205924347043037, -0.01604309491813183, 0.03596428409218788, -0.01779867522418499, 0.004696986638009548, -0.04982787370681763, 0.005949023179709911, -0.025349289178848267, -0.058276694267988205, -0.02537562884390354, -0.033857718110084534, 0.037098828703165054, -0.015124295838177204, -0.055683936923742294, 0.06182606890797615, 0.04207181558012962, 0.014884171076118946, -0.01746087335050106, -0.014633736573159695, 0.034516841173172, 0.02433709427714348, 0.0024324199184775352, -0.010603511705994606, 0.0705065131187439, 0.019817117601633072, -0.05024820938706398, -0.021043702960014343, 0.009453725069761276, 0.049150317907333374, -0.057842835783958435, 0.007625953294336796, 0.08630435913801193, -0.037871088832616806, -0.009864158928394318, -0.009562668390572071, -0.029756179079413414, 0.03177317976951599, -0.04273594170808792, -0.030502893030643463, 0.009694283828139305, 0.038576964288949966, -0.04448121413588524, -0.004346917849034071, -0.05145706236362457, 0.035206884145736694, -0.01882917806506157, 0.05088075250387192, -0.006815358065068722, 0.02147829718887806, 0.04262840375304222, -0.0040156240575015545, -0.05585654824972153, 0.042436517775058746, 0.018471311777830124, -0.02962319180369377, 0.0034826037008315325, 0.01949373632669449, -0.018776051700115204, 0.013786676339805126, -0.04225412756204605, -0.05460185557603836, 0.023421265184879303, -0.029562467709183693, 0.011084084399044514, 0.03131186217069626, -0.05181024596095085, -0.020407071337103844, 0.023841723799705505, 0.02385186217725277, -0.015177031978964806, 0.04081428423523903, 0.050551582127809525, -0.008389999158680439, -0.002355684759095311, -0.020177388563752174, 0.015828249976038933, 0.06566629558801651, 0.04596942663192749, 0.08809691667556763, -0.04605526849627495, -0.031024547293782234, -0.050618261098861694, -0.027813736349344254, -0.02517940290272236, 0.07417648285627365, 0.001388336531817913, 0.009419579990208149, 0.008250155486166477, 0.040317896753549576, 0.015958629548549652, 0.01654982753098011, -0.008096314035356045, 0.0008468794403597713, -0.03850887343287468, -0.04964926466345787, 0.020847387611865997, -0.01715490035712719, 0.09056158363819122, -0.027910009026527405, -0.007961020804941654, 0.020347334444522858, 0.03080873191356659, -0.0028114987071603537, -0.04326989874243736, -0.004723593592643738, -0.041111018508672714, -0.011655200272798538, 0.017304418608546257, 0.018112177029252052, 0.014147255569696426, 0.033033791929483414, 0.015316272154450417, -0.03502308204770088, 0.04660641402006149, -0.04847220703959465, -0.045294225215911865, 0.03037858009338379, 0.02881024032831192, 0.007409506943076849, 0.04837045446038246, 0.03796312212944031, 0.009881503880023956, 0.03250554949045181, -0.015571756288409233, 0.028276043012738228, -0.03803853318095207, -0.02207818254828453, -0.04259709268808365, -0.05101951211690903, -0.011083797551691532, 0.02495579421520233, 0.03183741867542267, -0.00859034527093172, -0.046222392469644547, -0.010562313720583916, -0.026293920353055, -0.038540370762348175, -0.006437964271754026, -0.005668070167303085, 0.07591769099235535, 0.029979733750224113, 0.009723846800625324, -0.003297463059425354, 0.0006841842550784349, 0.006180438678711653, -0.031188981607556343, 0.05365268513560295, -0.03036755882203579, -0.028352295979857445, 0.010281777009367943, 0.036803677678108215, -0.054833706468343735, -0.058987703174352646, -0.018142245709896088, -0.028288748115301132, -0.0016879660543054342, 0.053815484046936035, 0.028537161648273468, -0.02045292779803276, 0.01555581670254469, -0.014261768199503422, 0.09104527533054352, 0.003212533425539732, -0.00542939780279994, -0.03019372932612896, 0.005066052544862032, 0.006336155813187361, -0.03226402401924133, -0.08206162601709366, -0.014224938116967678, 0.0008216122514568269, -0.0325152762234211, -0.005915377754718065, -0.05452781543135643, -0.03973351791501045, 0.024763228371739388, -0.005319707561284304, -0.03159883990883827, 0.07347212731838226, 0.0005946095334365964, -0.057645149528980255, 0.03203866630792618, -0.014742802828550339, -0.05661452189087868, -0.01846935972571373, -0.0017729733372107148, -0.030917011201381683, 0.009190528653562069, -0.03280362859368324, -0.05712028592824936, 0.030552269890904427, 0.017228344455361366, -0.0036361669190227985, 0.0017370725981891155, 0.03158096969127655, -0.08270958065986633, 0.001773934462107718, 0.05317965894937515, 0.06345227360725403, 0.044894106686115265, 0.00011983963486272842, 0.061563167721033096, 0.004971788264811039, 0.04524711146950722, -0.002070923801511526, -0.015296154655516148, 0.01154863927513361, 0.03984430432319641, -0.00488151703029871, 0.024720948189496994, 0.0005113083170726895, -0.051982346922159195, -0.027386890724301338, 0.03552022948861122, -0.003573949681594968, 0.015628235414624214, -0.03970710188150406, 0.029649939388036728, 0.0025562709197402, 0.0350564680993557, 0.04724739491939545, 0.011503390967845917, 0.06677839905023575, -0.07840978354215622, 0.00517209293320775, -0.014339487068355083, -0.01569281704723835, 0.1169191226363182, 0.04602055251598358, -0.054863303899765015, 0.020018408074975014, 0.03338490054011345, -0.02844120003283024, 0.005490866024047136, 0.028671491891145706, 0.03709106147289276, 0.04273125156760216, -0.05815018713474274, -0.028163807466626167, -0.006965890992432833, 0.014994538389146328, 0.04540498927235603, 0.006789571139961481, 0.015318549238145351, -0.02675335668027401, 0.020274560898542404, 0.02364703267812729, -0.008004088886082172, -0.02121025137603283, 0.017085369676351547, 0.03184352070093155, 0.014976712875068188, -0.04056580737233162, 0.09310349822044373, 0.05789435654878616, -0.024020779877901077, -0.005463139619678259, -0.004338595550507307, 0.007879815995693207, 0.0005037683295086026, 0.0027208970859646797, 0.06409285217523575, 0.035682179033756256, -0.03264859691262245, -0.022209106013178825, -0.10428011417388916, -0.013625557534396648, 0.01914127916097641, 0.017739098519086838, 0.002774209948256612, 0.072581447660923, -0.05675191432237625, 0.04219142720103264, 0.012327690608799458, 0.015973342582583427, 0.011041504330933094, -0.024931730702519417, -0.047498930245637894, -0.02797660045325756, 0.05218223109841347, 0.06247995048761368, 0.0021343098487704992, -0.022161489352583885, -0.03320058435201645, 0.002304140944033861, 0.03751151263713837, 0.004416126292198896, -0.010514483787119389, -0.0597001388669014, -0.012313068844377995, -0.04173269122838974, 0.02708452194929123, -0.025224000215530396, 0.039608657360076904, 0.02847933955490589, 0.013708004727959633, -0.03910323604941368, -0.04253985360264778, 0.014433164149522781, -0.017834648489952087, -0.0153739545494318, 0.06522169709205627, 0.006546597462147474, -0.0061237504705786705, -0.0046268124133348465, -0.017307164147496223, -0.08729765564203262, 0.0018608368700370193, 0.007351929787546396, -0.0707658976316452, 0.01669967919588089, 0.004470677115023136, 0.008067364804446697, -0.03809696435928345, -0.010610665194690228, -0.008711126632988453, -0.05565783008933067, -0.018506905063986778, 0.0010692557552829385, 0.025913750752806664, 0.006499735172837973, 0.023800283670425415, -0.028030794113874435, -0.024519188329577446, -0.03253740444779396, 0.022827228531241417, 0.05659250169992447, -0.007099783048033714, -0.008256364613771439, -0.018558423966169357, -0.05514315143227577, 0.001725656446069479, 0.016384849324822426, -0.043996356427669525, -0.007220359053462744, 0.006280114408582449, -0.008352242410182953, -0.02747071534395218, -0.038627903908491135, -0.031881723552942276, -0.015240038745105267, 0.013342151418328285, 0.015060605481266975, 0.019661173224449158, 0.043235715478658676, -0.005645459517836571, 0.009172569029033184, 0.02328011579811573, -0.004258895292878151, 0.08952473104000092, -0.006056841928511858, 0.0294154342263937, -0.0016935266321524978, -0.028927218168973923, -0.013200799934566021, -0.01251265686005354, 0.0251652542501688, -0.015304723754525185, 0.014577210880815983, -0.013671212829649448, -0.0015976913273334503, -0.04566016048192978, 0.04269027337431908, -0.08209864795207977, 0.0002853772311937064, -0.0008572086226195097, 0.0031105095986276865, 0.025979826226830482, -0.021532295271754265, -0.059189461171627045, 0.016151202842593193, -0.025056155398488045, -0.006753117311745882, 0.05364897474646568, 0.0040777637623250484, -0.0061232419684529305, -0.009824993088841438, 0.025961050763726234, -0.08680353313684464, 0.048555828630924225, -0.015963692218065262, 0.011444415897130966, 0.017180060967803, 0.028895121067762375, -0.019905049353837967, 0.014963589608669281, 0.024637015536427498, 0.019486939534544945, 0.02766919508576393, -0.05886966735124588, 0.014054518193006516, -0.018217964097857475, 0.054352667182683945, -0.019838163629174232, 0.013471657410264015, -0.013763543218374252, 0.03127364069223404, 0.003902768949046731, 0.04256775230169296, -0.001741849584504962, 0.004225486423820257, -0.008811019361019135, -0.03399436175823212, -0.06762699037790298, 0.019383730366826057, -0.01636437512934208, 0.025039980188012123, -0.01744813099503517, -0.039985284209251404, -0.038890134543180466, 0.008327769115567207, 0.051196783781051636, -0.03497340530157089, -0.0063784378580749035, -0.07196158915758133, -0.00980371329933405, -0.0031735312659293413, -0.045934535562992096, -0.01664154790341854, 0.008659163489937782, 0.003310081083327532, 0.0193018801510334, 0.013973046094179153, -0.011093582957983017, -0.014578337781131268, 0.04537070915102959, 0.02549872361123562, 0.0363854244351387, 0.06212664395570755, 0.004858638159930706, 0.022946465760469437, -0.03403050824999809, 0.0480194166302681, 0.05986025929450989, 0.008750534616410732, -0.0002539193956181407, -0.031050406396389008, 0.008433080278337002, 0.027967045083642006, -0.0028549169655889273, -0.009114200249314308, 0.020267769694328308, 0.00033897830871865153, 0.04366718977689743, -0.017015649005770683, 0.047096408903598785, 0.0408269502222538, 0.0102451266720891, 0.012041842564940453, -0.004115867894142866, -0.07664287090301514, -0.004904221277683973, 0.024779317900538445, 0.004054458346217871, 0.02146431989967823, -0.06415385007858276, 0.04672390595078468, -0.008083449676632881, -0.009188179858028889, 0.04886807128787041, 0.04752161726355553, -0.021688438951969147, -0.022505145519971848, -0.03744020685553551, -0.02826583757996559, 0.045957256108522415, 0.010127789340913296, -0.10806047916412354, -0.006765921134501696, -0.08768030256032944, 0.04915511608123779, 0.03279018774628639, 0.0581914447247982, -0.043251678347587585, 0.007841140031814575, -0.006397252436727285, 0.00788965541869402, -0.00831529963761568, -0.023653939366340637, 0.005402965936809778, -0.04570341855287552, 0.0687430277466774, -0.013676836155354977, 0.031744860112667084, 0.006173341069370508, 0.027030466124415398, -0.13293014466762543, -0.017127912491559982, -0.036360349506139755, -0.019678067415952682, -0.028810828924179077, -0.01692233793437481, 0.05046332627534866, 0.03126462921500206, 0.031733013689517975, 0.011390790343284607, -0.011204556562006474, 0.00783311203122139, -0.0332220196723938, -0.011878877878189087, 0.030698727816343307, 0.023203538730740547, 0.09429746866226196, 0.005632533226162195, -0.01673758216202259, -0.01587151363492012, -0.02759162336587906, 0.0018431456992402673, 0.047600068151950836, -0.03296460583806038, 0.02880772575736046, -0.011843028478324413, -0.028700359165668488, -0.03701167553663254, -0.021674100309610367, 0.006420746445655823, -0.02702731266617775, 0.03652995079755783, 0.012671167030930519, -0.014063430018723011, -0.05521361157298088, 0.013327027671039104, -0.020698094740509987, -0.014266624115407467, -0.02830195613205433, 0.056234173476696014, 0.018176188692450523, 0.030926434323191643, -0.008285448886454105, 0.01721600443124771, 0.019847260788083076, -0.0492742620408535, 0.028175534680485725, 0.0012406973401084542, -0.050912026315927505, 0.019240712746977806, -0.0014665749622508883, 0.012047656811773777, -0.03876950964331627, -0.04063274711370468, -0.0031636792700737715, 0.007616602815687656, -0.02202591672539711, -0.03131936118006706, 0.025557180866599083, 0.0010924411471933126, -0.0033318428322672844, -0.02428433485329151, -0.033836618065834045, -0.01627947948873043]' ,@WhiteCar vector(768) = '[-0.027773430570960045, 0.039530493319034576, -0.15529711544513702, -0.06483940780162811, 0.08179382234811783, 0.005144587717950344, 0.01604730822145939, 0.03616004064679146, -0.03606047108769417, 0.005966268479824066, 0.002488966565579176, -0.02230852283537388, 0.03572741150856018, 0.005476628430187702, 0.019177015870809555, -0.03336160629987717, -0.012474258430302143, -0.06511066108942032, 0.0036975096445530653, 0.0020012161694467068, 0.06503894925117493, -0.021393274888396263, -0.08108069002628326, 0.051751334220170975, 0.13936534523963928, 0.03819107636809349, -0.013152619823813438, 0.020679963752627373, 0.022207461297512054, 0.002099481876939535, 0.02557438425719738, -0.03460562974214554, 0.027615489438176155, -0.011107731610536575, -0.03066939488053322, -0.06711160391569138, -0.002971278503537178, 0.0042205448262393475, 0.06502994149923325, 0.004430792294442654, 0.0461251437664032, 0.060845643281936646, 0.045654065907001495, -0.004769631661474705, 0.056308161467313766, -0.017277440056204796, -0.02472555637359619, -0.005831120535731316, 0.02578652836382389, 0.10307715833187103, -0.03490029647946358, 0.008871945552527905, -0.03912888094782829, -0.028934085741639137, 0.05575602874159813, -0.06705574691295624, 0.0697217732667923, -0.013902364298701286, 0.0007203867426142097, 0.05481135472655296, -0.007029454689472914, 0.007207621354609728, 0.018590332940220833, 0.03952087089419365, 0.03271830454468727, -0.0911862775683403, -0.014161312952637672, 0.10503512620925903, 0.026799261569976807, -0.04751047119498253, 0.014055154286324978, 0.0012199064949527383, 0.051043733954429626, -0.01608838513493538, 0.0059188054874539375, -0.004681244492530823, -0.001646179473027587, -0.01501183956861496, 0.024565408006310463, -0.02657518908381462, 0.010322021320462227, 0.01764117181301117, -0.0038006564136594534, 0.04681064561009407, 0.05278037115931511, 0.005045303143560886, 0.010114289820194244, -0.003386974800378084, -0.07605766505002975, -0.008668974041938782, 0.013985457830131054, 0.01054626889526844, 0.023407476022839546, 0.0026678189169615507, -0.03467955067753792, -0.07410559058189392, -0.03041413240134716, 0.04466770589351654, -0.021052509546279907, -0.03521634265780449, 0.0018785366555675864, -0.012509000487625599, 0.007446016184985638, -0.02714746631681919, 0.0822729766368866, 0.024290958419442177, -0.023559685796499252, -0.03406428545713425, -0.02545512281358242, -0.053772952407598495, 0.0040767863392829895, -0.02330601215362549, -0.004276062827557325, -0.05556870996952057, 0.005027248058468103, 0.018119601532816887, 0.052679505199193954, -0.030492300167679787, 0.039178457111120224, 0.03957346826791763, -0.027976131066679955, 0.014980779029428959, -0.0365472137928009, 0.046495888382196426, 0.03050621971487999, 0.017151230946183205, -0.008321292698383331, 0.010661730542778969, 0.0008899497333914042, -0.02733827941119671, -0.03678666427731514, -0.010498625226318836, 0.009685153141617775, 0.000848871364723891, 0.02256251499056816, 0.03832452744245529, -0.043646279722452164, 0.024096639826893806, -0.004959227982908487, 0.05731809884309769, -0.0028014916460961103, 0.07948092371225357, 0.021112585440278053, 0.03164079040288925, -0.019241472706198692, -0.004902735352516174, -0.0003354843065608293, -0.05428734049201012, -0.03530002012848854, 0.005925981793552637, -0.0051035042852163315, -0.02573351003229618, -0.00020739190222229809, 0.03344808518886566, 0.023947570472955704, -0.05079716444015503, 0.0322427973151207, 0.006346975453197956, -0.016064895316958427, 0.0038716415874660015, 0.05706328898668289, -0.03700413554906845, 0.010818267241120338, 0.01074746623635292, -0.02598869986832142, -0.029115578159689903, -0.00734021607786417, 0.040200524032115936, -0.0015159383183345199, 0.019210120663046837, -0.06263264268636703, -0.06970933079719543, -0.030296670272946358, 0.029005737975239754, 0.012844682671129704, -0.08572977036237717, 0.013248587027192116, -0.049891628324985504, -0.0038896978367120028, -0.004222207702696323, 0.03758583217859268, -0.0456540510058403, 0.010669228620827198, 0.033183444291353226, -0.016018124297261238, -0.022202223539352417, -0.022110508754849434, -0.024183349683880806, -0.08356387913227081, 0.002667655237019062, -0.010997305624186993, 0.027708960697054863, 0.001885443227365613, -0.038668956607580185, -0.025672707706689835, -0.02784651704132557, 0.027879370376467705, 0.0023488181177526712, 0.0668116882443428, -0.06550885736942291, -0.04538606107234955, 0.013983835466206074, -0.013426242396235466, 0.020894819870591164, -0.050896041095256805, -0.007906179875135422, 0.020554427057504654, -0.024958845227956772, 0.011896222829818726, 0.034876029938459396, 0.04984516650438309, 0.009584280662238598, -0.005319838412106037, -0.014203113503754139, 0.041704099625349045, 0.008387855254113674, -0.017288602888584137, -0.018591634929180145, 0.0004638260288629681, -0.004363324958831072, 0.03048016130924225, -0.012959439307451248, -0.0014924645656719804, -0.0922374278306961, 0.02095058187842369, -0.008263000287115574, -0.04503054544329643, -0.03981397673487663, -0.02145944908261299, 0.03226232901215553, -0.014521680772304535, -0.0899043157696724, 0.05006248131394386, -0.026391515508294106, 0.002523422008380294, 0.012114155106246471, -0.0007252439972944558, 0.02188967913389206, 0.009783552959561348, 0.03807026892900467, -0.027235927060246468, 0.05244848132133484, 0.014699896797537804, -0.044633373618125916, -0.018959691748023033, 0.009003251791000366, -0.013684503734111786, -0.051871370524168015, -0.013432854786515236, 0.05990012735128403, -0.017678288742899895, 0.017841465771198273, -0.022804172709584236, -0.06357692182064056, 0.025349583476781845, -0.05347674712538719, -0.017862102016806602, 0.02295127883553505, 0.023657700046896935, -0.017154710367321968, -0.009502316825091839, -0.045715466141700745, 0.0241754911839962, -0.03528975695371628, 0.02851894311606884, 0.02399999275803566, 0.015945598483085632, 0.024689894169569016, 0.03582053259015083, -0.06214354187250137, 0.0549696683883667, 0.023737076669931412, -0.00712949363514781, -0.0011287899687886238, 0.010742384940385818, -0.009505472145974636, 0.015222209505736828, -0.03557730093598366, -0.023885900154709816, 0.022650573402643204, -0.02623302862048149, 0.021914571523666382, 0.03731624037027359, -0.04200403764843941, -0.05022255703806877, 0.008199484087526798, 0.002730773761868477, -0.001346322358585894, 0.014979378320276737, 0.034269142895936966, -0.051819588989019394, 0.012751715257763863, 0.013381628319621086, 0.020860346034169197, 0.03848076984286308, 0.044453807175159454, 0.0832463949918747, 0.002823432208970189, 0.012544452212750912, -0.04760191589593887, -0.029558835551142693, -0.014169400557875633, 0.04878780245780945, -0.007322394289076328, 0.02943658083677292, -0.03162470459938049, 0.06516122072935104, 0.0512373149394989, 0.006416393909603357, -0.010464726015925407, -0.014438359998166561, -0.04026077315211296, -0.04505997151136398, 0.00630289176478982, -0.059823017567396164, 0.051852501928806305, -0.0328875333070755, -0.0029921967070549726, 0.002612308831885457, 0.03707247972488403, 0.02908540517091751, -0.04822351410984993, 0.02827073447406292, -0.057838354259729385, 0.006509389262646437, 0.038704339414834976, 0.03234097361564636, -0.0199846513569355, 0.03576580435037613, -0.032251451164484024, -0.009812775067985058, 0.057328961789608, -0.0009439962450414896, -0.046049706637859344, 0.018133064731955528, 0.019275331869721413, -0.014299883507192135, 0.047512613236904144, 0.0044340090826153755, -0.006182413548231125, 0.036392197012901306, -0.03633897006511688, 0.06728233397006989, -0.05193628743290901, -0.004103780724108219, -0.02307821996510029, -0.016786903142929077, 0.0322498120367527, 0.03291497007012367, 0.023500192910432816, -0.03070637956261635, -0.03341635316610336, -0.025083409622311592, 0.0096941739320755, -0.046655505895614624, 0.002176682697609067, -0.03749026730656624, 0.054098788648843765, 0.011262014508247375, 0.005034781526774168, 0.009044354781508446, -0.024228526279330254, -0.004430497996509075, -0.05384877324104309, 0.027384137734770775, -0.015950895845890045, -0.04525763913989067, -0.017276642844080925, 0.03651423379778862, -0.021059760823845863, -0.04006611928343773, 0.0179095771163702, -0.030000997707247734, 0.020122647285461426, 0.04558258131146431, 0.029792197048664093, -0.010563996620476246, -0.003013725159689784, -0.009239857085049152, 0.03636014461517334, 0.006303752306848764, -0.03701198846101761, -0.021528949961066246, 0.050655920058488846, 9.395935921929777e-05, -0.029211988672614098, -0.09995348751544952, -0.009716692380607128, 0.0008306097588501871, -0.014175927266478539, 0.009476348757743835, -0.0458831787109375, -0.039515420794487, 0.023751357570290565, 0.02506381645798683, -0.0682896301150322, 0.06958912312984467, -0.03228451684117317, -0.06413612514734268, 0.006441599689424038, -0.034933365881443024, -0.01175056491047144, 0.0158330500125885, 0.017741063609719276, -0.0008554741507396102, 0.021407008171081543, -0.025253433734178543, -0.04190477728843689, 0.034302860498428345, 0.01036786288022995, 0.015123465098440647, 0.007609411608427763, -0.004506566096097231, -0.06918089836835861, 0.023503923788666725, 0.03993012011051178, 0.044451575726270676, 0.025928789749741554, -0.0015766570577397943, 0.030420247465372086, 0.01841423101723194, 0.03506763279438019, -0.014076192863285542, 0.024656901136040688, 0.0012934101978316903, -0.00046112609561532736, -0.01754940301179886, 0.03432047367095947, -0.024709785357117653, -0.10086216777563095, 0.007587448228150606, -0.010878430679440498, -0.04428812861442566, -0.008701033890247345, -0.028961312025785446, 0.058874357491731644, -0.05407385900616646, 0.016642196103930473, 0.03211698681116104, 0.021964747458696365, 0.02750745229423046, -0.08663562685251236, 0.03899538144469261, 0.009808479808270931, 0.0018714063335210085, 0.11407934874296188, 0.01445274893194437, -0.042457301169633865, 0.013576327823102474, 0.06108250841498375, -0.03719149902462959, 0.03032270260155201, -0.010873125866055489, 0.08414588868618011, 0.056150808930397034, -0.07050346583127975, -0.055673226714134216, -0.036652371287345886, 0.002106383675709367, 0.04810524731874466, 0.021014215424656868, 0.01428179256618023, -0.014079921878874302, 0.0341220423579216, 0.04205545037984848, -0.011196696199476719, 0.01959650032222271, 0.01376767922192812, 0.03529849275946617, 0.03358030319213867, -0.054367613047361374, 0.04305139556527138, 0.047564998269081116, -0.04971931129693985, -0.011721794493496418, -0.015547874383628368, 0.055938154458999634, -0.030505802482366562, 0.020150132477283478, 0.06878970563411713, 0.023575181141495705, -0.02538732811808586, -0.05323423445224762, -0.09757126122713089, -0.02501114085316658, 0.025520214810967445, 0.045392122119665146, -0.00570613844320178, 0.07617274671792984, -0.011997787281870842, 0.041717223823070526, 0.005486263893544674, 0.02435426227748394, 0.0052115339785814285, -0.030325815081596375, -0.04783129692077637, -0.01748374104499817, 0.013632713817059994, 0.005610131658613682, 0.00539398193359375, -0.02239501103758812, -0.05806613340973854, -0.008843311108648777, 0.025016916915774345, 0.008394356817007065, -0.016845140606164932, -0.01248530950397253, -0.009419882670044899, -0.031032536178827286, 0.03627917170524597, 0.014204785227775574, 0.024342522025108337, 0.08323188126087189, 0.00834429170936346, -0.024382255971431732, -0.03452729806303978, -0.02160346321761608, -0.01639949530363083, -0.031417325139045715, 0.03166899457573891, 0.014218514785170555, -0.008542221039533615, -0.06047137826681137, -0.02509247697889805, -0.09044092893600464, 0.009661232121288776, 0.020590122789144516, -0.10719799995422363, 0.006614529062062502, -0.027564942836761475, 0.021683115512132645, -0.003914882894605398, -0.008151086047291756, 0.0269908644258976, -0.021936513483524323, 0.0021011391654610634, -0.03281485661864281, 0.005335668101906776, 0.022326039150357246, 0.027993353083729744, -0.014554052613675594, -0.04552881419658661, -0.0001212546558235772, 0.011287047527730465, 0.059243541210889816, 0.02504776045680046, -0.030452093109488487, 0.004934461787343025, -0.012495079077780247, -0.021131249144673347, -0.018626265227794647, -0.01839902065694332, 0.0354265496134758, -0.02157890982925892, 0.01731615886092186, -0.032658595591783524, 0.0034498441964387894, -0.017147619277238846, -0.028348557651042938, -0.008426777087152004, 0.012974978424608707, 0.0061413804069161415, 0.06649941951036453, 0.021327409893274307, 0.021504828706383705, 0.030579714104533195, -0.0032601128332316875, 0.043910566717386246, -0.009874310344457626, 0.05604301765561104, 0.030096622183918953, -0.014481349848210812, -0.014006524346768856, -0.02447066642343998, 0.02439013123512268, -0.037199266254901886, 0.015485153533518314, 0.006118180695921183, 0.0036686768289655447, -0.030363136902451515, 0.022162288427352905, -0.058403562754392624, -0.014325304888188839, 0.026818305253982544, 0.014442569576203823, 0.013894480653107166, -0.009776980616152287, -0.0628330186009407, 0.0008445630082860589, -0.020356982946395874, -0.0149035369977355, 0.02154732309281826, 0.013381577096879482, -0.006141583435237408, -0.014537287876009941, 0.029336096718907356, -0.07947469502687454, 0.013723640702664852, -0.007838642224669456, 0.0018007985781878233, 0.03356214240193367, 0.042999569326639175, -0.023353759199380875, -0.021111348643898964, -0.022204242646694183, 0.025356290861964226, 0.033963777124881744, -0.03163101151585579, 0.00783825758844614, -0.050719745457172394, 0.044873036444187164, -0.009552917443215847, -0.005667009856551886, -0.02122458629310131, -0.011520168744027615, 0.025401988998055458, 0.04798237234354019, -0.03905315697193146, 0.00022193806944414973, -0.024845890700817108, -0.01708778366446495, -0.047644633799791336, 0.04862580448389053, 0.010858521796762943, 0.016707085072994232, -0.015900004655122757, -0.05690767616033554, -0.03356078639626503, 0.02966243401169777, 0.082548126578331, -0.006331547629088163, -0.005229467526078224, -0.044357456266880035, 0.004159612115472555, -0.033369939774274826, -0.029806150123476982, 0.021217580884695053, 0.019044553861021996, 0.05491739884018898, 0.059718940407037735, 0.024168362841010094, 0.014946224167943, -0.004545973148196936, 0.04415087029337883, -0.0071115619502961636, -0.0066160960122942924, 0.04373406991362572, 0.0031468209344893694, 0.04609805718064308, -0.0024352618493139744, 0.04615902900695801, 0.05923732742667198, 0.012227801606059074, 0.009507173672318459, -0.006809429731220007, -0.00015941777382977307, 0.012248629704117775, -0.05527378246188164, -0.029200393706560135, 0.00874241255223751, -0.0038534763734787703, 0.1080559566617012, -0.03062039613723755, 0.04584809020161629, 0.026885241270065308, 0.01565711386501789, 0.003353129606693983, -0.05039756000041962, -0.07909312844276428, 0.034767210483551025, -0.0075780656188726425, 7.567479042336345e-05, -0.0014798074262216687, -0.07013475894927979, 0.04326019063591957, -0.00664185406640172, -0.02642153576016426, 0.05586319416761398, 0.09907937049865723, 0.01547487173229456, 0.02990557625889778, -0.022104112431406975, -0.04902450367808342, 0.027377299964427948, 0.034498393535614014, -0.05789083242416382, 0.004796757362782955, -0.053319301456213, 0.011462151072919369, -0.00547825125977397, 0.008008712902665138, -0.09623390436172485, 0.02178267575800419, -0.007160022389143705, 0.029232829809188843, -0.006469066254794598, -0.02577325887978077, -0.002938260789960623, -0.05693812295794487, 0.05601716786623001, -0.006650036666542292, 0.017208237200975418, 0.05249451845884323, 0.03863444924354553, -0.08671215921640396, -0.020112283527851105, -0.008245974779129028, -0.01234346628189087, -0.047104015946388245, 0.04901542514562607, -0.02337159588932991, 0.026961766183376312, 0.04068936035037041, 0.04701109975576401, -0.0018334798514842987, -0.005221422761678696, 0.018209561705589294, -0.010032080113887787, 0.006245321594178677, 0.021675242111086845, 0.07398740202188492, -0.017181867733597755, 0.008505577221512794, -0.06925423443317413, -0.03525201231241226, -0.004687266889959574, 0.0029127777088433504, -0.05455626919865608, 0.03369000181555748, -0.010883547365665436, -0.006105381064116955, 0.04479272663593292, -0.0005694981082342565, 0.013060487806797028, -0.04899865388870239, 0.005672058556228876, 0.00574337737634778, -0.03156585618853569, -0.046348921954631805, 0.023255605250597, -0.0521051287651062, -0.033938053995370865, 0.009132648818194866, 0.025467341765761375, 0.019316770136356354, 0.009398064576089382, 0.01125379465520382, 0.05623510852456093, 0.032729290425777435, 0.0133063904941082, 0.027968520298600197, 0.023214247077703476, -0.06517212092876434, -0.01652582362294197, 0.018255600705742836, 0.009669958613812923, -0.04515133425593376, -0.021455252543091774, 0.019841695204377174, -0.0027564314659684896, -0.019980860874056816, -0.004255531821399927, 0.008842863142490387, -0.0500887967646122, 0.01920354552567005, -0.014437372796237469, -0.06192202866077423, -0.024565989151597023]' ,@KingCar vector(768) = '[-0.06366106122732162, 0.0371050201356411, -0.13371889293193817, -0.021586041897535324, 0.0013707682956010103, 0.00780313229188323, -0.034369003027677536, 0.07440928369760513, -0.03610813245177269, -0.014822323806583881, -0.07335194945335388, 0.010727082379162312, 0.028241479769349098, -0.00557663943618536, 0.016600733622908592, -0.0306655652821064, 0.03163173422217369, -0.0392732247710228, -0.01930205337703228, 0.03520410507917404, 0.001106951734982431, 0.024142472073435783, -0.11819662898778915, 0.03766537830233574, 0.12828004360198975, -0.03675626590847969, 0.012544563040137291, -0.010433417744934559, -0.030474113300442696, 0.009951172396540642, 0.07748491317033768, 0.008755724877119064, -0.013789679855108261, -0.003658221336081624, -0.05787202715873718, -0.06254521757364273, 0.013255460187792778, 0.015263033099472523, 0.06202990561723709, -0.04171683266758919, 0.03531118109822273, -0.019832830876111984, -0.0035260797012597322, 0.0011221289169043303, 0.050706375390291214, -0.02496286854147911, -0.018272006884217262, -0.014864951372146606, -0.008298984728753567, 0.055641286075115204, -0.004939673002809286, -0.009292079135775566, -0.06001249700784683, -0.04088565334677696, 0.0348367914557457, 0.058439090847969055, 0.06897229701280594, -0.013636983931064606, -0.013078944757580757, -0.008195041678845882, 0.04189392924308777, -0.0026941827964037657, 0.03311255946755409, 0.03299403563141823, -0.01136003527790308, -0.07077934592962265, 0.008899410255253315, 0.11259376257658005, 0.005413408391177654, -0.0005293236463330686, 0.06112422049045563, -0.025380725041031837, 0.05198495090007782, -0.06003855913877487, 0.01372306328266859, -0.014799459837377071, 0.024818839505314827, -0.013034540228545666, 0.04515213891863823, 0.003686752635985613, 0.025093114003539085, 0.010564188472926617, 0.036675553768873215, -0.015977639704942703, 0.019526254385709763, 0.048439327627420425, 0.007097748573869467, -0.005672773811966181, -0.01210852526128292, 0.032246120274066925, 0.04791032522916794, 0.002837446052581072, 0.01372729241847992, 0.01059779804199934, -0.011713002808392048, -0.0035321360919624567, -0.07068976014852524, -0.006282274145632982, -0.054073482751846313, -0.024566451087594032, 0.004859513603150845, -0.06207720562815666, -0.04637769237160683, 0.007238851860165596, 0.04596610739827156, 0.09409582614898682, -0.022839045152068138, -0.01344651822000742, -0.05625656619668007, -0.04211822897195816, -0.05266684293746948, -0.019075682386755943, -0.02469347044825554, 0.01892205700278282, 0.0020926259458065033, 0.05143514275550842, 0.01646832749247551, -0.021359995007514954, 0.023504668846726418, 0.01597212813794613, -0.006127077620476484, 0.03513404354453087, -0.034080762416124344, 0.03015647828578949, 0.027435703203082085, 0.04274039715528488, -0.05109681934118271, 0.025393040850758553, -0.009092634543776512, -0.03166860714554787, 0.0008341529755853117, -0.017169179394841194, 0.02262737788259983, 0.02078302577137947, 0.021752193570137024, 0.040563080459833145, 0.024453796446323395, 0.011116179637610912, 0.01555157545953989, -0.015091498382389545, -0.004414839670062065, 0.10259556025266647, 0.006927843671292067, -0.001541371108032763, 0.011072404682636261, -0.05808652564883232, 0.03441719710826874, -0.04433462768793106, -0.08440816402435303, -0.03737889975309372, 0.042378831654787064, -0.026720141991972923, -0.02168756164610386, 0.05760018154978752, -0.0032769159879535437, -0.03169456124305725, 0.01809801533818245, 0.01806609518826008, -0.012502556666731834, 0.0035988816525787115, 0.06761959940195084, -0.05037262663245201, -0.03804485872387886, -0.015567172318696976, -0.0533166378736496, -0.05869799852371216, -0.001539027551189065, 0.027588823810219765, 0.025486772879958153, 0.012392756529152393, -0.03627096116542816, -0.045470546931028366, -0.0692552700638771, -0.01331236306577921, 0.01707572303712368, -0.031985603272914886, -0.0076558589935302734, 0.010407185181975365, 0.03333669155836105, -0.018301311880350113, 0.024359852075576782, -0.05566363409161568, 0.06798135489225388, 0.03206321597099304, -0.028008606284856796, -0.024596640840172768, -0.0013886664528399706, 0.0035310739185661077, -0.12796537578105927, -0.03128506615757942, 0.027147477492690086, 0.012598813511431217, -0.034458935260772705, -0.04176492244005203, -0.020084459334611893, -0.008275012485682964, 0.012430391274392605, -0.0014343679649755359, -0.0017723670462146401, -0.0669977068901062, 0.030101090669631958, -0.01649354211986065, -0.021510746330022812, 0.023386262357234955, -0.05557464063167572, 0.04042872041463852, 0.013721577823162079, 0.06907942146062851, 0.025088677182793617, 0.015678446739912033, 0.06761188060045242, 0.029340485110878944, -0.02622014284133911, 0.01902276650071144, 0.0044332160614430904, 0.011708052828907967, 0.011221346445381641, -0.05547370761632919, 0.026139002293348312, 0.02727733738720417, 0.011644686572253704, 0.06446246802806854, -0.019420454278588295, 0.0077054426074028015, 0.012713948264718056, 0.04476592689752579, -0.03194887563586235, -0.028435664251446724, -0.02789870835840702, 0.02823544852435589, -0.016924450173974037, -0.059969209134578705, -0.0035176135133951902, 0.023445427417755127, 0.008029638789594173, 0.043270356953144073, -0.017083656042814255, 0.017261117696762085, 0.0017239635344594717, -0.022292859852313995, -0.03037146106362343, 0.03088788501918316, -0.011150875128805637, 0.0029234846588224173, -0.04844862222671509, -0.014091788791120052, -0.04211028665304184, -0.052125848829746246, -0.01213399413973093, -0.0012184333754703403, 0.04219217970967293, 0.011617334559559822, 0.0017507555894553661, -0.05298397317528725, 0.034914419054985046, -0.0032100225798785686, 0.00433887867256999, 0.022006958723068237, 0.02388767898082733, -0.009323387406766415, 0.01200153212994337, -0.06079466640949249, -0.012501752935349941, -0.05929611250758171, -0.016602564603090286, -0.002764082746580243, -0.027686864137649536, -0.02444462478160858, 0.03277736157178879, -0.05755779892206192, -0.011888101696968079, 0.04949815198779106, -0.0005932464264333248, -0.009920597076416016, 0.027878912165760994, -0.015917856246232986, -0.015443075448274612, -0.004528769291937351, -0.04335176199674606, 0.024572549387812614, -0.024229703471064568, -0.01117569301277399, -0.045808907598257065, -0.03657638654112816, -0.031372059136629105, 0.008075215853750706, 0.03554118052124977, 0.02839074656367302, 0.00991312600672245, -0.002091935370117426, -0.0028176980558782816, 0.02154993638396263, -0.027894115075469017, 0.03942064568400383, -0.00697919400408864, 0.05364608019590378, 0.06351293623447418, 0.004432743415236473, 0.05171772092580795, -0.054354019463062286, 0.02710771933197975, -0.06337929517030716, 0.04363371059298515, 0.016077402979135513, -0.006730057764798403, 0.032895877957344055, 0.061682816594839096, -0.006756788119673729, -0.0013039348414167762, 0.02452850341796875, -0.04273669421672821, 0.0017555552767589688, -0.02484673634171486, 0.01654120162129402, -0.050401050597429276, -0.013555179350078106, -0.029520176351070404, 0.030410127714276314, 0.04934011772274971, 0.04255753010511398, 0.03343106433749199, -0.06316710263490677, -0.006875617895275354, 0.04040314257144928, 0.01475065853446722, 0.0064861527644097805, 0.00795707106590271, 0.024394547566771507, 0.015946978703141212, -0.06312892585992813, -0.05017373710870743, 0.034141771495342255, 0.004597937688231468, -0.011153428815305233, -0.014226709492504597, 0.0074204858392477036, 0.003184535074979067, 0.0006467169150710106, -0.07516764104366302, -0.02806982770562172, 0.06268969178199768, 0.005808957386761904, 0.05972323194146156, -0.058881018310785294, 0.003912910353392363, -0.024058520793914795, -0.01225863303989172, -0.002526150783523917, 0.00962097104638815, -0.04450139030814171, -0.052008628845214844, -0.03333699330687523, -0.05173855647444725, 0.0200785081833601, -0.03953101858496666, -0.0013116549234837294, 0.0038196281529963017, 0.001298278453759849, -0.010305926203727722, -0.022327329963445663, 0.021411694586277008, -0.024495767429471016, -0.011845064349472523, 0.01960724964737892, 0.007499337196350098, 0.02236524224281311, -0.044154245406389236, 0.03023315779864788, 0.07026881724596024, 0.01331376750022173, -0.025468070060014725, -0.025637846440076828, 0.007263836916536093, -0.010874268598854542, 0.06688091158866882, 0.035154540091753006, 0.022392945364117622, -0.04093608632683754, -0.011615126393735409, 0.01297572162002325, 0.0045560249127447605, -0.020895004272460938, 0.02393454499542713, -0.0022832215763628483, 0.035725802183151245, -0.01396249607205391, -0.00627897260710597, 0.0016107918927446008, 0.025219794362783432, 0.03471263498067856, 0.020762275904417038, -0.010397386737167835, -0.02790127508342266, -0.002030178438872099, 0.006919954437762499, -0.013145138509571552, 0.033879246562719345, -0.005154558923095465, -0.021613212302327156, -0.02694893442094326, -0.021107524633407593, -0.05720813572406769, -0.004802398383617401, 0.03572844713926315, -0.005722348112612963, 0.04624824598431587, 0.007859088480472565, 0.0013543666573241353, 0.023279927670955658, -0.014572516083717346, -0.03808373585343361, 0.033461615443229675, -0.006573510821908712, -0.021835295483469963, 0.04068354517221451, 0.08527461439371109, 0.04667339473962784, 0.0473264716565609, -0.007898886688053608, -0.014603382907807827, 0.0032634101808071136, 0.018541963770985603, -0.0214321780949831, 0.0655340626835823, 0.03454082831740379, -0.03912718966603279, 0.026738449931144714, 0.06706195324659348, -0.02891382947564125, -0.02839827351272106, 0.0041891285218298435, -0.01614525355398655, 0.015519657172262669, -0.0018116787541657686, -0.044259220361709595, -0.004364165477454662, -0.0405392087996006, 0.005998142529278994, 0.04484136402606964, 0.007288094609975815, -0.012759699486196041, -0.00428609736263752, 0.004865632858127356, 0.029453344643115997, 0.06727330386638641, 0.05441083386540413, 0.07995761930942535, -0.05690153315663338, -0.0035483071114867926, 0.012413259595632553, -0.03252313658595085, 0.004201763309538364, 0.005882630590349436, 0.08963844180107117, 0.025890352204442024, -0.030336754396557808, -0.018279405310750008, 0.04141668230295181, -0.014466621913015842, 0.03416265547275543, 0.03470799699425697, 0.06862060725688934, -0.06484212726354599, -0.015849579125642776, -0.01852634735405445, -0.03905472531914711, 0.0349593311548233, 0.025922926142811775, 0.010498475283384323, 0.09378057718276978, -0.0014182854210957885, 0.04863166809082031, 0.054431840777397156, -0.057487852871418, -0.0012642150977626443, -0.008686992339789867, 0.002338971011340618, -0.022694764658808708, 0.003046521684154868, 0.018556222319602966, 0.07186167687177658, -0.008406461216509342, -0.03591064736247063, -0.009360063821077347, 0.059594787657260895, 0.060069773346185684, 0.06003686040639877, 0.00474492646753788, 0.0107337711378932, -0.018538692966103554, 0.04737463220953941, 0.011740733869373798, 0.008988619782030582, -0.008960655890405178, 0.015540453605353832, 0.024755731225013733, -0.014641745947301388, -0.014524136669933796, 0.06867149472236633, 0.03326162323355675, 0.0028918017633259296, 0.0031980436760932207, 0.004538172855973244, 0.028210125863552094, 0.025534896180033684, 0.00014415518671739846, -0.04175432771444321, -0.048417385667562485, -0.030866866931319237, 0.01711653731763363, -0.025715069845318794, 0.018891382962465286, 0.052085716277360916, 0.027676770463585854, 0.06333545595407486, -0.026016179472208023, -0.02149113453924656, -0.003996374551206827, 0.010398399084806442, 0.03595874831080437, 0.0297502763569355, -0.05126122757792473, -0.0371004119515419, -0.01801861822605133, -0.04476458951830864, 0.018582718446850777, 0.014414746314287186, -0.08984274417161942, 0.033408407121896744, 0.010137028060853481, -0.02090885490179062, 0.051851462572813034, -0.027393698692321777, -0.003076093504205346, -0.028873620554804802, 0.010142097249627113, -0.03572884202003479, 0.015200181864202023, 0.06516408175230026, 0.051115039736032486, -0.03836166113615036, -0.05010218545794487, -0.05672683194279671, -0.0015361227560788393, 0.024037934839725494, 0.008187641389667988, -0.022505061700940132, 0.005200835410505533, 0.020836494863033295, -0.061269983649253845, -0.0009010604699142277, -0.0005452027544379234, -0.01656942255795002, -0.02000238001346588, -0.03806008771061897, 0.011611546389758587, -0.025317983701825142, 0.010892925783991814, -0.0388295017182827, -0.02852153778076172, 0.02633289434015751, 0.0077706738375127316, 0.07893088459968567, -0.008183461613953114, 0.057981397956609726, 0.04854878783226013, -0.03099481388926506, -0.014461650513112545, 0.022053267806768417, -0.022659189999103546, 0.057305049151182175, -0.07823824137449265, 0.03477101773023605, -0.008153085596859455, 0.02639620564877987, -0.022829649969935417, -0.011906684376299381, -0.01202781405299902, -0.004245353396981955, -0.03288949653506279, 0.0020920231472700834, -0.04012777656316757, 0.04536862671375275, -0.021806148812174797, -0.025099318474531174, 0.006625513546168804, -0.021334243938326836, -0.04357508197426796, 0.008799050003290176, 0.030935999006032944, 0.007096234709024429, -0.028460733592510223, -0.024773970246315002, -0.03955823928117752, 0.0360407717525959, 0.010507404804229736, -0.05877269431948662, -0.057825200259685516, 0.016515787690877914, 0.025679245591163635, 0.00016562180826440454, -0.020788313820958138, -0.004515292588621378, -0.030309511348605156, -0.05443612486124039, -0.019161170348525047, -0.006705099251121283, 0.012744844891130924, 0.028499005362391472, -0.07650218158960342, 0.05261358991265297, 0.010430612601339817, -0.05655532702803612, -0.021937832236289978, 0.017426565289497375, 0.00971758272498846, 0.03487032651901245, -0.03983062505722046, 0.04137676954269409, -0.037917062640190125, 0.01320004090666771, 0.003169502830132842, 0.02158210426568985, -0.05612201616168022, -0.010954713448882103, -0.0037530665285885334, -0.06391280889511108, -0.001566447434015572, 0.0620119571685791, 0.0163772813975811, -0.05010385438799858, -0.020807895809412003, -0.10817781835794449, -0.011930916458368301, 0.028940994292497635, -0.022621747106313705, 0.017265643924474716, -0.013283086940646172, -0.032334260642528534, 0.03764217346906662, -0.001690164441242814, 0.012455432675778866, 0.012295352295041084, 0.03212975710630417, -0.017112338915467262, -0.01531390193849802, 0.036518242210149765, 0.01306963711977005, 0.05304592475295067, -0.027347320690751076, 0.01528905238956213, 0.05146951973438263, -0.018679386004805565, 0.00927517656236887, -0.018137317150831223, -0.04333076998591423, 0.01455201767385006, -0.013612452894449234, -0.03810257837176323, -0.03232290595769882, 0.025517234578728676, 0.04348595440387726, -0.0337044931948185, -0.010229643434286118, 0.004854648374021053, -0.022152254357933998, -0.01501529011875391, -0.045361440628767014, -0.05973502993583679, -0.003665621392428875, -0.0017631041118875146, 0.062240779399871826, -0.030635660514235497, 0.006467327941209078, -0.06075343117117882, 0.00620994670316577, 0.024431154131889343, 0.09336975961923599, 0.07987461984157562, -0.012147100642323494, -0.0061226049438118935, -0.02962534874677658, -0.013505786657333374, 0.046773314476013184, 0.011823790147900581, -0.06813932955265045, 0.05885862186551094, -0.08962016552686691, -0.025659214705228806, -0.06166895851492882, -0.012911785393953323, -0.05230940505862236, -0.012052700854837894, 0.020201697945594788, 0.02006365731358528, -0.016116907820105553, -0.036077629774808884, 0.04135405272245407, -0.016678225249052048, 0.026984741911292076, -0.03253397345542908, 0.07236023247241974, -0.0041063022799789906, 0.05308401584625244, -0.04912285506725311, -0.016073934733867645, 0.05855884030461311, -0.049489881843328476, -0.047114912420511246, 0.07775460928678513, -0.024515114724636078, 0.032597050070762634, 0.0010274001397192478, 0.07839085161685944, 0.05551754683256149, -0.001981100533157587, 0.00037833908572793007, -0.022664068266749382, 0.017995117232203484, 0.03330269455909729, 0.04866890609264374, -0.0038558170199394226, 0.010613791644573212, -0.018434686586260796, -0.021841280162334442, -0.013224661350250244, 0.000776260276325047, -0.02765618823468685, -0.05495471507310867, -0.006177089177072048, 0.020273515954613686, 0.011953822337090969, -0.011116527020931244, -0.005147586110979319, -0.03997739404439926, -0.04089261218905449, 0.009126395918428898, -0.055831391364336014, -0.03294454142451286, 0.003459766274318099, -0.07259533554315567, -0.024916263297200203, 0.023026155307888985, 0.06521034985780716, 0.013879184611141682, -0.05423635616898537, -0.031092960387468338, 0.051712095737457275, 0.04224510118365288, 0.011599160730838776, 0.01474816258996725, -0.046958472579717636, -0.035996511578559875, 0.02138986997306347, -0.011776183731853962, -0.05024464800953865, -0.02437511458992958, 0.02252824418246746, 0.048551395535469055, 0.04517240822315216, 0.032376307994127274, 0.036311421543359756, 0.022917963564395905, 0.021379785612225533, 0.01934393309056759, -0.019422456622123718, -0.020691726356744766, 0.004326852969825268]' ,@QueenPlane vector(768) = '[0.016738194972276688, 0.03851189836859703, -0.1601611077785492, 0.013240817002952099, -0.02566191554069519, 0.09977556020021439, -0.09398238360881805, 0.009572899900376797, 0.0032859453931450844, -0.00032333898707292974, -0.10052357614040375, 0.016457481309771538, 0.05764659121632576, 0.008905536495149136, 0.03705701231956482, 0.017145730555057526, 0.02708732895553112, -0.05319942533969879, 0.011150202713906765, 0.026652848348021507, -0.018271682783961296, -0.04349777474999428, -0.09087739139795303, 0.03186503052711487, 0.04204704612493515, -0.02756803296506405, -0.02298874594271183, -0.028772469609975815, -0.052430376410484314, 0.016002431511878967, 0.03592327609658241, -0.05157889425754547, -0.007978458888828754, -0.04355033487081528, 0.04342946410179138, -0.04390189051628113, 0.007750354707241058, 0.021289626136422157, 0.05545462295413017, 0.012403812259435654, 0.04102298989892006, -0.042156558483839035, -0.05996732786297798, 0.02875075861811638, 0.0807604044675827, -0.002514082472771406, 0.10617813467979431, 0.021601933985948563, -0.0739089623093605, 0.055247969925403595, -0.003266998566687107, 0.04703563451766968, -0.02336852066218853, 0.012801905162632465, 0.02652469091117382, 0.012202356941998005, 0.07868687808513641, 0.031579479575157166, -0.010338389314711094, 0.03971477970480919, 0.07214783132076263, -0.0114823617041111, -0.00891769491136074, 0.050829194486141205, 0.0017501984257251024, -0.05484052374958992, -0.05692543834447861, 0.0692700743675232, -0.01557659637182951, -0.024288058280944824, 0.06469117850065231, -0.029098939150571823, 0.015836115926504135, -0.0034314070362597704, -0.008690569549798965, -0.055109649896621704, 0.021664556115865707, -0.0281540360301733, 0.03106490708887577, -0.0025430459063500166, 0.024443702772259712, -0.04702211171388626, 0.06634590029716492, 0.007679872680455446, 0.08201615512371063, 0.05635029822587967, -0.012808251194655895, -0.03962161764502525, -0.0297028049826622, 0.03853800520300865, 0.026925968006253242, 0.013254616409540176, 0.0505782775580883, 0.042274102568626404, 0.004908622708171606, -0.022555826231837273, -0.035282183438539505, -0.03359346091747284, -0.09881284087896347, -0.05224372446537018, 0.02286038175225258, -0.03992535546422005, -0.00864262506365776, 0.009546410292387009, 0.02249276451766491, 0.013854355551302433, 0.017956100404262543, -0.004915771074593067, -0.02826392650604248, -0.013385090045630932, -0.04583475738763809, -0.007576699834316969, 0.0015305611304938793, 0.014210045337677002, 0.04394854977726936, -0.0011736364103853703, -0.015165787190198898, -0.09530927240848541, -0.012121522799134254, 0.007773947902023792, -0.029642576351761818, -0.016042865812778473, -0.026232201606035233, 0.019411057233810425, 0.040535565465688705, 0.017174646258354187, -0.08341798931360245, 0.02100609615445137, -0.006393759045749903, -0.028912045061588287, -0.023898446932435036, -0.0069627598859369755, -0.01790030114352703, 0.0354580283164978, -0.010248945094645023, -0.005673663225024939, -0.03890756145119667, -0.05686764419078827, 0.02641872689127922, 0.022053426131606102, -0.004869663156569004, 0.040565963834524155, -0.00884919986128807, 0.01831507496535778, 0.017632294446229935, -0.050500232726335526, 0.031762056052684784, -0.003667967626824975, -0.05037406086921692, -0.0091431625187397, 0.02898624911904335, 0.010696418583393097, -0.026012087240815163, 0.05576695501804352, 0.007542508188635111, -0.04111504554748535, -0.010258208028972149, 0.03550751879811287, 0.020793624222278595, -0.030983489006757736, 0.0843900516629219, 0.005597489885985851, -0.02216118946671486, 0.015960024669766426, -0.051059383898973465, -0.006498910021036863, 0.03903690725564957, 0.03965875506401062, -0.006671146489679813, 0.018513090908527374, -0.009379379451274872, -0.015054634772241116, -0.013682165183126926, -0.010232221335172653, 0.03303896635770798, -0.0021401040721684694, 0.03342844173312187, 0.03880198299884796, 0.04391663148999214, -0.08045525848865509, 0.019559964537620544, -0.022398078814148903, 0.017407389357686043, 0.013860544189810753, -0.03572741895914078, -0.008447304368019104, -0.01932196505367756, -0.013986886478960514, -0.05978729948401451, -0.04262132570147514, -0.019841095432639122, 0.011346420273184776, -0.02127671055495739, -0.04411720484495163, -0.07477138191461563, -0.029742354527115822, 0.05125656723976135, 0.001999438274651766, -0.01500912755727768, -0.03576670214533806, 0.05003831535577774, -0.022809693589806557, 0.03387007489800453, 0.01983301155269146, -0.051122184842824936, 0.02503529004752636, 0.02872629649937153, 0.026122961193323135, 0.02446310967206955, 0.0029503251425921917, 0.042907748371362686, 0.039467353373765945, -0.019990645349025726, 0.03891472518444061, 0.042597826570272446, -0.022257691249251366, 0.007392737083137035, -0.09300504624843597, -0.01046187523752451, 0.0009323217673227191, 0.030724508687853813, -0.0060162716545164585, 0.005696398671716452, -0.010141856968402863, 0.07034212350845337, 0.02940642647445202, -0.029699712991714478, -0.04814918339252472, -0.049803055822849274, -0.005373232997953892, -0.037679947912693024, -0.08455987274646759, 0.003730542492121458, 0.020712651312351227, 0.011942348442971706, 0.02639000676572323, -0.04238726943731308, -0.010008812882006168, -0.005130933132022619, -0.006615553982555866, -0.009448476135730743, 0.06775406002998352, -0.018433457240462303, -0.011227636598050594, -0.05197012424468994, 0.0034698606468737125, -0.04564050957560539, -0.020316272974014282, 0.013147556222975254, 0.017338454723358154, -0.00854458101093769, -0.02353058010339737, 0.029066920280456543, 0.014241427183151245, 0.023930003866553307, 0.0017423448152840137, 0.009539748542010784, 0.01014459878206253, 0.05664994567632675, -0.01833701692521572, 0.021752776578068733, -0.04695868492126465, 0.031930647790431976, -0.013708713464438915, -0.04813426360487938, -0.011189988814294338, -0.03988586738705635, -0.008961199782788754, 0.01844659075140953, -0.06385631859302521, -0.019223956391215324, 0.03806215152144432, 0.0022795633412897587, 0.027209697291254997, 0.04145437851548195, -0.011339809745550156, 0.010930157266557217, 0.02068455144762993, -0.021217312663793564, 0.06953195482492447, 0.011332526803016663, -0.00088653335114941, -0.07522927969694138, -0.012830057181417942, 0.023100849241018295, -0.010069990530610085, 0.028209423646330833, 0.056359436362981796, 0.018819496035575867, 0.0017573075601831079, -0.035754069685935974, 0.03480902686715126, 0.013656988739967346, -0.008945025503635406, 0.012418141588568687, 0.042260512709617615, 0.0593673512339592, -0.013400958850979805, -0.013943775556981564, -0.027126982808113098, 0.004104991443455219, -0.03364824131131172, 0.061484966427087784, 0.05320975184440613, -0.08124128729104996, 0.05040320008993149, 0.04410267621278763, -0.03598344698548317, 0.017878156155347824, -0.008531754836440086, -0.055507563054561615, 0.0168584156781435, -0.01823558285832405, 0.03751259297132492, -0.03531065583229065, -0.05150856077671051, -0.0003685251867864281, -0.006224906537681818, 0.048452846705913544, 0.018872348591685295, 0.026734253391623497, -0.03202051296830177, -0.03586030378937721, 0.02265782654285431, -0.0021017412655055523, 0.020942004397511482, 0.022252678871154785, 0.03405863046646118, -0.0014108313480392098, -0.01753837801516056, 0.017598222941160202, 0.057206008583307266, -0.03653199225664139, -0.0028676888905465603, -0.0007728615310043097, 0.005585485137999058, 0.0049058361910283566, 0.06692136079072952, -0.021474266424775124, 0.01075589656829834, 0.038191020488739014, -0.03730933740735054, 0.03536481410264969, -0.043538860976696014, -0.011070878244936466, -0.029524916782975197, -0.006956583354622126, -0.016125787049531937, 0.04801303148269653, -0.007461526431143284, -0.03778446465730667, -0.00977606326341629, -0.05998871102929115, 0.01240465510636568, 0.02493540197610855, -0.02721187099814415, -0.009102694690227509, -0.012362118810415268, -0.0175927821546793, -0.01550324633717537, -0.012822081334888935, 0.02574613317847252, 0.022641126066446304, -0.016882766038179398, -0.007236667443066835, -0.03132973611354828, -0.05316244438290596, 0.026492122560739517, 0.07414160668849945, -0.037769343703985214, -0.03360746428370476, 0.007162704598158598, -0.009867759421467781, 0.030502796173095703, 0.024944359436631203, 0.0350472629070282, 0.018456341698765755, -0.025915546342730522, -0.012055722065269947, 0.007213617209345102, 0.017498068511486053, 0.023522090166807175, -0.008359485305845737, 0.014548699371516705, 0.01525846030563116, 0.008857429027557373, -0.016745729371905327, -0.0032172943465411663, 0.01721983030438423, -0.009812590666115284, -0.008818154223263264, -0.059485044330358505, -0.021558385342359543, 0.004702369682490826, 0.02849196456372738, -0.016097355633974075, 0.05093323439359665, 0.01087033562362194, 0.007483807858079672, 0.01374420803040266, 0.01030956394970417, -0.09010494500398636, -0.016670705750584602, -0.02403148263692856, -0.001606956822797656, 0.035718753933906555, -0.04093140363693237, -0.0414779856801033, 0.003474731231108308, 0.0202252846211195, 0.007800837978720665, 0.015149001032114029, -0.009900175034999847, -0.048066552728414536, -0.027544749900698662, 0.058307625353336334, 0.05493176355957985, 0.07319263368844986, -0.0027459014672785997, 0.006966785993427038, 0.08847440034151077, 0.07143829762935638, 0.002594202058389783, 0.0022252483759075403, 0.003393840277567506, 0.0014997972175478935, 0.007340571843087673, 0.00913151539862156, -0.023911427706480026, 0.002221625065430999, 0.03484165668487549, 0.006327471695840359, 0.029657810926437378, 0.02737434394657612, -0.02932390384376049, 0.0005192741518840194, 0.012676176615059376, -0.020018551498651505, 0.020246852189302444, 0.01343266386538744, 0.06945625692605972, -0.09359235316514969, -0.012852460145950317, -0.0013197700027376413, 0.031967319548130035, 0.05393998697400093, 0.08623220771551132, -0.060816455632448196, -0.005454978905618191, -0.004737988580018282, 0.010220644064247608, -0.004328414332121611, 0.0075034829787909985, 0.06917213648557663, 0.003914931323379278, -0.03218730911612511, 0.008188220672309399, 0.019775133579969406, 0.021480444818735123, 0.09641530364751816, 0.03969729319214821, 0.05238773673772812, -0.054309360682964325, -0.053298208862543106, -0.06630945950746536, 0.035328034311532974, -0.02010324038565159, 0.00748808728531003, -0.019121451303362846, 0.019790129736065865, -0.02960217371582985, 0.0151102589443326, -0.01603083685040474, 0.04448306933045387, -0.038398608565330505, -0.018642356619238853, -0.013590921647846699, -0.021060051396489143, -0.01433288399130106, 0.008626220747828484, 0.07013116031885147, -0.005259048659354448, -0.03434747830033302, -0.02391267754137516, 0.07674979418516159, 0.03439929708838463, 0.03194412589073181, -0.0009525692439638078, 0.024759212508797646, -0.0106736458837986, 0.06640107184648514, 0.024239279329776764, 0.02920496091246605, -0.028181569650769234, -0.023886345326900482, -0.003684115130454302, -0.0486324243247509, 0.015968341380357742, 0.0696687251329422, 0.008719763718545437, 0.05885184183716774, 0.02614978887140751, -0.002282149391248822, 0.021749000996351242, -0.006471035536378622, -0.026426345109939575, -0.03175948187708855, -0.07251287251710892, -0.048455215990543365, 0.049823034554719925, -0.08669071644544601, -0.04300191253423691, 0.003968361299484968, 0.01850733533501625, 0.05638306587934494, -0.006088278256356716, -0.03381618112325668, 0.036953721195459366, -0.0025000276509672403, 0.056115493178367615, -0.0067008924670517445, 0.0025004500057548285, -0.000795774394646287, 0.0018707712879404426, -0.05409854277968407, 0.00576277868822217, -0.04529155045747757, -0.062033992260694504, 0.040681641548871994, -0.03763865306973457, -0.010774009861052036, 0.04005745053291321, -0.04251312091946602, -0.027976125478744507, -0.02434081770479679, 0.004661739803850651, -0.0676010400056839, -0.013166707940399647, 0.03595155104994774, 0.058780353516340256, -0.00959074217826128, 0.0004109205328859389, -0.08828148245811462, 0.059098243713378906, 0.050313305109739304, -0.02270047925412655, -0.023943539708852768, -0.013526364229619503, 0.014774552546441555, 0.00095880136359483, 0.002964854007586837, -0.029238644987344742, -0.02630009315907955, -0.024440938606858253, 0.01178788673132658, -0.0032362639904022217, -0.015792328864336014, -0.028195055201649666, -0.03456846997141838, 0.03292889893054962, -0.0033026402816176414, 0.0002843879337888211, 0.059879839420318604, -0.04108784347772598, 0.01610223390161991, 0.03500882163643837, -0.020343545824289322, -0.005968176294118166, 0.005933261942118406, -0.07105488330125809, -0.007879647426307201, -0.07458782196044922, -0.04007600247859955, -0.01270411629229784, 0.016093553975224495, 0.0044067841954529285, 0.02022942155599594, -0.022388938814401627, 0.003536798758432269, -0.006112690549343824, 0.002480093389749527, -0.013570097275078297, -0.0037673828192055225, -0.020682096481323242, 0.012977599166333675, -0.0009866952896118164, -0.0016580044757574797, -0.030072646215558052, 0.0448291152715683, 0.032835952937603, -0.023184021934866905, -0.015366725623607635, -0.013297701254487038, -0.025444746017456055, 0.022517496719956398, -0.010525299236178398, -0.04201054945588112, -0.07798873633146286, -0.0016958541236817837, 0.004902257118374109, 0.030552977696061134, -0.002731588901951909, 0.017946965992450714, -0.04745452478528023, -0.010501217097043991, 0.055548619478940964, 0.054968513548374176, -0.008265938609838486, 0.02569761499762535, -0.0265275277197361, 0.045163027942180634, 0.03649991378188133, 0.011343163438141346, -0.03103656694293022, 0.05759907513856888, -0.011819942854344845, 0.04521813988685608, -0.019038887694478035, 0.0071534099988639355, -0.03366684541106224, -0.004851918667554855, -0.004684809595346451, -0.02359994500875473, 0.006764003075659275, 0.03730325400829315, 0.008620982058346272, -0.05255728214979172, 0.011243163608014584, 0.008363286964595318, 0.04214112088084221, -0.050502002239227295, 0.03311144560575485, -0.09547837823629379, -0.02051820419728756, 0.040080826729536057, 0.00043320399709045887, -0.02025090530514717, -0.01042998768389225, -0.015594413504004478, 0.004530890379101038, -0.02020351216197014, -0.002576566534116864, -0.0343933142721653, 0.0038870251737535, -0.0022682989947497845, -0.024573305621743202, 0.04511360079050064, 0.01852814294397831, 0.06651229411363602, -0.0436166450381279, 0.04573671519756317, 0.052817270159721375, -0.06541839241981506, 0.019004518166184425, -0.021425219252705574, -0.05235530063509941, 0.06509962677955627, -0.018190408125519753, -0.0872720405459404, -0.04603768140077591, 0.034270502626895905, -0.028407519683241844, -0.04639759287238121, -0.012207417748868465, 0.009987118653953075, -0.003755514742806554, -0.017188822850584984, -0.010773733258247375, -0.07867744565010071, -0.02267753891646862, 0.008949067443609238, 0.0247748252004385, -0.00022183799592312425, 0.00187829346396029, 0.0040367366746068, 0.0050281030125916, -0.000432629109127447, 0.08277720957994461, 0.06411131471395493, 0.006514275912195444, 0.022114641964435577, -4.7227567847585306e-05, -0.02967495284974575, 0.03527049347758293, -0.02284185215830803, -0.024746118113398552, 0.04625890776515007, -0.02403164654970169, -0.0028613756876438856, -0.04784679040312767, -0.03762797638773918, -0.02592344395816326, 0.02013106271624565, 0.0013015246950089931, -0.0026706107892096043, -0.021581165492534637, 0.032494690269231796, -0.0020923479460179806, -0.04341508448123932, -0.010732855647802353, -0.03939023241400719, 0.04009634256362915, 0.03936009481549263, 0.011550236493349075, -0.08402147889137268, -0.021285351365804672, 0.04879337176680565, -0.020444106310606003, -0.01262891199439764, 0.07764393836259842, -0.011605747044086456, -0.01118506584316492, 0.007341193500906229, 0.04991782084107399, 0.09183666855096817, 0.013707603327929974, 0.003041783580556512, -0.06033429875969887, -0.027428634464740753, -0.006611375603824854, 0.038715001195669174, 0.036283548921346664, -0.07758811116218567, 0.004315108992159367, -0.018478428944945335, 0.009504629299044609, 0.013021585531532764, -0.01536150835454464, 0.008590510115027428, -0.057258058339357376, 0.03776419535279274, 0.0179420355707407, -0.0030345141422003508, -0.02103487029671669, 0.01193779893219471, 0.008804796263575554, -0.025849735364317894, -0.03883868455886841, -0.04284774139523506, -0.019840601831674576, 0.007850023917853832, 0.019834047183394432, 0.0024500470608472824, 0.04544375464320183, 0.028934922069311142, -0.04422449320554733, 0.01719420589506626, 0.03489740192890167, 0.011843658983707428, 0.00019498325127642602, -0.02494777925312519, -0.0345609188079834, -0.056174296885728836, 0.007085337769240141, -0.007491451222449541, 0.016102168709039688, 0.013181081041693687, 0.03859405964612961, 0.06383322179317474, -0.010785223916172981, 0.025129983201622963, -0.04688799008727074, 0.033756375312805176, 0.04123861715197563, -0.03643007576465607, -0.009038388729095459, 0.0035998281091451645, 0.05489146336913109]' SELECT Cars = VECTOR_DISTANCE('cosine',@BlueCar,@WhiteCar) ,WhiteVehicles = VECTOR_DISTANCE('cosine',@WhiteBus,@WhiteCar) ,BlueCarVsBus = VECTOR_DISTANCE('cosine',@BlueCar,@WhiteBus) ,KingVsQueen = VECTOR_DISTANCE('cosine',@QueenPlane,@KingCar) ,KingVsCar = VECTOR_DISTANCE('cosine',@BlueCar,@KingCar) ,QueenVsCar = VECTOR_DISTANCE('cosine',@QueenPlane,@BlueCar) |
I took each text from our previous example, entered it into the Hugging Face Space, and copied the resulting embeddings back into the script in their respective variables. Additionally, I updated the vector size to vector(768), as we now have embeddings of that size. (Note: If you use embeddings of an incorrect size, SQL Server will raise an exception with a clear error message.)
Running the query, the result is that:

Note that the result changed slightly, but we can still make the same interpretation:
- Both cars ended up with a distance of 0.34, but the bus-to-car comparison remained higher.
- The comparison between king and queen increased, most likely due to the heavier weighting for vehicles and other words involved in Nomic’s model.
- King vs. Car decreased slightly, compared to King vs Queen, probably because it has more relation to the car.
- Queen vs. Car remains much higher than the others, as most of the concepts involved are quite different.
In practice, most of the time you won’t use the absolute values of these comparisons, but rather as a sorting criterion, for example. Let’s demonstrate this now by inserting all these embeddings into a table and then performing searches:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
drop table if exists texts; create table texts ( text varchar(500) not null ,embeddings vector(768) ) insert into texts values ('A blue car' ,'[-0.04458834230899811, -0.009829321876168251, -0.1071217805147171, 0.010725616477429867, 0.04995579272508621, 0.015441863797605038, -0.023975618183612823, 0.04064883291721344, -0.06193269044160843, -0.041421011090278625, 0.02388092130422592, 0.009038489311933517, 0.05676793307065964, 0.024577230215072632, 0.06226604804396629, -0.028421515598893166, -0.022054390981793404, -0.04445527121424675, -0.018383268266916275, -0.016402453184127808, 0.03631089627742767, -0.004198375158011913, -0.06958834826946259, 0.012117850594222546, 0.11983727663755417, 0.022704364731907845, 0.005344585981220007, -0.004786789417266846, -0.004828524775803089, 0.0031563241500407457, 0.03057517670094967, -0.01972569338977337, 0.023008687421679497, -0.06444232910871506, -0.03278486803174019, -0.06806060671806335, 0.054954931139945984, 0.03692738339304924, 0.024324459955096245, 0.019910648465156555, 0.03970235958695412, 0.04239603132009506, 0.020277298986911774, -0.038499604910612106, 0.045184530317783356, -0.04427910968661308, 0.013413416221737862, 0.008086941204965115, 0.0018591610714793205, 0.023727143183350563, -0.03441818058490753, 0.06187102198600769, -0.005788900423794985, -0.08753295987844467, 0.05097357928752899, 0.018424002453684807, 0.0642593577504158, -0.02466471865773201, -0.027755195274949074, -0.005679564084857702, 0.05021066963672638, 0.0684981420636177, 0.01535304170101881, 0.11579055339097977, 0.03215054050087929, -0.06288453191518784, -0.005609558429569006, 0.04544017091393471, 0.019825486466288567, -0.025379003956913948, 0.04727477580308914, -0.015504471957683563, 0.014745011925697327, 0.0002574832469690591, -0.01185810286551714, -0.01782406121492386, -0.05240254104137421, -0.01448904536664486, 0.07034696638584137, 0.015214410610496998, 0.021693026646971703, 0.042933158576488495, -0.008897911757230759, 0.028549902141094208, 0.06793371587991714, 0.04290949925780296, 0.018871232867240906, 0.023011019453406334, 0.009785083122551441, -0.004792643710970879, 0.04373989254236221, 0.003911094274371862, 0.030968867242336273, 0.0011366988765075803, -0.02094477228820324, -0.04180396348237991, -0.05376134812831879, 0.05762380734086037, -0.0791977271437645, -0.0017393478192389011, -0.05638999864459038, -0.013378458097577095, -0.03219909593462944, 0.02105892263352871, 0.08798985183238983, 0.05806451663374901, -0.025558721274137497, 0.02340591698884964, -0.033250775188207626, -0.05183858424425125, 0.007134871557354927, 0.021206513047218323, -0.00581371271982789, 0.007223502267152071, -0.02949046902358532, -0.013208393007516861, -0.00028520607156679034, -0.0410267673432827, 0.015350030735135078, 0.03721786290407181, 0.020713308826088905, 0.024941543117165565, 0.021492525935173035, -0.011716942302882671, 0.031691160053014755, 0.010888774879276752, -0.06948430091142654, 0.009628682397305965, -0.05074786767363548, -0.007150833494961262, -0.05531947687268257, -0.011956772767007351, 0.04409152269363403, -0.01744137890636921, 0.04083341732621193, 0.08218090236186981, 0.01675485074520111, -0.012431482784450054, 0.008827713318169117, 0.04506300762295723, 0.043751273304224014, 0.04307150840759277, 0.035565514117479324, 0.019312532618641853, -0.02739933505654335, -0.0674905925989151, -0.0014278371818363667, -0.010763842612504959, -0.04960747808218002, -0.04064032435417175, -0.02317170798778534, -0.02865341678261757, 0.021950285881757736, 0.04003581404685974, 0.02245517075061798, -0.03190750256180763, 0.03779936581850052, -0.0013709962368011475, 0.001240366604179144, 0.04703512787818909, 0.053498681634664536, -0.01866505853831768, -0.013270286843180656, -0.006980372592806816, -0.04191618040204048, -0.04824957996606827, -0.017657864838838577, 0.04011602699756622, 0.025559796020388603, 0.02767942100763321, -0.0718347504734993, -0.08276104927062988, -0.05908765643835068, -0.011533872224390507, 0.015494907274842262, -0.04670652747154236, 0.027652207762002945, 0.005854567978531122, 0.015494025312364101, -0.04215772822499275, 0.010043219663202763, -0.06292741745710373, 0.020513584837317467, 0.059602610766887665, -0.021126244217157364, 0.0009306254214607179, -0.01791425608098507, -0.030881397426128387, -0.07569355517625809, -0.013771002180874348, 0.0031389021314680576, 0.021203499287366867, -0.017458902671933174, -0.052497684955596924, -0.031171932816505432, -0.06560375541448593, 0.014586575329303741, 0.039773695170879364, 0.07964104413986206, -0.010418347083032131, 0.013054021634161472, -0.010862634517252445, -0.004336628597229719, 0.0034660515375435352, 0.012325860559940338, 0.0310186930000782, 0.02064221352338791, 0.03906438127160072, -0.0077979546040296555, -0.006689106114208698, 0.10142883658409119, 0.017406607046723366, -0.03187423571944237, -0.00280552776530385, 0.013753283768892288, -0.0024886459577828646, -0.029179152101278305, -0.00212482875213027, 0.01576637662947178, 0.045185357332229614, 0.05225301906466484, 0.026646187528967857, 0.034515004605054855, -0.06602824479341507, 0.0035212566144764423, 0.04593885317444801, -0.010273647494614124, -0.013297653757035732, 0.029531676322221756, 0.01459990069270134, -0.007203109562397003, -0.022152436897158623, 0.03449398651719093, -0.01600799709558487, 0.03527052700519562, 0.030825115740299225, 0.02414792962372303, 0.03218958154320717, -0.02445984072983265, 0.007938235998153687, -0.045423850417137146, 0.021618714556097984, -0.02194220758974552, -0.0017799666384235024, -0.045254215598106384, -0.004959322977811098, -0.044588856399059296, -0.008886345662176609, -0.007017726078629494, 0.02420138008892536, 0.01876715011894703, 0.013606566935777664, -0.0059608942829072475, -0.007155479863286018, 0.03559144213795662, -0.03662549704313278, -0.04128691554069519, -0.020289221778512, 0.008485700003802776, -0.01792328804731369, 0.01795504428446293, -0.053791407495737076, 0.05782441422343254, -0.056689273566007614, -0.034365542232990265, 0.030215471982955933, -0.034064363688230515, -0.05988907068967819, 0.05897688865661621, -0.07926946878433228, -0.013671633787453175, 0.02194714918732643, -0.04311457276344299, -0.004337904043495655, 0.05318035930395126, -0.017606036737561226, 0.008382213301956654, -0.03558102995157242, -0.03229406103491783, 0.034710466861724854, -0.016026755794882774, 0.01910104788839817, 0.0009287690045312047, -0.0013773366808891296, -0.010698087513446808, 0.008250868879258633, -0.001623785705305636, 0.04251360148191452, 0.03828693553805351, 0.024657947942614555, -0.020421013236045837, 0.03164256736636162, 0.02966219000518322, 0.07138805836439133, 0.005132843274623156, 0.05660286173224449, 0.045677538961172104, 0.014048275537788868, 0.03228544071316719, -0.0672767385840416, 0.026414306834340096, -0.049091946333646774, 0.03557564690709114, -0.01467729452997446, 0.04236193001270294, -0.0169052854180336, 0.03050827421247959, 0.05765344575047493, 0.04828033223748207, 0.02993435226380825, -0.03882436826825142, 0.003034873167052865, -0.006438660901039839, 0.03276243805885315, -0.08892108500003815, 0.05529256537556648, -0.009765543043613434, -0.01522672176361084, 0.04431522265076637, 0.025616057217121124, 0.04466290771961212, -0.05384442210197449, 0.035242948681116104, -0.010088742710649967, 0.029519852250814438, 0.0229637548327446, -0.006506725214421749, 0.01721988618373871, 0.0391397699713707, -0.05535484850406647, -0.023381533101201057, 0.04861003905534744, 0.01067870482802391, -0.023561011999845505, 0.009837557561695576, -0.026080848649144173, -0.027888892218470573, -0.017998553812503815, -0.03774026408791542, 0.035249508917331696, 0.10900387167930603, -0.04481406509876251, 0.06988035887479782, -0.08475394546985626, -0.008044935762882233, 0.0037447696086019278, 0.03613508120179176, 0.0038100893143564463, 0.0232907272875309, -0.018171973526477814, -0.011069288477301598, -0.012372579425573349, -0.0026245738845318556, 0.0159969050437212, -0.046687982976436615, -0.005576498806476593, -0.031446345150470734, -0.008139989338815212, -0.004630087874829769, 0.03800315037369728, -0.0076899453997612, -0.04177406430244446, -0.0011113722575828433, 0.02075171284377575, -0.007061907090246677, -0.00457674078643322, -0.018312174826860428, -0.015328168869018555, 0.03769223019480705, -0.025444528087973595, -0.014578772708773613, 0.0028800361324101686, 0.007001400459557772, 0.04080093652009964, 0.04084431752562523, 0.02959582954645157, 0.010196713730692863, -0.08240749686956406, -0.023550838232040405, -0.013527732342481613, -0.0046657840721309185, 0.01683313213288784, 0.018105538561940193, 0.04947469383478165, 0.009627943858504295, -0.00787968747317791, -0.03463498502969742, -0.00952286459505558, -0.027184920385479927, -0.00010891148122027516, -0.020475665107369423, -0.04363911226391792, -0.043618664145469666, -0.005125652998685837, 0.008717392571270466, -0.03713659942150116, 0.07424020022153854, -0.04220863804221153, -0.03437221422791481, -0.013623720034956932, -0.08492084592580795, 0.03012186847627163, -0.000183523865416646, 0.0016044233925640583, -0.01082699652761221, 0.04065268486738205, 0.0041084871627390385, -0.07984661310911179, 0.07615739852190018, 0.04354507476091385, 0.03144824877381325, 0.04032951593399048, -0.0006487745558843017, -0.08480391651391983, 0.05250420421361923, 0.006078385282307863, 0.017964694648981094, 0.021382901817560196, 0.016195058822631836, 0.034203752875328064, 0.04542602598667145, 0.03762105107307434, 0.023206880316138268, 0.02269216999411583, 0.011191658675670624, -0.03162073716521263, -0.004136469215154648, 0.050807420164346695, -0.007415789645165205, -0.08906275033950806, 0.0005250597605481744, -0.03927477076649666, -0.06583748757839203, 0.01227788906544447, -0.058591220527887344, 0.015749415382742882, -0.01901897042989731, 0.013352006673812866, 0.03541041910648346, 0.03136182948946953, 0.0011963006108999252, -0.058109257370233536, 0.0075218817219138145, -0.022862421348690987, 0.050932079553604126, 0.05321560800075531, 0.03908088058233261, -0.04156560078263283, -0.039304621517658234, 0.01888279803097248, -0.01838444173336029, 0.008581935428082943, 0.008577101863920689, 0.09941866248846054, 0.03172394633293152, -0.016049740836024284, -0.0630931630730629, -0.022660337388515472, 0.030857818201184273, 0.056882552802562714, 0.06405030936002731, -0.021415363997220993, -0.02394810877740383, 0.023284198716282845, -0.001377528766170144, -0.06713501363992691, 0.026300892233848572, -0.0029329725075513124, 0.02913600392639637, 0.059909041970968246, -0.04377346113324165, 0.018109086900949478, 0.05821564793586731, -0.028245529159903526, -0.028598768636584282, 0.03718763217329979, 9.1334200988058e-05, -0.01507672667503357, 0.041492391377687454, 0.034136053174734116, 0.019847366958856583, -0.004361756145954132, -0.018782196566462517, -0.05312579870223999, -0.012427203357219696, 0.05985007807612419, 0.024106523022055626, 0.005240618716925383, 0.027749046683311462, -0.00847015343606472, 0.039485834538936615, -0.011582993902266026, 0.005015389062464237, -0.017159758135676384, 0.009834924712777138, -0.02104646898806095, 0.000333851610776037, -0.018587281927466393, 0.02018999122083187, -0.01813613995909691, -0.00655454583466053, 0.036018501967191696, 0.012484434992074966, 0.009627913124859333, 0.004255648702383041, 0.01408689096570015, -0.0022100619971752167, -0.03803907334804535, -0.03450121358036995, 0.07098370790481567, 0.005612822249531746, -0.008791891857981682, 0.0763261616230011, -0.017805201932787895, -0.006088851951062679, -0.014006400480866432, -0.01839282177388668, 0.011536906473338604, -9.187000978272408e-05, 0.04383537545800209, 0.01657944731414318, 0.005993365775793791, -0.056950874626636505, -0.011222431436181068, -0.02558913826942444, 0.02300037257373333, 0.026649868115782738, -0.09589041769504547, 0.010007309727370739, -0.016294756904244423, 0.036312468349933624, 0.010488925501704216, -0.007384163327515125, -0.01630517654120922, -0.031917303800582886, 0.01985437236726284, -0.013202645815908909, 0.031113244593143463, 0.0007531677256338298, 0.0395992211997509, 0.01619206741452217, -0.03746408596634865, 0.0006403798470273614, 0.007145638111978769, 0.016966165974736214, 0.011510501615703106, -0.07173535972833633, -0.001270035281777382, 0.04151802882552147, -0.03872992843389511, 0.0054492163471877575, -0.06005703657865524, 0.015165703371167183, -0.0026355574373155832, 0.02812781184911728, -0.040573202073574066, -0.01786266453564167, -0.03182343393564224, -0.018672503530979156, -0.0076803481206297874, 0.002477959729731083, -0.03744545206427574, 0.07461670786142349, 0.015338209457695484, 0.04671023041009903, -0.03625244274735451, -0.019696548581123352, 0.0485449880361557, 0.04302943870425224, 0.03326919674873352, 0.05340471491217613, -0.014243046753108501, 0.0052040256559848785, -0.014084364287555218, 0.012719972059130669, -0.05518585070967674, 0.015577088110148907, 0.02665451541543007, -0.03588317334651947, -0.0031324599403887987, 0.02835208736360073, -0.0179744865745306, 0.0013478054897859693, 0.04923906922340393, -0.04796208068728447, 0.03368159383535385, -0.0170985646545887, -0.03967010974884033, 0.01676964946091175, -0.04562560096383095, -0.014340144582092762, -0.017994705587625504, -0.049109481275081635, -0.013166957534849644, 0.008508670143783092, -0.00793615821748972, -0.04516813904047012, -0.053426146507263184, -0.01563597284257412, -0.022686179727315903, 0.006693217903375626, -0.042636141180992126, -0.02670179307460785, -0.026644675061106682, -0.045979585498571396, 0.014035256579518318, 0.012620972469449043, -0.0004200899275019765, 0.009021283127367496, -0.045996714383363724, 0.025143921375274658, 0.0005889218300580978, -0.014238595962524414, 0.001405593124218285, 0.025856880471110344, 0.030948085710406303, 0.04509618133306503, -0.028244081884622574, 0.002345679560676217, -0.06277463585138321, 0.009890945628285408, -0.039629943668842316, 0.060927506536245346, -0.05436713248491287, 0.011711291037499905, -0.042613085359334946, -0.05946489796042442, -0.048017822206020355, 0.038083869963884354, 0.037365399301052094, -0.004685573745518923, 0.006939896382391453, -0.0446152463555336, -0.04937287047505379, -0.01914559118449688, -0.00998601969331503, -0.02829478494822979, 0.015269330702722073, 0.04307304695248604, 0.011615797877311707, -0.014019818045198917, -0.004207888152450323, -0.013406096026301384, 0.0260293111205101, 0.011236384510993958, -0.035698067396879196, 0.03529798239469528, 0.015200851485133171, 0.041870664805173874, -0.022969925776124, 0.028679613023996353, 0.03459436446428299, 0.004514069762080908, -0.034869126975536346, -0.010406107641756535, -0.009594103321433067, 0.002175095258280635, -0.0335761159658432, -0.01719016209244728, -0.02812047302722931, -0.01164099108427763, 0.029904399067163467, -0.0728212296962738, 0.006694641429930925, 0.05029255524277687, -0.008469502441585064, 0.0003439775318838656, -0.05687438324093819, -0.0631667897105217, 0.025388125330209732, -0.0533159039914608, 0.030535930767655373, -0.03837808966636658, -0.037061844021081924, -0.0005907514714635909, 0.018075140193104744, 0.0004641663399524987, 0.05778947472572327, 0.0779535248875618, -0.009621520526707172, 0.03850407525897026, -0.02038906142115593, -0.03411258012056351, -0.0030089705251157284, -0.007862337864935398, -0.038158249109983444, 0.011490199714899063, -0.028851917013525963, -0.009170010685920715, -0.1108689159154892, 0.002080589300021529, -0.06527896970510483, -0.04045668989419937, -0.039408981800079346, 0.015382892452180386, -0.01328832283616066, -0.022550228983163834, -0.009678739123046398, -0.02530931867659092, 0.034438736736774445, -0.026507239788770676, 0.015273204073309898, 0.03182642161846161, 0.06187283247709274, -0.03433910012245178, -0.03867434710264206, -0.0025324926245957613, -0.03466170281171799, -0.054944537580013275, 0.03976785019040108, -0.06810741126537323, 0.020119652152061462, -0.003124671522527933, 0.02616346813738346, -0.001620466005988419, 0.006080920342355967, 0.04139496013522148, -0.022103674709796906, -0.013027285225689411, 0.041742026805877686, 0.06539066880941391, -0.019183265045285225, 0.0072784931398928165, -0.05994619429111481, -0.025857316330075264, -0.06124955788254738, 0.02660318650305271, -0.06940257549285889, -0.028727496042847633, -0.03020239993929863, -0.009900989942252636, 0.044294003397226334, 0.013945786282420158, 0.042010899633169174, -0.03985859453678131, -0.07205677777528763, -0.03511785715818405, -0.008442526683211327, 0.0033362647518515587, -0.008233805187046528, -0.04114651307463646, -0.056525059044361115, 0.03839297220110893, 0.03941555321216583, 0.01640142686665058, 0.015072820708155632, -0.00801049917936325, 0.04846164956688881, 0.09000784903764725, 0.011643040925264359, 0.009907384403049946, 0.009495485574007034, -0.02457716502249241, -0.01612655259668827, -0.005796502809971571, 0.00931460689753294, -0.018077122047543526, 0.0036246587987989187, 0.03422935679554939, 0.008152666501700878, 0.01341637410223484, 0.04989401623606682, -0.00456588389351964, -0.022077040746808052, -0.014214788563549519, -0.0026837908662855625, -0.09649178385734558, -0.006170217413455248]') ,('A white bus' ,'[-0.06753987073898315, 0.07278157770633698, -0.16209536790847778, -0.03427405282855034, 0.059884246438741684, 0.03777429834008217, 0.04805590957403183, 0.06330639123916626, 0.0013740735594183207, 0.037285130470991135, 0.034625161439180374, 0.02807888388633728, 0.005724778864532709, -0.015320872887969017, 0.0006015371182002127, -0.05546802282333374, 0.03255333751440048, -0.07278770953416824, -0.01803540252149105, 0.02775910310447216, 0.022438742220401764, 0.01651052013039589, -0.07111023366451263, 0.05056516453623772, 0.12490788847208023, 0.04730222746729851, -0.02558787725865841, 0.02021860145032406, 0.027999714016914368, 0.0016590554732829332, 0.020401258021593094, -0.046842802315950394, 0.03908110782504082, -0.021801725029945374, -0.01823713630437851, -0.049415700137615204, 0.013592363335192204, -0.05734631419181824, 0.034646037966012955, 0.05381272733211517, 0.023852409794926643, -0.007062137592583895, -0.012680746614933014, 0.01586841233074665, 0.030323611572384834, -0.020290547981858253, -0.030928965657949448, -0.025266055017709732, 0.022992825135588646, 0.07110389322042465, -0.008829225786030293, -0.020472854375839233, -0.03709211200475693, -0.027930958196520805, 0.037873607128858566, -0.06502632051706314, 0.05565175786614418, -0.00949242152273655, -0.0268830768764019, 0.07220879942178726, -0.007129456382244825, -0.016455309465527534, 0.01270582340657711, 0.05786964297294617, 0.01951593905687332, -0.06139933317899704, -0.025385914370417595, 0.11720259487628937, 0.003314809873700142, -0.01399045716971159, 0.042422592639923096, -0.0026398140471428633, 0.03154914826154709, 0.040785130113363266, 0.044427379965782166, 0.04090290516614914, 0.02223508432507515, -0.03245113044977188, 0.010845126584172249, -0.012934555299580097, 0.026572134345769882, 0.0243513286113739, 0.04298821836709976, 0.06295352429151535, 0.02148522064089775, 0.0251179039478302, 0.009442930109798908, -0.033573418855667114, -0.09622170776128769, -0.0033251119311898947, 0.005363987293094397, 0.010275479406118393, 0.041716620326042175, 0.004539657849818468, -0.0165326576679945, -0.06448474526405334, -0.03357795253396034, 0.0011327677639201283, -0.042509887367486954, -0.06874965876340866, 0.044723592698574066, 0.031449757516384125, 0.027130942791700363, -0.04718969017267227, 0.019093431532382965, -0.021139338612556458, -0.016892246901988983, -0.06022575870156288, -0.060594819486141205, -0.02801678515970707, 0.002128286985680461, -0.020585065707564354, 0.006462740711867809, -0.055388811975717545, 0.03148769214749336, 0.06857883185148239, 0.06219728663563728, -0.05486880987882614, 0.05562739819288254, 0.015620740130543709, -0.00640681991353631, -0.018847718834877014, -0.04233672097325325, 0.044789720326662064, 0.012020831927657127, 0.01032610796391964, 0.007643215823918581, 0.03582453355193138, -0.0034806784242391586, -0.011811125092208385, -0.02844700776040554, -0.028272517025470734, 0.001826923107728362, -0.010596401058137417, 0.027004648000001907, 0.0507185235619545, -0.04681149125099182, -0.012483175843954086, -0.05343441292643547, 0.03387528285384178, -0.010971411131322384, 0.04591359943151474, 0.007331435102969408, 0.013547238893806934, -0.004284666385501623, -0.010278704576194286, 0.0058721802197396755, -0.02742108516395092, 0.012341071851551533, 0.058024633675813675, -0.025083083659410477, 0.011608975008130074, 0.0026038535870611668, 0.023073816671967506, 0.02586543932557106, -0.052216071635484695, 0.03018985502421856, 0.005576753988862038, 0.0027047337498515844, -0.03885068744421005, 0.06071760132908821, -0.012369439005851746, -0.015294978395104408, 0.014733134768903255, -0.018253983929753304, -0.04611120745539665, 0.008534821681678295, 0.006546329706907272, 0.04615360498428345, 0.01581859588623047, -0.06257878988981247, -0.08920854330062866, -0.018853727728128433, 0.03649149462580681, 0.006270451005548239, -0.0609319694340229, -0.02108457311987877, -0.005191299598664045, 0.02025851048529148, 0.013186526484787464, 0.016135388985276222, -0.04393143206834793, 0.026144227012991905, 0.020026234909892082, 0.007963729090988636, -0.01081851776689291, -0.031052667647600174, -0.026542475447058678, -0.08690182864665985, 0.0006196757312864065, -0.04287133365869522, 0.0416436642408371, 0.0013381780590862036, -0.013389253057539463, -0.031561486423015594, -0.01870056986808777, 0.060468584299087524, 0.00133947329595685, 0.028163133189082146, -0.051322322338819504, -0.03908231109380722, 0.017875945195555687, -0.02971956692636013, -0.0007504074601456523, -0.050515543669462204, 0.000861346663441509, -0.0033522476442158222, -0.017696678638458252, 0.009080146439373493, 0.05820843204855919, 0.031717319041490555, -0.043661974370479584, 0.025903934612870216, -0.005628982093185186, 0.007039457559585571, -0.005992755759507418, -0.021218182519078255, -0.031268827617168427, -0.009205924347043037, -0.01604309491813183, 0.03596428409218788, -0.01779867522418499, 0.004696986638009548, -0.04982787370681763, 0.005949023179709911, -0.025349289178848267, -0.058276694267988205, -0.02537562884390354, -0.033857718110084534, 0.037098828703165054, -0.015124295838177204, -0.055683936923742294, 0.06182606890797615, 0.04207181558012962, 0.014884171076118946, -0.01746087335050106, -0.014633736573159695, 0.034516841173172, 0.02433709427714348, 0.0024324199184775352, -0.010603511705994606, 0.0705065131187439, 0.019817117601633072, -0.05024820938706398, -0.021043702960014343, 0.009453725069761276, 0.049150317907333374, -0.057842835783958435, 0.007625953294336796, 0.08630435913801193, -0.037871088832616806, -0.009864158928394318, -0.009562668390572071, -0.029756179079413414, 0.03177317976951599, -0.04273594170808792, -0.030502893030643463, 0.009694283828139305, 0.038576964288949966, -0.04448121413588524, -0.004346917849034071, -0.05145706236362457, 0.035206884145736694, -0.01882917806506157, 0.05088075250387192, -0.006815358065068722, 0.02147829718887806, 0.04262840375304222, -0.0040156240575015545, -0.05585654824972153, 0.042436517775058746, 0.018471311777830124, -0.02962319180369377, 0.0034826037008315325, 0.01949373632669449, -0.018776051700115204, 0.013786676339805126, -0.04225412756204605, -0.05460185557603836, 0.023421265184879303, -0.029562467709183693, 0.011084084399044514, 0.03131186217069626, -0.05181024596095085, -0.020407071337103844, 0.023841723799705505, 0.02385186217725277, -0.015177031978964806, 0.04081428423523903, 0.050551582127809525, -0.008389999158680439, -0.002355684759095311, -0.020177388563752174, 0.015828249976038933, 0.06566629558801651, 0.04596942663192749, 0.08809691667556763, -0.04605526849627495, -0.031024547293782234, -0.050618261098861694, -0.027813736349344254, -0.02517940290272236, 0.07417648285627365, 0.001388336531817913, 0.009419579990208149, 0.008250155486166477, 0.040317896753549576, 0.015958629548549652, 0.01654982753098011, -0.008096314035356045, 0.0008468794403597713, -0.03850887343287468, -0.04964926466345787, 0.020847387611865997, -0.01715490035712719, 0.09056158363819122, -0.027910009026527405, -0.007961020804941654, 0.020347334444522858, 0.03080873191356659, -0.0028114987071603537, -0.04326989874243736, -0.004723593592643738, -0.041111018508672714, -0.011655200272798538, 0.017304418608546257, 0.018112177029252052, 0.014147255569696426, 0.033033791929483414, 0.015316272154450417, -0.03502308204770088, 0.04660641402006149, -0.04847220703959465, -0.045294225215911865, 0.03037858009338379, 0.02881024032831192, 0.007409506943076849, 0.04837045446038246, 0.03796312212944031, 0.009881503880023956, 0.03250554949045181, -0.015571756288409233, 0.028276043012738228, -0.03803853318095207, -0.02207818254828453, -0.04259709268808365, -0.05101951211690903, -0.011083797551691532, 0.02495579421520233, 0.03183741867542267, -0.00859034527093172, -0.046222392469644547, -0.010562313720583916, -0.026293920353055, -0.038540370762348175, -0.006437964271754026, -0.005668070167303085, 0.07591769099235535, 0.029979733750224113, 0.009723846800625324, -0.003297463059425354, 0.0006841842550784349, 0.006180438678711653, -0.031188981607556343, 0.05365268513560295, -0.03036755882203579, -0.028352295979857445, 0.010281777009367943, 0.036803677678108215, -0.054833706468343735, -0.058987703174352646, -0.018142245709896088, -0.028288748115301132, -0.0016879660543054342, 0.053815484046936035, 0.028537161648273468, -0.02045292779803276, 0.01555581670254469, -0.014261768199503422, 0.09104527533054352, 0.003212533425539732, -0.00542939780279994, -0.03019372932612896, 0.005066052544862032, 0.006336155813187361, -0.03226402401924133, -0.08206162601709366, -0.014224938116967678, 0.0008216122514568269, -0.0325152762234211, -0.005915377754718065, -0.05452781543135643, -0.03973351791501045, 0.024763228371739388, -0.005319707561284304, -0.03159883990883827, 0.07347212731838226, 0.0005946095334365964, -0.057645149528980255, 0.03203866630792618, -0.014742802828550339, -0.05661452189087868, -0.01846935972571373, -0.0017729733372107148, -0.030917011201381683, 0.009190528653562069, -0.03280362859368324, -0.05712028592824936, 0.030552269890904427, 0.017228344455361366, -0.0036361669190227985, 0.0017370725981891155, 0.03158096969127655, -0.08270958065986633, 0.001773934462107718, 0.05317965894937515, 0.06345227360725403, 0.044894106686115265, 0.00011983963486272842, 0.061563167721033096, 0.004971788264811039, 0.04524711146950722, -0.002070923801511526, -0.015296154655516148, 0.01154863927513361, 0.03984430432319641, -0.00488151703029871, 0.024720948189496994, 0.0005113083170726895, -0.051982346922159195, -0.027386890724301338, 0.03552022948861122, -0.003573949681594968, 0.015628235414624214, -0.03970710188150406, 0.029649939388036728, 0.0025562709197402, 0.0350564680993557, 0.04724739491939545, 0.011503390967845917, 0.06677839905023575, -0.07840978354215622, 0.00517209293320775, -0.014339487068355083, -0.01569281704723835, 0.1169191226363182, 0.04602055251598358, -0.054863303899765015, 0.020018408074975014, 0.03338490054011345, -0.02844120003283024, 0.005490866024047136, 0.028671491891145706, 0.03709106147289276, 0.04273125156760216, -0.05815018713474274, -0.028163807466626167, -0.006965890992432833, 0.014994538389146328, 0.04540498927235603, 0.006789571139961481, 0.015318549238145351, -0.02675335668027401, 0.020274560898542404, 0.02364703267812729, -0.008004088886082172, -0.02121025137603283, 0.017085369676351547, 0.03184352070093155, 0.014976712875068188, -0.04056580737233162, 0.09310349822044373, 0.05789435654878616, -0.024020779877901077, -0.005463139619678259, -0.004338595550507307, 0.007879815995693207, 0.0005037683295086026, 0.0027208970859646797, 0.06409285217523575, 0.035682179033756256, -0.03264859691262245, -0.022209106013178825, -0.10428011417388916, -0.013625557534396648, 0.01914127916097641, 0.017739098519086838, 0.002774209948256612, 0.072581447660923, -0.05675191432237625, 0.04219142720103264, 0.012327690608799458, 0.015973342582583427, 0.011041504330933094, -0.024931730702519417, -0.047498930245637894, -0.02797660045325756, 0.05218223109841347, 0.06247995048761368, 0.0021343098487704992, -0.022161489352583885, -0.03320058435201645, 0.002304140944033861, 0.03751151263713837, 0.004416126292198896, -0.010514483787119389, -0.0597001388669014, -0.012313068844377995, -0.04173269122838974, 0.02708452194929123, -0.025224000215530396, 0.039608657360076904, 0.02847933955490589, 0.013708004727959633, -0.03910323604941368, -0.04253985360264778, 0.014433164149522781, -0.017834648489952087, -0.0153739545494318, 0.06522169709205627, 0.006546597462147474, -0.0061237504705786705, -0.0046268124133348465, -0.017307164147496223, -0.08729765564203262, 0.0018608368700370193, 0.007351929787546396, -0.0707658976316452, 0.01669967919588089, 0.004470677115023136, 0.008067364804446697, -0.03809696435928345, -0.010610665194690228, -0.008711126632988453, -0.05565783008933067, -0.018506905063986778, 0.0010692557552829385, 0.025913750752806664, 0.006499735172837973, 0.023800283670425415, -0.028030794113874435, -0.024519188329577446, -0.03253740444779396, 0.022827228531241417, 0.05659250169992447, -0.007099783048033714, -0.008256364613771439, -0.018558423966169357, -0.05514315143227577, 0.001725656446069479, 0.016384849324822426, -0.043996356427669525, -0.007220359053462744, 0.006280114408582449, -0.008352242410182953, -0.02747071534395218, -0.038627903908491135, -0.031881723552942276, -0.015240038745105267, 0.013342151418328285, 0.015060605481266975, 0.019661173224449158, 0.043235715478658676, -0.005645459517836571, 0.009172569029033184, 0.02328011579811573, -0.004258895292878151, 0.08952473104000092, -0.006056841928511858, 0.0294154342263937, -0.0016935266321524978, -0.028927218168973923, -0.013200799934566021, -0.01251265686005354, 0.0251652542501688, -0.015304723754525185, 0.014577210880815983, -0.013671212829649448, -0.0015976913273334503, -0.04566016048192978, 0.04269027337431908, -0.08209864795207977, 0.0002853772311937064, -0.0008572086226195097, 0.0031105095986276865, 0.025979826226830482, -0.021532295271754265, -0.059189461171627045, 0.016151202842593193, -0.025056155398488045, -0.006753117311745882, 0.05364897474646568, 0.0040777637623250484, -0.0061232419684529305, -0.009824993088841438, 0.025961050763726234, -0.08680353313684464, 0.048555828630924225, -0.015963692218065262, 0.011444415897130966, 0.017180060967803, 0.028895121067762375, -0.019905049353837967, 0.014963589608669281, 0.024637015536427498, 0.019486939534544945, 0.02766919508576393, -0.05886966735124588, 0.014054518193006516, -0.018217964097857475, 0.054352667182683945, -0.019838163629174232, 0.013471657410264015, -0.013763543218374252, 0.03127364069223404, 0.003902768949046731, 0.04256775230169296, -0.001741849584504962, 0.004225486423820257, -0.008811019361019135, -0.03399436175823212, -0.06762699037790298, 0.019383730366826057, -0.01636437512934208, 0.025039980188012123, -0.01744813099503517, -0.039985284209251404, -0.038890134543180466, 0.008327769115567207, 0.051196783781051636, -0.03497340530157089, -0.0063784378580749035, -0.07196158915758133, -0.00980371329933405, -0.0031735312659293413, -0.045934535562992096, -0.01664154790341854, 0.008659163489937782, 0.003310081083327532, 0.0193018801510334, 0.013973046094179153, -0.011093582957983017, -0.014578337781131268, 0.04537070915102959, 0.02549872361123562, 0.0363854244351387, 0.06212664395570755, 0.004858638159930706, 0.022946465760469437, -0.03403050824999809, 0.0480194166302681, 0.05986025929450989, 0.008750534616410732, -0.0002539193956181407, -0.031050406396389008, 0.008433080278337002, 0.027967045083642006, -0.0028549169655889273, -0.009114200249314308, 0.020267769694328308, 0.00033897830871865153, 0.04366718977689743, -0.017015649005770683, 0.047096408903598785, 0.0408269502222538, 0.0102451266720891, 0.012041842564940453, -0.004115867894142866, -0.07664287090301514, -0.004904221277683973, 0.024779317900538445, 0.004054458346217871, 0.02146431989967823, -0.06415385007858276, 0.04672390595078468, -0.008083449676632881, -0.009188179858028889, 0.04886807128787041, 0.04752161726355553, -0.021688438951969147, -0.022505145519971848, -0.03744020685553551, -0.02826583757996559, 0.045957256108522415, 0.010127789340913296, -0.10806047916412354, -0.006765921134501696, -0.08768030256032944, 0.04915511608123779, 0.03279018774628639, 0.0581914447247982, -0.043251678347587585, 0.007841140031814575, -0.006397252436727285, 0.00788965541869402, -0.00831529963761568, -0.023653939366340637, 0.005402965936809778, -0.04570341855287552, 0.0687430277466774, -0.013676836155354977, 0.031744860112667084, 0.006173341069370508, 0.027030466124415398, -0.13293014466762543, -0.017127912491559982, -0.036360349506139755, -0.019678067415952682, -0.028810828924179077, -0.01692233793437481, 0.05046332627534866, 0.03126462921500206, 0.031733013689517975, 0.011390790343284607, -0.011204556562006474, 0.00783311203122139, -0.0332220196723938, -0.011878877878189087, 0.030698727816343307, 0.023203538730740547, 0.09429746866226196, 0.005632533226162195, -0.01673758216202259, -0.01587151363492012, -0.02759162336587906, 0.0018431456992402673, 0.047600068151950836, -0.03296460583806038, 0.02880772575736046, -0.011843028478324413, -0.028700359165668488, -0.03701167553663254, -0.021674100309610367, 0.006420746445655823, -0.02702731266617775, 0.03652995079755783, 0.012671167030930519, -0.014063430018723011, -0.05521361157298088, 0.013327027671039104, -0.020698094740509987, -0.014266624115407467, -0.02830195613205433, 0.056234173476696014, 0.018176188692450523, 0.030926434323191643, -0.008285448886454105, 0.01721600443124771, 0.019847260788083076, -0.0492742620408535, 0.028175534680485725, 0.0012406973401084542, -0.050912026315927505, 0.019240712746977806, -0.0014665749622508883, 0.012047656811773777, -0.03876950964331627, -0.04063274711370468, -0.0031636792700737715, 0.007616602815687656, -0.02202591672539711, -0.03131936118006706, 0.025557180866599083, 0.0010924411471933126, -0.0033318428322672844, -0.02428433485329151, -0.033836618065834045, -0.01627947948873043]') ,('A white car' ,'[-0.027773430570960045, 0.039530493319034576, -0.15529711544513702, -0.06483940780162811, 0.08179382234811783, 0.005144587717950344, 0.01604730822145939, 0.03616004064679146, -0.03606047108769417, 0.005966268479824066, 0.002488966565579176, -0.02230852283537388, 0.03572741150856018, 0.005476628430187702, 0.019177015870809555, -0.03336160629987717, -0.012474258430302143, -0.06511066108942032, 0.0036975096445530653, 0.0020012161694467068, 0.06503894925117493, -0.021393274888396263, -0.08108069002628326, 0.051751334220170975, 0.13936534523963928, 0.03819107636809349, -0.013152619823813438, 0.020679963752627373, 0.022207461297512054, 0.002099481876939535, 0.02557438425719738, -0.03460562974214554, 0.027615489438176155, -0.011107731610536575, -0.03066939488053322, -0.06711160391569138, -0.002971278503537178, 0.0042205448262393475, 0.06502994149923325, 0.004430792294442654, 0.0461251437664032, 0.060845643281936646, 0.045654065907001495, -0.004769631661474705, 0.056308161467313766, -0.017277440056204796, -0.02472555637359619, -0.005831120535731316, 0.02578652836382389, 0.10307715833187103, -0.03490029647946358, 0.008871945552527905, -0.03912888094782829, -0.028934085741639137, 0.05575602874159813, -0.06705574691295624, 0.0697217732667923, -0.013902364298701286, 0.0007203867426142097, 0.05481135472655296, -0.007029454689472914, 0.007207621354609728, 0.018590332940220833, 0.03952087089419365, 0.03271830454468727, -0.0911862775683403, -0.014161312952637672, 0.10503512620925903, 0.026799261569976807, -0.04751047119498253, 0.014055154286324978, 0.0012199064949527383, 0.051043733954429626, -0.01608838513493538, 0.0059188054874539375, -0.004681244492530823, -0.001646179473027587, -0.01501183956861496, 0.024565408006310463, -0.02657518908381462, 0.010322021320462227, 0.01764117181301117, -0.0038006564136594534, 0.04681064561009407, 0.05278037115931511, 0.005045303143560886, 0.010114289820194244, -0.003386974800378084, -0.07605766505002975, -0.008668974041938782, 0.013985457830131054, 0.01054626889526844, 0.023407476022839546, 0.0026678189169615507, -0.03467955067753792, -0.07410559058189392, -0.03041413240134716, 0.04466770589351654, -0.021052509546279907, -0.03521634265780449, 0.0018785366555675864, -0.012509000487625599, 0.007446016184985638, -0.02714746631681919, 0.0822729766368866, 0.024290958419442177, -0.023559685796499252, -0.03406428545713425, -0.02545512281358242, -0.053772952407598495, 0.0040767863392829895, -0.02330601215362549, -0.004276062827557325, -0.05556870996952057, 0.005027248058468103, 0.018119601532816887, 0.052679505199193954, -0.030492300167679787, 0.039178457111120224, 0.03957346826791763, -0.027976131066679955, 0.014980779029428959, -0.0365472137928009, 0.046495888382196426, 0.03050621971487999, 0.017151230946183205, -0.008321292698383331, 0.010661730542778969, 0.0008899497333914042, -0.02733827941119671, -0.03678666427731514, -0.010498625226318836, 0.009685153141617775, 0.000848871364723891, 0.02256251499056816, 0.03832452744245529, -0.043646279722452164, 0.024096639826893806, -0.004959227982908487, 0.05731809884309769, -0.0028014916460961103, 0.07948092371225357, 0.021112585440278053, 0.03164079040288925, -0.019241472706198692, -0.004902735352516174, -0.0003354843065608293, -0.05428734049201012, -0.03530002012848854, 0.005925981793552637, -0.0051035042852163315, -0.02573351003229618, -0.00020739190222229809, 0.03344808518886566, 0.023947570472955704, -0.05079716444015503, 0.0322427973151207, 0.006346975453197956, -0.016064895316958427, 0.0038716415874660015, 0.05706328898668289, -0.03700413554906845, 0.010818267241120338, 0.01074746623635292, -0.02598869986832142, -0.029115578159689903, -0.00734021607786417, 0.040200524032115936, -0.0015159383183345199, 0.019210120663046837, -0.06263264268636703, -0.06970933079719543, -0.030296670272946358, 0.029005737975239754, 0.012844682671129704, -0.08572977036237717, 0.013248587027192116, -0.049891628324985504, -0.0038896978367120028, -0.004222207702696323, 0.03758583217859268, -0.0456540510058403, 0.010669228620827198, 0.033183444291353226, -0.016018124297261238, -0.022202223539352417, -0.022110508754849434, -0.024183349683880806, -0.08356387913227081, 0.002667655237019062, -0.010997305624186993, 0.027708960697054863, 0.001885443227365613, -0.038668956607580185, -0.025672707706689835, -0.02784651704132557, 0.027879370376467705, 0.0023488181177526712, 0.0668116882443428, -0.06550885736942291, -0.04538606107234955, 0.013983835466206074, -0.013426242396235466, 0.020894819870591164, -0.050896041095256805, -0.007906179875135422, 0.020554427057504654, -0.024958845227956772, 0.011896222829818726, 0.034876029938459396, 0.04984516650438309, 0.009584280662238598, -0.005319838412106037, -0.014203113503754139, 0.041704099625349045, 0.008387855254113674, -0.017288602888584137, -0.018591634929180145, 0.0004638260288629681, -0.004363324958831072, 0.03048016130924225, -0.012959439307451248, -0.0014924645656719804, -0.0922374278306961, 0.02095058187842369, -0.008263000287115574, -0.04503054544329643, -0.03981397673487663, -0.02145944908261299, 0.03226232901215553, -0.014521680772304535, -0.0899043157696724, 0.05006248131394386, -0.026391515508294106, 0.002523422008380294, 0.012114155106246471, -0.0007252439972944558, 0.02188967913389206, 0.009783552959561348, 0.03807026892900467, -0.027235927060246468, 0.05244848132133484, 0.014699896797537804, -0.044633373618125916, -0.018959691748023033, 0.009003251791000366, -0.013684503734111786, -0.051871370524168015, -0.013432854786515236, 0.05990012735128403, -0.017678288742899895, 0.017841465771198273, -0.022804172709584236, -0.06357692182064056, 0.025349583476781845, -0.05347674712538719, -0.017862102016806602, 0.02295127883553505, 0.023657700046896935, -0.017154710367321968, -0.009502316825091839, -0.045715466141700745, 0.0241754911839962, -0.03528975695371628, 0.02851894311606884, 0.02399999275803566, 0.015945598483085632, 0.024689894169569016, 0.03582053259015083, -0.06214354187250137, 0.0549696683883667, 0.023737076669931412, -0.00712949363514781, -0.0011287899687886238, 0.010742384940385818, -0.009505472145974636, 0.015222209505736828, -0.03557730093598366, -0.023885900154709816, 0.022650573402643204, -0.02623302862048149, 0.021914571523666382, 0.03731624037027359, -0.04200403764843941, -0.05022255703806877, 0.008199484087526798, 0.002730773761868477, -0.001346322358585894, 0.014979378320276737, 0.034269142895936966, -0.051819588989019394, 0.012751715257763863, 0.013381628319621086, 0.020860346034169197, 0.03848076984286308, 0.044453807175159454, 0.0832463949918747, 0.002823432208970189, 0.012544452212750912, -0.04760191589593887, -0.029558835551142693, -0.014169400557875633, 0.04878780245780945, -0.007322394289076328, 0.02943658083677292, -0.03162470459938049, 0.06516122072935104, 0.0512373149394989, 0.006416393909603357, -0.010464726015925407, -0.014438359998166561, -0.04026077315211296, -0.04505997151136398, 0.00630289176478982, -0.059823017567396164, 0.051852501928806305, -0.0328875333070755, -0.0029921967070549726, 0.002612308831885457, 0.03707247972488403, 0.02908540517091751, -0.04822351410984993, 0.02827073447406292, -0.057838354259729385, 0.006509389262646437, 0.038704339414834976, 0.03234097361564636, -0.0199846513569355, 0.03576580435037613, -0.032251451164484024, -0.009812775067985058, 0.057328961789608, -0.0009439962450414896, -0.046049706637859344, 0.018133064731955528, 0.019275331869721413, -0.014299883507192135, 0.047512613236904144, 0.0044340090826153755, -0.006182413548231125, 0.036392197012901306, -0.03633897006511688, 0.06728233397006989, -0.05193628743290901, -0.004103780724108219, -0.02307821996510029, -0.016786903142929077, 0.0322498120367527, 0.03291497007012367, 0.023500192910432816, -0.03070637956261635, -0.03341635316610336, -0.025083409622311592, 0.0096941739320755, -0.046655505895614624, 0.002176682697609067, -0.03749026730656624, 0.054098788648843765, 0.011262014508247375, 0.005034781526774168, 0.009044354781508446, -0.024228526279330254, -0.004430497996509075, -0.05384877324104309, 0.027384137734770775, -0.015950895845890045, -0.04525763913989067, -0.017276642844080925, 0.03651423379778862, -0.021059760823845863, -0.04006611928343773, 0.0179095771163702, -0.030000997707247734, 0.020122647285461426, 0.04558258131146431, 0.029792197048664093, -0.010563996620476246, -0.003013725159689784, -0.009239857085049152, 0.03636014461517334, 0.006303752306848764, -0.03701198846101761, -0.021528949961066246, 0.050655920058488846, 9.395935921929777e-05, -0.029211988672614098, -0.09995348751544952, -0.009716692380607128, 0.0008306097588501871, -0.014175927266478539, 0.009476348757743835, -0.0458831787109375, -0.039515420794487, 0.023751357570290565, 0.02506381645798683, -0.0682896301150322, 0.06958912312984467, -0.03228451684117317, -0.06413612514734268, 0.006441599689424038, -0.034933365881443024, -0.01175056491047144, 0.0158330500125885, 0.017741063609719276, -0.0008554741507396102, 0.021407008171081543, -0.025253433734178543, -0.04190477728843689, 0.034302860498428345, 0.01036786288022995, 0.015123465098440647, 0.007609411608427763, -0.004506566096097231, -0.06918089836835861, 0.023503923788666725, 0.03993012011051178, 0.044451575726270676, 0.025928789749741554, -0.0015766570577397943, 0.030420247465372086, 0.01841423101723194, 0.03506763279438019, -0.014076192863285542, 0.024656901136040688, 0.0012934101978316903, -0.00046112609561532736, -0.01754940301179886, 0.03432047367095947, -0.024709785357117653, -0.10086216777563095, 0.007587448228150606, -0.010878430679440498, -0.04428812861442566, -0.008701033890247345, -0.028961312025785446, 0.058874357491731644, -0.05407385900616646, 0.016642196103930473, 0.03211698681116104, 0.021964747458696365, 0.02750745229423046, -0.08663562685251236, 0.03899538144469261, 0.009808479808270931, 0.0018714063335210085, 0.11407934874296188, 0.01445274893194437, -0.042457301169633865, 0.013576327823102474, 0.06108250841498375, -0.03719149902462959, 0.03032270260155201, -0.010873125866055489, 0.08414588868618011, 0.056150808930397034, -0.07050346583127975, -0.055673226714134216, -0.036652371287345886, 0.002106383675709367, 0.04810524731874466, 0.021014215424656868, 0.01428179256618023, -0.014079921878874302, 0.0341220423579216, 0.04205545037984848, -0.011196696199476719, 0.01959650032222271, 0.01376767922192812, 0.03529849275946617, 0.03358030319213867, -0.054367613047361374, 0.04305139556527138, 0.047564998269081116, -0.04971931129693985, -0.011721794493496418, -0.015547874383628368, 0.055938154458999634, -0.030505802482366562, 0.020150132477283478, 0.06878970563411713, 0.023575181141495705, -0.02538732811808586, -0.05323423445224762, -0.09757126122713089, -0.02501114085316658, 0.025520214810967445, 0.045392122119665146, -0.00570613844320178, 0.07617274671792984, -0.011997787281870842, 0.041717223823070526, 0.005486263893544674, 0.02435426227748394, 0.0052115339785814285, -0.030325815081596375, -0.04783129692077637, -0.01748374104499817, 0.013632713817059994, 0.005610131658613682, 0.00539398193359375, -0.02239501103758812, -0.05806613340973854, -0.008843311108648777, 0.025016916915774345, 0.008394356817007065, -0.016845140606164932, -0.01248530950397253, -0.009419882670044899, -0.031032536178827286, 0.03627917170524597, 0.014204785227775574, 0.024342522025108337, 0.08323188126087189, 0.00834429170936346, -0.024382255971431732, -0.03452729806303978, -0.02160346321761608, -0.01639949530363083, -0.031417325139045715, 0.03166899457573891, 0.014218514785170555, -0.008542221039533615, -0.06047137826681137, -0.02509247697889805, -0.09044092893600464, 0.009661232121288776, 0.020590122789144516, -0.10719799995422363, 0.006614529062062502, -0.027564942836761475, 0.021683115512132645, -0.003914882894605398, -0.008151086047291756, 0.0269908644258976, -0.021936513483524323, 0.0021011391654610634, -0.03281485661864281, 0.005335668101906776, 0.022326039150357246, 0.027993353083729744, -0.014554052613675594, -0.04552881419658661, -0.0001212546558235772, 0.011287047527730465, 0.059243541210889816, 0.02504776045680046, -0.030452093109488487, 0.004934461787343025, -0.012495079077780247, -0.021131249144673347, -0.018626265227794647, -0.01839902065694332, 0.0354265496134758, -0.02157890982925892, 0.01731615886092186, -0.032658595591783524, 0.0034498441964387894, -0.017147619277238846, -0.028348557651042938, -0.008426777087152004, 0.012974978424608707, 0.0061413804069161415, 0.06649941951036453, 0.021327409893274307, 0.021504828706383705, 0.030579714104533195, -0.0032601128332316875, 0.043910566717386246, -0.009874310344457626, 0.05604301765561104, 0.030096622183918953, -0.014481349848210812, -0.014006524346768856, -0.02447066642343998, 0.02439013123512268, -0.037199266254901886, 0.015485153533518314, 0.006118180695921183, 0.0036686768289655447, -0.030363136902451515, 0.022162288427352905, -0.058403562754392624, -0.014325304888188839, 0.026818305253982544, 0.014442569576203823, 0.013894480653107166, -0.009776980616152287, -0.0628330186009407, 0.0008445630082860589, -0.020356982946395874, -0.0149035369977355, 0.02154732309281826, 0.013381577096879482, -0.006141583435237408, -0.014537287876009941, 0.029336096718907356, -0.07947469502687454, 0.013723640702664852, -0.007838642224669456, 0.0018007985781878233, 0.03356214240193367, 0.042999569326639175, -0.023353759199380875, -0.021111348643898964, -0.022204242646694183, 0.025356290861964226, 0.033963777124881744, -0.03163101151585579, 0.00783825758844614, -0.050719745457172394, 0.044873036444187164, -0.009552917443215847, -0.005667009856551886, -0.02122458629310131, -0.011520168744027615, 0.025401988998055458, 0.04798237234354019, -0.03905315697193146, 0.00022193806944414973, -0.024845890700817108, -0.01708778366446495, -0.047644633799791336, 0.04862580448389053, 0.010858521796762943, 0.016707085072994232, -0.015900004655122757, -0.05690767616033554, -0.03356078639626503, 0.02966243401169777, 0.082548126578331, -0.006331547629088163, -0.005229467526078224, -0.044357456266880035, 0.004159612115472555, -0.033369939774274826, -0.029806150123476982, 0.021217580884695053, 0.019044553861021996, 0.05491739884018898, 0.059718940407037735, 0.024168362841010094, 0.014946224167943, -0.004545973148196936, 0.04415087029337883, -0.0071115619502961636, -0.0066160960122942924, 0.04373406991362572, 0.0031468209344893694, 0.04609805718064308, -0.0024352618493139744, 0.04615902900695801, 0.05923732742667198, 0.012227801606059074, 0.009507173672318459, -0.006809429731220007, -0.00015941777382977307, 0.012248629704117775, -0.05527378246188164, -0.029200393706560135, 0.00874241255223751, -0.0038534763734787703, 0.1080559566617012, -0.03062039613723755, 0.04584809020161629, 0.026885241270065308, 0.01565711386501789, 0.003353129606693983, -0.05039756000041962, -0.07909312844276428, 0.034767210483551025, -0.0075780656188726425, 7.567479042336345e-05, -0.0014798074262216687, -0.07013475894927979, 0.04326019063591957, -0.00664185406640172, -0.02642153576016426, 0.05586319416761398, 0.09907937049865723, 0.01547487173229456, 0.02990557625889778, -0.022104112431406975, -0.04902450367808342, 0.027377299964427948, 0.034498393535614014, -0.05789083242416382, 0.004796757362782955, -0.053319301456213, 0.011462151072919369, -0.00547825125977397, 0.008008712902665138, -0.09623390436172485, 0.02178267575800419, -0.007160022389143705, 0.029232829809188843, -0.006469066254794598, -0.02577325887978077, -0.002938260789960623, -0.05693812295794487, 0.05601716786623001, -0.006650036666542292, 0.017208237200975418, 0.05249451845884323, 0.03863444924354553, -0.08671215921640396, -0.020112283527851105, -0.008245974779129028, -0.01234346628189087, -0.047104015946388245, 0.04901542514562607, -0.02337159588932991, 0.026961766183376312, 0.04068936035037041, 0.04701109975576401, -0.0018334798514842987, -0.005221422761678696, 0.018209561705589294, -0.010032080113887787, 0.006245321594178677, 0.021675242111086845, 0.07398740202188492, -0.017181867733597755, 0.008505577221512794, -0.06925423443317413, -0.03525201231241226, -0.004687266889959574, 0.0029127777088433504, -0.05455626919865608, 0.03369000181555748, -0.010883547365665436, -0.006105381064116955, 0.04479272663593292, -0.0005694981082342565, 0.013060487806797028, -0.04899865388870239, 0.005672058556228876, 0.00574337737634778, -0.03156585618853569, -0.046348921954631805, 0.023255605250597, -0.0521051287651062, -0.033938053995370865, 0.009132648818194866, 0.025467341765761375, 0.019316770136356354, 0.009398064576089382, 0.01125379465520382, 0.05623510852456093, 0.032729290425777435, 0.0133063904941082, 0.027968520298600197, 0.023214247077703476, -0.06517212092876434, -0.01652582362294197, 0.018255600705742836, 0.009669958613812923, -0.04515133425593376, -0.021455252543091774, 0.019841695204377174, -0.0027564314659684896, -0.019980860874056816, -0.004255531821399927, 0.008842863142490387, -0.0500887967646122, 0.01920354552567005, -0.014437372796237469, -0.06192202866077423, -0.024565989151597023]') ,('The king entered the car' ,'[-0.06366106122732162, 0.0371050201356411, -0.13371889293193817, -0.021586041897535324, 0.0013707682956010103, 0.00780313229188323, -0.034369003027677536, 0.07440928369760513, -0.03610813245177269, -0.014822323806583881, -0.07335194945335388, 0.010727082379162312, 0.028241479769349098, -0.00557663943618536, 0.016600733622908592, -0.0306655652821064, 0.03163173422217369, -0.0392732247710228, -0.01930205337703228, 0.03520410507917404, 0.001106951734982431, 0.024142472073435783, -0.11819662898778915, 0.03766537830233574, 0.12828004360198975, -0.03675626590847969, 0.012544563040137291, -0.010433417744934559, -0.030474113300442696, 0.009951172396540642, 0.07748491317033768, 0.008755724877119064, -0.013789679855108261, -0.003658221336081624, -0.05787202715873718, -0.06254521757364273, 0.013255460187792778, 0.015263033099472523, 0.06202990561723709, -0.04171683266758919, 0.03531118109822273, -0.019832830876111984, -0.0035260797012597322, 0.0011221289169043303, 0.050706375390291214, -0.02496286854147911, -0.018272006884217262, -0.014864951372146606, -0.008298984728753567, 0.055641286075115204, -0.004939673002809286, -0.009292079135775566, -0.06001249700784683, -0.04088565334677696, 0.0348367914557457, 0.058439090847969055, 0.06897229701280594, -0.013636983931064606, -0.013078944757580757, -0.008195041678845882, 0.04189392924308777, -0.0026941827964037657, 0.03311255946755409, 0.03299403563141823, -0.01136003527790308, -0.07077934592962265, 0.008899410255253315, 0.11259376257658005, 0.005413408391177654, -0.0005293236463330686, 0.06112422049045563, -0.025380725041031837, 0.05198495090007782, -0.06003855913877487, 0.01372306328266859, -0.014799459837377071, 0.024818839505314827, -0.013034540228545666, 0.04515213891863823, 0.003686752635985613, 0.025093114003539085, 0.010564188472926617, 0.036675553768873215, -0.015977639704942703, 0.019526254385709763, 0.048439327627420425, 0.007097748573869467, -0.005672773811966181, -0.01210852526128292, 0.032246120274066925, 0.04791032522916794, 0.002837446052581072, 0.01372729241847992, 0.01059779804199934, -0.011713002808392048, -0.0035321360919624567, -0.07068976014852524, -0.006282274145632982, -0.054073482751846313, -0.024566451087594032, 0.004859513603150845, -0.06207720562815666, -0.04637769237160683, 0.007238851860165596, 0.04596610739827156, 0.09409582614898682, -0.022839045152068138, -0.01344651822000742, -0.05625656619668007, -0.04211822897195816, -0.05266684293746948, -0.019075682386755943, -0.02469347044825554, 0.01892205700278282, 0.0020926259458065033, 0.05143514275550842, 0.01646832749247551, -0.021359995007514954, 0.023504668846726418, 0.01597212813794613, -0.006127077620476484, 0.03513404354453087, -0.034080762416124344, 0.03015647828578949, 0.027435703203082085, 0.04274039715528488, -0.05109681934118271, 0.025393040850758553, -0.009092634543776512, -0.03166860714554787, 0.0008341529755853117, -0.017169179394841194, 0.02262737788259983, 0.02078302577137947, 0.021752193570137024, 0.040563080459833145, 0.024453796446323395, 0.011116179637610912, 0.01555157545953989, -0.015091498382389545, -0.004414839670062065, 0.10259556025266647, 0.006927843671292067, -0.001541371108032763, 0.011072404682636261, -0.05808652564883232, 0.03441719710826874, -0.04433462768793106, -0.08440816402435303, -0.03737889975309372, 0.042378831654787064, -0.026720141991972923, -0.02168756164610386, 0.05760018154978752, -0.0032769159879535437, -0.03169456124305725, 0.01809801533818245, 0.01806609518826008, -0.012502556666731834, 0.0035988816525787115, 0.06761959940195084, -0.05037262663245201, -0.03804485872387886, -0.015567172318696976, -0.0533166378736496, -0.05869799852371216, -0.001539027551189065, 0.027588823810219765, 0.025486772879958153, 0.012392756529152393, -0.03627096116542816, -0.045470546931028366, -0.0692552700638771, -0.01331236306577921, 0.01707572303712368, -0.031985603272914886, -0.0076558589935302734, 0.010407185181975365, 0.03333669155836105, -0.018301311880350113, 0.024359852075576782, -0.05566363409161568, 0.06798135489225388, 0.03206321597099304, -0.028008606284856796, -0.024596640840172768, -0.0013886664528399706, 0.0035310739185661077, -0.12796537578105927, -0.03128506615757942, 0.027147477492690086, 0.012598813511431217, -0.034458935260772705, -0.04176492244005203, -0.020084459334611893, -0.008275012485682964, 0.012430391274392605, -0.0014343679649755359, -0.0017723670462146401, -0.0669977068901062, 0.030101090669631958, -0.01649354211986065, -0.021510746330022812, 0.023386262357234955, -0.05557464063167572, 0.04042872041463852, 0.013721577823162079, 0.06907942146062851, 0.025088677182793617, 0.015678446739912033, 0.06761188060045242, 0.029340485110878944, -0.02622014284133911, 0.01902276650071144, 0.0044332160614430904, 0.011708052828907967, 0.011221346445381641, -0.05547370761632919, 0.026139002293348312, 0.02727733738720417, 0.011644686572253704, 0.06446246802806854, -0.019420454278588295, 0.0077054426074028015, 0.012713948264718056, 0.04476592689752579, -0.03194887563586235, -0.028435664251446724, -0.02789870835840702, 0.02823544852435589, -0.016924450173974037, -0.059969209134578705, -0.0035176135133951902, 0.023445427417755127, 0.008029638789594173, 0.043270356953144073, -0.017083656042814255, 0.017261117696762085, 0.0017239635344594717, -0.022292859852313995, -0.03037146106362343, 0.03088788501918316, -0.011150875128805637, 0.0029234846588224173, -0.04844862222671509, -0.014091788791120052, -0.04211028665304184, -0.052125848829746246, -0.01213399413973093, -0.0012184333754703403, 0.04219217970967293, 0.011617334559559822, 0.0017507555894553661, -0.05298397317528725, 0.034914419054985046, -0.0032100225798785686, 0.00433887867256999, 0.022006958723068237, 0.02388767898082733, -0.009323387406766415, 0.01200153212994337, -0.06079466640949249, -0.012501752935349941, -0.05929611250758171, -0.016602564603090286, -0.002764082746580243, -0.027686864137649536, -0.02444462478160858, 0.03277736157178879, -0.05755779892206192, -0.011888101696968079, 0.04949815198779106, -0.0005932464264333248, -0.009920597076416016, 0.027878912165760994, -0.015917856246232986, -0.015443075448274612, -0.004528769291937351, -0.04335176199674606, 0.024572549387812614, -0.024229703471064568, -0.01117569301277399, -0.045808907598257065, -0.03657638654112816, -0.031372059136629105, 0.008075215853750706, 0.03554118052124977, 0.02839074656367302, 0.00991312600672245, -0.002091935370117426, -0.0028176980558782816, 0.02154993638396263, -0.027894115075469017, 0.03942064568400383, -0.00697919400408864, 0.05364608019590378, 0.06351293623447418, 0.004432743415236473, 0.05171772092580795, -0.054354019463062286, 0.02710771933197975, -0.06337929517030716, 0.04363371059298515, 0.016077402979135513, -0.006730057764798403, 0.032895877957344055, 0.061682816594839096, -0.006756788119673729, -0.0013039348414167762, 0.02452850341796875, -0.04273669421672821, 0.0017555552767589688, -0.02484673634171486, 0.01654120162129402, -0.050401050597429276, -0.013555179350078106, -0.029520176351070404, 0.030410127714276314, 0.04934011772274971, 0.04255753010511398, 0.03343106433749199, -0.06316710263490677, -0.006875617895275354, 0.04040314257144928, 0.01475065853446722, 0.0064861527644097805, 0.00795707106590271, 0.024394547566771507, 0.015946978703141212, -0.06312892585992813, -0.05017373710870743, 0.034141771495342255, 0.004597937688231468, -0.011153428815305233, -0.014226709492504597, 0.0074204858392477036, 0.003184535074979067, 0.0006467169150710106, -0.07516764104366302, -0.02806982770562172, 0.06268969178199768, 0.005808957386761904, 0.05972323194146156, -0.058881018310785294, 0.003912910353392363, -0.024058520793914795, -0.01225863303989172, -0.002526150783523917, 0.00962097104638815, -0.04450139030814171, -0.052008628845214844, -0.03333699330687523, -0.05173855647444725, 0.0200785081833601, -0.03953101858496666, -0.0013116549234837294, 0.0038196281529963017, 0.001298278453759849, -0.010305926203727722, -0.022327329963445663, 0.021411694586277008, -0.024495767429471016, -0.011845064349472523, 0.01960724964737892, 0.007499337196350098, 0.02236524224281311, -0.044154245406389236, 0.03023315779864788, 0.07026881724596024, 0.01331376750022173, -0.025468070060014725, -0.025637846440076828, 0.007263836916536093, -0.010874268598854542, 0.06688091158866882, 0.035154540091753006, 0.022392945364117622, -0.04093608632683754, -0.011615126393735409, 0.01297572162002325, 0.0045560249127447605, -0.020895004272460938, 0.02393454499542713, -0.0022832215763628483, 0.035725802183151245, -0.01396249607205391, -0.00627897260710597, 0.0016107918927446008, 0.025219794362783432, 0.03471263498067856, 0.020762275904417038, -0.010397386737167835, -0.02790127508342266, -0.002030178438872099, 0.006919954437762499, -0.013145138509571552, 0.033879246562719345, -0.005154558923095465, -0.021613212302327156, -0.02694893442094326, -0.021107524633407593, -0.05720813572406769, -0.004802398383617401, 0.03572844713926315, -0.005722348112612963, 0.04624824598431587, 0.007859088480472565, 0.0013543666573241353, 0.023279927670955658, -0.014572516083717346, -0.03808373585343361, 0.033461615443229675, -0.006573510821908712, -0.021835295483469963, 0.04068354517221451, 0.08527461439371109, 0.04667339473962784, 0.0473264716565609, -0.007898886688053608, -0.014603382907807827, 0.0032634101808071136, 0.018541963770985603, -0.0214321780949831, 0.0655340626835823, 0.03454082831740379, -0.03912718966603279, 0.026738449931144714, 0.06706195324659348, -0.02891382947564125, -0.02839827351272106, 0.0041891285218298435, -0.01614525355398655, 0.015519657172262669, -0.0018116787541657686, -0.044259220361709595, -0.004364165477454662, -0.0405392087996006, 0.005998142529278994, 0.04484136402606964, 0.007288094609975815, -0.012759699486196041, -0.00428609736263752, 0.004865632858127356, 0.029453344643115997, 0.06727330386638641, 0.05441083386540413, 0.07995761930942535, -0.05690153315663338, -0.0035483071114867926, 0.012413259595632553, -0.03252313658595085, 0.004201763309538364, 0.005882630590349436, 0.08963844180107117, 0.025890352204442024, -0.030336754396557808, -0.018279405310750008, 0.04141668230295181, -0.014466621913015842, 0.03416265547275543, 0.03470799699425697, 0.06862060725688934, -0.06484212726354599, -0.015849579125642776, -0.01852634735405445, -0.03905472531914711, 0.0349593311548233, 0.025922926142811775, 0.010498475283384323, 0.09378057718276978, -0.0014182854210957885, 0.04863166809082031, 0.054431840777397156, -0.057487852871418, -0.0012642150977626443, -0.008686992339789867, 0.002338971011340618, -0.022694764658808708, 0.003046521684154868, 0.018556222319602966, 0.07186167687177658, -0.008406461216509342, -0.03591064736247063, -0.009360063821077347, 0.059594787657260895, 0.060069773346185684, 0.06003686040639877, 0.00474492646753788, 0.0107337711378932, -0.018538692966103554, 0.04737463220953941, 0.011740733869373798, 0.008988619782030582, -0.008960655890405178, 0.015540453605353832, 0.024755731225013733, -0.014641745947301388, -0.014524136669933796, 0.06867149472236633, 0.03326162323355675, 0.0028918017633259296, 0.0031980436760932207, 0.004538172855973244, 0.028210125863552094, 0.025534896180033684, 0.00014415518671739846, -0.04175432771444321, -0.048417385667562485, -0.030866866931319237, 0.01711653731763363, -0.025715069845318794, 0.018891382962465286, 0.052085716277360916, 0.027676770463585854, 0.06333545595407486, -0.026016179472208023, -0.02149113453924656, -0.003996374551206827, 0.010398399084806442, 0.03595874831080437, 0.0297502763569355, -0.05126122757792473, -0.0371004119515419, -0.01801861822605133, -0.04476458951830864, 0.018582718446850777, 0.014414746314287186, -0.08984274417161942, 0.033408407121896744, 0.010137028060853481, -0.02090885490179062, 0.051851462572813034, -0.027393698692321777, -0.003076093504205346, -0.028873620554804802, 0.010142097249627113, -0.03572884202003479, 0.015200181864202023, 0.06516408175230026, 0.051115039736032486, -0.03836166113615036, -0.05010218545794487, -0.05672683194279671, -0.0015361227560788393, 0.024037934839725494, 0.008187641389667988, -0.022505061700940132, 0.005200835410505533, 0.020836494863033295, -0.061269983649253845, -0.0009010604699142277, -0.0005452027544379234, -0.01656942255795002, -0.02000238001346588, -0.03806008771061897, 0.011611546389758587, -0.025317983701825142, 0.010892925783991814, -0.0388295017182827, -0.02852153778076172, 0.02633289434015751, 0.0077706738375127316, 0.07893088459968567, -0.008183461613953114, 0.057981397956609726, 0.04854878783226013, -0.03099481388926506, -0.014461650513112545, 0.022053267806768417, -0.022659189999103546, 0.057305049151182175, -0.07823824137449265, 0.03477101773023605, -0.008153085596859455, 0.02639620564877987, -0.022829649969935417, -0.011906684376299381, -0.01202781405299902, -0.004245353396981955, -0.03288949653506279, 0.0020920231472700834, -0.04012777656316757, 0.04536862671375275, -0.021806148812174797, -0.025099318474531174, 0.006625513546168804, -0.021334243938326836, -0.04357508197426796, 0.008799050003290176, 0.030935999006032944, 0.007096234709024429, -0.028460733592510223, -0.024773970246315002, -0.03955823928117752, 0.0360407717525959, 0.010507404804229736, -0.05877269431948662, -0.057825200259685516, 0.016515787690877914, 0.025679245591163635, 0.00016562180826440454, -0.020788313820958138, -0.004515292588621378, -0.030309511348605156, -0.05443612486124039, -0.019161170348525047, -0.006705099251121283, 0.012744844891130924, 0.028499005362391472, -0.07650218158960342, 0.05261358991265297, 0.010430612601339817, -0.05655532702803612, -0.021937832236289978, 0.017426565289497375, 0.00971758272498846, 0.03487032651901245, -0.03983062505722046, 0.04137676954269409, -0.037917062640190125, 0.01320004090666771, 0.003169502830132842, 0.02158210426568985, -0.05612201616168022, -0.010954713448882103, -0.0037530665285885334, -0.06391280889511108, -0.001566447434015572, 0.0620119571685791, 0.0163772813975811, -0.05010385438799858, -0.020807895809412003, -0.10817781835794449, -0.011930916458368301, 0.028940994292497635, -0.022621747106313705, 0.017265643924474716, -0.013283086940646172, -0.032334260642528534, 0.03764217346906662, -0.001690164441242814, 0.012455432675778866, 0.012295352295041084, 0.03212975710630417, -0.017112338915467262, -0.01531390193849802, 0.036518242210149765, 0.01306963711977005, 0.05304592475295067, -0.027347320690751076, 0.01528905238956213, 0.05146951973438263, -0.018679386004805565, 0.00927517656236887, -0.018137317150831223, -0.04333076998591423, 0.01455201767385006, -0.013612452894449234, -0.03810257837176323, -0.03232290595769882, 0.025517234578728676, 0.04348595440387726, -0.0337044931948185, -0.010229643434286118, 0.004854648374021053, -0.022152254357933998, -0.01501529011875391, -0.045361440628767014, -0.05973502993583679, -0.003665621392428875, -0.0017631041118875146, 0.062240779399871826, -0.030635660514235497, 0.006467327941209078, -0.06075343117117882, 0.00620994670316577, 0.024431154131889343, 0.09336975961923599, 0.07987461984157562, -0.012147100642323494, -0.0061226049438118935, -0.02962534874677658, -0.013505786657333374, 0.046773314476013184, 0.011823790147900581, -0.06813932955265045, 0.05885862186551094, -0.08962016552686691, -0.025659214705228806, -0.06166895851492882, -0.012911785393953323, -0.05230940505862236, -0.012052700854837894, 0.020201697945594788, 0.02006365731358528, -0.016116907820105553, -0.036077629774808884, 0.04135405272245407, -0.016678225249052048, 0.026984741911292076, -0.03253397345542908, 0.07236023247241974, -0.0041063022799789906, 0.05308401584625244, -0.04912285506725311, -0.016073934733867645, 0.05855884030461311, -0.049489881843328476, -0.047114912420511246, 0.07775460928678513, -0.024515114724636078, 0.032597050070762634, 0.0010274001397192478, 0.07839085161685944, 0.05551754683256149, -0.001981100533157587, 0.00037833908572793007, -0.022664068266749382, 0.017995117232203484, 0.03330269455909729, 0.04866890609264374, -0.0038558170199394226, 0.010613791644573212, -0.018434686586260796, -0.021841280162334442, -0.013224661350250244, 0.000776260276325047, -0.02765618823468685, -0.05495471507310867, -0.006177089177072048, 0.020273515954613686, 0.011953822337090969, -0.011116527020931244, -0.005147586110979319, -0.03997739404439926, -0.04089261218905449, 0.009126395918428898, -0.055831391364336014, -0.03294454142451286, 0.003459766274318099, -0.07259533554315567, -0.024916263297200203, 0.023026155307888985, 0.06521034985780716, 0.013879184611141682, -0.05423635616898537, -0.031092960387468338, 0.051712095737457275, 0.04224510118365288, 0.011599160730838776, 0.01474816258996725, -0.046958472579717636, -0.035996511578559875, 0.02138986997306347, -0.011776183731853962, -0.05024464800953865, -0.02437511458992958, 0.02252824418246746, 0.048551395535469055, 0.04517240822315216, 0.032376307994127274, 0.036311421543359756, 0.022917963564395905, 0.021379785612225533, 0.01934393309056759, -0.019422456622123718, -0.020691726356744766, 0.004326852969825268]') ,('The queen took a plane' ,'[0.016738194972276688, 0.03851189836859703, -0.1601611077785492, 0.013240817002952099, -0.02566191554069519, 0.09977556020021439, -0.09398238360881805, 0.009572899900376797, 0.0032859453931450844, -0.00032333898707292974, -0.10052357614040375, 0.016457481309771538, 0.05764659121632576, 0.008905536495149136, 0.03705701231956482, 0.017145730555057526, 0.02708732895553112, -0.05319942533969879, 0.011150202713906765, 0.026652848348021507, -0.018271682783961296, -0.04349777474999428, -0.09087739139795303, 0.03186503052711487, 0.04204704612493515, -0.02756803296506405, -0.02298874594271183, -0.028772469609975815, -0.052430376410484314, 0.016002431511878967, 0.03592327609658241, -0.05157889425754547, -0.007978458888828754, -0.04355033487081528, 0.04342946410179138, -0.04390189051628113, 0.007750354707241058, 0.021289626136422157, 0.05545462295413017, 0.012403812259435654, 0.04102298989892006, -0.042156558483839035, -0.05996732786297798, 0.02875075861811638, 0.0807604044675827, -0.002514082472771406, 0.10617813467979431, 0.021601933985948563, -0.0739089623093605, 0.055247969925403595, -0.003266998566687107, 0.04703563451766968, -0.02336852066218853, 0.012801905162632465, 0.02652469091117382, 0.012202356941998005, 0.07868687808513641, 0.031579479575157166, -0.010338389314711094, 0.03971477970480919, 0.07214783132076263, -0.0114823617041111, -0.00891769491136074, 0.050829194486141205, 0.0017501984257251024, -0.05484052374958992, -0.05692543834447861, 0.0692700743675232, -0.01557659637182951, -0.024288058280944824, 0.06469117850065231, -0.029098939150571823, 0.015836115926504135, -0.0034314070362597704, -0.008690569549798965, -0.055109649896621704, 0.021664556115865707, -0.0281540360301733, 0.03106490708887577, -0.0025430459063500166, 0.024443702772259712, -0.04702211171388626, 0.06634590029716492, 0.007679872680455446, 0.08201615512371063, 0.05635029822587967, -0.012808251194655895, -0.03962161764502525, -0.0297028049826622, 0.03853800520300865, 0.026925968006253242, 0.013254616409540176, 0.0505782775580883, 0.042274102568626404, 0.004908622708171606, -0.022555826231837273, -0.035282183438539505, -0.03359346091747284, -0.09881284087896347, -0.05224372446537018, 0.02286038175225258, -0.03992535546422005, -0.00864262506365776, 0.009546410292387009, 0.02249276451766491, 0.013854355551302433, 0.017956100404262543, -0.004915771074593067, -0.02826392650604248, -0.013385090045630932, -0.04583475738763809, -0.007576699834316969, 0.0015305611304938793, 0.014210045337677002, 0.04394854977726936, -0.0011736364103853703, -0.015165787190198898, -0.09530927240848541, -0.012121522799134254, 0.007773947902023792, -0.029642576351761818, -0.016042865812778473, -0.026232201606035233, 0.019411057233810425, 0.040535565465688705, 0.017174646258354187, -0.08341798931360245, 0.02100609615445137, -0.006393759045749903, -0.028912045061588287, -0.023898446932435036, -0.0069627598859369755, -0.01790030114352703, 0.0354580283164978, -0.010248945094645023, -0.005673663225024939, -0.03890756145119667, -0.05686764419078827, 0.02641872689127922, 0.022053426131606102, -0.004869663156569004, 0.040565963834524155, -0.00884919986128807, 0.01831507496535778, 0.017632294446229935, -0.050500232726335526, 0.031762056052684784, -0.003667967626824975, -0.05037406086921692, -0.0091431625187397, 0.02898624911904335, 0.010696418583393097, -0.026012087240815163, 0.05576695501804352, 0.007542508188635111, -0.04111504554748535, -0.010258208028972149, 0.03550751879811287, 0.020793624222278595, -0.030983489006757736, 0.0843900516629219, 0.005597489885985851, -0.02216118946671486, 0.015960024669766426, -0.051059383898973465, -0.006498910021036863, 0.03903690725564957, 0.03965875506401062, -0.006671146489679813, 0.018513090908527374, -0.009379379451274872, -0.015054634772241116, -0.013682165183126926, -0.010232221335172653, 0.03303896635770798, -0.0021401040721684694, 0.03342844173312187, 0.03880198299884796, 0.04391663148999214, -0.08045525848865509, 0.019559964537620544, -0.022398078814148903, 0.017407389357686043, 0.013860544189810753, -0.03572741895914078, -0.008447304368019104, -0.01932196505367756, -0.013986886478960514, -0.05978729948401451, -0.04262132570147514, -0.019841095432639122, 0.011346420273184776, -0.02127671055495739, -0.04411720484495163, -0.07477138191461563, -0.029742354527115822, 0.05125656723976135, 0.001999438274651766, -0.01500912755727768, -0.03576670214533806, 0.05003831535577774, -0.022809693589806557, 0.03387007489800453, 0.01983301155269146, -0.051122184842824936, 0.02503529004752636, 0.02872629649937153, 0.026122961193323135, 0.02446310967206955, 0.0029503251425921917, 0.042907748371362686, 0.039467353373765945, -0.019990645349025726, 0.03891472518444061, 0.042597826570272446, -0.022257691249251366, 0.007392737083137035, -0.09300504624843597, -0.01046187523752451, 0.0009323217673227191, 0.030724508687853813, -0.0060162716545164585, 0.005696398671716452, -0.010141856968402863, 0.07034212350845337, 0.02940642647445202, -0.029699712991714478, -0.04814918339252472, -0.049803055822849274, -0.005373232997953892, -0.037679947912693024, -0.08455987274646759, 0.003730542492121458, 0.020712651312351227, 0.011942348442971706, 0.02639000676572323, -0.04238726943731308, -0.010008812882006168, -0.005130933132022619, -0.006615553982555866, -0.009448476135730743, 0.06775406002998352, -0.018433457240462303, -0.011227636598050594, -0.05197012424468994, 0.0034698606468737125, -0.04564050957560539, -0.020316272974014282, 0.013147556222975254, 0.017338454723358154, -0.00854458101093769, -0.02353058010339737, 0.029066920280456543, 0.014241427183151245, 0.023930003866553307, 0.0017423448152840137, 0.009539748542010784, 0.01014459878206253, 0.05664994567632675, -0.01833701692521572, 0.021752776578068733, -0.04695868492126465, 0.031930647790431976, -0.013708713464438915, -0.04813426360487938, -0.011189988814294338, -0.03988586738705635, -0.008961199782788754, 0.01844659075140953, -0.06385631859302521, -0.019223956391215324, 0.03806215152144432, 0.0022795633412897587, 0.027209697291254997, 0.04145437851548195, -0.011339809745550156, 0.010930157266557217, 0.02068455144762993, -0.021217312663793564, 0.06953195482492447, 0.011332526803016663, -0.00088653335114941, -0.07522927969694138, -0.012830057181417942, 0.023100849241018295, -0.010069990530610085, 0.028209423646330833, 0.056359436362981796, 0.018819496035575867, 0.0017573075601831079, -0.035754069685935974, 0.03480902686715126, 0.013656988739967346, -0.008945025503635406, 0.012418141588568687, 0.042260512709617615, 0.0593673512339592, -0.013400958850979805, -0.013943775556981564, -0.027126982808113098, 0.004104991443455219, -0.03364824131131172, 0.061484966427087784, 0.05320975184440613, -0.08124128729104996, 0.05040320008993149, 0.04410267621278763, -0.03598344698548317, 0.017878156155347824, -0.008531754836440086, -0.055507563054561615, 0.0168584156781435, -0.01823558285832405, 0.03751259297132492, -0.03531065583229065, -0.05150856077671051, -0.0003685251867864281, -0.006224906537681818, 0.048452846705913544, 0.018872348591685295, 0.026734253391623497, -0.03202051296830177, -0.03586030378937721, 0.02265782654285431, -0.0021017412655055523, 0.020942004397511482, 0.022252678871154785, 0.03405863046646118, -0.0014108313480392098, -0.01753837801516056, 0.017598222941160202, 0.057206008583307266, -0.03653199225664139, -0.0028676888905465603, -0.0007728615310043097, 0.005585485137999058, 0.0049058361910283566, 0.06692136079072952, -0.021474266424775124, 0.01075589656829834, 0.038191020488739014, -0.03730933740735054, 0.03536481410264969, -0.043538860976696014, -0.011070878244936466, -0.029524916782975197, -0.006956583354622126, -0.016125787049531937, 0.04801303148269653, -0.007461526431143284, -0.03778446465730667, -0.00977606326341629, -0.05998871102929115, 0.01240465510636568, 0.02493540197610855, -0.02721187099814415, -0.009102694690227509, -0.012362118810415268, -0.0175927821546793, -0.01550324633717537, -0.012822081334888935, 0.02574613317847252, 0.022641126066446304, -0.016882766038179398, -0.007236667443066835, -0.03132973611354828, -0.05316244438290596, 0.026492122560739517, 0.07414160668849945, -0.037769343703985214, -0.03360746428370476, 0.007162704598158598, -0.009867759421467781, 0.030502796173095703, 0.024944359436631203, 0.0350472629070282, 0.018456341698765755, -0.025915546342730522, -0.012055722065269947, 0.007213617209345102, 0.017498068511486053, 0.023522090166807175, -0.008359485305845737, 0.014548699371516705, 0.01525846030563116, 0.008857429027557373, -0.016745729371905327, -0.0032172943465411663, 0.01721983030438423, -0.009812590666115284, -0.008818154223263264, -0.059485044330358505, -0.021558385342359543, 0.004702369682490826, 0.02849196456372738, -0.016097355633974075, 0.05093323439359665, 0.01087033562362194, 0.007483807858079672, 0.01374420803040266, 0.01030956394970417, -0.09010494500398636, -0.016670705750584602, -0.02403148263692856, -0.001606956822797656, 0.035718753933906555, -0.04093140363693237, -0.0414779856801033, 0.003474731231108308, 0.0202252846211195, 0.007800837978720665, 0.015149001032114029, -0.009900175034999847, -0.048066552728414536, -0.027544749900698662, 0.058307625353336334, 0.05493176355957985, 0.07319263368844986, -0.0027459014672785997, 0.006966785993427038, 0.08847440034151077, 0.07143829762935638, 0.002594202058389783, 0.0022252483759075403, 0.003393840277567506, 0.0014997972175478935, 0.007340571843087673, 0.00913151539862156, -0.023911427706480026, 0.002221625065430999, 0.03484165668487549, 0.006327471695840359, 0.029657810926437378, 0.02737434394657612, -0.02932390384376049, 0.0005192741518840194, 0.012676176615059376, -0.020018551498651505, 0.020246852189302444, 0.01343266386538744, 0.06945625692605972, -0.09359235316514969, -0.012852460145950317, -0.0013197700027376413, 0.031967319548130035, 0.05393998697400093, 0.08623220771551132, -0.060816455632448196, -0.005454978905618191, -0.004737988580018282, 0.010220644064247608, -0.004328414332121611, 0.0075034829787909985, 0.06917213648557663, 0.003914931323379278, -0.03218730911612511, 0.008188220672309399, 0.019775133579969406, 0.021480444818735123, 0.09641530364751816, 0.03969729319214821, 0.05238773673772812, -0.054309360682964325, -0.053298208862543106, -0.06630945950746536, 0.035328034311532974, -0.02010324038565159, 0.00748808728531003, -0.019121451303362846, 0.019790129736065865, -0.02960217371582985, 0.0151102589443326, -0.01603083685040474, 0.04448306933045387, -0.038398608565330505, -0.018642356619238853, -0.013590921647846699, -0.021060051396489143, -0.01433288399130106, 0.008626220747828484, 0.07013116031885147, -0.005259048659354448, -0.03434747830033302, -0.02391267754137516, 0.07674979418516159, 0.03439929708838463, 0.03194412589073181, -0.0009525692439638078, 0.024759212508797646, -0.0106736458837986, 0.06640107184648514, 0.024239279329776764, 0.02920496091246605, -0.028181569650769234, -0.023886345326900482, -0.003684115130454302, -0.0486324243247509, 0.015968341380357742, 0.0696687251329422, 0.008719763718545437, 0.05885184183716774, 0.02614978887140751, -0.002282149391248822, 0.021749000996351242, -0.006471035536378622, -0.026426345109939575, -0.03175948187708855, -0.07251287251710892, -0.048455215990543365, 0.049823034554719925, -0.08669071644544601, -0.04300191253423691, 0.003968361299484968, 0.01850733533501625, 0.05638306587934494, -0.006088278256356716, -0.03381618112325668, 0.036953721195459366, -0.0025000276509672403, 0.056115493178367615, -0.0067008924670517445, 0.0025004500057548285, -0.000795774394646287, 0.0018707712879404426, -0.05409854277968407, 0.00576277868822217, -0.04529155045747757, -0.062033992260694504, 0.040681641548871994, -0.03763865306973457, -0.010774009861052036, 0.04005745053291321, -0.04251312091946602, -0.027976125478744507, -0.02434081770479679, 0.004661739803850651, -0.0676010400056839, -0.013166707940399647, 0.03595155104994774, 0.058780353516340256, -0.00959074217826128, 0.0004109205328859389, -0.08828148245811462, 0.059098243713378906, 0.050313305109739304, -0.02270047925412655, -0.023943539708852768, -0.013526364229619503, 0.014774552546441555, 0.00095880136359483, 0.002964854007586837, -0.029238644987344742, -0.02630009315907955, -0.024440938606858253, 0.01178788673132658, -0.0032362639904022217, -0.015792328864336014, -0.028195055201649666, -0.03456846997141838, 0.03292889893054962, -0.0033026402816176414, 0.0002843879337888211, 0.059879839420318604, -0.04108784347772598, 0.01610223390161991, 0.03500882163643837, -0.020343545824289322, -0.005968176294118166, 0.005933261942118406, -0.07105488330125809, -0.007879647426307201, -0.07458782196044922, -0.04007600247859955, -0.01270411629229784, 0.016093553975224495, 0.0044067841954529285, 0.02022942155599594, -0.022388938814401627, 0.003536798758432269, -0.006112690549343824, 0.002480093389749527, -0.013570097275078297, -0.0037673828192055225, -0.020682096481323242, 0.012977599166333675, -0.0009866952896118164, -0.0016580044757574797, -0.030072646215558052, 0.0448291152715683, 0.032835952937603, -0.023184021934866905, -0.015366725623607635, -0.013297701254487038, -0.025444746017456055, 0.022517496719956398, -0.010525299236178398, -0.04201054945588112, -0.07798873633146286, -0.0016958541236817837, 0.004902257118374109, 0.030552977696061134, -0.002731588901951909, 0.017946965992450714, -0.04745452478528023, -0.010501217097043991, 0.055548619478940964, 0.054968513548374176, -0.008265938609838486, 0.02569761499762535, -0.0265275277197361, 0.045163027942180634, 0.03649991378188133, 0.011343163438141346, -0.03103656694293022, 0.05759907513856888, -0.011819942854344845, 0.04521813988685608, -0.019038887694478035, 0.0071534099988639355, -0.03366684541106224, -0.004851918667554855, -0.004684809595346451, -0.02359994500875473, 0.006764003075659275, 0.03730325400829315, 0.008620982058346272, -0.05255728214979172, 0.011243163608014584, 0.008363286964595318, 0.04214112088084221, -0.050502002239227295, 0.03311144560575485, -0.09547837823629379, -0.02051820419728756, 0.040080826729536057, 0.00043320399709045887, -0.02025090530514717, -0.01042998768389225, -0.015594413504004478, 0.004530890379101038, -0.02020351216197014, -0.002576566534116864, -0.0343933142721653, 0.0038870251737535, -0.0022682989947497845, -0.024573305621743202, 0.04511360079050064, 0.01852814294397831, 0.06651229411363602, -0.0436166450381279, 0.04573671519756317, 0.052817270159721375, -0.06541839241981506, 0.019004518166184425, -0.021425219252705574, -0.05235530063509941, 0.06509962677955627, -0.018190408125519753, -0.0872720405459404, -0.04603768140077591, 0.034270502626895905, -0.028407519683241844, -0.04639759287238121, -0.012207417748868465, 0.009987118653953075, -0.003755514742806554, -0.017188822850584984, -0.010773733258247375, -0.07867744565010071, -0.02267753891646862, 0.008949067443609238, 0.0247748252004385, -0.00022183799592312425, 0.00187829346396029, 0.0040367366746068, 0.0050281030125916, -0.000432629109127447, 0.08277720957994461, 0.06411131471395493, 0.006514275912195444, 0.022114641964435577, -4.7227567847585306e-05, -0.02967495284974575, 0.03527049347758293, -0.02284185215830803, -0.024746118113398552, 0.04625890776515007, -0.02403164654970169, -0.0028613756876438856, -0.04784679040312767, -0.03762797638773918, -0.02592344395816326, 0.02013106271624565, 0.0013015246950089931, -0.0026706107892096043, -0.021581165492534637, 0.032494690269231796, -0.0020923479460179806, -0.04341508448123932, -0.010732855647802353, -0.03939023241400719, 0.04009634256362915, 0.03936009481549263, 0.011550236493349075, -0.08402147889137268, -0.021285351365804672, 0.04879337176680565, -0.020444106310606003, -0.01262891199439764, 0.07764393836259842, -0.011605747044086456, -0.01118506584316492, 0.007341193500906229, 0.04991782084107399, 0.09183666855096817, 0.013707603327929974, 0.003041783580556512, -0.06033429875969887, -0.027428634464740753, -0.006611375603824854, 0.038715001195669174, 0.036283548921346664, -0.07758811116218567, 0.004315108992159367, -0.018478428944945335, 0.009504629299044609, 0.013021585531532764, -0.01536150835454464, 0.008590510115027428, -0.057258058339357376, 0.03776419535279274, 0.0179420355707407, -0.0030345141422003508, -0.02103487029671669, 0.01193779893219471, 0.008804796263575554, -0.025849735364317894, -0.03883868455886841, -0.04284774139523506, -0.019840601831674576, 0.007850023917853832, 0.019834047183394432, 0.0024500470608472824, 0.04544375464320183, 0.028934922069311142, -0.04422449320554733, 0.01719420589506626, 0.03489740192890167, 0.011843658983707428, 0.00019498325127642602, -0.02494777925312519, -0.0345609188079834, -0.056174296885728836, 0.007085337769240141, -0.007491451222449541, 0.016102168709039688, 0.013181081041693687, 0.03859405964612961, 0.06383322179317474, -0.010785223916172981, 0.025129983201622963, -0.04688799008727074, 0.033756375312805176, 0.04123861715197563, -0.03643007576465607, -0.009038388729095459, 0.0035998281091451645, 0.05489146336913109]') DECLARE @Search vector(768) -- white vehicles set @Search = ' [-0.06424842774868011, 0.03221892938017845, -0.18985779583454132, -0.044986143708229065, 0.11152318865060806, 0.021156571805477142, 0.006625930313020945, -0.006481862161308527, -0.0019161656964570284, 0.030416803434491158, 0.029086867347359657, -0.014932475984096527, 0.038311656564474106, -0.00543052377179265, -0.018185321241617203, -0.04669100046157837, 0.004660810809582472, -0.037902455776929855, 0.005061687435954809, -0.008155930787324905, 0.021223604679107666, 0.01191001757979393, -0.06668391823768616, 0.02517373487353325, 0.14258863031864166, 0.03980790451169014, -0.019366640597581863, -0.014019537717103958, 0.038783829659223557, -0.015439989976584911, 0.05257941782474518, -0.04486413672566414, 0.033327165991067886, -0.040523286908864975, 0.018352461978793144, -0.051757488399744034, 0.028932109475135803, -0.026281364262104034, 0.06563375890254974, -0.016671814024448395, 0.077931709587574, 0.06708738952875137, 0.01428169570863247, 0.005012205336242914, 0.053897954523563385, -0.019928740337491035, 0.015971718356013298, 0.010076760314404964, 0.04924388602375984, 0.08519214391708374, 0.020445842295885086, 0.02401822619140148, -0.07378727197647095, -0.023849427700042725, 0.054087456315755844, -0.11039216071367264, 0.028031138703227043, -0.04913400113582611, -0.011718522757291794, 0.05293262004852295, -0.0330439954996109, 0.009404538199305534, 0.026440845802426338, 0.024949314072728157, 0.031440749764442444, -0.08461210131645203, -0.02627267688512802, 0.07737402617931366, 0.03937524929642677, -0.027552202343940735, 0.0012067239731550217, 0.022170454263687134, 0.021674908697605133, -0.006251885090023279, 0.01723342575132847, 0.005691996309906244, -0.0037202956154942513, 0.017469044774770737, 0.019476763904094696, -0.020143473520874977, 0.039007171988487244, 0.023101095110177994, 0.0260835699737072, 0.04771464690566063, 0.07503000646829605, 0.017611630260944366, 0.021038906648755074, -0.014097307808697224, -0.0659383237361908, -0.015383075922727585, 0.020105957984924316, 0.011939396150410175, 0.017272381111979485, 0.011737520806491375, -0.06845743209123611, -0.06732632219791412, -0.03167977184057236, 0.04631085321307182, -0.025687377899885178, -0.03810965642333031, 0.014627703465521336, -0.0025679406244307756, -0.00785229355096817, -0.0591357983648777, 0.055136751383543015, -0.009749571792781353, -0.008508809842169285, -0.030196022242307663, -0.004697995726019144, -0.04597108066082001, -0.01855878159403801, -0.0005994052044115961, -0.01878342032432556, -0.04530445113778114, 0.011293046176433563, 0.004355760291218758, 0.03407236933708191, -0.040041595697402954, 0.07539021968841553, 0.04882114380598068, 0.015141826122999191, -0.0243845134973526, -0.05708783492445946, 0.025130895897746086, 0.054814163595438004, -0.005305236671119928, 0.007174971979111433, -0.008433893322944641, 0.0064066266641020775, -0.05024270340800285, -0.00886854249984026, -0.027262676507234573, 0.020433837547898293, -0.033099155873060226, 0.0069719054736196995, 0.043518390506505966, -0.042989496141672134, -0.0038864987436681986, 0.022616378962993622, 0.05650903284549713, -0.005588094238191843, 0.049201320856809616, -0.007689609192311764, 0.027006590738892555, -0.011228466406464577, -0.010823671706020832, 0.003092929720878601, -0.06652706861495972, -0.04415958747267723, 0.007053679786622524, -0.00677508395165205, -0.012162593193352222, 0.0016734004020690918, 0.03316763415932655, -0.005059727467596531, -0.0384310744702816, 0.013918272219598293, 0.00761135620996356, -0.015281236730515957, -0.02626996673643589, 0.02408435195684433, -0.013529624789953232, 0.004656650125980377, 0.005739920306950808, 0.00277326931245625, -0.017982974648475647, -0.010849391110241413, 0.036841653287410736, 0.020485401153564453, 0.02019122615456581, -0.06202871352434158, -0.056190166622400284, -0.02872275561094284, 0.03351724520325661, 0.03946353867650032, -0.04823585972189903, -0.0006860009743832052, -0.06286843866109848, -0.016222914680838585, 0.005689236335456371, 0.030090458691120148, -0.03272038325667381, 0.01684434339404106, 0.025813665241003036, -0.01680697314441204, -0.024539563804864883, -0.04032651335000992, -0.034875039011240005, -0.07037433981895447, 0.0006838706322014332, -0.015577947720885277, 0.056670382618904114, -0.015399033203721046, -0.06995081901550293, -0.055647023022174835, -0.00994394812732935, 0.02508293092250824, 0.009103687480092049, 0.04488147795200348, -0.07402339577674866, -0.04227219521999359, -0.012168019078671932, -0.019615894183516502, -0.013425816781818867, -0.05397937819361687, -0.020558146759867668, -0.004242454655468464, -0.004410248249769211, 0.03166569769382477, 0.00920156016945839, 0.041537538170814514, -0.023645009845495224, 0.008341352455317974, -0.014317070133984089, 0.02558685652911663, -0.007311736699193716, -0.008227155543863773, -0.039260536432266235, 0.02242719754576683, -0.034918759018182755, 0.031576529145240784, -0.001136081526055932, -0.018067587167024612, -0.056381337344646454, 0.037869181483983994, -0.019608264788985252, -0.023204023018479347, -0.030249809846282005, -0.002432983135804534, 0.0013182057300582528, -0.006945191882550716, -0.0656643733382225, 0.04973547160625458, -0.0263337641954422, 0.004551753867417574, -0.010360843501985073, -0.010795476846396923, 0.012970920652151108, 0.027797207236289978, 0.028766650706529617, 0.00730749499052763, 0.035104263573884964, 0.024958642199635506, -0.033051762729883194, -0.029452485963702202, -0.019347092136740685, -0.009803270921111107, -0.04992097243666649, 0.004946145694702864, 0.07071883231401443, -0.036068376153707504, -0.0055175102315843105, -0.04563325643539429, -0.047205183655023575, 0.021752838045358658, -0.05277771130204201, -0.007793332915753126, 0.02044106088578701, 0.038147229701280594, -0.00507740443572402, -0.03252587839961052, -0.014225266873836517, 0.021059714257717133, -0.04295126721262932, 0.0382683165371418, 0.010946858674287796, 0.025389282032847404, 0.028464628383517265, 0.0261253509670496, -0.04321233183145523, 0.04371867701411247, -0.010682275518774986, -0.013876073993742466, 0.0007261484861373901, 0.006615238729864359, -0.013173611834645271, 0.01610327698290348, -0.027258411049842834, -0.045860420912504196, 0.04925297200679779, -0.043920572847127914, -0.001793022034689784, 0.03153923526406288, -0.049796365201473236, -0.02359488606452942, 0.010889873839914799, 0.029007405042648315, -0.021097997203469276, 0.03835943341255188, 0.028321556746959686, -0.039325837045907974, 0.025492127984762192, 0.013048522174358368, 0.028449976816773415, 0.03985382243990898, 0.017860397696495056, 0.07240825891494751, -0.017905591055750847, 0.006553477142006159, -0.034410811960697174, -0.01334433164447546, 0.0017197637353092432, 0.07261864840984344, 0.0015159156173467636, 0.019597455859184265, -0.02588408626616001, 0.05926475673913956, 0.023673439398407936, 0.008216421119868755, -0.013027803972363472, -0.0038554342463612556, -0.001741387415677309, -0.055484626442193985, -0.003856005147099495, -0.035527151077985764, 0.06496063619852066, -0.01793813519179821, -0.018626440316438675, -0.0032172268256545067, 0.0072389100678265095, -0.003296768292784691, -0.035598769783973694, 0.015689708292484283, -0.04112862050533295, 0.010792406275868416, 0.06548408418893814, 0.03894372284412384, -0.028429551050066948, 0.045734040439128876, 0.0009804461151361465, -0.019679922610521317, 0.053760237991809845, 0.013153376057744026, -0.04176386818289757, 0.003924838732928038, 0.00485910614952445, -0.013142549432814121, 0.023422935977578163, -0.013711033388972282, -0.007103450130671263, 0.024913739413022995, -0.015696587041020393, 0.03154449537396431, -0.024019505828619003, -0.050214774906635284, -0.010446710512042046, -0.04143192991614342, 0.026698477566242218, 0.01818973571062088, 0.02343379333615303, -0.02104427106678486, -0.006474757567048073, 0.012510271742939949, -0.01378082949668169, -0.022844836115837097, 0.0069488598965108395, -0.009485557675361633, 0.06716566532850266, 0.06437771022319794, 0.0028018373996019363, 0.018266860395669937, 0.016796141862869263, 0.008115977980196476, -0.06289748102426529, 0.01627570018172264, -0.005853503476828337, -0.046962350606918335, 0.007879305630922318, 0.03723220154643059, -0.03430245444178581, -0.008360056206583977, 0.04698173701763153, -0.03318047523498535, 0.04110615700483322, 0.01659897342324257, 0.044679079204797745, -0.0007644869037903845, 0.0021157909650355577, -0.04338552802801132, 0.029779691249132156, 0.011762711219489574, -0.021973593160510063, -0.02448909357190132, 0.01483192853629589, -0.0031903719063848257, -0.061692625284194946, -0.08447884023189545, -0.030547520145773888, -0.018559057265520096, -0.004801932256668806, -0.01525219064205885, -0.03303515538573265, -0.05754084885120392, -0.0009899711003527045, 0.033135786652565, -0.05653419718146324, 0.07739812880754471, -0.03584146127104759, -0.00301663507707417, 0.03052412159740925, -0.02553425543010235, 0.0024201057385653257, -0.005086002871394157, -0.020461156964302063, -0.011752246879041195, 0.004769184160977602, -0.04402326047420502, -0.03314654901623726, 0.04900630563497543, 0.006176366936415434, -0.008423673920333385, 0.008636485785245895, 0.01192907989025116, -0.0724424198269844, 0.04339691996574402, 0.037870489060878754, 0.02393096126616001, 0.03270341455936432, 0.0034080599434673786, 0.04581800475716591, 0.02545134164392948, 0.010376889258623123, 0.0070397937670350075, 0.005877072922885418, 0.003726519178599119, 0.005279299803078175, -0.015791842713952065, 0.02568979747593403, 0.00865862239152193, -0.0775657594203949, 0.006868361029773951, -0.004635872319340706, -0.033540789037942886, -0.021007521077990532, -0.027248617261648178, 0.03325561434030533, -0.03295297920703888, 0.03695937246084213, 0.06623519212007523, 0.026328828185796738, 0.02975020743906498, -0.06813885271549225, 0.018117155879735947, 0.003692036494612694, -0.0059463148936629295, 0.14440283179283142, 0.029273536056280136, -0.02842084690928459, 0.023978903889656067, 0.0278385691344738, -0.039646368473768234, 0.023719068616628647, 0.045337844640016556, 0.06867904216051102, 0.060004401952028275, -0.08187194168567657, -0.03651939332485199, -0.02131916955113411, 0.009151767939329147, 0.03770595043897629, -0.0008861650712788105, 0.01289375126361847, -0.011301054619252682, 0.006334356497973204, 0.02615957520902157, 0.008274362422525883, -0.006458709482103586, 0.03974691778421402, 0.022611873224377632, 0.038449279963970184, -0.07850610464811325, 0.045147862285375595, 0.0074540055356919765, -0.027048232033848763, -0.023540783673524857, -0.04685206338763237, 0.011514722369611263, -0.027465980499982834, 0.03679439425468445, 0.05425809323787689, 0.03203056380152702, -0.0324639193713665, -0.0433519184589386, -0.0922655314207077, -0.0032368928659707308, 0.04520825296640396, 0.03802839666604996, -0.006500863004475832, 0.09294341504573822, -0.03400373458862305, 0.01896442472934723, -0.006386405322700739, 0.004013680387288332, 0.006053384859114885, -0.05881129205226898, -0.0448233038187027, -0.009923530742526054, 0.007167365867644548, -0.004135095980018377, 0.023654550313949585, -0.010428921319544315, -0.045214854180812836, 0.01807267591357231, 0.007889032363891602, 0.02637879177927971, -0.00368244550190866, -0.009942393749952316, -0.031675443053245544, -0.017959272488951683, 0.015233218669891357, -0.0029894676990807056, 0.03604536131024361, 0.07225756347179413, 0.03443645313382149, -0.03576883673667908, -0.06148652732372284, -0.01638367958366871, 0.00012194953887956217, -0.0337236113846302, 0.009495490230619907, 0.01788226142525673, -0.020674556493759155, -0.04131229221820831, 0.016214296221733093, -0.08688460290431976, -0.0019137774361297488, -0.012903387658298016, -0.06625562161207199, 0.02420826442539692, -0.02054518833756447, 0.012416183948516846, 0.0017149267951026559, -0.020307254046201706, -0.0073332651518285275, -0.047086991369724274, 0.010140540078282356, -0.0014046075521036983, -0.006405347026884556, 0.02274545095860958, 0.04475179314613342, -0.005227306392043829, -0.03602874279022217, -0.013740018010139465, 0.012474746443331242, 0.061891913414001465, 0.0012082805624231696, -0.003256476018577814, 0.00433072866871953, -0.02189864031970501, -0.032465558499097824, 0.00036864151479676366, -0.01467724610120058, 0.002659326186403632, -0.03800807520747185, 0.017944013699889183, -0.025209367275238037, -0.026904989033937454, -0.02280041202902794, -0.018767738714814186, -0.015217983163893223, 0.021313395351171494, -0.002659485675394535, 0.052915994077920914, 0.050608064979314804, 0.011025925166904926, 0.027962790802121162, 0.0004753519024234265, 0.05103138089179993, -0.027808183804154396, 0.0604436993598938, 0.04842314124107361, -0.014079855754971504, 0.009031745605170727, -0.002686689142137766, 0.01935747265815735, -0.0431002713739872, 0.02167782187461853, -0.013529027812182903, -0.02432108297944069, -0.010896038264036179, 0.024974897503852844, -0.05504515394568443, -0.029316890984773636, 0.017865462228655815, 0.00707029365003109, 0.044108159840106964, 0.02495364472270012, -0.09939988702535629, -0.02607048861682415, -0.044734735041856766, 0.0071218060329556465, 0.02045254595577717, 0.01882515475153923, -0.02146344631910324, -0.010119572281837463, 0.006125136744230986, -0.058355219662189484, 0.03658200427889824, -0.025171302258968353, 0.0011513109784573317, 0.037503305822610855, 0.02549874596297741, -1.1294244359305594e-05, -0.028980687260627747, 0.029997145757079124, 0.022381393238902092, 0.01550395879894495, -0.04710380733013153, 0.03896894305944443, -0.03321269899606705, 0.039106644690036774, -0.019182026386260986, -0.025114653632044792, -0.027354439720511436, 0.005029949359595776, 0.005115492735058069, 0.06684833019971848, -0.02157885953783989, -0.019548533484339714, -0.037544913589954376, -0.013591648079454899, -0.07755380868911743, 0.0559365414083004, 0.031634025275707245, 0.028616344556212425, 0.009554591029882431, -0.050796713680028915, -0.055249083787202835, 0.021863609552383423, 0.0808267816901207, -0.0028455089777708054, 0.0005158230778761208, -0.021871762350201607, -0.03242599964141846, -0.019479429349303246, -0.02404046431183815, 0.01650499552488327, 0.01811457797884941, 0.03075544163584709, 0.04168625921010971, 0.053802669048309326, 0.01359399501234293, -0.003560492768883705, 0.06291903555393219, 0.013471643440425396, 0.017396632581949234, 0.028603821992874146, 0.028432572260499, 0.061310987919569016, 0.0018191151320934296, 0.04700637236237526, 0.05772482231259346, 0.022913964465260506, -0.002062431536614895, -0.003909200429916382, 0.007352882996201515, 0.009288974106311798, -0.018495799973607063, -0.05605904012918472, 0.034479763358831406, 0.006581916008144617, 0.10860137641429901, -0.051131471991539, 0.03927027806639671, 0.01437310315668583, 0.007366774138063192, -0.0014557958347722888, -0.020945237949490547, -0.08162839710712433, 0.029603885486721992, 0.01585167460143566, 0.008125596679747105, -0.0036173665430396795, -0.05365041270852089, 0.038384515792131424, -0.019545437768101692, -0.026140620931982994, 0.0893469825387001, 0.12638625502586365, 0.0051570553332567215, 0.004413178656250238, -0.03791859745979309, -0.027088813483715057, 0.013427099213004112, 0.028763843700289726, -0.03224829211831093, 0.02636033110320568, -0.052300501614809036, -0.007258704397827387, -0.02341005764901638, 0.012192071415483952, -0.08628516644239426, 0.026114163920283318, 0.00970775168389082, 0.001742793945595622, -0.032308243215084076, -0.01796022057533264, 0.002304907189682126, -0.057333916425704956, 0.059458911418914795, -0.012698977254331112, 0.023402057588100433, 0.04563261196017265, 0.026613611727952957, -0.10195398330688477, -0.03138311952352524, -0.014457358047366142, -0.028744926676154137, -0.006019307300448418, 0.035843487828969955, 0.005615387577563524, 0.044916193932294846, 0.029495300725102425, 0.0493701808154583, -0.01587889902293682, -0.027778221294283867, -0.00045442316331900656, -0.017105884850025177, 0.019336368888616562, 0.023486072197556496, 0.07454583793878555, -0.027062298730015755, -0.01126489881426096, -0.04416334629058838, -0.04587416723370552, 0.02537139132618904, 0.028791796416044235, -0.046688053756952286, 0.04267425090074539, -0.022042153403162956, -0.03074715845286846, -0.0010170863242819905, -0.006624043453484774, -0.0010717896511778235, -0.033579710870981216, 0.014895821921527386, 0.03331773728132248, -0.01862342283129692, -0.05315524712204933, 0.01711312122642994, -0.05130178853869438, -0.030296139419078827, -0.003494932781904936, 0.03759324550628662, -0.002242754679173231, 0.015836171805858612, 0.0308135524392128, 0.02063809707760811, -0.0037703397683799267, -0.005892723333090544, 0.06656464189291, 0.025771215558052063, -0.041210468858480453, -0.020485423505306244, 0.0073438286781311035, 0.031543683260679245, -0.02991250716149807, -0.022529395297169685, 0.03629766032099724, 0.03530672937631607, 0.02399500273168087, 0.004157110117375851, -0.019345160573720932, -0.028839128091931343, -0.021315274760127068, -0.04726051539182663, -0.07812302559614182, -0.028801998123526573]' select * ,dist = VECTOR_DISTANCE('cosine',@Search,embeddings) from texts order by dist -- people travel flying set @Search = ' [-0.053862474858760834, 0.07673442363739014, -0.22220733761787415, 0.04425668343901634, 0.01701144129037857, 0.08223138749599457, -0.056119758635759354, -0.05087451636791229, 0.0058615365996956825, -0.004386433865875006, -0.00680549768730998, -0.012561852112412453, 0.015372635796666145, 0.03355209901928902, 0.037002868950366974, 0.008151315152645111, -0.011736482381820679, -0.0559665709733963, -0.012033366598188877, -0.020947128534317017, -0.028503544628620148, -0.01028283778578043, -0.01952989213168621, 0.03569025918841362, 0.04752234369516373, -0.0399385467171669, -0.034980472177267075, -0.044386010617017746, -0.05935594439506531, -0.05767259746789932, 0.04142545536160469, -0.013952993787825108, -0.04219847545027733, -0.07793683558702469, -0.005383307579904795, -0.02704077772796154, -0.0016300131101161242, 0.022766418755054474, 0.026411833241581917, 0.027037644758820534, 0.03546792268753052, -0.04573303461074829, -0.030698854476213455, -0.03001352958381176, 0.04883897304534912, -0.006032274570316076, 0.09848432242870331, 0.02681197226047516, -0.02192787639796734, 0.02637435682117939, -0.049456484615802765, -0.013197332620620728, -0.04433551803231239, 0.005709625780582428, 0.0014223601901903749, -0.02612340822815895, -0.004645301960408688, -0.01150439027696848, 0.0002476020308677107, 0.02874804474413395, 0.06801185756921768, 0.03072456642985344, 0.016739945858716965, 0.06012309342622757, 0.033308014273643494, -0.04799368232488632, -0.08570083230733871, 0.06631703674793243, 0.06756993383169174, -0.045301202684640884, 0.08318019658327103, -0.07374844700098038, 0.020982204005122185, 0.03163880854845047, -0.05201447010040283, -0.01593082956969738, 0.010795318521559238, -0.019002629444003105, 0.009700275026261806, 0.025333866477012634, 0.07807213068008423, -0.04677816852927208, 0.01811748929321766, 0.0031094737350940704, 0.030760254710912704, 0.008305534720420837, 0.026540832594037056, -0.048134252429008484, -0.046986307948827744, 0.009551356546580791, 0.044588349759578705, -0.0355173796415329, 0.07510446757078171, 0.036095913499593735, -0.04066182300448418, 0.02551054023206234, -0.03610082343220711, -0.012625494040548801, -0.034823574125766754, -0.09059088677167892, 0.019493144005537033, -0.0005283182254061103, 0.024536889046430588, 0.05709906667470932, 0.029225479811429977, -0.023698335513472557, 0.04563949629664421, 0.007756375707685947, -0.004515582229942083, -0.007379421964287758, -0.02476557157933712, -0.000920205726288259, 0.02775590308010578, -0.00823171529918909, 0.03993465006351471, -0.026482228189706802, 0.011956462636590004, -0.0663151890039444, -0.01735282875597477, 0.006957150995731354, -0.01784759759902954, -0.027733374387025833, 0.022979160770773888, 0.025452136993408203, 0.034284718334674835, 0.05121096223592758, -0.04695860669016838, -0.04146562144160271, -0.012765910476446152, -0.04222125560045242, -0.010537291876971722, -0.022530974820256233, -0.015209334902465343, 0.0008249147213064134, 0.011376401409506798, -0.0015518682776018977, -0.020122643560171127, 0.011986842378973961, 0.0277319997549057, 0.01996360719203949, 0.033921483904123306, -0.02107253111898899, -0.007403898052871227, -0.005990363657474518, 0.03940326347947121, -0.03910711035132408, 0.004676923155784607, -0.030372459441423416, -0.037920866161584854, -0.02442580834031105, 0.0473836213350296, 0.041587259620428085, 0.014460022561252117, 0.04136962071061134, -0.036436472088098526, -0.06590966880321503, 0.021241992712020874, -0.004037976730614901, 0.04406747221946716, -0.02494896948337555, 0.05780649557709694, 0.01940038986504078, 0.018784405663609505, 0.013268438167870045, -0.0496806837618351, 0.00964528601616621, 0.019371723756194115, 0.050319042056798935, 0.027533581480383873, 0.05531640350818634, -0.061351362615823746, -0.0176317747682333, -0.018996726721525192, -0.008612209931015968, 0.0674101859331131, -0.04446431249380112, 0.023302629590034485, -0.0024291579611599445, 0.008309081196784973, -0.09526216238737106, -0.0059860218316316605, -0.07562518119812012, -0.024769175797700882, 0.009877779521048069, 0.011551485396921635, 0.01796528697013855, -0.03427921608090401, -0.026558533310890198, -0.0321478433907032, -0.07145241647958755, 0.008649543859064579, -0.047167956829071045, -0.026637675240635872, -0.05443987995386124, -0.07752290368080139, -0.06453132629394531, 0.07922420650720596, -0.004167146049439907, 0.02551312744617462, -0.03586743026971817, 0.001005923142656684, -0.05180312693119049, 0.014741271734237671, -0.014089709147810936, -0.019177984446287155, 0.015369460918009281, 0.017802884802222252, -0.00323119736276567, -0.03404717519879341, -0.007078847382217646, 0.037577319890260696, -0.014560575596988201, 0.00927674025297165, 0.02470186911523342, 0.03511880338191986, -0.03045837953686714, 0.014752646908164024, -0.05911312624812126, -0.0190200787037611, -0.015707334503531456, 0.05539243668317795, -0.011355402879416943, -0.010293151251971722, -0.025884775444865227, 0.054739899933338165, -0.02781401388347149, -0.051045048981904984, -0.06166858226060867, -0.041273389011621475, 0.024633139371871948, 0.00107875547837466, -0.027509747073054314, 0.022839762270450592, 0.03186710178852081, -0.004463407211005688, -0.014744299463927746, 0.010300209745764732, 0.057055260986089706, 0.05392635986208916, 0.013593091629445553, 0.0019757237751036882, 0.04004262760281563, -0.0050231763161718845, -0.002202106872573495, -0.0027088588103652, -0.003092674072831869, -0.04149329289793968, -0.046705346554517746, -0.002609010087326169, 0.0656202882528305, -0.014033711515367031, -0.025060705840587616, -0.0037866244092583656, 0.07377942651510239, 0.009513398632407188, -0.023516854271292686, -0.05500384420156479, 0.027626579627394676, 0.04428790137171745, -0.01470628660172224, -0.001129325944930315, -0.0144380247220397, 0.012516668997704983, -0.045468784868717194, 0.007813851349055767, 0.01276633981615305, -0.036013972014188766, 0.042436257004737854, 0.010302474722266197, -0.03322415426373482, 0.012293362058699131, 0.013158880174160004, 0.010026335716247559, 0.0604676827788353, 0.011739709414541721, -0.07762851566076279, 0.0115168122574687, 0.011704053729772568, -0.03923153132200241, 0.04764093831181526, 0.017717326059937477, -0.0171642042696476, -0.014217689633369446, -0.00022067663667257875, 0.02649417147040367, -0.025761425495147705, 0.07562465220689774, 0.031558483839035034, 0.013049346394836903, -0.002107892418280244, 0.024092350155115128, 0.003484367160126567, 0.051267534494400024, 0.016852837055921555, 0.02710232324898243, 0.08080057054758072, 0.08400882035493851, 0.014995478093624115, -0.02574595808982849, -0.05084018036723137, -0.01014750450849533, -0.02796337381005287, 0.10009348392486572, 0.06353422999382019, -0.02880043536424637, 0.04828617349267006, 0.060688748955726624, -0.031150473281741142, 0.008280891925096512, -0.028060778975486755, 0.022161215543746948, 0.009834811091423035, -0.00696801720187068, 0.03122439794242382, 0.005038756411522627, 0.04684237763285637, 0.005210087168961763, 0.03941076248884201, 0.06472665816545486, -0.006276765838265419, 0.028221262618899345, -0.05354145169258118, -0.007192348130047321, 0.013624127954244614, 0.026028666645288467, 0.03795324265956879, -0.010002083145081997, -0.0035035372711718082, -0.007743075955659151, -0.03165474906563759, -0.02545107901096344, 0.031927455216646194, 0.00765508646145463, -0.06441585719585419, -0.025288542732596397, 0.010766768828034401, 0.0055702500976622105, 0.04821470007300377, 0.0020202540326863527, 0.005174568854272366, 0.01009645126760006, -0.04472019523382187, -0.013832386583089828, -0.038113612681627274, 0.015747392550110817, -0.029830077663064003, -0.0016359396977350116, 0.016367074102163315, 0.029791558161377907, -0.025606205686926842, 0.0014011188177391887, 0.014748523011803627, -0.046533651649951935, -0.004180107731372118, -0.0014564330922439694, -0.0339818075299263, 0.03389102965593338, 0.0041073160246014595, 0.01884012296795845, -0.005249293986707926, 0.009227504022419453, 0.03440498188138008, 0.010526968166232109, -0.004985027946531773, -0.00020738235616590828, -0.003948873374611139, 0.016008643433451653, 0.017220644280314445, 0.023210715502500534, -0.011674155481159687, -0.0023239385336637497, -0.018832886591553688, -0.011645885184407234, 0.025061490014195442, 0.023121200501918793, 0.00046814861707389355, -0.005873694550246, -0.01749204471707344, -0.009620021097362041, 0.020866692066192627, 0.007566800806671381, -0.01711764559149742, 0.02565787173807621, -0.0005810711300000548, 0.01709386706352234, 0.01940382458269596, 0.012943234294652939, -0.034850798547267914, -0.011962433345615864, -0.01760566048324108, -0.031155385076999664, -0.06714180111885071, -0.01604468561708927, -0.005877605173736811, 0.04759783297777176, -0.01999346725642681, 0.005714385770261288, 0.01546455454081297, 0.06516584008932114, 0.02429724670946598, -0.02255840040743351, -0.061292748898267746, -0.03404277190566063, -0.037808023393154144, -0.008990813978016376, 0.03173277899622917, -0.07618968933820724, -0.038482166826725006, 0.031603917479515076, 0.02469239942729473, -0.0009153003920800984, 0.09773417562246323, -0.0010198571253567934, -0.07195692509412766, -0.0064113992266356945, 0.0796939879655838, 0.035377584397792816, 0.024300245568156242, -0.02320743165910244, 0.013465539552271366, 0.03435331583023071, 0.05537431687116623, 0.03807246312499046, 0.021610280498862267, -0.03731900453567505, 0.05208677053451538, 0.024541521444916725, 0.02374419756233692, -0.005460611544549465, -0.030823446810245514, -0.011298742145299911, 0.03736589476466179, -0.041217830032110214, 0.010812587104737759, -0.020030569285154343, 0.01104435883462429, 0.03069518506526947, 0.000708518666215241, 0.06608368456363678, 0.054531652480363846, 0.0179035235196352, -0.05562695488333702, -0.04963186755776405, 0.009513664990663528, 0.016997745260596275, 0.07911185175180435, 0.03947194665670395, -0.04036480188369751, 0.0007362337782979012, 0.03961101174354553, -0.029199346899986267, -0.024910591542720795, 0.040941912680864334, 0.03296094760298729, 0.01914277859032154, -0.04311768338084221, 0.008552981540560722, -0.052854254841804504, 0.06576872617006302, -0.0013357677962630987, -0.022919805720448494, 0.011018206365406513, -0.050853997468948364, -0.04705611988902092, -0.06618033349514008, 0.03956045210361481, -0.011382551863789558, -0.02980884537100792, 0.045650579035282135, -0.02923038974404335, -0.049739446491003036, 0.023939603939652443, -0.022839460521936417, 0.025147350504994392, -0.06152413785457611, -0.019921528175473213, 0.029643656685948372, 0.034434787929058075, -0.020699601620435715, 0.03134117275476456, 0.03754592686891556, 0.019867271184921265, -0.024957038462162018, -0.012518706731498241, 0.04711650311946869, 0.050435345619916916, 0.0402907095849514, -0.027389053255319595, 0.01598600298166275, -0.023254701867699623, 0.014501014724373817, 0.003986218944191933, -0.01076797116547823, 0.007809855043888092, -0.030568532645702362, -0.012659172527492046, -0.05173122510313988, 0.01630227640271187, 0.026857048273086548, -0.05930164083838463, 0.04034483805298805, 0.026640677824616432, 0.016961878165602684, 0.0015717351343482733, -0.0037326840683817863, -0.03585391491651535, 0.0025011079851537943, -0.08346078544855118, -0.015099523589015007, 0.07668928802013397, -0.0775492936372757, -0.05655403807759285, -0.03159168362617493, -0.008628400042653084, 0.026233263313770294, -0.013614744879305363, -0.04382036253809929, -0.006208110600709915, 0.011989402584731579, 0.03022715449333191, 0.011657245457172394, -0.0026004451792687178, 0.006177494768053293, 0.05764828622341156, -0.059138696640729904, 0.051604609936475754, -0.04226706176996231, -0.021147945895791054, 0.0931001529097557, 0.020989904180169106, -0.012103497050702572, 0.02168836072087288, -0.01770538091659546, -0.060813263058662415, -0.01631275564432144, -0.03626071289181709, -0.014937353320419788, -0.0023415046744048595, 0.01618880219757557, 0.07581888139247894, 0.00078253960236907, 0.026110267266631126, -0.04125359281897545, 0.07886094599962234, 0.025281699374318123, 0.007511085364967585, -0.06372769176959991, 0.023854205384850502, 0.0070777153596282005, 0.022130610421299934, -0.003933281637728214, -0.06037907674908638, -0.0330091267824173, 0.002617472782731056, 0.020184693858027458, -0.03127238526940346, -0.001696707564406097, -0.023990342393517494, -0.011060948483645916, 0.03971528634428978, 0.046926528215408325, -0.012661849148571491, 0.026190761476755142, -0.015426487661898136, 0.031483426690101624, 0.026310833171010017, -0.04280073940753937, 0.0006046215421520174, -0.03532837703824043, -0.049978502094745636, -0.030428174883127213, -0.01853780262172222, -0.031841941177845, -0.000922660285141319, -0.0018639538902789354, 0.014395257458090782, 0.033603180199861526, -0.05515957251191139, -0.06681428104639053, -0.014495975337922573, -0.01570187136530876, -0.03781501576304436, 0.003149628173559904, -0.008802009746432304, -0.00823028665035963, 0.03069920651614666, -0.015947487205266953, -0.0555373951792717, 0.018404502421617508, 0.0029653592500835657, -0.013624681159853935, 0.014758139848709106, 0.03637481853365898, -0.02256682701408863, -0.011781420558691025, -0.0347730852663517, -0.008453354239463806, -0.019311046227812767, -0.03332223743200302, -0.0035105543211102486, 0.0270168948918581, 0.02776847593486309, 0.01826815865933895, -0.029039034619927406, 0.014855487272143364, 0.03709380328655243, 0.002875623293220997, -0.014841211959719658, 0.03734609857201576, -0.025677695870399475, 0.047382328659296036, 0.005290514789521694, 0.002316547790542245, -0.02190549299120903, 0.04998624324798584, -0.018745679408311844, 0.04957675188779831, -0.024338748306035995, -0.005481197964400053, -0.05379927158355713, -0.015409215353429317, -0.06843657046556473, -0.007059851195663214, 0.018650582060217857, 0.01779523864388466, -0.0056877415627241135, -0.03837334364652634, -0.0462334081530571, -0.013449384830892086, 0.03203986957669258, -0.01667155884206295, 0.010643829591572285, -0.07218409329652786, -0.02274138294160366, 0.009027405641973019, 0.0016186721622943878, -0.047124870121479034, 0.011937576346099377, 0.01342321839183569, 0.008207688108086586, -0.02841566689312458, -0.009984626434743404, -0.0010731954826042056, -0.010904660448431969, 0.025147994980216026, -0.03829275071620941, 0.05378000810742378, 0.02526985853910446, 0.05343843623995781, -0.04341792315244675, 0.10105057060718536, 0.035271719098091125, 0.012455728836357594, 0.028224723413586617, 0.021498821675777435, -0.044140882790088654, 0.055813662707805634, -0.02598949521780014, -0.06595104932785034, -0.03292469307780266, -0.005253043491393328, 0.04525535926222801, -0.028180580586194992, 0.06181280314922333, -0.008077103644609451, -0.0008392218151129782, 0.021208833903074265, -0.023534255102276802, -0.06035665422677994, 0.018185874447226524, -0.0007169537711888552, 0.03071155957877636, -0.024632057175040245, 0.0001921048096846789, 0.007113667670637369, 0.012666934169828892, -0.022118424996733665, 0.0364646352827549, 0.014908237382769585, -0.013195818290114403, 0.02817501127719879, -0.015515809878706932, -0.009357189759612083, 0.036134399473667145, -0.00583746749907732, -0.009197785519063473, 0.017633574083447456, -0.018953636288642883, -0.010411965660750866, -0.06504784524440765, 0.0076116290874779224, -0.024768836796283722, -0.010404995642602444, -0.005780045874416828, -0.03158370032906532, 0.0030708389822393656, 0.05985633283853531, -0.00898638553917408, -0.003212343668565154, 0.049548376351594925, -0.035182662308216095, 0.028378333896398544, 0.05223653465509415, 0.02822921611368656, -0.029573993757367134, -0.025141501799225807, 0.007531287614256144, -0.015344111248850822, -0.014068410731852055, 0.04784790799021721, 0.014255544170737267, 0.004716023802757263, -0.0014580448623746634, 0.05913225933909416, 0.04364650323987007, -0.005204115994274616, -0.004963055718690157, -0.04320904612541199, 0.032060980796813965, 0.017601072788238525, 0.10087651014328003, -0.005272873677313328, -0.027145300060510635, -0.06152533367276192, -0.01581391505897045, 0.006250869948416948, 0.013939145021140575, -0.04545010253787041, 0.03651072457432747, -0.060288917273283005, -0.02378781884908676, 0.0003448160132393241, -0.031346067786216736, -0.020015079528093338, -0.02564144879579544, -0.008247078396379948, -0.028735326603055, -0.07543889433145523, -0.030191795900464058, 0.00340361800044775, -0.004883440211415291, 0.06795383244752884, 0.013584045693278313, 0.04222071170806885, 0.008592290803790092, -0.015339639969170094, 0.011062992736697197, 0.0017828184645622969, 0.011797571554780006, -0.016799023374915123, 0.04521056264638901, -0.019295381382107735, -0.03349868953227997, -0.008753085508942604, 0.043399590998888016, 0.05436161905527115, 0.018322335556149483, 0.037256982177495956, 0.05465342849493027, -0.01950635388493538, 0.016076473519206047, -0.03751254454255104, 0.03754441812634468, 0.04481630399823189, -0.04630459472537041, 0.007135187275707722, -0.05163330212235451, 0.06427627801895142] ' select * ,dist = VECTOR_DISTANCE('cosine',@Search,embeddings) from texts order by dist -- men and women set @Search = ' [0.01237055379897356, 0.024239622056484222, -0.19582921266555786, -0.015613879077136517, 0.04553060233592987, 0.07791487872600555, -0.04602167382836342, -0.06439552456140518, -0.043427981436252594, 0.019440926611423492, 0.012373382225632668, -0.0065780701115727425, 0.015703605487942696, 0.01995248720049858, -0.000441278942162171, -0.02380434237420559, -0.004773030057549477, -0.0022546304389834404, -0.06893309205770493, 0.046289220452308655, -0.0815700963139534, 0.017977751791477203, -0.0256639551371336, -0.019171910360455513, 0.09466126561164856, 0.034650009125471115, -0.0290383268147707, 0.02402234449982643, -0.04271193966269493, -0.02901410683989525, -0.01265956461429596, 0.06773647665977478, -0.026040898635983467, -0.051159828901290894, 0.03271431848406792, -0.07067617028951645, 0.03143174946308136, -0.008345941081643105, 0.02663901261985302, 0.035647373646497726, 0.06584825366735458, -0.013237591832876205, -0.01433472614735365, -0.0517093762755394, 0.021245667710900307, -0.023479733616113663, 0.022668402642011642, -0.010702984407544136, 0.028774069622159004, 0.03970919921994209, -0.038457345217466354, -0.02669740840792656, 0.006058731582015753, -0.010615110397338867, 0.05194751173257828, 0.002803204581141472, -0.0003947065561078489, -0.029935486614704132, 0.0075009530410170555, -0.01925850845873356, 0.0199141688644886, 0.0540761761367321, -0.014047808945178986, 0.06985927373170853, 0.029272833839058876, -0.07150446623563766, -0.029290953651070595, 0.07371299713850021, 0.04563957452774048, -0.0723143070936203, 0.01607263647019863, -0.05816732719540596, 0.04342658817768097, 0.013422738760709763, -0.004468090366572142, -0.013602536171674728, 0.0015148582169786096, 0.026496881619095802, -0.011477061547338963, -0.02157992497086525, 0.06164456531405449, -0.037861328572034836, 0.0198453851044178, 0.0037264693528413773, -0.012114601209759712, -0.002769351936876774, 0.029840629547834396, -0.0492936447262764, -0.044592052698135376, 0.0329829566180706, 0.034679580479860306, 0.03304801508784294, 0.07926074415445328, 0.0921645388007164, -0.06327775120735168, -0.005511185619980097, -0.020144980400800705, -0.0038222779985517263, -0.030681217089295387, 0.03099256567656994, -0.04153943061828613, 0.008735354989767075, 0.019256213679909706, 0.013309838250279427, 0.037762876600027084, -0.0021774107590317726, 0.007020723074674606, 0.047675568610429764, -0.03184507414698601, 0.017188025638461113, -0.06557384878396988, 0.0376366451382637, -0.012497816234827042, -0.018476074561476707, 0.0002581600856501609, -0.034405797719955444, 0.021917784586548805, -0.04787197336554527, 0.007537008263170719, 0.056505557149648666, 0.0033981187734752893, -0.020735900849103928, 0.011410803534090519, 0.03873341158032417, -0.012420572340488434, 0.03403520584106445, -0.033089783042669296, -0.007086984813213348, -0.04204908013343811, -0.06248854473233223, 0.005470674019306898, 0.0026199936401098967, -0.010256731882691383, -0.02879636362195015, 0.007623933721333742, 0.04992001876235008, -0.0026015315670520067, 0.019639773294329643, 0.020319517701864243, 0.01341472752392292, 0.047194503247737885, 0.053032055497169495, -0.01450030505657196, -0.06640981882810593, -0.029423657804727554, -0.0002909815520979464, 0.016860481351614, -0.05967976897954941, -0.0795450434088707, 0.001181966857984662, 0.03716329485177994, 0.050098225474357605, 0.024816377088427544, 0.034740347415208817, -0.0034462229814380407, -0.06981880962848663, -0.056540172547101974, 0.030711261555552483, -0.015808748081326485, 0.016044072806835175, -0.023814747110009193, -0.013334913179278374, -0.022314170375466347, 0.01152851339429617, -0.04635216295719147, -0.020469797775149345, 0.012949662283062935, 0.04520042613148689, 0.026957636699080467, 0.04282486066222191, -0.04959902539849281, -0.07573582231998444, -0.05595479905605316, -0.02870493195950985, 0.03224175050854683, 0.018132008612155914, -0.015448815189301968, -0.07552004605531693, 0.01619846373796463, -0.028634417802095413, 0.031246446073055267, -0.0415729358792305, 0.023415926843881607, -0.013252906501293182, -0.011688868515193462, -0.013990876264870167, 0.0026213042438030243, 0.021799754351377487, -0.05127037689089775, -0.03638426586985588, -0.028916656970977783, 0.0064731319434940815, -0.03926217183470726, -0.0330425426363945, -0.04632958769798279, -0.01963021606206894, 0.04886186122894287, 0.047216132283210754, 0.016005340963602066, -0.06615003943443298, -0.009445182047784328, -0.05508309230208397, -0.029744839295744896, 0.01681341417133808, -0.006336553953588009, 0.06633078306913376, -0.003514942480251193, 0.005610647611320019, -0.0007753532263450325, -0.014929904602468014, 0.034857429563999176, 0.015582729130983353, -0.011565103195607662, 0.007222482468932867, -0.033299773931503296, -0.04532258212566376, -0.0074777123518288136, -0.07913103699684143, 0.02281240187585354, 0.008941787295043468, 0.007308525033295155, -0.010956787504255772, -0.04824329540133476, -0.04341774806380272, 0.053111810237169266, -0.007436253596097231, -0.024801893159747124, -0.046288516372442245, -0.07547979801893234, 0.002061691600829363, -0.0019851606339216232, -0.05998770520091057, 0.04827280342578888, -0.0022439954336732626, -0.06141107156872749, 0.005784123204648495, 0.034749437123537064, 0.07704940438270569, 0.030396118760108948, 0.004624818917363882, -0.023219233378767967, 0.037139661610126495, 0.0067637101747095585, 0.02286544255912304, -0.017365016043186188, 0.011127916164696217, 0.0101004121825099, -0.027056053280830383, 0.03307484835386276, 0.054070618003606796, -0.007622106466442347, -0.06618943810462952, -0.04037570208311081, 0.056182462722063065, 0.008952824398875237, -0.021382981911301613, -0.02928183786571026, 0.00493537588045001, -0.047765348106622696, -0.007141344249248505, 0.03143201768398285, -0.04795118793845177, 0.035858359187841415, -0.012759188190102577, 0.019157566130161285, -0.004762647207826376, -0.008988424204289913, 0.04596434906125069, 0.05832699313759804, -0.018704768270254135, 0.031623538583517075, 0.004584648180752993, -0.006454383488744497, 0.009695112705230713, -0.03245990350842476, -0.06897074729204178, -0.002744816243648529, -0.023155156522989273, -0.012941383756697178, 0.043349165469408035, 0.01026755478233099, -0.015390399843454361, -0.024938909336924553, -0.042356930673122406, -0.015250724740326405, 0.05013670399785042, 0.06983187794685364, -0.037431564182043076, -0.007605809718370438, 0.011471192352473736, 0.03287370502948761, 0.004240183159708977, 0.025313491001725197, 0.008898433297872543, 0.047483138740062714, 0.015435287728905678, 0.04762514680624008, -0.02543269470334053, -0.003304327605292201, -0.03209836035966873, 0.017573049291968346, -0.050520334392786026, 0.07347522675991058, 0.06391412764787674, -0.005724151153117418, -0.0395636186003685, 0.05741742253303528, -0.026332320645451546, 0.0724330022931099, -0.04931318387389183, -0.033026400953531265, 0.02969529666006565, 0.009119853377342224, 0.04305592179298401, -0.038625940680503845, 0.057078294456005096, 0.01146570686250925, 0.020206645131111145, 0.018367061391472816, 0.00443393737077713, -0.01426498033106327, -0.03326155245304108, -0.004381794482469559, 0.017430342733860016, -0.00724590802565217, 0.056209079921245575, 0.00836167111992836, 0.021621448919177055, -0.02571628987789154, -0.02472890168428421, -0.04352816939353943, 0.029159924015402794, 0.06708388775587082, -0.027332989498972893, 0.0031264284625649452, 0.03151949495077133, -0.012987878173589706, -0.0343281589448452, -0.006092449184507132, 0.017329314723610878, 0.053523123264312744, -0.03004351630806923, 0.00504837604239583, -0.06521645188331604, 0.009715382941067219, 0.01551011297851801, -0.050152700394392014, 0.015805164352059364, 0.07078198343515396, -0.015146666206419468, 0.0013779187574982643, 0.032897986471652985, 0.007684480398893356, -0.0025172606110572815, 0.014582477509975433, 0.000298757862765342, 0.05721026659011841, 0.034141961485147476, -0.05624014884233475, -0.006467393133789301, 0.05778668448328972, -0.023597072809934616, 0.016875576227903366, -0.022009270265698433, 0.016528502106666565, 0.008313297294080257, 0.08241753280162811, 0.02218642272055149, 0.01816004514694214, -0.0026633753441274166, 0.009557127021253109, 0.0163385309278965, -0.011005430482327938, 0.013616428710520267, 0.03157811611890793, 0.02575390785932541, 0.007897794246673584, -0.02238195389509201, -0.003967178054153919, 0.03368660435080528, 0.027044106274843216, -0.020748334005475044, 0.00969095528125763, 0.0017755689332261682, -0.023160768672823906, -0.02342258393764496, 0.024257225915789604, -0.06812159717082977, -0.040030866861343384, -0.03420571982860565, -0.019213953986763954, -0.05177292972803116, -0.04456043615937233, 0.010961666703224182, 0.00923210009932518, -0.050580184906721115, 0.03458330035209656, -0.036127883940935135, 0.021756678819656372, 0.036377884447574615, -0.04021680727601051, -0.05405646935105324, -0.022356007248163223, -0.047563500702381134, 0.013053851202130318, 0.04643375426530838, -0.027367182075977325, -0.0427098385989666, 0.042107462882995605, 0.02539876103401184, -0.0055090198293328285, 0.06580625474452972, 0.003959292080253363, -0.006784270517528057, 0.015025658532977104, 0.05508021265268326, 0.04463020712137222, 0.012032048776745796, -0.027566347271203995, 0.002988689113408327, 0.05453116446733475, 0.06099727004766464, -0.013656549155712128, 0.010402442887425423, 0.002305764239281416, 0.04383605346083641, 0.024789655581116676, 0.05706468224525452, 0.0009952442487701774, -0.02202880196273327, 0.014697384089231491, 0.055400677025318146, -0.025242475792765617, -0.024719053879380226, 0.019859222695231438, -0.012356542982161045, 0.05644157528877258, -0.021424584090709686, 0.006311161443591118, 0.04908080771565437, 0.012218298390507698, -0.070388562977314, -0.03173903748393059, -0.02960945852100849, 0.028951557353138924, 0.112008236348629, 0.08974413573741913, -0.028196388855576515, -0.031823866069316864, -0.013140670955181122, 0.05172642692923546, -0.006196864880621433, -0.028104115277528763, 0.031219473108649254, 0.058365754783153534, -0.008974725380539894, 0.00460823392495513, -0.007372016552835703, 0.05315056070685387, 0.05539216473698616, -0.012229186482727528, 0.024132143706083298, -0.039275117218494415, 0.010338871739804745, -0.015603321604430676, -0.015444803051650524, 0.006638711784034967, -0.009424936957657337, 0.01960078254342079, -0.006499573588371277, -0.022136347368359566, 0.0012156645534560084, 0.018388478085398674, -0.014185137115418911, -0.012882881797850132, -0.003169712843373418, 0.01420595496892929, -0.029908202588558197, 0.008221198804676533, 0.01879950612783432, 0.011950950138270855, 0.013227849267423153, 0.012987825088202953, -0.026071812957525253, 0.011576159857213497, 0.027534188702702522, 0.024988336488604546, 0.04866841435432434, 0.03028479404747486, 0.00564165273681283, -0.028115306049585342, -0.027848925441503525, 0.024740831926465034, -0.03752727434039116, -0.013309558853507042, -0.0019820823799818754, -0.03983188793063164, -0.0569121427834034, 0.002595193451270461, -0.013414221815764904, 0.021932153031229973, 0.049898747354745865, -0.0019941916689276695, -0.0075864894315600395, 0.0072683426551520824, 0.009657070972025394, -0.059203919023275375, -0.03406965732574463, -0.0011716102017089725, 0.04530983418226242, -0.018698088824748993, -0.04943174868822098, 0.032289303839206696, -0.0018222946673631668, -0.001560534117743373, -0.030991055071353912, 0.049944665282964706, -0.03808208554983139, -0.03281693533062935, 0.0035294541157782078, 0.026255633682012558, -0.01477489061653614, -0.010622726753354073, 0.023649675771594048, -0.04328983277082443, 0.040119800716638565, -0.0277702659368515, -0.014179005287587643, 0.05697385221719742, 0.027776895090937614, 0.022273261100053787, -0.03282482177019119, -0.007251861970871687, -0.04303174465894699, -0.0030635015573352575, -0.05053115263581276, -0.046777211129665375, -0.005521655082702637, 0.04009922221302986, 0.07512093335390091, 0.0015436280518770218, 0.01655617728829384, 0.015109320171177387, 0.01140138041228056, -0.02351977862417698, 0.013504979200661182, -0.09182482212781906, 0.018604809418320656, 0.015308678150177002, 0.06290865689516068, -0.01732105016708374, -0.05975252389907837, 0.00812321063131094, 0.0009631541324779391, -0.03443889319896698, -0.02894439548254013, -0.0042705778032541275, -0.01686175912618637, -0.046966779977083206, -0.009371488355100155, 0.030095001682639122, 0.008612172678112984, 0.04172777384519577, -0.011643681675195694, 0.0009737798827700317, -0.0427059531211853, 0.00441448949277401, -0.018092725425958633, -0.03799719735980034, -0.013489563018083572, 0.0600193589925766, -0.0634143203496933, -0.00727631151676178, -0.015273986384272575, 0.013198399916291237, -0.03482510522007942, -0.024336474016308784, -0.03709769248962402, -0.07557176053524017, -0.025176003575325012, 0.07785925269126892, -0.06072531268000603, -0.08608098328113556, 0.021817144006490707, 0.0001775398850440979, 0.04497992619872093, -0.029442425817251205, -0.025335822254419327, 0.05449514091014862, -0.027911094948649406, -0.013486950658261776, 0.01973859593272209, -0.0024275099858641624, -0.0027841480914503336, 0.005654281470924616, -0.00046254743938334286, 0.011583946645259857, -0.053393565118312836, -0.036912765353918076, 0.005469242110848427, -0.0035772717092186213, 0.02835286594927311, 0.023450927808880806, -0.03181128576397896, 0.03038078546524048, 0.022530443966388702, -0.021874435245990753, 0.04191597178578377, -0.006974989548325539, -0.02914976328611374, 0.05874782055616379, 0.03512626513838768, -0.03991765156388283, -0.0019961975049227476, 0.020286642014980316, 0.00992339476943016, 0.08579371124505997, -0.04068402200937271, -0.02975337952375412, -0.008792833425104618, -0.04763348773121834, -0.09980571269989014, 0.019442889839410782, -0.010120782069861889, 0.039765600115060806, -0.028224697336554527, -0.07335420697927475, -0.008500251919031143, -0.03246380016207695, 0.06138433516025543, 0.020087748765945435, 0.002758546732366085, -0.03916047513484955, -0.05057390779256821, -0.02677745185792446, 0.004483225289732218, -0.012551580555737019, 0.04239640384912491, 0.03716052323579788, 0.04867367073893547, 0.07328944653272629, -0.04355652630329132, -0.011410933919250965, 0.030657732859253883, 0.04016264155507088, -0.01869187317788601, -0.005746589507907629, -0.020260566845536232, 0.037912070751190186, -0.028735356405377388, 0.016896530985832214, 0.024582164362072945, -0.015506022609770298, 0.05554620176553726, 0.015669088810682297, 0.03429349139332771, 0.035217687487602234, -0.028187988325953484, -0.0650487169623375, 0.004335780628025532, -0.009703835472464561, 0.08378484100103378, -0.022748932242393494, 0.0013924158411100507, 0.036350298672914505, -0.012990825809538364, 0.0282017569988966, 0.025552568957209587, -0.0809384435415268, 0.0142765361815691, 0.05757252871990204, 0.00172137632034719, 0.020094845443964005, 0.00874384120106697, -0.012796415947377682, 0.04399215802550316, -0.013127279467880726, 0.05994236469268799, -0.015510883182287216, -0.009694043546915054, 0.008261890150606632, 0.010053087957203388, 0.060878634452819824, -0.004384650383144617, 0.02663969062268734, 0.006029771640896797, 0.03139827027916908, -0.03705187141895294, 0.004437887575477362, -0.034144509583711624, 0.005889259744435549, -0.08575199544429779, -0.01720130816102028, -0.01393953152000904, -0.03323160111904144, -0.003150275209918618, -0.048236191272735596, 0.025162145495414734, 0.014639390632510185, 0.07152772694826126, 0.01948758400976658, -0.0275118425488472, 0.033225275576114655, 0.039410948753356934, -0.03909173980355263, -0.024964183568954468, -0.04168178141117096, -0.00682516535744071, 0.014942646957933903, -0.002938796067610383, 0.008154074661433697, 0.045982200652360916, -0.035190433263778687, 0.04332344979047775, 0.05764489248394966, 0.006816228851675987, -0.060996782034635544, -0.021545276045799255, -0.00849003717303276, -0.004598199389874935, 0.06036629527807236, -0.014939922839403152, -0.02233090251684189, -0.0538782961666584, -0.04430929943919182, 0.00835644081234932, -0.009245919063687325, -0.035477422177791595, 0.03989940509200096, -0.006009814795106649, -0.007031283341348171, -0.048485081642866135, -0.02287021465599537, -0.03248808905482292, -0.018149923533201218, 0.02442087046802044, -0.027541102841496468, 0.03170221671462059, -0.05533201992511749, -0.04342202469706535, -0.026908669620752335, 0.004367942921817303, -0.018623335286974907, 0.06439100950956345, 0.016771947965025902, 0.023305175825953484, -0.01517521869391203, 0.049208126962184906, 0.037189435213804245, -0.0016709266928955913, 0.024677228182554245, 0.005417055916041136, -0.04067694768309593, -0.013457142747938633, 0.03124595806002617, -0.011107987724244595, 0.03241858258843422, 0.0602632537484169, 0.09424291551113129, -0.0012391095515340567, 0.015682732686400414, -0.012820606119930744, -0.020100250840187073, -0.006965359207242727, -0.00617004930973053, 0.0008079578983597457, -0.050157204270362854, -0.007003145292401314] ' select * ,dist = VECTOR_DISTANCE('cosine',@Search,embeddings) from texts order by dist |
The script contains a simple INSERT statement followed by several SELECT queries on the table with an ORDER BY clause. The results are sorted based on the output of VECTOR_DISTANCE.
I use an auxiliary variable called @Search to store the embeddings of my “search text.” These embeddings are then compared with the embeddings of each row in the table, and the results are sorted by the output of the comparison, which is calculated using VECTOR_DISTANCE.
Note that I repeated the @Search variable for each search text. I generated each embedding using the Hugging Face Space and copied it into the script.
Note, this short video shows how creating your own search vector is done using Hugging Face.
The text used to generate the embeddings is included as a comment above the variable assignment. For example:

In a real scenario, the values of the @search variable would come from an application that, before running the script, invokes an API to retrieve the embeddings. Additionally, in SQL Server 2025, we should be able to do this directly within T-SQL.
Once I have access to a public preview, I will write another blog post with detailed instructions on how to achieve that. For now, just keep in mind that these values are only here to demonstrate the comparison process!
Important: I generated each embedding using the same model. You (still) can’t compare embeddings generated by different models, because, after all, each model has its own rules. For example, in our first example, dimension 0 was vehicle. Most likely for the Nomic model, dimension 0 is not vehicle, and even less, if it were, it would be classified in the way I defined.
Here are the output examples of SELECT statements for each text for which I populated each the variable search and the commented results:
- Search: “white vehicles”
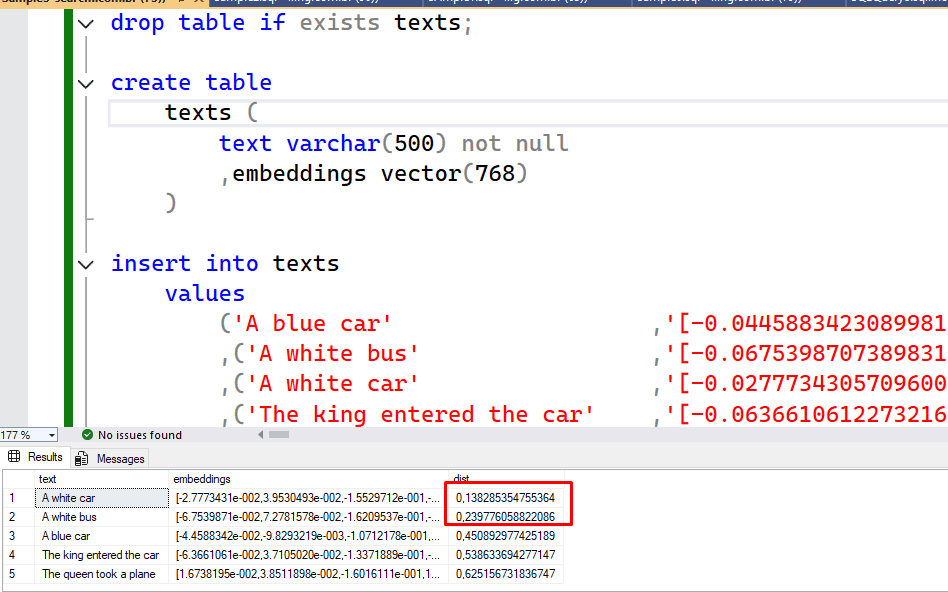
Notice how the distance between “A white car” and “white cars” is much smaller compared to the others. By sorting distance, we can retrieve the most similar segments.
- “people travel flying”
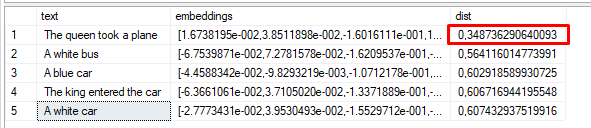
Although the distance is high, compared to the others, the phrase about the queen has the smallest distance, which reflects its meaning. A more detailed phrase or a model with more dimensions could likely produce a smaller value.
- “men and women”
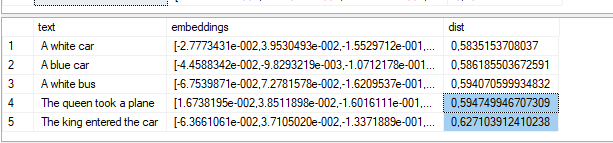
Here, the comparison didn’t turn out as expected. I made a point to include this example, so you understand that this type of comparison won’t always produce the desired outcome. This depends on the model used, how it interprets the text and context, and how it converts them into embeddings. A deeper analysis would be necessary here to identify what adjustments could be made to retrieve the intended information.
The last example was a bit frustrating, right? There can be many reasons for this. Our model might struggle to understand certain terms due to limitations in its training data or might not perform well with short texts. I suspect it could be related to the Nomic model and its training. We can explore these scenarios in greater detail in future posts.
But for now, I’ll leave you with an exercise, and you can share your results in the comments:
- Generate embeddings for the word “women” using the Hugging Face Space, replace them in the @search variable, and run the query. What changed in the results?
- Now, generate embeddings for the word “men” and do the same thing. Any surprises?
Read also: VARCHAR(MAX) for storing large data in SQL Server
And that’s not all, folks!
A super important point is that I didn’t need to know which dimension represents what in these embeddings generated by the AI. I don’t know if position 0 represents a vehicle, I don’t know what the value means. I only know that this whole set is enough for me to compare with another, and that I can use the result of this comparison to test the similarity of two phrases, based on context and meaning. That’s why I mentioned earlier that you don’t need to worry about the values. For a basic understanding of embeddings and their use, you don’t need to know the internal details. However, for more advanced use cases or troubleshooting, understanding the underlying model can help you predict how your text will behave. This requires diving into the fascinating and complex world of AI and large language models (LLMs).
The only relevant information for you is the number of dimensions and the quality of the model in handling the subject you are going to represent. For example, if the model doesn’t understand Brazilian Portuguese well, then your embeddings will be very bad for phrases in Portuguese. If you are going to use common terms in a specific area, such as medicine or law, and the model doesn’t know them well, you will also have problems.
It’s art!
In the case of SQL Server, especially in Azure SQL Database, support is still very basic. If you tried to apply this to a table of millions of rows, it would probably take a table scan, which is bad enough when doing simple comparisons between text values. That’s where that algorithm mentioned for 2025 comes in: DiskANN, which is a way to index and search for embeddings in these indexes.
I will cover this in a later post when I’ve tested it and it has become available to talk about.
This post provided the fundamentals for you to understand how SQL Server fits into the world of AI through embeddings. Any questions, just find me in the comments or on social media.
If you want more practical examples of how to use embeddings:
- The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
This is one of my favorite articles. This post provides an excellent explanation of how embeddings work on a deeper level, but it starts from the basics—without AI—and gradually builds understanding step by step. Jay Alammar is a well-known figure in the world of AI and machine learning. His posts often include a wealth of visual illustrations that make it much easier to grasp new concepts
Thanks for reading and until next time!
FAQs: AI and Embeddings in SQL Server 2025
1. What are embeddings in SQL Server?
Embeddings are numerical vector representations of text or data that capture meaning, allowing similarity comparisons directly in SQL Server 2025.
2. How can I store embeddings in SQL Server?
SQL Server 2025 introduces a VECTOR data type, letting you store embeddings in tables for use in T‑SQL queries.
Read also: In-memory optimized tables for high-throughput AI workloads
3. How do I compare embeddings in T‑SQL?
Use functions like VECTOR_DISTANCE('cosine', vector1, vector2) to calculate similarity between embeddings for ranking or search.
4. Can I generate embeddings directly in SQL Server?
Embeddings are typically generated by AI models (via Python, REST APIs, or PowerShell) and then stored in SQL Server for querying.
5. What are some practical uses of embeddings in SQL Server?
They enable semantic search, recommendations, AI-driven analytics, and similarity-based ranking without leaving the database.
6. How do embeddings improve AI workflows in SQL Server?
By storing vectors natively, embeddings allow fast similarity search and integration of AI insights directly in T‑SQL, streamlining data-driven applications.
Subscribe to the Simple Talk newsletter
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments